
Soul App 正式升级 自研端到端全双工语音通话大模型
SoulX-DuoVoice 包含一个负责对话理解与生成的 Dialogue Model 和一个负责语音生成的 Speech Model。
新模型摒弃了传统语音交互中依赖的 VAD(话音激活检测)机制与延迟控制逻辑,打破行业中普遍存在的“轮次对话”模式,赋予 AI 自主决策对话节奏的能力。AI可实现主动打破沉默、适时打断用户、边听边说、时间语义感知、并行发言讨论等。同时,模型具备多维度感知(包括时间感知、环境感知、事件感知等),口语化表达(如语气词、结巴、明显情绪起伏),音色复刻等能力,让AI更具“真人感”,支持打造更沉浸、类现实交互的语音互动新体验。
SoulX-DuoVoice 核心技术架构
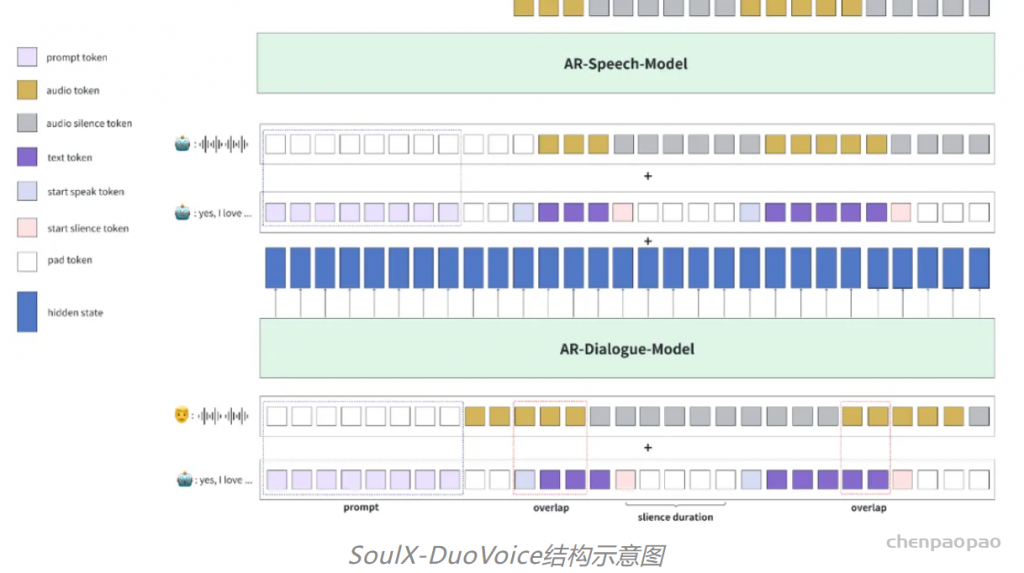
SoulX-DuoVoice 结构示意图
为了尽可能保证全双工对话模型的基础对话能力,避免模型 “降智”,SoulX-DuoVoice 采用了双 LLMs 的结构。具体而言,SoulX-DuoVoice 包含一个负责对话理解与生成的 Dialogue Model 和一个负责语音生成的 Speech Model。
- Dialogue Model
- 接收用户侧的语音 Tokens 作为输入;
- 负责生成机器人对话的文本 Token 序列;
- 向下游 Speech Model 传递高维语义上下文表示[应该会比语音token方法效果更好],确保跨模态信息的完整传递。
- Speech Model
- 接收来自 Dialogue Model 的高维上下文表示和文本 Token 序列;
- 生成机器人侧的语音 Tokens 输出;
- 通过显式的高维上下文传递机制,有效缓解了文本与语音模态间的信息干扰问题。
数据及对话训练策略
- 精准的说话时机建模
- 模型通过建模预测静音(Silence)和响应(Response)Token 任务,实现机器人的完全自主决策能力,精准控制对话节奏中的沉默与发声时机。
- 沉默持续时间建模(Silence Duration Token Prediction)
- 训练阶段:显式建模静音持续时长预测任务,显著提升模型训练效率与收敛速度;
- 推理阶段:沉默持续时长建模有效规避了 LLM 解码过程中的重复问题,无需依赖复杂的解码惩罚机制,提升了输出语音的时序稳定性,同时显著减少解码步数,降低推理延迟。
- 可控对话风格建模
- 支持 Prompt 驱动的个性化对话生成,通过文本和音频 Few-Shot 学习机制,实现特定对话风格驱动。
- 安全性对齐
- 采用融合对齐算法与监督微调的混合损失函数设计(KTO-loss 与 SFT-loss 联合优化),显著提升机器人输出的安全性和可靠性。
此次Soul技术升级便重点聚焦在全双工实时语音通话能力在陪伴场景的交互突破。具体来看,升级后AI能力特点包括:
一、全双工语音交互,AI具备自主决策反应能力
新模型支持响应(Response)、倾听(Listen)与打断(Interrupt)流式预测,AI自主决定发言时机,实现完全端到端的全双工交互——AI 与用户可以同时说话(如辩论、吵架、合唱)、适宜打断用户/被用户打断、AI主动打破沉默发起话题。
当AI拥有自主决策反应能力,在边听边说中,掌握互动时机、互动内容的“主动性”,将极大提升人机对话的自然度,并且在较长时间、多轮对话的交互中,实现沉浸的类真实交互体验。
二、日常表达口语化和情感化,情绪更鲜明的人机交互
让AI更具“真人感”,这包括在情绪表达、发音特点、对话内容等多维度的综合指标提升,更加接近现实表达。例如,情绪表达方面,除了具备笑、哭、生气等情绪特色外,新模型的声音情绪起伏更加明显,并能结合对话推进实现同步变化。在发音特点上,具备语气词、结巴、常用口头禅、咳嗽等日常语音元素。此外,AI对话的内容更加口语化、社交化,而非书面语言。
三、时间、事件、环境感知能力,互动更具沉浸感
Soul的新模型基于纯自回归模型架构,统一文本和音频生成(Unified Model),充分利用大语言模型强大的学习能力,让AI发言深度整合人设、时间、环境及上下文对话等信息。这意味着,具备感知、理解能力的AI能够更好塑造“数字人格”,形成丰富的AI故事线,让人机交互真正成为“情感与信息的双向交流”。
值得关注的是,Soul AI团队正在积极推进全双工语音通话模型在多人交互场景的创新应用。该技术突破使得AI在多人语音对话中能够基于智能决策算法,精准把握发言时机,有效引导话题讨论并实现深度延伸,从而在复杂社交场景中构建更自然的交互体验。