

背景
论文来自 Open AI 2021 年提出的一个成果,相关可参考信息: github、 paper、主页 。 之前其实并不太了解多模态预训练领域的成果,最近看到了这篇质量很高的成果。
Hugging Face: https://huggingface.co/openai/clip-vit-base-patch32(预训练模型库)
效果
我们可以运行这colab,该作者将 Unsplash 的所有素材计算了 clip image embedding ,然后使用 clip word embedding 进行配图。
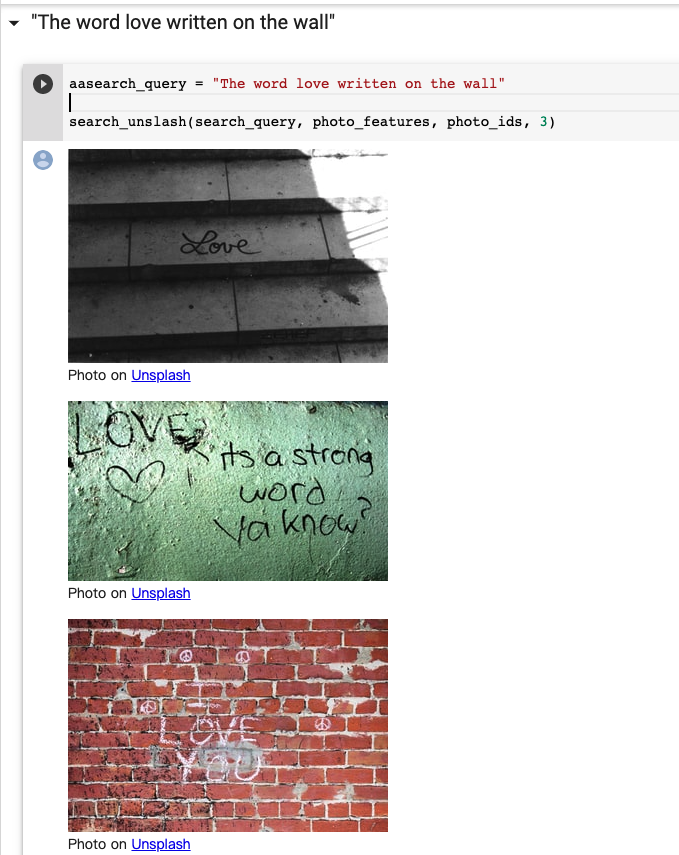
效果看起来似乎不错,几乎实现了通过一句话就找到合适的图片。不可否定,会存在大量的badcase。但是在不需要fine-tune/下游任务,直接zero-shot得到的embedding可以实现这样的效果已经很厉害了。
作者团队来自 OPEN AI
CLIP工作:
1 方法简单,效果好
2 迁移学习能力强(已训练好的模型,可以在任意数据集上取得好效果)
Q1 CLIP 是什么?how 做zero-shot(一种分类方式)?
Q2 CLIP How 预训练?
利用信号(来自自然语言处理)训练一个模型(迁移效果好)
Q3 经过预训练能得到什么?
A3 仅得到图片或文本的特征,没有在分类任务上继续做训练或微调。即CLIP没有分类头。
Q4 没有分类头,how 做推理?
A4 利用自然语言的方法—prompt template;
将1000个类,生成一个1000个句子(object),
例子:plane 变成 object
1000个句子通过文本编码器(text-Encode)生成1000个特征。
Q5 直接从1000个类里面抽取特征也可以, why 还要进行Prompt- template ?
A5 在预训练时,model 看到的是sample-pair,若在推理时,把所有文本变成一个单词(word),导致model看到的东西和预训练时不一样,导致识别效果稍下降。
Q6 如何将1000分类变成 1000个句子(object)?why 这样做?
A6 2个方法:prompt engineering 和 prompot ensambol;
提高模型准确率,且不需要重新训练模型
Q7 prompt template 操作之后要干嘛?
A7 input 图片,经过image_Encode 得到图片特征,利用image_feature 和 text-feature 计算相似性,挑出值(最相似),进而完成分类任务。
Q8 how 理解分类任务?
A8 judge image 中有哪些物体
Q9 text and image 可以改吗?
A9 yes (all of anything)
Q10 若用imageNet做训练,input三轮车(image),why 得到车,而不是,三轮车?
A10 因为,imageNet 无法实时更新已有类别。
但CLIP可以实时更新,故 imput = output。
这也是CLIP的强大之处,彻底摆脱了categoricel label 限制。

为了提高model泛化性,作者提出新办法,从 text 中提取监督信号。(正是有了监督信号(覆盖范围广)的存在,model 的泛化能力得到提高)作者利用4亿 text-image-pair-dataset ,选择自监督训练方式,进而训练模型。
CLIP 利用多模态对比学习完成训练,并可以做物体分类(即prompt),这种分类不限于已有类别,可扩展到新类别。(即当前学到的model,可以直接在 downstream tasks(下游任务)上做推理。
2017年有人研究,但是影响力小,效果差:
主要有3个工作(均基于transformer)和CLIP像,但有区别:VIrTex:用自回归预测方式,做model预训练,ICMLM :用完型填空方式,做model预训练,ConVIRT:和CLIP类似,但仅在医疗图像上做实验。但由于data 和 model规模小,所以效果不好。
利用自然语言的监督信号,来训练好的视觉模型。在自监督学习(完型填空)的范式下,NLP可以利用(取不尽)的文本监督信号。用此方法训练出的模型,简单,泛化力强,为多模态训练铺路。
why 用自然语言监督信号训练视觉模型?
1 无需标注这些数据(数据规模变大)
2 此时监督信号是文本(不是n选1 的标签),意味着input,output 自由度大了很多.
3 因为image-text-pair数据,model所学特征不单是视觉特征,而是多模态特征。当image和语言联系在一起,便容易做zero-shot迁移学习。
若仅做单模态自监督学习,无论是单模态对比学习(MOCO),还是单模态掩码学习(MAE),model仅学到视觉特征,无法和自然语言联系在一起,依旧很难做zero-shot的迁移。需要大量的image-text-pair(4亿个Image-text-pair)
总结:用 文本监督信号来训练视觉model 这种做法很有潜力。
整个训练过程:
给定一张image,来预测文本,会产生较大歧义(即可能性太多);若逐字句预测文本,太难了。会导致模型训练慢因此采用对比学习,让 model 判断,image 和 text 是否配对。把 ” 训练任务 “ 换成 ” 对比任务 “ ,训练效率提高4倍
2个输入:image 和 text归一化,投射层:将单模态变成多模态,获得 n 个图像的特征,n 个文本的特征。计算 image-feature 和 text-feature相似度。利用相似度做分类。利用交叉熵目标函数计算loss

细节:
1 由于收集数据大,model 不存在 overfitting
简化了工作:当训练CLIP – model时,对应的 image-Encode 和 text-Encode 无需进行预训练
2 在多模态训练中,投射时,用线性投射层,
非线性投射层(作者推测,适配纯 Image 单模态学习),带来10个点的性能提升
3 使用 ” 随即裁减 “ 进行数据增强
4 数据集和 model 太大,不好调参
5 temperature parm(极重要超参数)稍调,model 性能会提高很多 但作者,将其设置成,可学习的标量

模型选择和参数设置:
视觉方面:
训练8个model;
ResNet = 5个,VIT = 3个
残差网络变体ResNet50*4:*16:*64:用 efficientNet-style 方法 将input-image 大小,channel宽度,model-depth 做微调
针对 transformer-model,作者选择数据集 VIT-B/32:/16:/64(阿拉伯数字表示patch大小)
文本方面:transformer
all-model 训练了epoch = 32;Adam optimizer优化器;手动调整超参数,用ResNet-50作为超参搜索,为了快速调参(训练epoch = 1)训练时:选用 batch-size = 32768(很大)(此model在很多机器上做分布式训练)
CLIP 文章的核心 = Zero-shot Transfer
作者研究迁移学习的动机:之前自监督or无监督的方法,主要研究 frature 学习的能力,model的目标是学习泛化性能好的特征,虽然学习到good-feature,但down-work中,还是需要有标签数据做微调。作者想仅训练一个model,在down-work中不再微调。
衡量model 学到的feature 好不好的方法有主要有2种:第一种:linear:冻结训练好的model,再训练一个分类头。第二种:微调:把整个网络放开,做end-to-end的学习。微调的优点: 灵活、当down-work数据集大,微调效果好。但这里作者使用只训练liner分类头: CLIP本就用来研究更数据集无关的训练方式,若用 “ 微调 “ 方法,无法判断预训练model效果如何。(因为,如果预训练model效果不好,经过在down-work上做微调,会导致最终结果好。)
CLIP这么强大,它有什么缺点?
平均来看,CLIIP可以和机械模型(ResNet-50(在ImageNet上训练))持平
若继续增加数据集和model规模,CLIP性能可以继续提高,但是代价很大(需提高计算和数据的高效性)
zreo-shot结果并不好
1 在细分类数据集上,CLIP效果低于(有监督训练)ResNet-50(极限网络)
2 CLIP无法处理抽象概念原因:CLUP无法区分 what is 异常?what is 安全?例如:数一数图片中的物体个数;在视频中,区分这一帧是异常还是非异常;作者提出:在很多领域,CLIP性能和瞎猜差不多
3 若数据集中的data 已经 out-of-distribution,那么CLIP-model泛化照样差;例子:在MNIST数据集上,CLIP准确率仅有88% 。推测原因:作者收集的数据集有4亿个样本,但没有和MINIS长得像的,所以MINIS数据集对于CLIP来说就是out-of-distribution数据集
评价
创新度高1 打破固定类别标签做法2 放飞视觉model训练过程3 引发后续大量工作
有效性高1 大数据集,效果好2 泛化性能好3 zero-shot性能超过人类