
也许是CycleGAN的光芒太过耀眼,Pix2Pix就像家中的次子,还没得宠多长时间,就被弟弟CycleGAN抢走了风头。这也怪不得它们的“爹滴”朱大神把“域风格迁移”的CycleGAN(下个项目介绍)造得太好用了,似乎完全能够代替“像素风格迁移”的Pix2Pix,以至于都来不及给Pix2Pix起个××GAN的名字~
其实,除了“白天照片变夜晚”、“图片着色”、“蓝图变街景”等它弟弟CycleGAN更容易玩儿的花样儿外,Pix2Pix是有着自己的独门绝技的。比如,用自然风景照片训练好的Pix2Pix模型,能实时将手绘的草图渲染成对应风景照片。如果训练集照片里包括老虎等动物,我们几笔在一个圆圈脑袋上画个王字,Pix2Pix模型就能生成一张活灵活现的大老虎,比《照相馆的故事》快多了~Pix2Pix的工作也启发了一些更具体的应用,比如专门手绘照片的SketchyGAN、手绘人脸的模型DeepFaceDrawing等。另外Pix2Pix->Pix2PixHD(高清渲染)->Vid2Vid(视频实时渲染)也是一条发展路线。试想,只需建好游戏人物和场景的结构模型,然后机器自动按训练的风格渲染人物和场景,游戏设计师们有没有感到点儿激动。
1. Pix2Pix的原理
发表在CVPR2017上的论文《Image-to-Image Translation with Conditional Adversarial Networks》是将GAN应用于有监督的图像到图像翻译的经典论文,提出的GAN模型被简称为Pix2Pix(不叫××GAN,很像是小名儿吧~)。为了解决图像到图像的翻译(也就是前面提到的那些上色、手绘草图的应用),我们需要建立一个模型实现图像到图像的映射。
以前曾经有过尝试搭建一个CNN网络进行映射,并用L1距离来度量、优化模型,结果发现效果很模糊(用L2距离更模糊),就像下面这样:
那么,既然GAN能够较好地生成图片的细节,我们何不拿来一用?显然,经典GAN是不行的,没法控制输出嘛。CGAN正好拿来一用。对此,朱大神在报告里曾经解释过:如果我们用经典GAN,判别器判别时会出现这样的问题。
这样的生成图片判别为真没问题
但是,这样的生成图片也判断为真就有问题了。显而易见,生成的猫图片与手绘的猫草图的形态完全不一致。但因为这也是一张猫图片,是符合训练集图片的像素概率分布的,所以会被经典GAN判别为真图片。
为了解决这一问题,我们将输入的猫草图作为“条件标签”和生成的猫图片一起送入判别器进行判断,如下图:
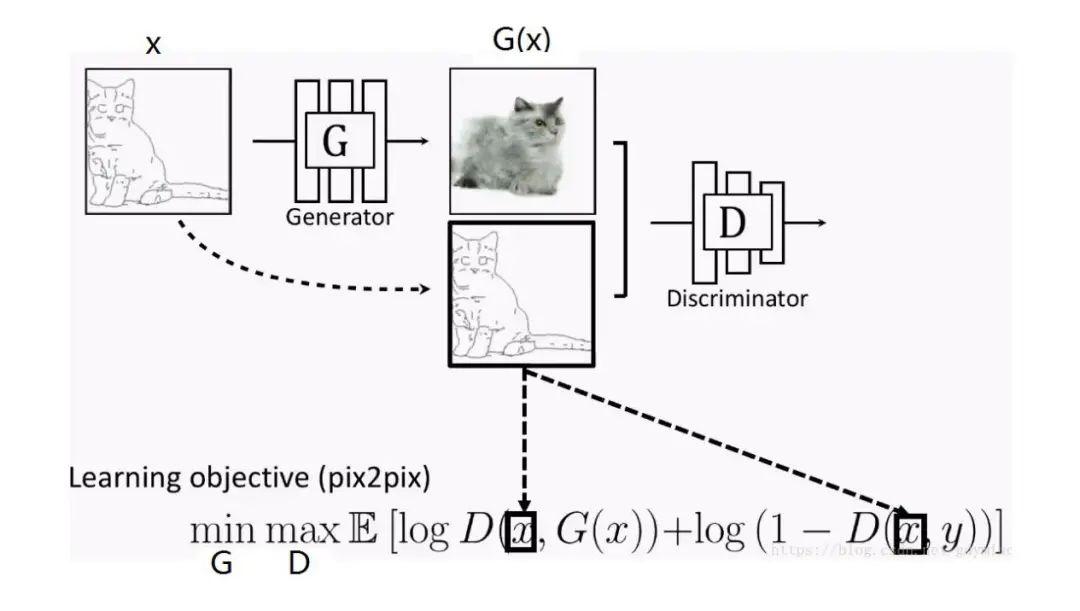
这看上去是不是有点儿CGAN的影子?没错,这个Pix2Pix就是个CGAN!
2.Pix2Pix的结构
我们将Pix2Pix的结构与上篇CGAN的结构对比一下:
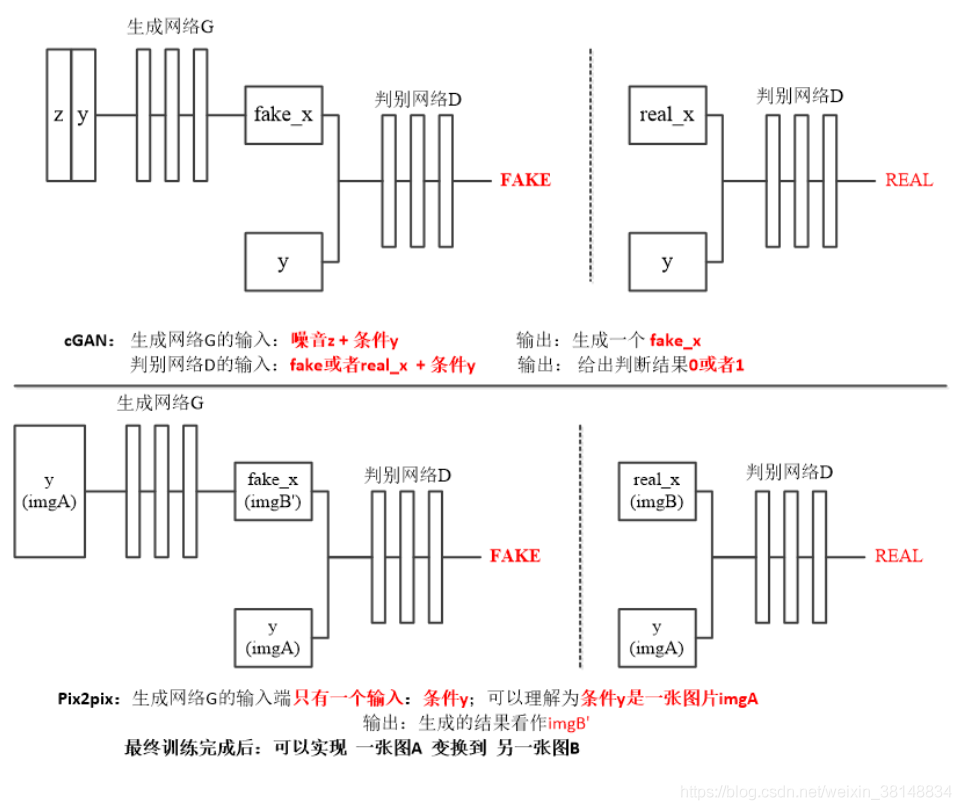
上图的上半部份是普通CGAN的结构,下半部分是Pix2Pix的结构。对比发现,Pix2Pix与CGAN的结构有两点不同:
- 在Pix2Pix中,输入生成器的控制条件由“分类标签y”变成了A组(原风格)图片,因为这里我们要用A组(原风格)图片做为控制条件来生成B组(目标风格)图片。由于输入生成器的A组图片的维度(图片尺寸)与生成器输出的B组图片的维度相同,足以映射复杂分布,所以,我们不必再输入噪声z。细心的同学可能会发现:在刚才那张“对比普通CGAN和Pix2Pix结构”的图片中,我们对“条件y”的解释,与上一张“介绍给Pix2Pix加标签原因”的图片中的解释不一样。“对比结构”的图片中将生成器的输入解释为“条件y”,而“解释用CGAN原因”的图片中将生成器的输入解释为“输入x”。实际上这两种对生成器输入的解释都指的是A(原风格)组图片,不影响后面的推理。但个人觉得:将生成器的输入解释为“条件y”更容易帮助理解Pix2Pix的CGAN本质。我理解,Pix2Pix拟合的是训练集中B组(目标风格)图片的像素概率分布,A组(原风格)图片是作为“约束条件”来使用的。对比一下普通CGAN的结构就清楚了。
- 在Pix2Pix中,输入判别器的控制条件也由“分类标签y”变成了A组(原风格)图片。A组(原风格)图片作为“条件y”要和真B组(目标风格)图片或生成器生成的假B组图片(在图像通道维度上)拼接在一起送入判别器。这个很好理解,也说明了前面把生成器的输入解释为“条件y”更“工整”。
这样,Pix2Pix做了以上改动后,整个模型从“输入噪声、输出图片”的流程,变成了“输入A组图片、输出B组图片”的流程。
3.Pix2Pix的loss
在大神造Pix2Pix的过程中也试过各种“配方”。包括使用L1损失、使用CGAN损失和使用两者之和,测试结果如下:

观察结果发现:
- 只用L1损失时,生成的图片比较模糊。
- 只用CGAN损失时,生成的图片很清晰,但颜色风格与Ground Truth图片差别较大。
- 使用L1+CGAN损失时,生成的图片又清晰,又保留了更多Ground Truth图片的特征。
所以,最后Pix2Pix使用了L1+CGAN损失。我们看下loss的构成。
先看L1损失:
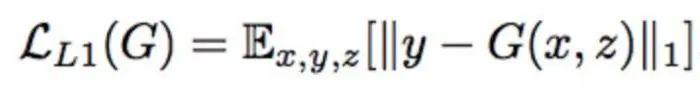
L1损失的计算方法就是真B组(目标风格)图片与生成器生成的假B组图片逐像素求差的绝对值再求平均。公式中的x指A组(原风格)图片,y指B组(目标风格)图片,z指C输入给生成器的(一般是高斯分布的)噪声,代码中并未使用。
再来看看CGAN损失:
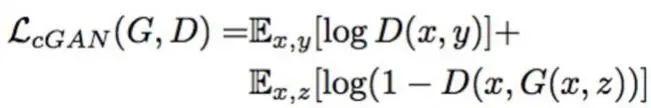
Pix2Pix的CGAN损失和普通CGAN损失一模一样
Pix2Pix总的损失是这两者之和:
