paper:https://arxiv.org/pdf/2111.09883.pdf
Swin Transformer V2: Scaling Up Capacity and Resolution:扩展容量和分辨率
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
本文介绍这篇文章是 Swin Transformer 系列的升级版 Swin Transformer v2。Swin Transformer 是屠榜各大CV任务的通用视觉Transformer模型,它在图像分类、目标检测、分割上全面超越 SOTA,在语义分割任务中在 ADE20K 上刷到 53.5 mIoU,超过之前 SOTA 大概 4.5 mIoU!可能是CNN的完美替代方案。除此之外,本文一并介绍 Swin MLP 的代码实现,Swin Transformer 作者们在已有模型的基础上实现了 Swin MLP 模型,证明了 Window-based attention 对于 MLP 模型的有效性。
Swin Transformer Block 有两种,大致结构和 Transformer Block 一致,只是内部 attention 模块分别是 Window-based MSA 和 Shifted Window-based MSA。Window-based MSA 不同于普通的 MSA,它在一个个 window 里面去计算 self-attention,计算量与序列长度 N=hw 成线性关系。Window-based MSA 虽然大幅节约了计算量,但是牺牲了 windows 之间关系的建模,不重合的 Window 之间缺乏信息交流影响了模型的表征能力。Shifted Window-based MSA 就是为了解决这个问题。将下一层 Swin Transformer Block 的 Window 位置进行移动,得到不重合的 patch。
在 Swin Transformer 的基础上,研究人员进一步开发出了用于底层复原任务的 SwinIR
Swin Transformer v2 原理分析:
Swin Transformer 提出了一种针对视觉任务的通用的 Transformer 架构,MSRA 进一步打造了一个包含3 billion 个参数,且允许输入分辨率达到1560×1560的大型 Swin Transformer,称之为 SwinV2。它在多个基准数据集 (包含 ImageNet 分类、COCO 检测、ADE20K 语义分割以及Kinetics-400 动作分类) 上取得新记录,分别是 ImageNet 图像分类84.0% Top-1 accuracy,COCO 目标检测63.1/54.4 box / mask mAP,ADE20K 语义分割59.9mIoU,Kinetics-400视频动作识别86.8% Top-1 accuracy。
Swin Transformer v2 的核心目的是把 Swin Transformer 模型做大,做成类似 BERT large 那样包含 340M 参数的预训练大模型。在 NLP 中,有的预训练的大模型,比如 Megatron-Turing-530B 或者 Switch-Transformer-1.6T,参数量分别达到了530 billion 或者1.6 trillion。
另一方面,视觉大模型的发展却滞后了。 Vision Transformer 的大模型目前也只是达到了1-2 billion 的参数量,且只支持图像识别任务。部分原因是因为在训练和部署方面存在以下困难:
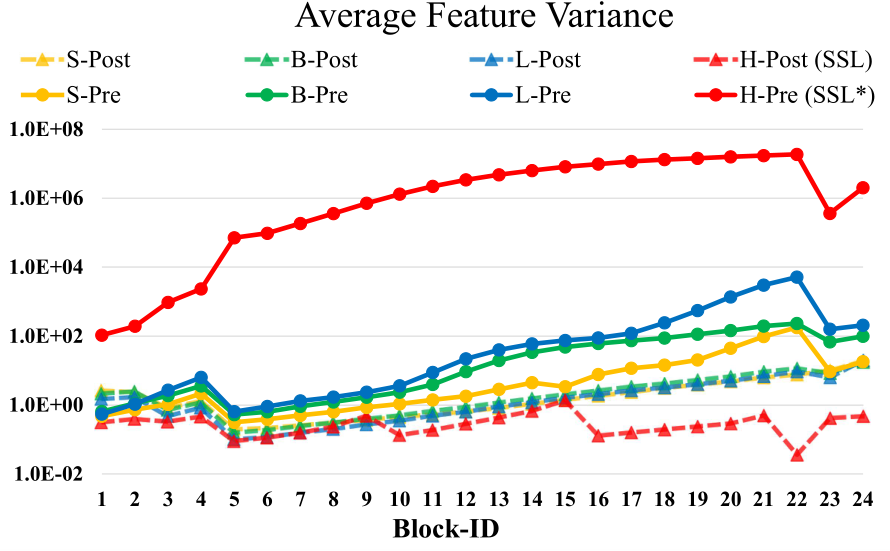
- 问题1:训练中的不稳定性问题。在大型模型中,跨层激活函数输出的幅值的差异变得更大。激活值是逐层累积的,因此深层的幅值明显大于浅层的幅值。如下图1所示是扩大模型容量时的不稳定问题。 当我们将原来的 Swin Transformer 模型从小模型放大到大模型时,深层的 activation 值急剧增加。最高和最低幅值之间的差异达到了104。当我们进一步扩展到一个巨大的规模 (658M 参数) 时,它不能完成训练,如图2所示。

- 问题2:许多下游视觉任务需要高分辨率的图像或窗口,预训练模型时是在低分辨率下进行的,而 fine-tuning 是在高分辨率下进行的。针对分辨率不同的问题传统的做法是把位置编码进行双线性插值 (bi-cubic interpolation),这种做法是次优的。如下图3所示是不同位置编码方式性能的比较,当我们直接在较大的图像分辨率和窗口大小测试预训练的 Imagenet-1k 模型 (分辨率256×256,window siez=8×8) 时,发现精度显着下降。

- 问题3:当图像分辨率较高时,GPU 内存消耗也是一个问题。
为了解决以上几点问题,作者提出了:
方法1:post normalization 技术:解决训练中的不稳定性问题。
把 Layer Normalization 层放在 Attention 或者 MLP 的后面。这样每个残差块的输出变化不至于太大,因为主分支和残差分支都是 LN 层的输出,有 LN 归一化作用的限制。如上图1所示,这种做法使得每一层的输出值基本上相差不大。在最大的模型训练中,作者每经过6个 Transformer Block,就在主支路上增加了一层 LN,以进一步稳定训练和输出幅值。
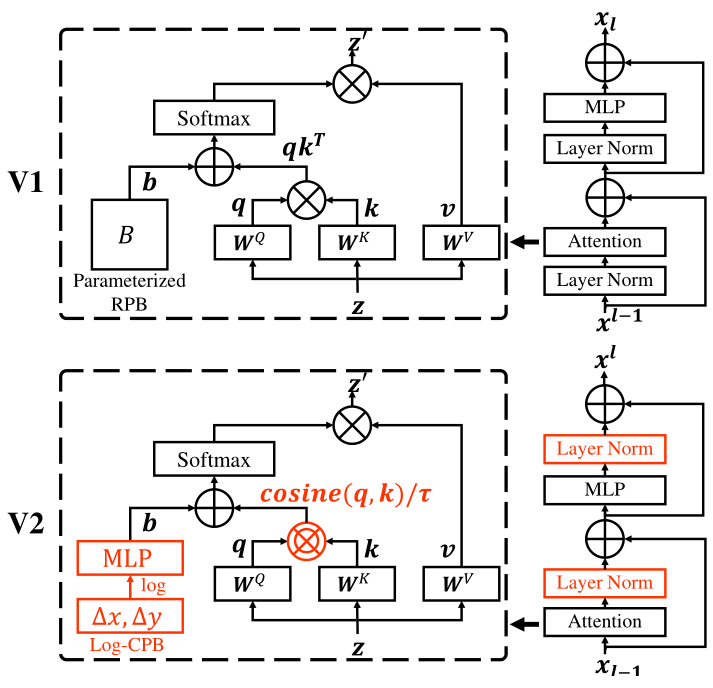
方法2:scaled cosine attention 技术:解决训练中的不稳定性问题。
原来的 self-attention 计算中,query 和 key 之间的相似性通过 dot-product 来衡量,作者发现这样学习到的 attention map 往往被少数像素对所支配。所以把 dot-product 改成了 cosine 函数,通过它来衡量 query 和 key 之间的相似性。
\[\operatorname{Sim}\left(\mathbf{q}i, \mathbf{k}_j\right)=\cos \left(\mathbf{q}_i, \mathbf{k}_j\right) / \tau+B{i j}\]
式中, \(B_{i j}\) 是下面讲得相对位置编码, \(\tau\) 是可学习参数。余弦函数是 naturally normalized,因 此可以有较温和的注意力值。
方法3:对数连续位置编码技术:解决分辨率变化导致的位置编码维度不一致问题。
- 该方法可以 更平滑地传递在低分辨率下预先训练好的模型权值,以处理高分辨率的模型权值。
我们首先复习下 Swin Transformer 的相对位置编码技术。
\[\operatorname{Attention}(Q, K, V)=\operatorname{SoftMax}\left(Q K^T / \sqrt{d}+B\right) V\]
式中, \(B \in \mathbb{R}^{M^2 \times M^2}\) 是每个 head 的相对位置偏差项 (relative position bias),\(Q, K, V \in \mathbb{R}^{M^2 \times d}\) 是 window-based attention 的 query, key 和 value。 window 的大小。
作者引入对数空间连续位置偏差 (log-spaced continuous position bias),使相对位置偏差在不同的 window 分辨率之下可以较为平滑地过渡。
方法4:节省 GPU memory 的方法:
1 Zero-Redundancy Optimizer (ZeRO) 技术:
来自论文:Zero: Memory optimizations toward training trillion parameter models
传统的数据并行训练方法 (如 DDP) 会把模型 broadcast 到每个 GPU 里面,这对于大型模型来讲非常不友好,比如参数量为 3,000M=3B 的大模型来讲,若使用 AdamW optimizer,32为的浮点数,就会占用 48G 的 GPU memory。通过使用 ZeRO optimizer, 将模型参数和相应的优化状态划分并分布到多个 GPU 中,从而大大降低了内存消耗。训练时使用 DeepSpeed framework,ZeRO stage-1 option。
2 Activation check-pointing 技术:
来自论文:Training deep nets with sublinear memory cost
Transformer 层中的特征映射也消耗了大量的 GPU 内存,在 image 和 window 分辨率较高的情况下会成为一个瓶颈。这个优化最多可以减少30%的训练速度。
3 Sequential self-attention computation 技术:
在非常大的分辨率下训练大模型时,如分辨率为1535×1536,window size=32×32时,在使用了上述两种优化策略之后,对于常规的 GPU (40GB 的内存)来说,仍然是无法承受的。作者发现在这种情况下,self-attention 模块构成了瓶颈。为了解决这个问题,作者实现了一个 sequential 的 self-attention 计算,而不是使用以前的批处理计算方法。这种优化在前两个阶段应用于各层,并且对整体的训练速度有一定的提升。
在这项工作中,作者还一方面适度放大 ImageNet-22k 数据集5倍,达到7000万张带有噪声标签的图像。 还采用了一种自监督学习的方法来更好地利用这些数据。通过结合这两种策略,作者训练了一个30亿参数的强大的 Swin Transformer 模型刷新了多个基准数据集的指标,并能够将输入分辨率提升至1536×1536 (Nvidia A100-40G GPUs)。此外,作者还分享了一些 SwinV2 的关键实现细节,这些细节导致了 GPU 内存消耗的显着节省,从而使得使用常规 GPU 来训练大型视觉模型成为可能。 作者的目标是在视觉预训练大模型这个方向上激发更多的研究,从而最终缩小视觉模型和语言模型之间的容量差距。
不同 Swin V2 的模型配置:
- SwinV2-T: C= 96, layer numbers ={2,2,6,2}
- SwinV2-S: C= 96, layer numbers ={2,2,18,2}
- SwinV2-B: C= 128, layer numbers ={2,2,18,2}
- SwinV2-L: C= 192, layer numbers ={2,2,18,2}
- SwinV2-H: C= 352, layer numbers ={2,2,18,2}
- SwinV2-G: C= 512, layer numbers ={2,2,42,2}
对于 SwinV2-H 和 SwinV2-G 的模型训练,作者每经过6个 Transformer Block,就在主支路上增加了一层 LN,以进一步稳定训练和输出幅值。
Experiments
模型:SwinV2-G,3B parameters
Image classification
Dataset for Evaluation:ImageNet-1k,ImageNet-1k V2
Dataset for Pre-Training:ImageNet-22K-ext (70M images, 22k classes)
训练策略:分辨率使用192×192,为了节约参数量。2-step 的预训练策略。首先以自监督学习的方式在 ImageNet-22K-ext 数据集上训练 20 epochs,再以有监督学习的方式在这个数据集上训练 30 epochs,SwinV2-G 模型在 ImageNet-1k 上面达到了惊人的90.17%的 Top-1 Accuracy,在 ImageNet-1k V2 上面也达到了惊人的84.00%的 Top-1 Accuracy,超过了历史最佳的83.33%。
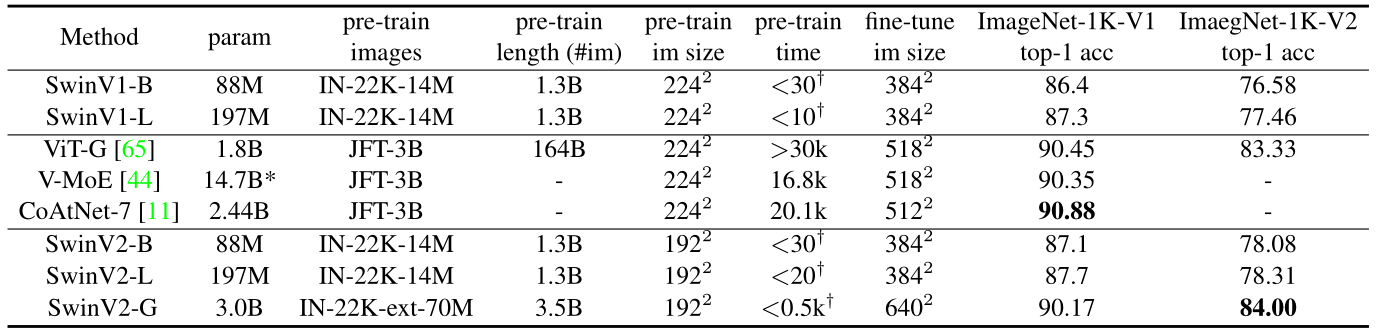
同时,使用 Swin V2 的训练策略以后,Base 模型和 Large 模型的性能也可以进一步提升。比如 SwinV2-B 和 SwinV2-L 在 SwinV1-B 和 SwinV1-L 的基础上分别涨点0.8%和0.4%,原因来自更多的 labelled data (ImageNet-22k-ext, 70M images), 更强的 Regularization,或是自监督学习策略。
Object detection,Instance Segmentation
Dataset for Evaluation:COCO
Dataset for Pre-Training:Object 365 v2
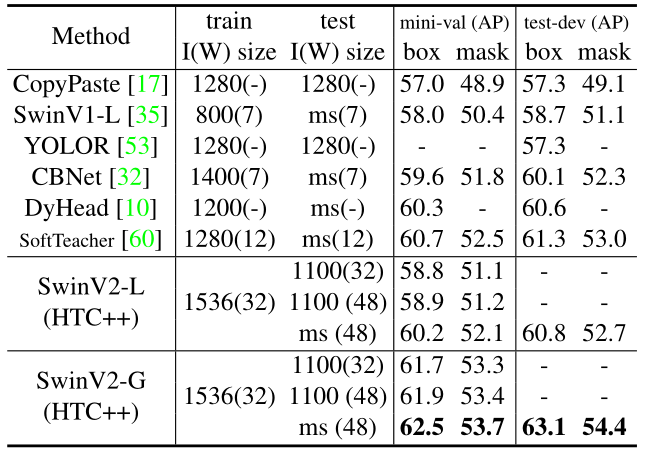
如下图6所示 SwinV2-G 模型与之前在 COCO 目标检测和实例分割任务上取得最佳性能模型进行了比较。SwinV2-G 在 COCO test-dev 上实现了 63.1/54.4 box/max AP,相比于 SoftTeacher (61.3/53.0) 提高了 + 1.8/1.4。
Semantic segmentation
Dataset for Evaluation:ADE20K
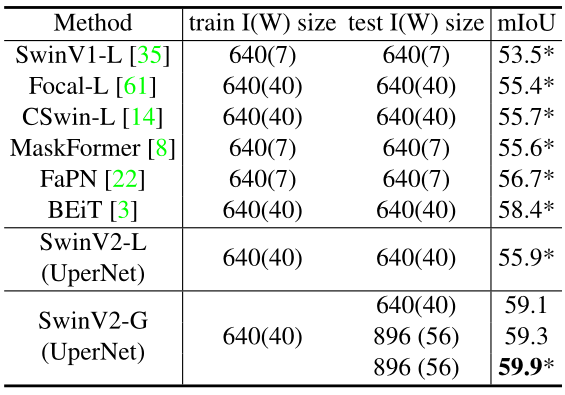
如下图7所示 SwinV2-G 模型与之前在 ADE20K 语义分割基准上的 SOTA 结果进行了比较。Swin-V2-G 在 ADE20K val 集上实现了 59.9 mIoU,相比于 BEiT 的 58.4 高了 1.5。
Video action classification
Dataset for Evaluation:Kinetics-400 (K400)
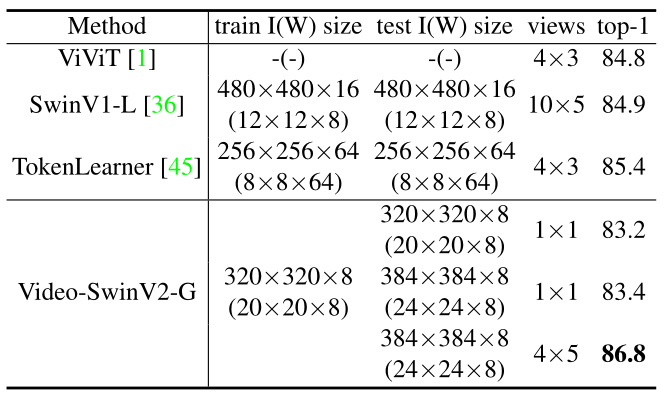
如下图8所示 SwinV2-G 模型与之前在 Kinetics-400 动作分类基准上的 SOTA 结果进行了比较。可以看到,Video-SwinV2-G 实现了 86.8% 的 top-1 准确率,比之前的 TokenLearner 方法的 85.4% 高出 +1.4%。
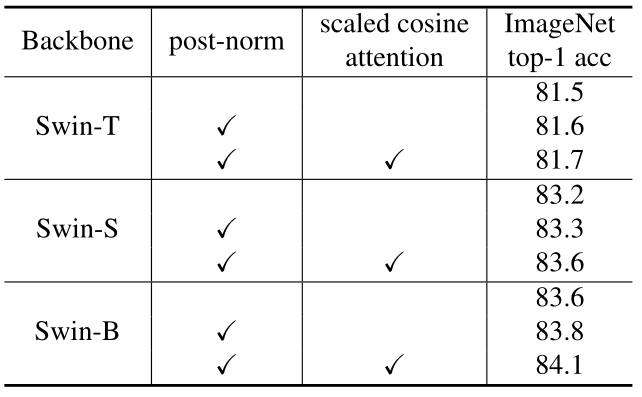
对比实验:post-norm 和 scaled cosine attention 的作用
如下图9所示,这两种技术均能提高 Swin-T,Swin-S 和 Swin-B 的性能,总体提高分别为 0.2%,0.4% 和 0.5%。说明该技术对大模型更有利。更重要的是,它们能让训练更稳定。对于 Swin-H 和 Swin-G 模型而言,自监督预训练使用原来的 Swin V1 无法收敛,而 Swin V2 模型训练得很好。