yolov3属于一阶段、anchor-based 目标检测
FPN :
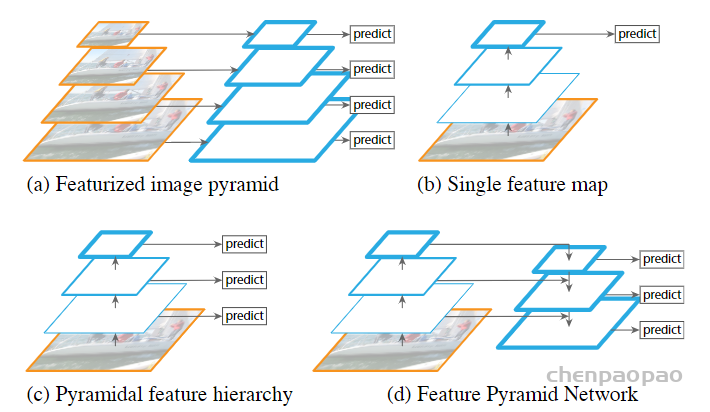
原来多数的object detection算法都是只采用顶层特征做预测,但我们知道低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而本文不一样的地方在于预测是在不同特征层独立进行的。
FPN(Feature Pyramid Network)算法可以同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到很好的预测效果。此外,和其他的特征融合方式不同的是本文中的预测是在每个融合后的特征层上单独进行的。(对不同特征层单独预测)
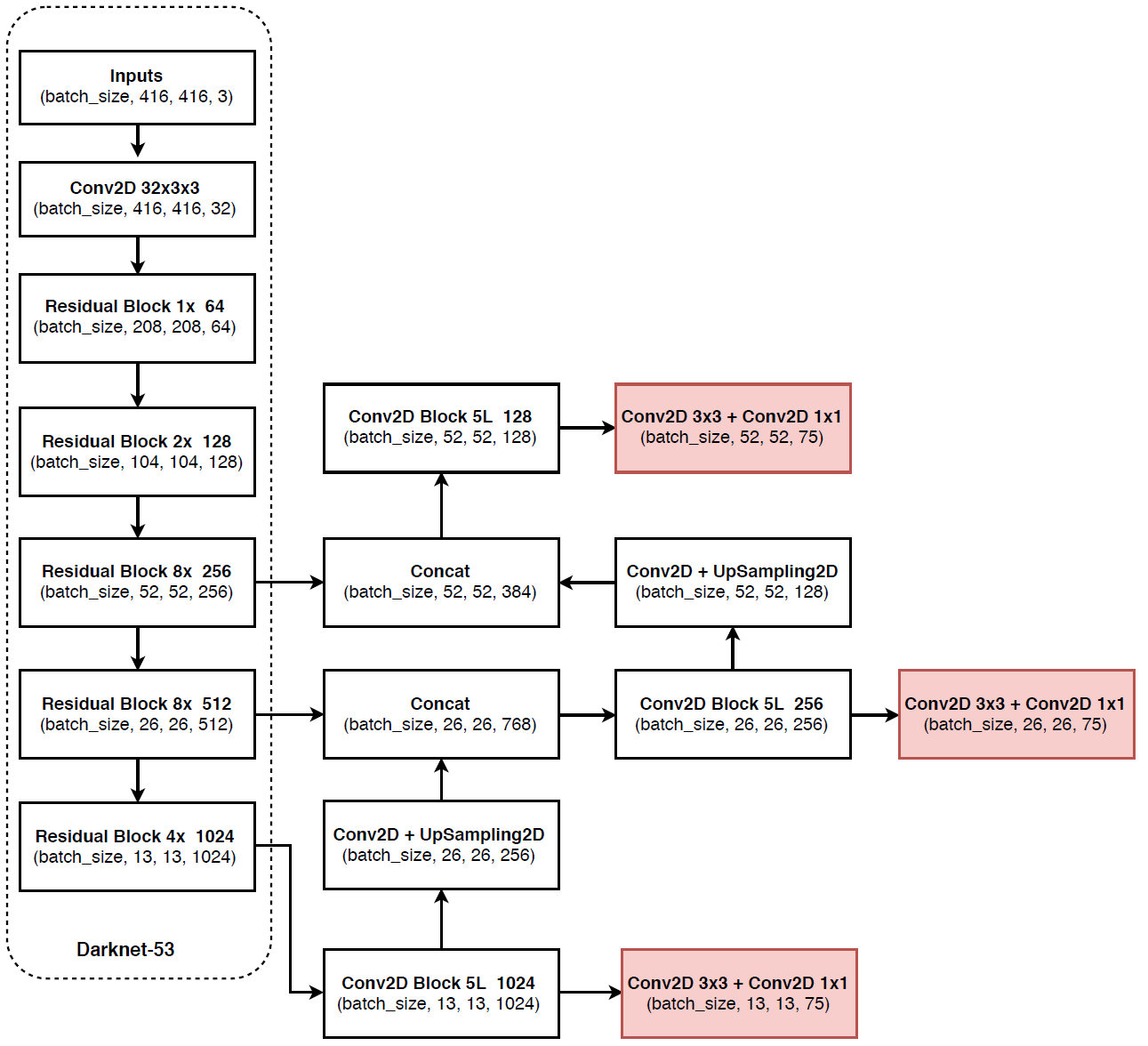
网络结构解析:
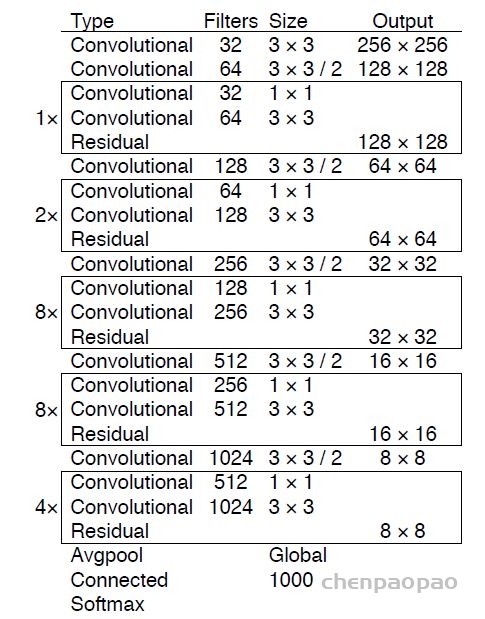
- Yolov3中,只有卷积层,通过调节卷积步长控制输出特征图的尺寸。所以对于输入图片尺寸没有特别限制。流程图中,输入图片以256*256作为样例。
- Yolov3借鉴了金字塔特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。特征图的输出维度为
,
为输出特征图格点数,一共3个Anchor框,每个框有4维预测框数值
,1维预测框置信度,80维物体类别数。所以第一层特征图的输出维度为
。
- Yolov3总共输出3个特征图,第一个特征图下采样32倍,第二个特征图下采样16倍,第三个下采样8倍。输入图像经过Darknet-53(无全连接层),再经过Yoloblock生成的特征图被当作两用,第一用为经过3*3卷积层、1*1卷积之后生成特征图一,第二用为经过1*1卷积层加上采样层,与Darnet-53网络的中间层输出结果进行拼接,产生特征图二。同样的循环之后产生特征图三。
- concat操作与加和操作的区别:加和操作来源于ResNet思想,将输入的特征图,与输出特征图对应维度进行相加,即
;而concat操作源于DenseNet网络的设计思路,将特征图按照通道维度直接进行拼接,例如8*8*16的特征图与8*8*16的特征图拼接后生成8*8*32的特征图。
- 上采样层(upsample):作用是将小尺寸特征图通过插值等方法,生成大尺寸图像。例如使用最近邻插值算法,将8*8的图像变换为16*16。上采样层不改变特征图的通道数。
Yolo的整个网络,吸取了Resnet、Densenet、FPN的精髓,可以说是融合了目标检测当前业界最有效的全部技巧。