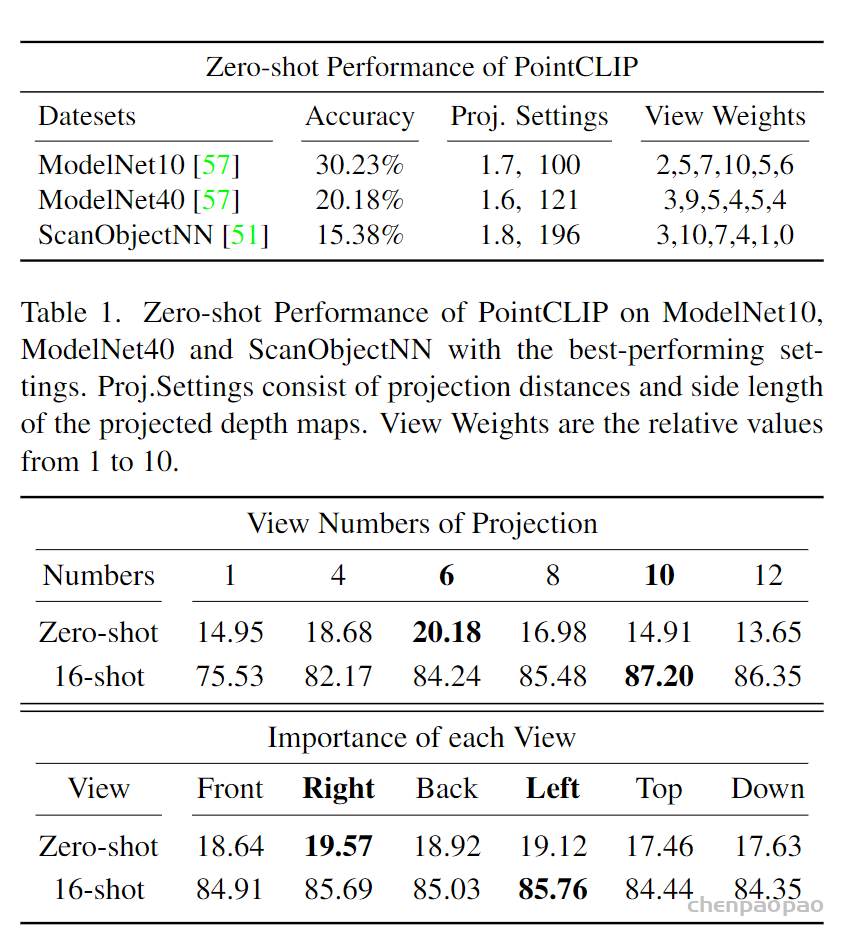
论文: CVPR2022 PointCLIP: Point Cloud Understanding by CLIP
代码:https://github.com/ZrrSkywalker
本文提出PointCLIP:第一个将 CLIP 应用于点云识别的工作,它将2D预训练的知识迁移到3D领域,可在没有任何 3D 训练的情况下对点云进行跨模态零样本识别。
在本文中,我们通过提出 PointCLIP 来确定这种设置是可行的,它在 CLIP 编码的点云和 3D 类别文本之间进行对齐。
因为重新训练clip的代价太大(原始clip的训练数据 有4yi对文本图像对),因此没法去修改clip的模型结构,因此也就意味之模型的输入:text-image形式。因此作者将三d点云数据经过不同视角的渲染,变成M个RGB的二维maps,送如encoder中并获得M个特征,通过与对应的文本特征做一个相似度,来确定 当前的点云类别。
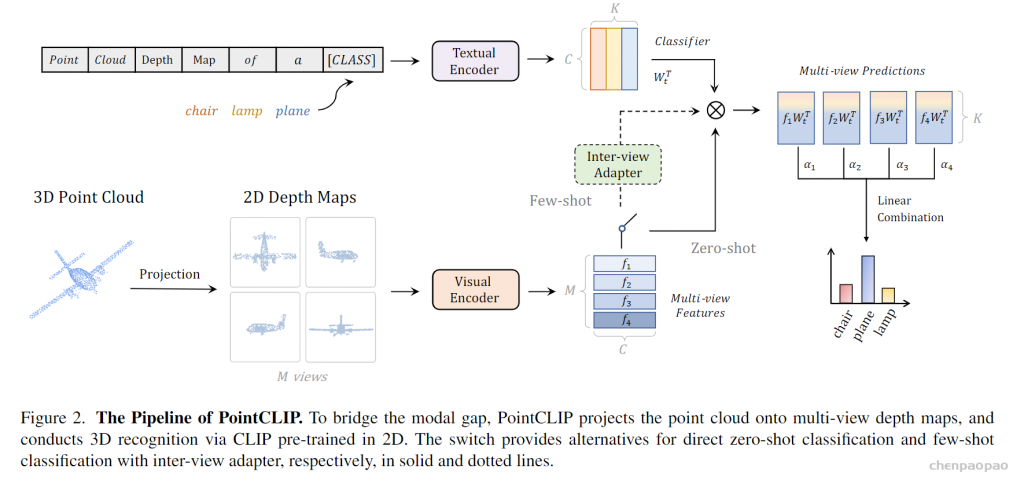
具体来说,我们通过将点云投影到多视图深度图中而不进行渲染来编码点云,并聚合视图方式的零样本预测以实现从 2D 到 3D 的知识迁移。最重要的是,我们设计了一个视图间适配器,以更好地提取全局特征,并将从 3D 中学到的小样本知识自适应地融合到 2D 中预训练的 CLIP 中。
通过在小样本设置中微调轻量级适配器,PointCLIP 的性能可以大大提高。此外,我们观察到 PointCLIP 和经典 3D 监督网络之间的互补特性。通过简单的集成,PointCLIP 提高了基线的性能,甚至超越了最先进的模型。因此,PointCLIP 是在低资源成本和数据机制下通过 CLIP 进行有效 3D 点云理解的有前途的替代方案。
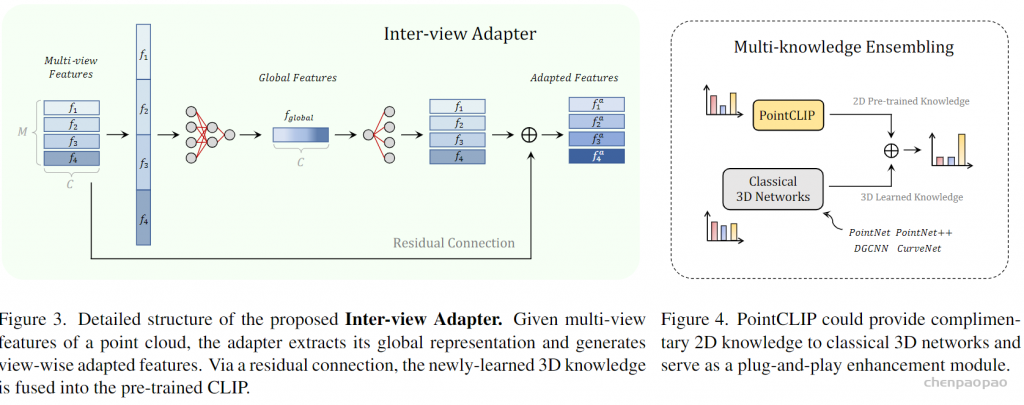
ensembling聚合部分:可以认为是把pointclip作为一个即插即用的模块,用于辅助3D点云分类网络做分类任务 。
实验结果
我们对广泛采用的 ModelNet10、ModelNet40 和具有挑战性的 ScanObjectNN 进行了彻底的实验,以证明 PointCLIP 的有效性。