
- 论文题目:《SpeakerLM: End-to-End Versatile Speaker Diarization and Recognition with Multimodal Large Language Models》
- 论文地址:https://arxiv.org/pdf/2508.06372
- Pseudo–code/demo: https://sites.google.com/view/speakerlm/code
目标:解决“说话人分割与识别(SDR)”任务,简单讲就是从音频里搞清楚“谁在什么时候说了什么”,SpeakerLM是第一个能完整做SDR的音频-文本MLLM。

三种方案的对比:
- (a):SD+ASR级联,“先分割再识别”,有误差传递、无法联合优化;
- (b):SD+ASR+LLM,在级联后加LLM修正,依赖前端输出,改不了上游的错;
- (c):E2E-SDR(端到端),用一个SpeakerLM模型统一做,但需要考虑如何处理“注册说话人不匹配”的情况(比如多注册了人、少注册了人[这个比较难做])。
SpeakerLM —— 一种面向 SDR 的统一多模态大语言模型,可在端到端方式下同时执行 SD 和 ASR。此外,为适配不同的真实应用场景,我们在 SpeakerLM 中引入了灵活的说话人注册机制,使其能够在多种注册配置下执行 SDR。SpeakerLM 通过多阶段训练策略,在大规模真实数据上逐步构建而成。实验结果表明,SpeakerLM 具有强大的数据扩展能力和泛化能力,在域内和跨域的公开 SDR 基准上均优于最新的级联式系统。此外,实验还显示,所提出的说话人注册机制能够有效保证 SpeakerLM 在不同的注册条件以及不同数量的已注册说话人下,持续保持稳健的 SDR 性能。
Introduction
SpeakerLM主要贡献:
- 第一个“端到端SDR的多模态大模型(SpeakerLM)”,不用拆SD和ASR,解决了级联系统的误差传递问题;采用音频编码器和两个投影器作为前端,构建了针对 SDR 的编码器–投影器–LLM 架构
- 加了“灵活的说话人注册机制”,能应对无注册、匹配注册、过量注册三种场景,特别贴合现实需求;将先验的说话人嵌入投影后与音频与文本 token 进行拼接,使模型能够处理真实应用中多种多说话人场景。
- 用“多阶段训练”让模型从简单到复杂逐步学习,数据越多性能越强,在域内、域外(比如车内噪音)都比现有基线好。
模型架构
SpeakerLM 在预训练文本 LLM 中集成了一个轻量级的模态对齐机制。对于输入的多说话人音频,我们首先使用音频编码器进行编码,然后通过一个投影器将音频嵌入注入到文本 LLM 的特征空间中。
对于说话人注册部分,我们使用冻结的文本分词器(tokenizer)对已注册说话人的姓名以及特殊标记(如 <start> 和 <end>)进行分词。已注册说话人的语音首先经过冻结的预训练嵌入提取器处理,以获得说话人嵌入;随后,这些嵌入通过单层线性投影器映射到 LLM 的主干网络中。
Audio Encoder and Projector
音频编码器使用预训练的 SenseVoice-large 编码器初始化,该编码器具备强大的音频表征能力,并在多语言语音识别和音频事件检测等各类音频理解任务中表现优异。
音频投影器采用随机初始化的两层 Transformer,之后接一个卷积神经网络层用于维度对齐。
Embedding Extractor and Projector
使用预训练的说话人嵌入模型来提取说话人嵌入,该模型能够提供稳健且具有判别性的特征表示,对精确的说话人识别和归因至关重要。采用开源的 ERes2NetV2 模型进行嵌入提取,该模型在多个说话人验证基准上达到了 SOTA 性能。提取出的嵌入通过单层线性投影器进行维度对齐。
Large Language Model
使用预训练的 Qwen2.5-7B-Instruct作为文本 LLM 主干,以充分利用其强大的指令跟随能力和通用语言理解能力,从而使 SpeakerLM 能够高效处理不同信息量的复杂多说话人 SDR 任务。

灵活的说话人注册机制
如图 2 所示,我们在 SpeakerLM 中引入了灵活的说话人注册机制。为了适配真实应用场景,我们提出了三种不同的注册策略:No-Regist、Match-Regist 和 Over-Regist,具体如图 3 所示。
设真实标注中的说话人数为 Ngt,注册的说话人数为 Nrg,则在不同注册设置下,两者的关系可以形式化为:
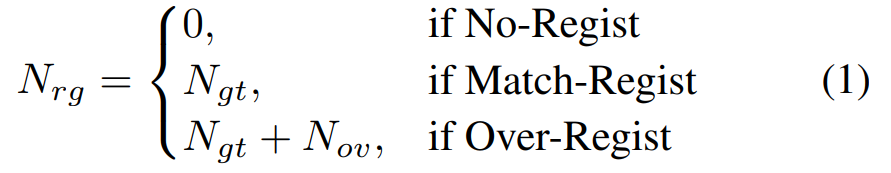

No-Regist 表示不执行任何说话人注册。这是传统级联式 SD 系统及其应用中的常规设置。我们仅将多说话人音频输入模型,而不提供任何关于说话人的先验信息。这种范式与传统级联式 SDR 框架相一致,输出中的每位说话人都以匿名说话人 ID 表示(如 spk0、spk1 等)。
Match-Regist 假设所有真实标签中出现的说话人均已提前注册,与 SA-ASR 的设定一致。模型需要将每位说话人正确匹配到对应的姓名。该设置能够很好地反映那些已知用户预先注册、并需要个性化输出(如带说话人姓名的转写)的实际场景。在 Match-Regist 中,准确的说话人–姓名关联至关重要,模型必须有效利用注册的说话人信息来进行识别。
Over-Regist 指注册的说话人数多于实际音频中出现的说话人。在这种情况下,模型必须判断哪些注册说话人并未出现在当前语句中,并对剩余的活跃说话人执行准确的带说话人归因的 SDR。这一设置比 Match-Regist 更具挑战性,因为模型不仅需要处理冗余的说话人信息,还必须抑制无关的身份。同时,这与实际场景高度一致:系统可能预先注册了大量用户,但在某次交互中只有其中一部分参与。
总体而言,所提出的说话人注册框架使 SpeakerLM 能够在不同程度的说话人监督条件下灵活执行 SDR,从匿名转写到带个性化姓名的转写均可适用,从而覆盖多种真实的多说话人应用场景。
多阶段训练策略
分了4个阶段,让模型循序渐进掌握SDR能力:
Stage1:只训ASR,得到“SpeakerLM-ASR”。用60万小时ASR数据,加LoRA训LLM,不加载说话人相关模块——目的是先把“听清楚内容”的能力拉满,毕竟ASR准了,后续SDR才好做。在这一阶段,说话人嵌入提取器与投影器不会加入模型。在随后的三个阶段中,这些模块会被加入完整架构。
Stage2:使用模拟的 SDR 数据训练随机初始化的投影器,同时 冻结 LLM 与音频编码器,目标是在 SDR 领域快速对齐音频与文本。使用模拟数据训练使得投影器能够在简化分布下建立初步的粗粒度对齐。与真实录音相比,模拟混合语音仅通过简单地拼接不同说话人的语句构造,并未模拟强噪声或混响。
Stage3:用真实SDR数据训音频编码器+projector。冻结LLM,联合训前两个模块——真实数据更复杂(比如会议远场语音),这一步是让模型抓真实场景的声学特征。
Stage4:联合训所有模块。给LLM加LoRA,一起训音频编码器、projector和LLM——最后一步整合语言(文本)和声学(音频)信息,搞定复杂多说话人场景。
数据构成
数据构成:真实+模拟,覆盖各种场景
公开语料库中采样了 238.55 小时音频用于训练与评估,覆盖多种真实世界的多说话人场景。此外,我们还使用了 7456.99 小时的内部数据用于训练与验证,以进一步增强模型性能。详细统计如表 1 所示。

主要是中文数据集,用来训和测SDR:
- 公开数据:AliMeeting(会议场景,训104.75h、测10h)、AISHELL4(会议场景,训107.5h、测12.72h)、AISHELL5(车内场景,测3.58h,有风声、轮胎声、空调声,特别难,用来测泛化性);
- 内部数据:7426.7h训练、30.29h验证,是近场录音,用来提升模型数据量。
模拟数据:用AliMeeting、AISHELL2、LibriSpeech、In-House-Train等的近场语音混出来的,5000h训练、5.6h测试(叫Simulation-Test),每段50秒,2-4个说话人,加了真实噪音和混响——用来做Stage2的训练数据。
Experiments
实现细节
音频重采样至 16 kHz,录音被随机切分为 40 到 50 秒的片段,用于训练和测试 SpeakerLM。对于说话人注册,已注册说话人的语音被切分为 2–10 秒的片段用于嵌入提取,随后将对应嵌入取平均,生成单个代表性说话人嵌入。对于 Over-Regist,训练期间过度注册的说话人数在 1 到 50 之间均匀取值。
优化器AdamW,学习率从1e-5 warm-up到5e-5,再余弦衰减;用4个NVIDIA A800 GPU,每个阶段训1M步,每10K步验证一次。
评估指标
公开基准上评估 SDR 性能,包括同域数据 AliMeeting-Eval 和 AISHELL4-Eval,以及跨域数据 AISHELL5-Eval。
使用以下指标进行评估:字符错误率(CER)、cpCER、∆cp、saCER以及 ∆sa。
- CER:只看ASR准不准,不管说话人(比如把“你好”写成“你郝”,CER就高);
- cpCER:联合看ASR和SD,无注册时找“最优标签排列”(比如模型标spk0,实际是spk1,只要内容对、排列对就算对);
- saCER:联合看ASR和SD,有注册时直接按名字对齐(比如模型把Mike的话标成Lucy,就算错);
- ∆cp=cpCER-CER、∆sa=saCER-CER:反映“说话人归属误差”——比如CER很低但∆cp高,说明ASR准但说话人标错了,这俩指标不受ASR影响,更准。
基线模型:
- SD+ASR:用Paraformer-large(ASR里的SOTA)当ASR,配4个SD工具(3D-Speaker、Pyannote3.1、Diarizen-base/large),共4个基线;
- SD+ASR+LLM:用Diarizen-large+Para当前端,加LLM修正(ChatGPT4.5零样本、Qwen2.5-7B零样本、Qwen2.5-7B微调),共3个基线;
- E2E-SDR:SpeakerLM。
实验结果
Performance without Speaker Registration
SpeakerLM 在无注册条件下,预测结果中的每个说话人都以匿名 ID 表示。

LM零样本(ChatGPT4.5、Qwen2.5零样本)特别差,CER反而升高——因为LLM会“ hallucination(幻觉)”,明明让它只改说话人标签,它却改了内容;就算微调Qwen2.5,也只比最强的SD+ASR(Diarizen-large+Para)好一点。
结果表明,当 SDR 数据规模有限时,SpeakerLM 表现落后于大多数级联基线。但随着训练数据量的增长,SpeakerLM 展现出强大的数据扩展能力(data scaling capability),其 cpCER 和 ∆cp 显著提升。
与此同时,CER 的提升幅度较小,这是因为企业内部数据多为近场录音,对具有混响的远场语音带来的 ASR 改善有限。当 SDR 训练数据达到 7,638.95 小时后,SpeakerLM 的性能显著超越所有基线系统。在 cpCER 方面,SpeakerLM 相比最强的级联系统,在 AliMeeting-Eval、AISHELL-4-Eval 和 AISHELL-5-Eval 上分别取得 6.60%、6.56% 和 13.82% 的绝对改进。值得注意的是,即使在难度较高且跨域的 AISHELL5-Eval 测试集上,SpeakerLM 也取得了 0.57 的 ∆cp,表明该模型在未见过且噪声环境下具有强大的鲁棒性和泛化能力。
在AliMeeting-Eval和Simulation-Test上,从Stage1到Stage4,cpCER和∆cp稳步下降,说明多阶段训练有效;第二阶段的 CER 高于第一阶段,这是因为 Stage 2 依赖模拟数据,而模拟过程并未包含来自这两个数据集的真实音频,导致了领域不匹配。后续阶段(Stage 3 和 Stage 4)中在更真实、更具多样性的会议风格数据上的微调,对缓解领域不匹配、提升模型在不同评测场景下的稳健性至关重要。

Performance with Speaker Registration
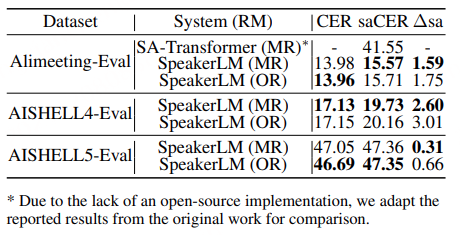
- 比SA-Transformer强太多:在AliMeeting-Eval上,SpeakerLM的saCER比SA-Transformer低25.98%——因为SA-Transformer只能处理“注册和实际完全匹配”的情况,而SpeakerLM能应对各种注册场景;
- Match-Regist vs Over-Regist:两者的CER、cpCER差不多,但Over-Regist的∆sa更高(比如AliMeeting-Eval上,Match-Regist的∆sa=1.59%,Over-Regist=1.75%)——说明多余的注册信息会轻微影响说话人归属,但整体影响不大,模型能过滤冗余。
多余说话人数量对saCER的影响:

随着 Nov 的增加,并未观察到明显的性能退化。这反映出 SpeakerLM 对冗余说话人身份具有良好的鲁棒性,并且在推理过程中能够聚焦于与任务相关的说话人表征。
Impact of Embedding Extractors
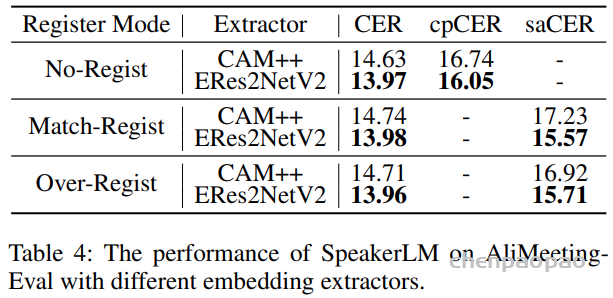
选择ERes2NetV2/CAM++ 作为说话人特征提取模型,在多项说话人验证基准上,ERes2NetV2 的表现优于 CAM++:No-Regist时,ERes2NetV2的CER=13.97%、cpCER=16.05%,都比CAM++低——说明“说话人embedding质量”会影响SpeakerLM性能,好的embedding能让模型更准识别说话人。
Training Pseudo-code
无注册/匹配注册/过度注册任务配置:
在 SpeakerLM 中,我们为 SDR 任务引入了三种说话人注册(speaker registration)机制:无注册(No-Regist)、匹配注册(Match-Regist) 和 过度注册(Over-Regist)。在训练过程中,所有样本默认以匹配注册的形式加载。对于每一个训练批次,我们会从 0 到 1 的均匀分布中采样一个随机数,用于决定注册类型:
- 如果随机数小于 1/3,则保持匹配注册(Match-Regist);
- 如果随机数在 1/3 与 2/3 之间,则从提示(prompt)中移除所有已注册的说话人(No-Regist);
- 如果随机数大于 2/3,则从其他会话中随机采样 1 到 50 名说话人,并将其作为冗余的已注册说话人附加到提示中(Over-Regist)。

Prompts for LLMs
1. SD+ASR+LLM: 在 SD+ASR+LLM 流水线中,我们使用基于文本的 LLM 来纠正 SD+ASR 前端生成的说话人标签。所使用的 prompt 继承自先前研究。
SD+ASR+LLM 的 LLM Prompt:
You are a helpful assistant. In the speaker diarization transcript below, some words are potentially misplaced. Please correct those words and move them to the right speaker. Directly show the corrected transcript without explaining what changes were made or why you made those changes.
(你是一名有帮助的助手。下面的说话人分离转录中,某些词语可能被错误地分配到说话人。请纠正这些词语并将其移动到正确的说话人处。直接展示修正后的转录,不要解释修改内容或理由。)
2. SpeakerLM-ASR : 在 SpeakerLM 的第一阶段训练中,我们使用纯 ASR 数据来增强模型的 ASR 性能。该模型被称为 SpeakerLM-ASR。使用的 LLM prompt 如下:
SpeakerLM-ASR 的 LLM Prompt:
You are a helpful assistant. Transcribe the speech. <start>path to the input speech<end>
(你是一名有帮助的助手。请进行语音转写。<start>输入语音的路径<end>)
3. SpeakerLM: 在 SpeakerLM 中,LLM 的 prompt 会随着注册机制的不同而变化。这里给出了三种注册场景(No-Regist、Match-Regist 和 Over-Regist)的 prompt 设计。假设真实标注包含三位说话人:Mike、Lucy 和 Jack,则相应的 prompt 构造如下。
No-Regist(无注册)
You are a helpful assistant. Transcribe by roles. <start>path to the multi-speaker speech<end>
(你是一名有帮助的助手。请按角色进行转写。<start>多说话人语音的路径<end>)
Match-Regist(匹配注册)
You are a helpful assistant. Registered Speaker Embeddings:
Mike<start>path to the embedding of Mike<end>;
Lucy<start>path to the embedding of Lucy<end>;
Jack<start>path to the embedding of Jack<end>;
Transcribe by roles. <start>path to the multi-speaker speech<end> (你是一名有帮助的助手。已注册的说话人嵌入如下:
MikeMike 的嵌入路径;
LucyLucy 的嵌入路径;
JackJack 的嵌入路径;
请按角色进行转写。多说话人语音的路径
(说话人顺序没有特定要求。))
Over-Regist(过度注册)
You are a helpful assistant. Registered Speaker Embeddings:
Mike<start>path to the embedding of Mike<end>;
Lucy<start>path to the embedding of Lucy<end>;
Jack<start>path to the embedding of Jack<end>;
Andy<start>path to the embedding of Andy<end>;
Rose<start>path to the embedding of Rose<end>;
Frank<start>path to the embedding of Frank<end>;
Transcribe by roles. <start>path to the multi-speaker speech<end> (注:在此情况下,Andy、Rose 和 Frank 是来自其他会话的过度注册说话人。说话人顺序没有特定要求。)