
- 🔗【论文链接】https://arxiv.org/abs/2601.02702v1
- 🌐【论文主页】https://lemas-project.github.io/LEMAS-Project
- 💻【项目代码】https://github.com/LEMAS-Project
LEMAS 是一个大规模可扩展的多语种音频套件,提供带有单词级时间戳的多语种语音语料库(LEMAS-Dataset),涵盖 10 种主要语言(中文/英文/德文/法文/西班牙文/葡萄牙文/意大利文/俄文/印尼文/越南文),总量超过 150,000 小时。通过严格的对齐和基于置信度的过滤流程构建,LEMAS 支持多种生成范式,包括零样本多语种语音合成(LEMAS-TTS,0.3B 参数)和无缝语音编辑(LEMAS-Edit,0.3B 参数)。
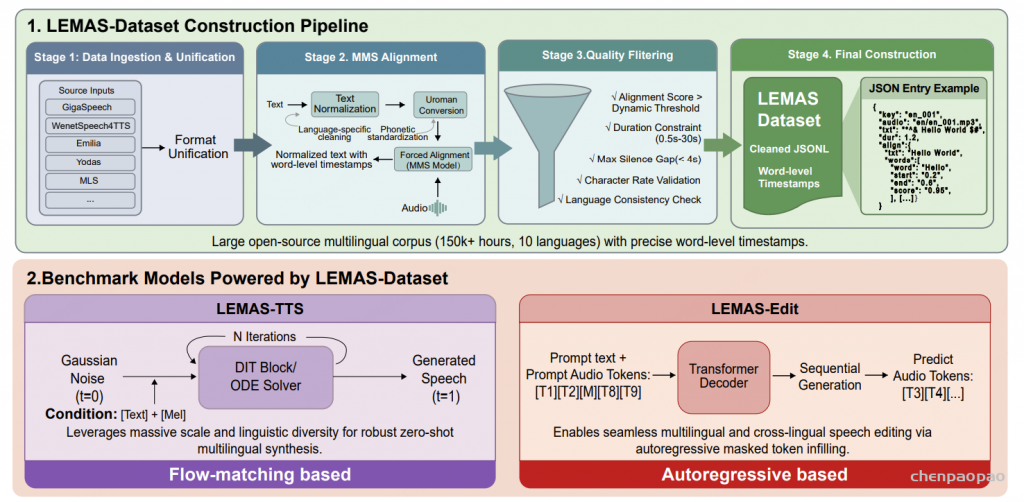
从真实环境(in-the-wild)音频中构建此类数据集面临着独特的挑战,因为传统的基于 HMM 的强制对齐工具(例如 MFA )在处理嘈杂、未分割的语音时往往表现不佳。针对这一问题,我们设计了一套鲁棒的多阶段处理流水线,利用 MMS 对齐器(MMS aligner) 提取词级时间戳,并且关键性地为每一个对齐后的词分配一个置信度分数。这种设计支持灵活且具备可靠性感知的数据过滤机制,使研究人员能够根据下游任务需求,在数据规模与对齐精度之间进行动态权衡,从而确保该数据集在对精度要求较高的应用场景中具有较高的实用价值。
Dataset Processing Pipeline:
数据接入与结构统一。
我们首先从多个公开可用的语音语料库中汇集音频–文本配对数据,包括 GigaSpeech(英语)、GigaSpeech2(印尼语、越南语)、WenetSpeech4TTS(中文,基于 VoiceBox)、Emilia(中文和英语,基于 VoiceBox)、MLS(英语、德语、法语、葡萄牙语、西班牙语、意大利语)、多语种 TEDx(德语、法语、葡萄牙语、西班牙语、意大利语)、Alcaim(葡萄牙语)、Golos(俄语)以及 Yodas(德语、法语、西班牙语、葡萄牙语、俄语、意大利语、印尼语、越南语)。这些数据源覆盖了多种录制场景,包括有声书、播客以及真实环境下的对话语音。
不同于保留各数据集特有的数据结构,我们将所有输入统一规范化为一致的数据表示形式,从而支持与语言无关的下游处理以及大规模自动化流程。
词级时间戳对齐:采用了由 torchaudio 提供的基于 wav2vec 的 CTC 对齐模型Multilingual MMS Forced Aligner。该模型在超过 23,000 小时、涵盖 1,100 多种语言的语音数据上进行了训练。在对齐处理之前,先对转录文本进行语种特异性归一化,再通过 Uroman 3 等工具将其罗马化 —— 该工具可将多种文字(如汉字、西里尔字母等)映射为统一的拉丁字母表示形式。这种设计摒弃了对语种专属发音词典的依赖,使对齐模型能够稳健处理生僻词、命名实体及句内语码转换现象。随后,MMS 对齐器会生成词汇级边界信息及词元级后验概率,为后续的质量控制环节奠定基础。
基于置信度的质量过滤:
仅仅对齐成功是不够的,只有具有高时间可靠性的对齐结果才适合用于生成式语音建模。因此,我们仅保留能够提取到词级对齐的样本,并基于对齐置信度和时间一致性应用一系列规则过滤器:
- 对齐置信度过滤(Alignment Confidence Filtering)
对于每条语音,我们根据对齐 token 的后验概率计算平均对齐置信度分数。为了适应不同语言和数据集的差异,我们使用数据集特定的阈值 [0.2,0.5],仅保留置信度高于对应阈值的样本。 - 时长与停顿约束(Duration and Pause Constraints)
- 移除长度小于 0.5 秒或大于 30 秒的语音,以确保与 TTS 训练兼容。
- 删除包含长时间未对齐区域或静默超过 4 秒的样本,因为这些通常表示分段或转录错误。
- 语速归一化(Speech Rate Normalization)
为排除异常快或慢的语音,我们对文本长度与音频时长的比值施加语言特定约束。对于每种语言 L,字符级比值 len(text)/duration必须落在经验确定的区间 [min_ratioL,max_ratioL]内,该区间由语料统计经验获得。 - 语言与字符验证(Language and Character Validation)
数据集仅限于十种目标语言:中文(zh)、英语(en)、俄语(ru)、西班牙语(es)、印尼语(id)、德语(de)、葡萄牙语(pt)、越南语(vi)、法语(fr)和意大利语(it)。- 所有转录文本必须属于上述语言之一。
- 含有不支持字符集、表情符号或过多非语言符号的样本将被移除,过滤规则依据语言特定字符集执行。
所有阈值均通过经验选择,以在数据规模与对齐精度之间取得平衡。值得注意的是,在预处理阶段未进行显式的语音增强或背景噪声去除。虽然许多 TTS 系统对声学干扰仍较为敏感,但我们有意保留了真实环境(in-the-wild)特征,期望更先进的生成模型能够更好地利用这种多样性。
