
以下文章来源于微信公众号: 所向披靡的张大刀
作者:张大刀
原文链接:https://mp.weixin.qq.com/s/nhZ3Q1NHm3op8abdVIGmLA
本文仅用于学术分享,如有侵权,请联系后台作删文处理
导读在正负样本分配中,Yolov7的策略算是Yolov5和YoloX的结合。本文先从Yolov5和Yolov6正负样本分配策略分析入手,后引入到Yolov7的解析中,希望对大家学习Yolov7有帮助。
本文主要就Yolov7的正负样本筛选策略,并与Yolov5,Yolov6进行比对。
首先接着上一篇Yolov7系列一,网络整体结构,填几个小坑,希望对大家没有造成困扰:
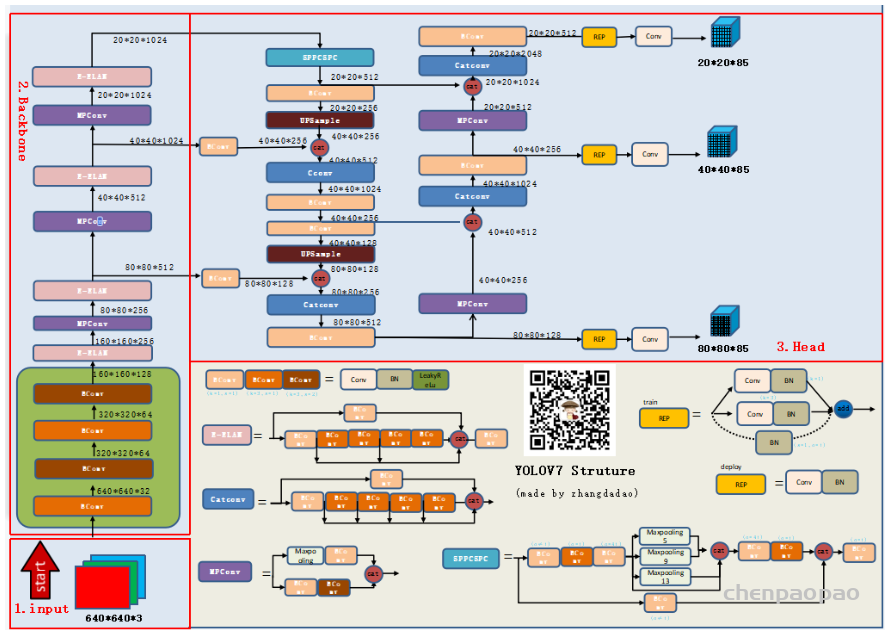
如:E-ELAN层,在cat后需要要conv层做特征融合:

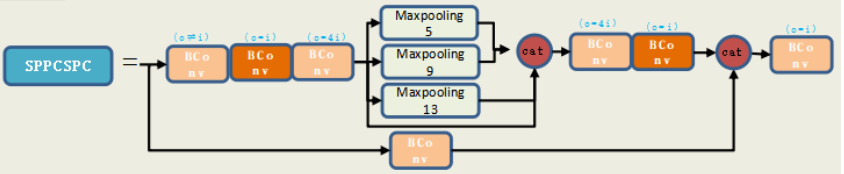
还有SPPCSPC层经大家勘误后,改动如下:
还有另外几个小问题:如REPconv层在Yolov7论文中将identity 层去掉,卷积后的激活函数是SiLu这些,因Yolov7网络是基于Tag0.1版本Yolov7.yaml的代码构造的,作者后续在持续优化迭代,后续大刀也会继续更新。
Yolov7因为基于anchor based的目标检测,与Yolov5相同,Yolov6的正负样本的匹配策略则与Yolox相同,Yolov7则基本集成两家之所长。下面先回顾下Yolov5,v6的正负样本匹配策略。
1. Yolov5的正负样本匹配策略
Yolov5基于anchor based,在开始训练前,会基于训练集中gt(ground truth 框),通过k-means聚类算法,先验获得9个从小到大排列的anchor框。先将每个gt与9个anchor匹配(以前是IOU匹配,Yolov5中变成shape匹配,计算gt与9个anchor的长宽比,如果长宽比小于设定阈值,说明该gt和对应的anchor匹配),
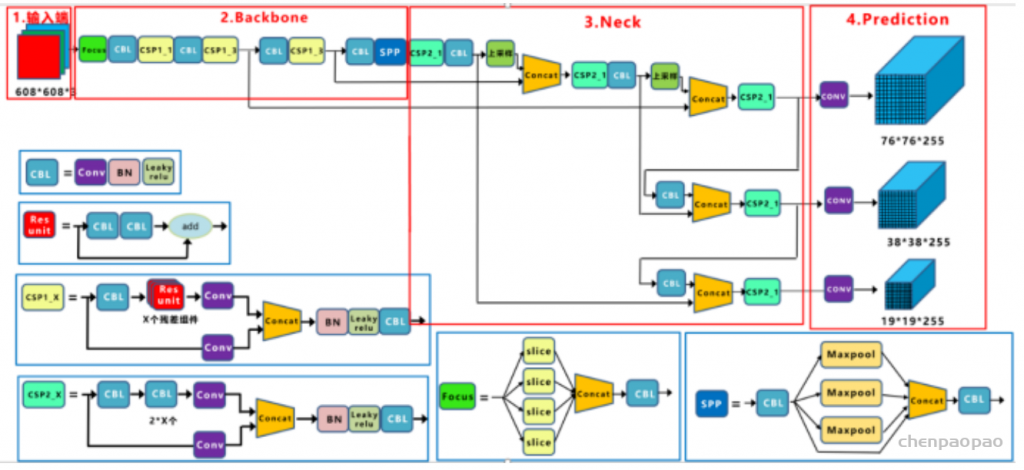
如上图为Yolov5的网络架构,Yolov5有三层网络,9个anchor, 从小到大,每3个anchor对应一层prediction网络,gt与之对应anchor所在的层,用于对该gt做训练预测,一个gt可能与几个anchor均能匹配上。所以一个gt可能在不同的网络层上做预测训练,大大增加了正样本的数量,当然也会出现gt与所有anchor都匹配不上的情况,这样gt就会被当成背景,不参与训练,说明anchor框尺寸设计的不好。
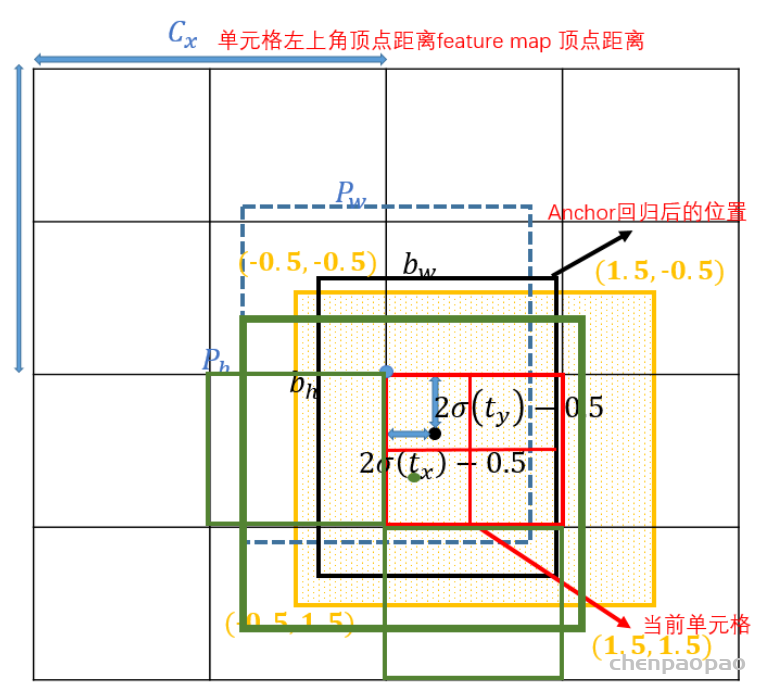
在训练过程中怎么定义正负样本呢,因为Yolov5中负样本不参与训练,所以要增加正样本的数量。gt框与anchor框匹配后,得到anchor框对应的网络层的grid,看gt中心点落在哪个grid上,不仅取该grid中和gt匹配的anchor作为正样本,还取相邻的的两个grid中的anchor为正样本。如下图所示,绿色的gt框中心点落在红色grid的第三象限里,那不仅取该grid,还要取左边的grid和下面的grid,这样基于三个grid和匹配的anchor就有三个中心点位于三个grid中心点,长宽为anchor长宽的正样本,同时gt不仅与一个anchor框匹配,如果跟几个anchor框都匹配上,所以可能有3-27个正样本,增大正样本数量。
2. Yolov6的正负样本匹配策略
Yolov6的正负样本匹配策略同Yolox,Yolox因为是anchor free,anchor free因为缺少先验框这个先验知识,理论上应该是对场景的泛化性更好,同时参见旷视的官方解读:Anchor 增加了检测头的复杂度以及生成结果的数量,将大量检测结果从NPU搬运到CPU上对于某些边缘设备是无法容忍的。Yolov6中的正样本筛选,主要分成以下几个部分:①:基于两个维度来粗略筛选;②:基于simOTA进一步筛选。

tie标签的gt如图所示,找到gt的中心点(Cx,Cy),计算中心点到左上角的距离(l_l,l_t),右下角坐标(l_r,l_b),然后从两步筛选正样本:第一步粗略筛选第一个维度是如果grid的中心点落在gt中,则认为该grid所预测的框为正样本,如图所示的红色和橙色部分,第二个维度是以gt的中心点所在grid的中心点为中心点,上下左右扩充2.5个grid步长范围内的grid,则默认该grid所预测的框为正样本,如图紫色和橙色部分。这样第一步筛选出31个正样本(注:这里单独一层的正样本,Yolov6有三个网络层,分别计算出各层的正样本,并叠加)。

第二步:通过SimOTA进一步筛选:SimOTA是基于OTA的一种优化,OTA是一种动态匹配算法,具体参见旷视官方解读(https://www.zhihu.com/question/473350307/answer/2021031747)SimOTA流程如下:
①计算初筛正样本与gt的IOU,并对IOU从大到小排序,取前十之和并取整,记为b。
②计算初筛正样本的cos代价函数,将cos代价函数从小到大排列,取cos前b的样本为正样本。同时考虑同一个grid预测框被两个gt关联的情况,取cos较小的值,该预测框为对应的gt的正样本。具体细节可以参考大白的知乎文章:https://www.zhihu.com/search?type=content&q=simOTA
3. Yolov7的正负样本匹配策略
Yolov7因为基于anchor based , 集成v5和v6两者的精华,即Yolov6中的第一步的初筛换成了Yolov5中的筛选正样本的策略,保留第二步的simOTA进一步筛选策略。
同时Yolov7中有aux_head 和lead_head 两个head ,aux_head做为辅助,其筛选正样本的策略和lead_head相同,但更宽松。如在第一步筛选时,lead_head 取中心点所在grid和与之接近的两个grid对应的预测框做为正样本,如图绿色的grid, aux_head则取中心点以及周围的4个预测框为正样本。如下图绿色+蓝色区域的grid.
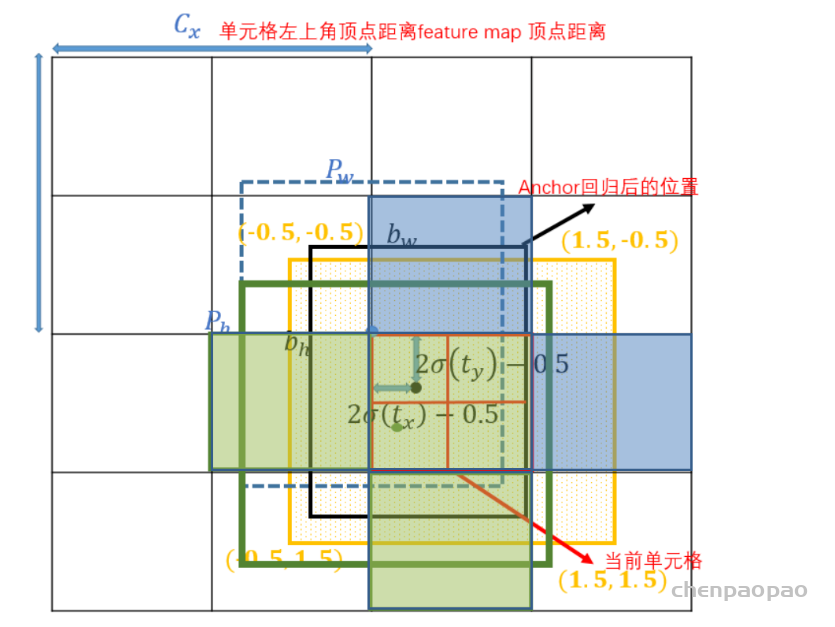
同时在第二步simOTA部分,lead_head 是计算初筛正样本与gt的IOU,并对IOU从大到小排序,取前十之和并取整,记为b。aux_head 则取前二十之和并取整。其他步骤相同,aux_head主要是为了增加召回率,防止漏检,lead_head再基于aux_head 做进一步筛选。
4. 结语以上为Yolov7的正负样本的匹配策略,希望对大家有帮助。同时文中如果有bug,欢迎一起讨论。
参考:[1] https://github.com/WongKinYiu/yolov7(官方github代码)
[2] https://arxiv.org/pdf/2207.02696.pdf(yolov7论文)[3]https://zhuanlan.zhihu.com/p/394392992[4]YOLOv7官方开源 | Alexey Bochkovskiy站台,精度速度超越所有YOLO,还得是AB (qq.com)[5] https://www.zhihu.com/question/473350307/answer/2021031747
[6]【yolov6系列】细节拆解网络框架 (qq.com)[7] https://arixv.org/abs/2103/14259v1 (OTA for object detection)[8] https://github.com/Megvii-BasedDetection/OTA