
- github:https://github.com/microsoft/VibeVoice
- paper:https://www.arxiv.org/pdf/2601.18184
- demo:https://aka.ms/VibeVoice-ASR
概述
VibeVoice-ASR 是微软开源的90亿参数统一语音识别模型,基于Qwen2 Decoder架构,采用64K token超长上下文窗口与7.5 Hz超低帧率语音分词技术,实现了ASR(自动语音识别)、说话人分离(Diarization)和时间戳标注(Timestamping)三大任务的端到端联合建模。该模型支持中英双语,可单次处理长达60分钟的连续音频,输出”Who-When-What”结构化转录结果,并通过自定义热词功能适配医疗、法律等专业领域
🕒 60 分钟单次处理:
不同于传统 ASR 模型需要将音频切分为多个短片段(这通常会导致全局上下文丢失),VibeVoice ASR 在 64K token 长度限制内 可直接接收最长 60 分钟的连续音频输入,从而在整段音频范围内保持说话人一致性和语义连贯性。
👤 自定义热词(Customized Hotwords):
用户可以提供自定义热词(例如人名、专业术语或背景信息)来引导识别过程,显著提升特定领域内容的识别准确率。
📝 丰富的结构化转写(Who / When / What):
模型联合完成 语音识别(ASR)、说话人分离(Diarization) 和 时间戳标注(Timestamping),输出结构化结果,清晰标注是谁在什么时间说了什么内容。
当前主流的长音频处理方法采用级联流水线架构,将连续语音切分为短片段(通常小于 30 秒)进行独立处理,尽管这种 “分而治之” 的策略具备实用性,但存在两个根本性缺陷:上下文碎片化与流水线复杂度。首先,片段独立处理会切断全局语义依赖,使模型丢失跨语句上下文信息,这对于消除同音词歧义、解决长对话中的指代消解问题是致命的。其次,传统系统将自动语音识别(ASR)、说话人分轨(Diarization)和时间戳标注视为相互独立的任务,由互不相关的模型分别处理。调和其输出往往需要复杂的启发式规则,进而导致错误传播:一旦分段或说话人分轨出现错误,就会污染最终转录结果。 为弥补这一差距,我们提出 VIBEVOICE-ASR,一个面向高保真长语音理解的统一通用框架。

Method
模型
VibeVoice-ASR采用声学-语义双编码器架构:
- 声学编码器:基于VAE结构,将16kHz音频压缩为7.5 Hz离散token(码本大小8K),捕捉音色、语调等声学细节
- 语义编码器:类似HuBERT架构,提取语音的语义表示,确保内容理解准确性
双编码器特征融合后,通过声学连接器(Acoustic Connector)映射至LLM语义空间,实现声学信息与语言知识的深度耦合。
传统梅尔频谱以50 Hz帧率提取特征,1小时音频产生18万帧,超出Transformer处理能力。VibeVoice创新性地采用7.5 Hz帧率,压缩比高达2133:1,将长音频转化为LLM可处理的token序列。这种超低帧率设计不仅解决长度瓶颈,更通过连续语音分词器保留韵律与语气信息,为后续TTS任务提供统一表征基础。
这种超低帧率至关重要,一小时连续音频可换算为:3600 秒×7.5 token/秒=27000 个 token这一长度可以轻松放入现代大语言模型的单遍上下文窗口中。
大语言模型主干( Qwen 2.5-7B)处理,自回归地生成目标序列。
Pre-training
预训练数据英文占比最高66%,中文占比 14%,覆盖了 50 余种语言。该流水线包含三个阶段:分段与转录、说话人分轨以及质量过滤。
首先,利用 Silero 语音活动检测(VAD)将长录音切分为最长 30 秒的片段,再使用 Whisper-large-v3-turbo 进行转录,得到带标点的文本与词级时间戳;通过在标点结束时间戳(如句号、问号、感叹号)处进行切分,进一步优化分段边界,使其与说话人轮次更好对齐。 随后,使用 WeSpeaker 工具包 中的 vblinkp 模型执行说话人分轨:从重叠帧(窗口 1.5 秒,步长 0.75 秒)中提取说话人嵌入,使用 HDBSCAN进行聚类,并将质心余弦相似度大于 0.67 的簇进行合并优化,得到最终的说话人轮次标注。
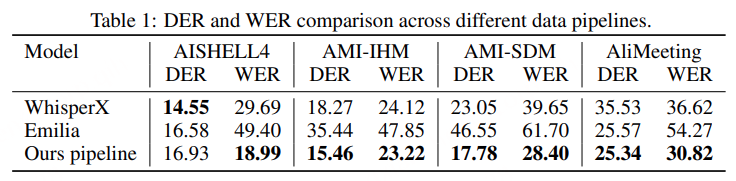
最后,为保证标注可靠性,我们使用另一套 ASR 模型 对片段重新转录;若超过 30% 的片段词错误率(WER)高于 20%,或语音时长占总时长不足 60%,则将该条录音丢弃。 为验证数据处理流水线的有效性,我们将其与两种广泛使用的音频处理流水线 WhisperX和 Emilia 进行了对比实验。实验在三个常用的公开多人会议数据集上开展:AMI 、AliMeeting 和 AISHELL-4 ,并同时报告说话人分轨错误率(DER)与分轨不变词错误率(WER)。为保证公平对比,我们关闭了 Emilia 中的数据过滤模块,因其默认配置会剔除大量音频样本。
如表 1 所示,在大多数测试数据集上,本文提出的数据流水线相比两个基线系统均能持续获得更低的 DER 与 WER。结果表明,在不同声学环境下,我们的流水线在分段、说话人分轨与转录任务上均具备更稳健的性能。
对大语言模型的输入序列长度采用了课程学习策略,从 8192 个 Token 逐步增加到 65536 个 Token。
SFT
构建了四类高质量数据进行微调:
- 标准语音与音乐数据集:提升多说话人识别与音乐场景鲁棒性;
- 上下文感知合成数据:用 GPT‑5 生成带上下文提示的中英混流对话脚本,再通过 VIBEVOICE 合成约 6000 小时高质量音频;
- 长语音修复数据:用 GPT‑5 对碎片化转录做全局语义校正,并标注非语音片段以抑制幻觉;
- 最后按 0.5: 0.1: 0.1: 0.3 的比例混合训练,让模型在常规识别、音乐、上下文感知、长语音理解上能力更均衡。
流式处理与内存优化
通过VibeVoiceTokenizerStreamingCache缓存机制,模型在处理超长音频时采用分块编码策略:将60分钟音频切分为60秒块流式处理,缓存卷积层状态,最终统一采样确保块间一致性。配合FlashAttention-2技术,内存复杂度从O(N²)降至O(N),使得90亿参数模型可在单卡24GB显存环境下运行。
结果

在所有测试数据集上,VIBEVOICE‑ASR 在 DER 和 tcpWER 指标上均持续优于 Gemini‑2.5‑Pro 与 Gemini‑3‑Pro,表明其说话人建模能力更强、说话人轮次时间对齐精度更高。 在更直接反映模型说话人一致性保持能力的 cpWER 指标上,我们的模型在 16 个评测配置中的 11 个取得最优性能,显著优于两个 Gemini 版本,说明在多说话人场景下说话人区分效果更可靠。 在 WER 方面,我们的模型在 16 个配置中的 8 个取得最低错误率,在其余数据集上仅出现小幅下降。
Limitations
监督微调中的多语言遗忘:虽然预训练覆盖了 50 余种语言,但监督微调阶段主要聚焦于英语、中文及语码切换数据。因此,对于未出现在指令微调中的低资源语言,模型性能可能出现下降。
重叠语音问题:当前架构生成序列化输出流,并未显式处理重叠语音(即 “鸡尾酒会问题”)。在多人同时说话的场景中,模型倾向于转录主要说话人内容,可能丢失次要信息。未来版本将探索带语音分离感知的建模方式来应对这一挑战。
对模型设计和数据的思考
多任务的模型设计
虽然模型命名为VibeVoice-ASR,但它并非单纯的语音转文字模型。VibeVoice-ASR集成了说话人日志、时间戳以及部分声音事件检测功能。
这样的多任务设计符合大模型时代的技术趋势,也契合未来的用户需求。如今,仅实现语音转录已远远不够。无论是底层模型还是上层应用,乃至用户对智能体验日益提升的期待,都要求我们从语音数据中提取更丰富的信息。用户对产品的追求不再停留在基础功能,而更多地转向情感价值与类人体验。
关注声音特性
声音在机器理解用户方面的价值被严重低估了。理解声音,是通往“世界模型”、理解世界不可或缺的一环。
遗憾的是,目前除了Gemini,我还没看到能与之比肩的系统。我也认为这是谷歌布局未来重要的一步。(不得不提一句,至于那些号称超越的,或许在某些测试集和指标上能实现超越,这一点我并不否认。)
VibeVoice-ASR模型其实让我有所期待。至少,它是开源模型中明确对声纹进行建模的(另外还有阿里的 SpeakerLM ,也是对声纹进行建模识别),并且在我真实测试集(家庭录音,包括男性、女性、儿童)中,在区分度较大的场景下是可用的。
- “建模声纹很难吗?”“是的。”
- “声纹识别现在做得很好了吗?”“并没有。”
声纹作为声音的底层属性,与语音语义有很大不同。识别一个人的声纹,对人类来说也并非易事。我们觉得容易,大多是因为我们接触的声纹往往是“已注册”的。从模型实现来看,声纹的做法看似简单,但实际效果并不理想,原因有多方面:
极易受环境干扰
与ASR相比,声纹更易受声学环境干扰。训练数据的覆盖范围、环境噪声、信道差异,以及注册与使用条件的不一致,都会影响最终效果。
声纹具有时变性
声纹会随时间发生漂移,比如儿童的声音变化最快,不同儿童之间的声音区分也很困难,成人的声音也会因状态(如感冒、情绪)而改变。
声纹数据自动标注困难
从数据标注角度看,由于历史上声纹模型效果一般,再加上上述难点,导致自动化标注很难做到准确。
幻觉问题较为突出
在体验VibeVoice-ASR模型的过程中,发现最明显的问题是幻觉。测试中,注意到一个特别的现象:数据中孩子的哭声极容易触发模型的幻觉。

这背后最主要的原因,应该还是接下来要谈的数据覆盖问题。
长度真的那么重要吗?
对于文本大模型,长度等于上下文,上下文窗口的确很重要。但对于语音模型,特别是偏重转录的模型,在当前阶段,长度是否真的如此关键,我持保留态度。
VibeVoice-ASR提出的理由是:当前的系统存在两个根本性局限:上下文碎片化(Context Fragmentation)与流水线复杂度(Pipeline Complexity)。首先,独立处理各个片段会割裂全局语义依赖,导致模型无法追踪跨句子的上下文信息。这在处理长对话时尤为致命——例如,难以消解同音词歧义,或无法正确解析跨句的指代关系。其次,传统系统通常将自动语音识别(ASR)、说话人日记化(Speaker Diarization)和时间戳标注视为相互独立的任务,由彼此分离的模型分别处理。要协调这些模型的输出,往往需要依赖复杂的启发式规则,这容易引发误差传播:一旦分段或说话人划分环节出现错误,最终的转写结果就会受到污染。
首先,关于上下文断裂问题——纯音频的上下文真能解决这个问题吗? 或许能部分缓解,但对多数场景来说,可能并非至关重要。文本层面的上下文或许已足以提升准确率。
其次,工程复杂度方面,文中提到的说话人日志优势我很认同,但这个和长度其实关系不是特别大,我认为更多的优势来自于识别+说话人的联合建模。短句说话人日志的确很困难,但几分钟的数据进行说话人相关的工作也没有太大问题。如果可以把效果做好,后续通过一个混淆矩阵进行相同说话人的聚类。如果长语音识别确实可以做的好,那么降低系统复杂度的优势肯定是有的。
综上所述,在当前条件尚不成熟的情况下,过度强调长度或许并不是最优先的。相比长度,我们更应关注模型的稳定性与准确性。 当然,如果能处理更长的音频,那自然是更好的。
“垃圾”数据也有价值
从我测试中遇到的幻觉问题,结合当前主流数据清洗流程的做法,会发现一个现象:
人们常用多个模型交叉验证,筛选出“有用且正确”的数据。
什么是“有用且正确”的数据?如果一条数据包含文字,且多个模型识别结果一致,就被认为是有价值且标注正确的。那么,那些被过滤掉的数据,其价值又该如何看待?
事实上,它们的价值在今天更应被重视。原因如下:
幸存者偏差
这种方式筛选出的数据,都是以往模型基础上的“幸存者”,数据质量虽高,但对模型来说难度较低。换句话说,大量这类数据对模型能力的提升并无太大增益。如果模型只用这类数据训练,那么无论输入什么,哪怕是人耳都难以听清的语音,模型都可能用最大似然的方式“猜”一个最可能的结果,而不是“承认困难”。一个懂得“示弱”的模型,或许也有其价值。
“垃圾”数据的价值
所谓“垃圾数据”,正是那些被自动标注流程过滤掉的数据,它们的价值应当被重新审视。比如我测试数据中的哭声片段,很可能会被清洗流程过滤掉。再加上这类声音重复性强,更容易导致模型产生幻觉。
在强化学习中,也应该加强对“坏”数据如何给予正确反馈的机制。