
去年 1 月 6 日,OpenAI 发布了新模型 DALL·E,不用跨界也能从文本生成图像,打破了自然语言与视觉次元壁,引起了 AI 圈的一阵欢呼。时隔一年多后,DALL·E 迎来了升级版本——DALL·E 2。
DALL·E 2 是一个新的人工智能系统,可以根据自然语言的描述创建逼真的图像和艺术。
链接:
1、试玩 https://openai.com/dall-e-2/
2、论文地址:https://cdn.openai.com/papers/dall-e-2.pdf
3、github : https://github.com/lucidrains/DALLE2-pytorch
示例:
TEXT DESCRIPTION 文本描述:
An astronautTeddy bearsA bowl of soup
输出:

网络:(具体细节还没仔细看论文)

生成模型的迭代
DALL·E 2 建立在 CLIP 之上,OpenAI 研究科学家 Prafulla Dhariwal 说:「DALL·E 1 只是从语言中提取了 GPT-3 的方法并将其应用于生成图像:将图像压缩成一系列单词,并且学会了预测接下来会发生什么。」这是许多文本 AI 应用程序使用的 GPT 模型。但单词匹配并不一定能符合人们的预期,而且预测过程限制了图像的真实性。CLIP 旨在以人类的方式查看图像并总结其内容,OpenAI 迭代创建了一个 CLIP 的倒置版本——「unCLIP」,它能从描述生成图像,而 DALL·E 2 使用称为扩散(diffusion)的过程生成图像。
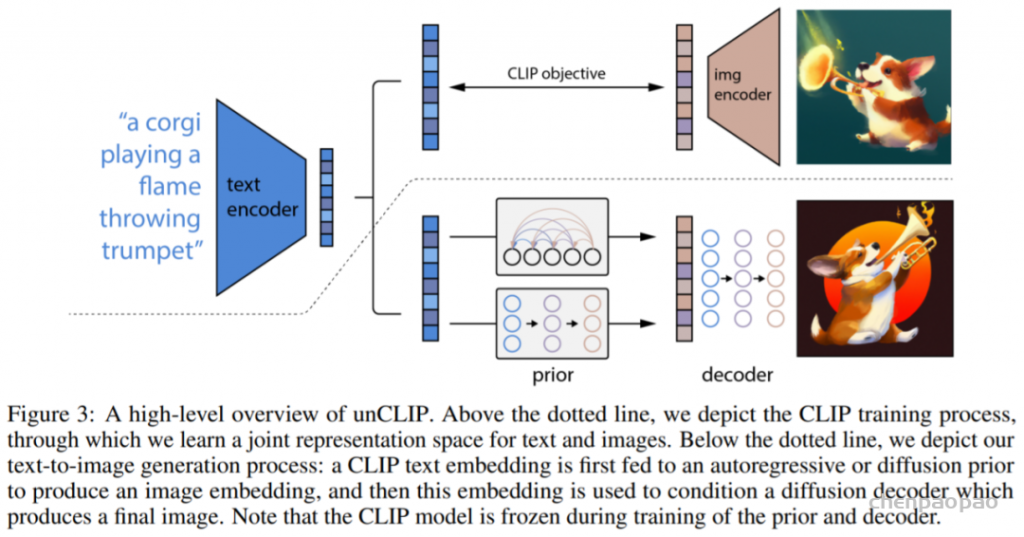
训练数据集由图像 x 及其对应的字幕 y 对 (x, y) 组成。给定图像 x, z_i 和 z_t 分别表示 CLIP 图像和文本嵌入。OpenAI 生成堆栈以使用两个组件从字幕生成图像:
- 先验 P(z_i |y) 生成以字幕 y 为条件的 CLIP 图像嵌入 z_i;
- 解码器 P(x|z_i , y) 以 CLIP 图像嵌入 z_i(以及可选的文本字幕 y)为条件生成图像 x。
解码器允许研究者在给定 CLIP 图像嵌入的情况下反演图像(invert images),而先验允许学习图像嵌入本身的生成模型。堆叠这两个组件产生一个图像 x 、给定字幕 y 的生成模型 P(x|y) :
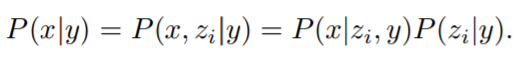
DALL·E 的完整模型从未公开发布,但其他开发人员在过去一年中已经构建了一些模仿 DALL·E 功能的工具。最受欢迎的主流应用程序之一是 Wombo 的 Dream 移动应用程序,它能够根据用户描述的各种内容生成图片。
OpenAI 已经采取了一些内置的保护措施。该模型是在已剔除不良数据的数据集上进行训练的,理想情况下会限制其产生令人反感的内容的能力。为避免生成的图片被滥用,DALL·E 2 在生成的图片上都标有水印,以表明该作品是 AI 生成的。此外,该模型也无法根据名称生成任何可识别的面孔。DALL·E 2 将由经过审查的合作伙伴进行测试,但有一些要求:禁止用户上传或生成「可能造成伤害」的图像。他们还必须说明用 AI 生成图像的作用,并且不能通过应用程序或网站将生成的图像提供给其他人。