
reference:
https://zhuanlan.zhihu.com/p/78777020
https://zhuanlan.zhihu.com/p/28853704
GAN全称:Generative Adversarial Network 即生成对抗网络,由Ian J. Goodfellow等人于2014年10月发表在NIPS大会上的论文《Generative Adversarial Nets》中提出。此后各种花式变体Pix2Pix、CYCLEGAN、STARGAN、StyleGAN等层出不穷,在“换脸”、“换衣”、“换天地”等应用场景下生成的图像、视频以假乱真,好不热闹。前段时间PaddleGAN实现的First Order Motion表情迁移模型,能用一张照片生成一段唱歌视频。各种搞笑鬼畜视频火遍全网。用的就是一种GAN模型哦。深度学习三巨神之一的LeCun也对GAN大加赞赏,称“adversarial training is the coolest thing since sliced bread”。
对抗生成模型GAN首先是一个生成模型,和大家比较熟悉的、用于分类的判别模型不同。
判别模型的数学表示是y=f(x),也可以表示为条件概率分布p(y|x)。当输入一张训练集图片x时,判别模型输出分类标签y。模型学习的是输入图片x与输出的类别标签的映射关系。即学习的目的是在输入图片x的条件下,尽量增大模型输出分类标签y的概率。
而生成模型的数学表示是概率分布p(x)。没有约束条件的生成模型是无监督模型,将给定的简单先验分布π(z)(通常是高斯分布),映射为训练集图片的像素概率分布p(x),即输出一张服从p(x)分布的具有训练集特征的图片。模型学习的是先验分布π(z)与训练集像素概率分布p(x)的映射关系。
生成对抗网络一般由一个生成器(生成网络),和一个判别器(判别网络)组成。生成器的作用是,通过学习训练集数据的特征,在判别器的指导下,将随机噪声分布尽量拟合为训练数据的真实分布,从而生成具有训练集特征的相似数据。而判别器则负责区分输入的数据是真实的还是生成器生成的假数据,并反馈给生成器。两个网络交替训练,能力同步提高,直到生成网络生成的数据能够以假乱真,并与与判别网络的能力达到一定均衡。
GAN的本质
其实GAN模型以及所有的生成模型都一样,做的事情只有一件:拟合训练数据的分布。对图片生成任务来说就是拟合训练集图片的像素概率分布。下面我们从原理的角度演示一下GAN的训练过程:
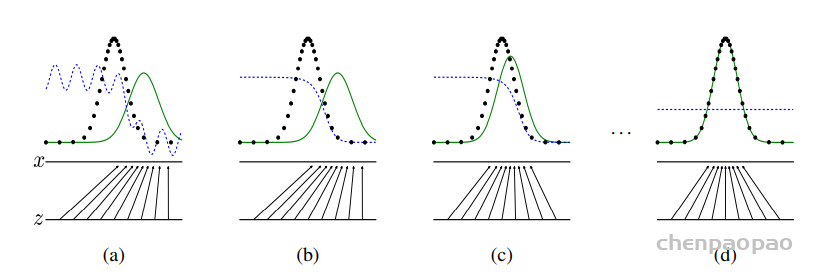
上图中: 黑色点线为训练集数据分布曲线 蓝色点线为判别器输出的分布曲线 绿色实线为生成器输出的分布曲线 z展示的是生成器映射前的简单概率分布(一般是高斯分布)的范围和密度 x展示的是生成器映射后学到的训练集的概率分布的范围和密度 (a)判别器与生成器均未训练呈随机分布 (b)判别器经过训练,输出的分布在靠近训练集“真”数据分布的区间趋近于1(真),在靠近生成器生成的“假”数据分布的区间趋近于0(假) (c)生成器根据判别器输出的(真假)分布,更新参数,使自己的输出分布趋近于训练集“真”数据的分布。 经过(b)(c)(b)(c)…步骤的循环交替。判别器的输出分布随着生成器输出的分布与训练集分布的接近而更加平缓;生成器输出的分布则在判别器输出分布的指引下逐渐趋近于训练集“真”数据的分布。 (d)训练完成时,生成器输出的分布完美拟合了训练集数据的分布,判别器的输出由于生成器的完美拟合而无法判别生成器输出的真伪而呈一条取值约为0.5(真假之间)的直线。
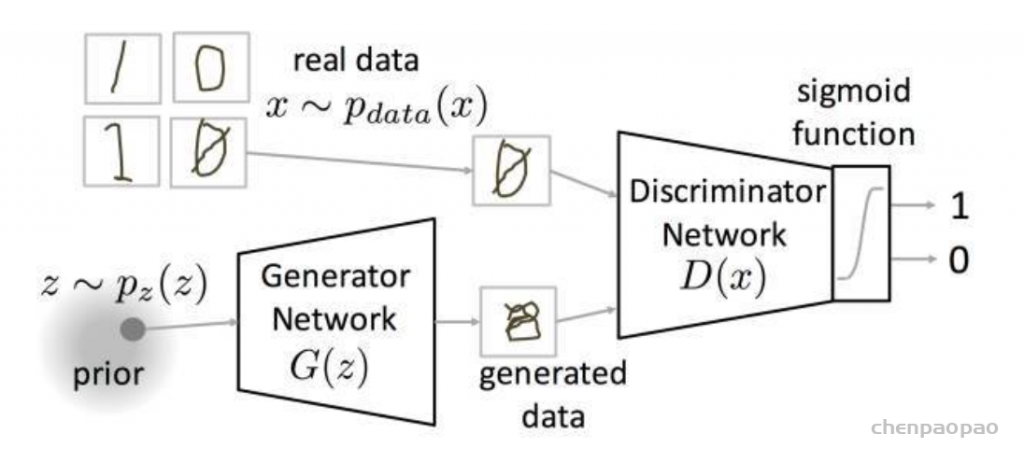
GAN的组成
- 解读GAN的loss函数
GAN网络的训练优化目标就是如下公式:

公式出自Goodfellow在2014年发表的论文Generative Adversarial Nets。这里简单介绍下公式的含义和如何应用到代码中。上式中等号左边的部分: V(D,G)表示的是生成样本和真实样本的差异度,可以使用二分类(真、假两个类别)的交叉熵损失。
maxV(D, G)表示在生成器固定的情况下,通过最大化交叉熵损失V(D,G)来更新判别器D的参数。
min maxV(D, G)表示生成器要在判别器最大化真、假图片交叉熵损失V(D,G)的情况下,最小化这个交叉熵损失
首先固定G训练D :
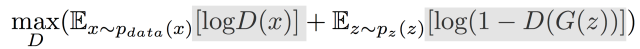
1)训练D的目的是希望这个式子的值越大越好。真实数据希望被D分成1,生成数据希望被分成0。
第一项,如果有一个真实数据被分错,那么log(D(x))<<0,期望会变成负无穷大。
第二项,如果被分错成1的话,第二项也会是负无穷大。
很多被分错的话,就会出现很多负无穷,那样可以优化的空间还有很多。可以修正参数,使V的数值增大。
2)训练G ,它是希望V的值越小越好,让D分不开真假数据。
因为目标函数的第一项不包含G,是常数,所以可以直接忽略 不受影响。

对于G来说 它希望D在划分他的时候能够越大越好,他希望被D划分1(真实数据)。

第二个式子和第一个式子等价。在训练的时候,第二个式子训练效果比较好 常用第二个式子的形式。
证明V是可以收敛导最佳解的。
(1)global optimum 存在
(2)global optimum训练过程收敛
全局优化首先固定G优化D,D的最佳情况为:
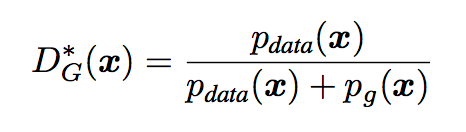
1、证明D*G(x)是最优解
由于V是连续的所以可以写成积分的形式来表示期望:
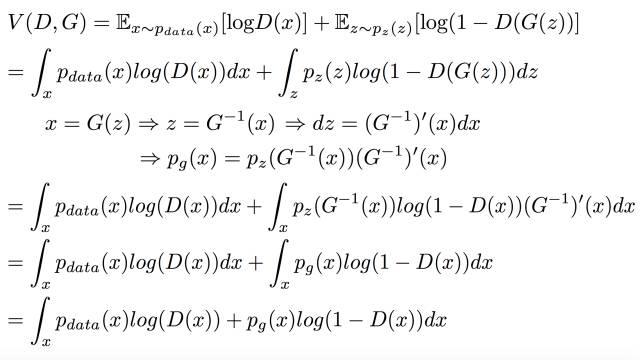
通过假设x=G(z)可逆进行了变量替换,整理式子后得到:

然后对V(G,D)进行最大化:对D进行优化令V取最大
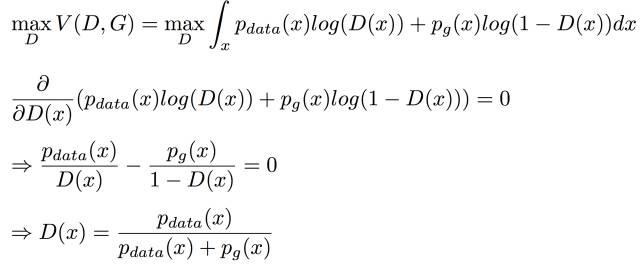
取极值,对V进行求导并令导数等于0.求解出来可得D的最佳解D*G(x)结果一样。
2、假设我们已经知道D*G(x)是最佳解了,这种情况下G想要得到最佳解的情况是:G产生出来的分布要和真实分布一致,即:
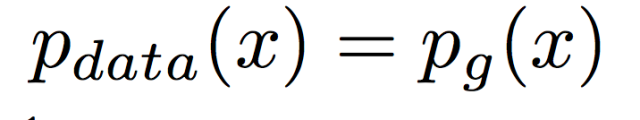
在这个条件下,D*G(x)=1/2。
接下来看G的最优解是什么,因为D的这时已经找到最优解了,所以只需要调整G ,令
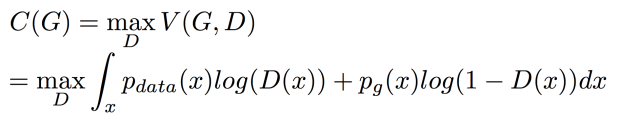
对于D的最优解我们已经知道了,D*G(x),可以直接把它带进来 并去掉前面的Max
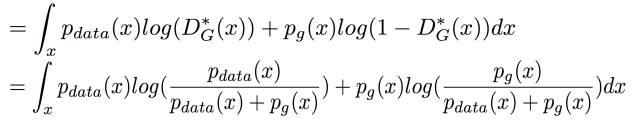
然后对 log里面的式子分子分母都同除以2,分母不动,两个分子在log里面除以2 相当于在log外面 -log(4) 可以直接提出来:

结果可以整理成两个KL散度-log(4)

KL散度是大于等于零的,所以C的最小值是 -log(4)
当且仅当
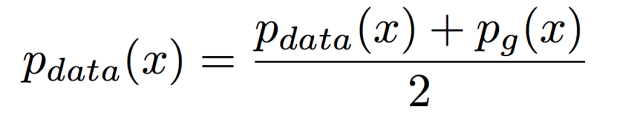
即

所以证明了 当G产生的数据和真实数据是一样的时候,C取得最小值也就是最佳解。
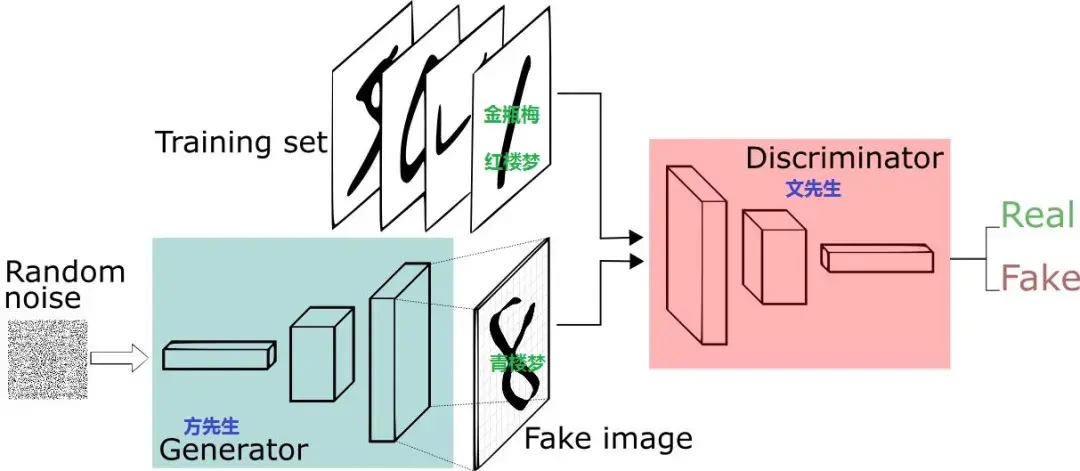
如上图所示GAN由一个判别器(Discriminator)和一个生成器(Generator)两个网络组成。
训练时先训练判别器:将训练集数据(Training Set)打上真标签(1)和生成器(Generator)生成的假图片(Fake image)打上假标签(0)一同组成batch送入判别器(Discriminator),对判别器进行训练。计算loss时使判别器对真数据(Training Set)输入的判别趋近于真(1),对生成器(Generator)生成的假图片(Fake image)的判别趋近于假(0)。此过程中只更新判别器(Discriminator)的参数,不更新生成器(Generator)的参数。
然后再训练生成器:将高斯分布的噪声z(Random noise)送入生成器(Generator),然后将生成器(Generator)生成的假图片(Fake image)打上真标签(1)送入判别器(Discriminator)。计算loss时使判别器对生成器(Generator)生成的假图片(Fake image)的判别趋近于真(1)。此过程中只更新生成器(Generator)的参数,不更新判别器(Discriminator)的参数。
判别器结构:
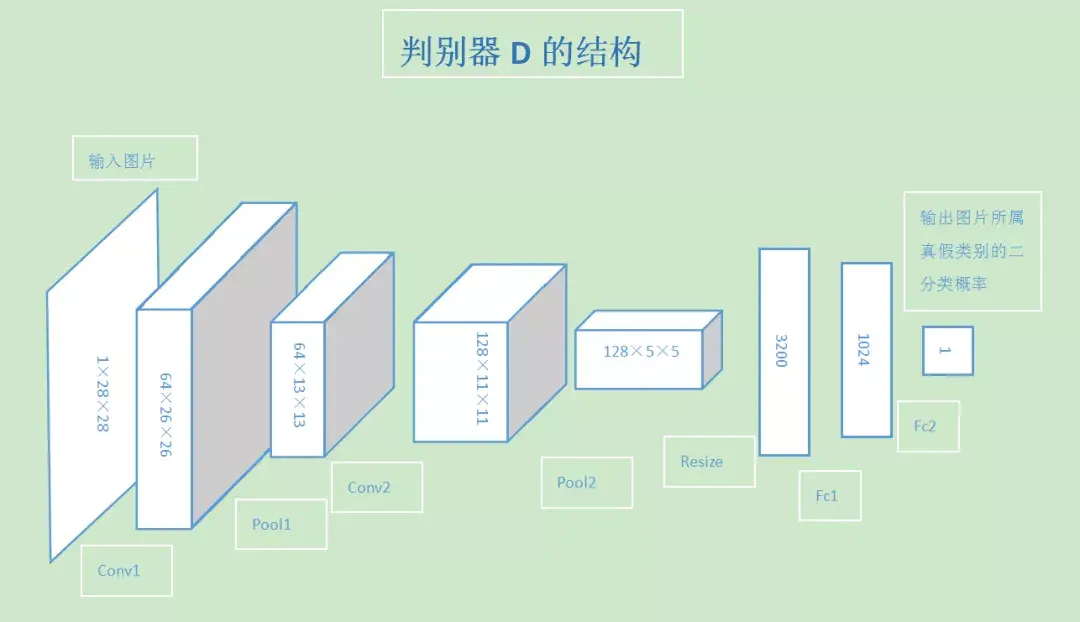
生成器结构:

代码实现:http://139.9.1.231/index.php/2021/12/29/gan/