
paper: https://arxiv.org/abs/2604.18105
面向生产部署的 LLM-ASR 框架,系统解决轻量化、幻觉抑制、热词定制三大痛点。基于 phoneme-level encoder 预训练减少模态差距,引入 Iterative Asynchronous SFT(IA-SFT)防止 representation drift,设计 ASR 专用 RL 提升识别质量,并以 phoneme RAG 实现百万量级热词定制。
音频 → 600M Conformer Encoder(phoneme CTC 预训练,CKA 监控 drift)
├── 流式:dynamic-chunk mechanism(预训练期内嵌)
└── phoneme CTC head → 音素假设
MLP Adapter(4x 下采样,160ms/token)
↓
Qwen3-1.7B(LLM 解码器)
↑
Phoneme RAG:音素假设 → 检索热词数据库(<1ms)→ Prompt 注入
训练 pipeline:
Stage1: Encoder 预训练(phoneme CTC,CR-CTC)
Stage2: Alignment(仅训练 Adapter,冻结其余)
Stage3: IA-SFT(异步并行,CKA 监控 encoder 稳定性)
Stage4+5: Late Joint SFT + Context SFT + ASR-RL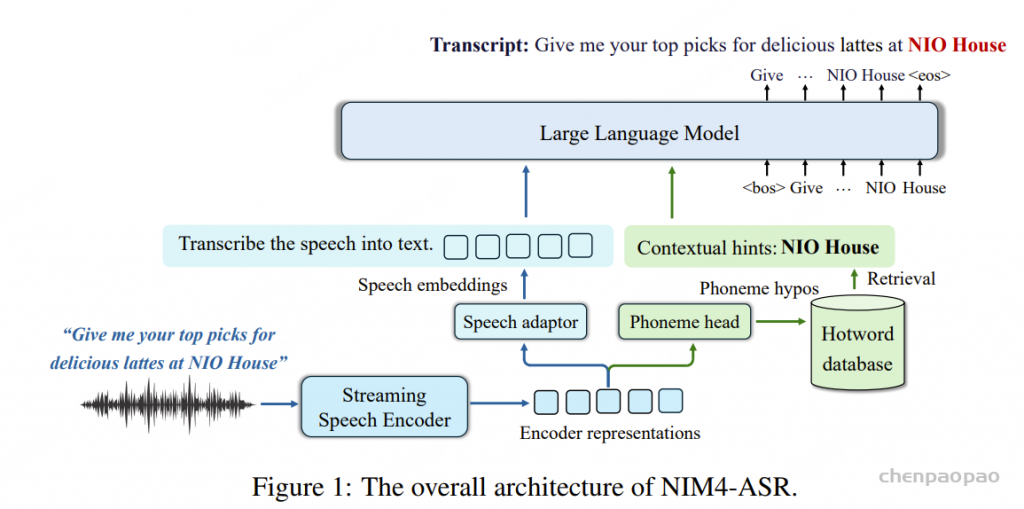
Challenge
1、Limited downward scalability
在实际部署中,尤其是实时语音交互场景下,轻量级 ASR 模型由于推理延迟更低、计算成本更小因此更受青睐。然而,基于 LLM 的 ASR 在模型缩小后的性能表现并不理想:比如Qwen3-ASR-0.6B、Fun-ASR-nano这类轻量版本相比完整大模型存在明显性能差距。除了模型缩小本身带来的性能下降外,LLM-ASR 还额外承担了一种:模态税(modality tax),
即:模型中有相当一部分参数并不是直接用于 ASR 任务,而是用于跨模态对齐(cross-modal alignment)。这种结构性开销会导致轻量 LLM 真正可用于 ASR 的有效容量更少,从而带来不成比例的性能下降。
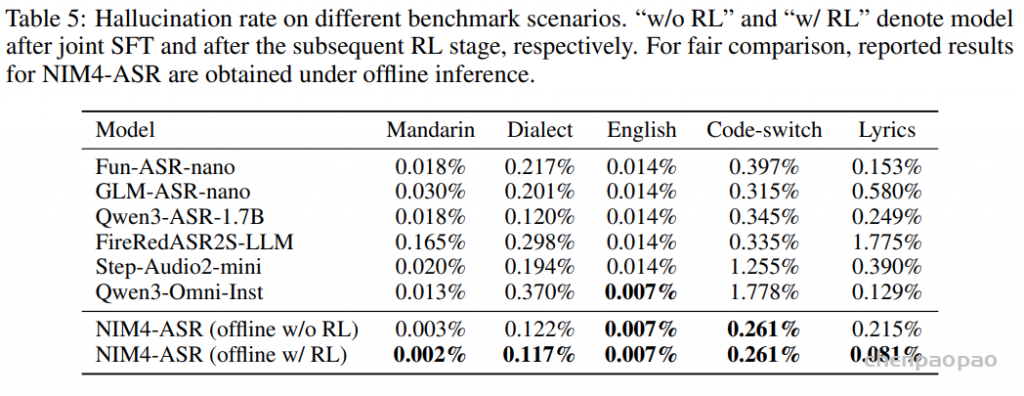
2、幻觉问题(Hallucination)
除了自回归 LLM 天生存在的 hallucination(幻觉)问题之外,encoder–adaptor–LLM 联合训练范式还会引入额外风险。
在联合优化过程中由于:LLM 梯度更强、LLM 语言先验更强。 encoder 会逐渐被拉向LLM 的优化目标,导致 encoder 的表示逐渐偏移到 LLM 的文本特征空间,称之为representation drift(表示漂移),导致encoder 会越来越依赖语言捷径(linguistic shortcuts)而不是精细声学信息(fine-grained acoustic fidelity)。在噪声、发音模糊、音频不清晰的声学歧义场景下会加重幻觉问题。
3、缺乏工业级热词定制能力(Lack of production-ready hotword customization)
为了解决上述问题,提出了面向工业部署的 LLM-ASR 框架 NIM4-ASR,重点优化推理效率和系统鲁棒性。
- 提出了一种基于原则的多阶段训练范式
- 优化了流式处理支持
- 音素级 RAG 用于热词定制
Methodology
Model
encoder–adaptor–LLM 架构
1、音频特征提取
80 维 log-Mel 频谱,窗长(window):25 ms 帧移(frame shift):10 ms,全局均值方差归一化
2、Streaming speech encoder
编码器采用FireRedASR-AED Conformer,一个 4 倍下采样卷积模块 多层 Conformer Block 堆叠,输出帧率 25Hz,为了支持流式推理,训练阶段会模拟streaming 约束,将其改造成chunk-based streaming encoder
3、Speech adaptor
两层 MLP,将 encoder 输出映射到 LLM 的 embedding 空间,4倍下采样,将连续 4 帧特征进行拼接,帧率从 25 Hz 降到 6.25 Hz,每个 token 160ms。
4、Phoneme-level CTC head and RAG module
三层 MLP,将 encoder 表示解码为 phoneme hypothesis(音素假设),greedy decoding。RAG 模块会根据这些音素序列检索 hotword 数据库,将热词作为上下文提示注入 prompt
5、LLM decoder: Qwen3-1.7B
Training Recipe
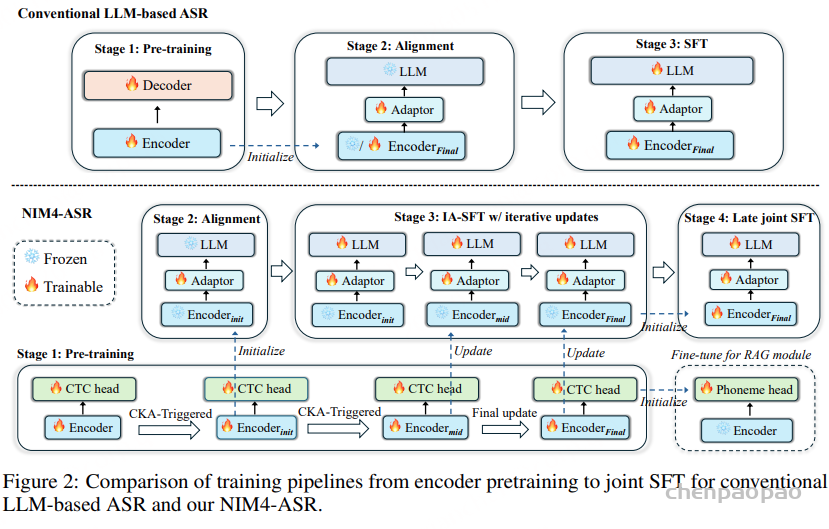
与以往主要依赖经验微调的工作不同,首先对当前基于 LLM 的 ASR 系统的实际局限性及其根本原因进行了系统性的分析 ,结果表明跨模态差距和表征漂移问题仍未得到充分解决。基于这些见解,我们对训练流程进行了全面重新设计。如图 2 所示,NIM4-ASR 的方法论改进主要体现在四个核心训练阶段:编码器预训练、对齐、IA-SFT 和后期联合 SFT。除了这四个阶段的流程之外,我们在后期联合 SFT 之后进一步加入了上下文 SFT 和强化学习(RL),以增强上下文建模和鲁棒性。具体步骤如下所述。
第一阶段:编码器预训练
为了缩小编码器表征与 LLM 嵌入空间之间的模态差异,采用了一种改进的连接主义时间分类(CTC)变体 ——即 CR-CTC 作为预训练目标。如图 2 所示,预训练期间的模型架构由编码器和 CTC 头组成。与先前工作中常用的基于注意力机制的编码器-解码器(AED) 相比,CTC 鼓励编码器生成低熵、音素区分性强的表征,使其与 LLM 的嵌入空间更自然地对齐,从而减少跨模态对齐的开销,并为自动语音识别(ASR)任务保留更多模型容量
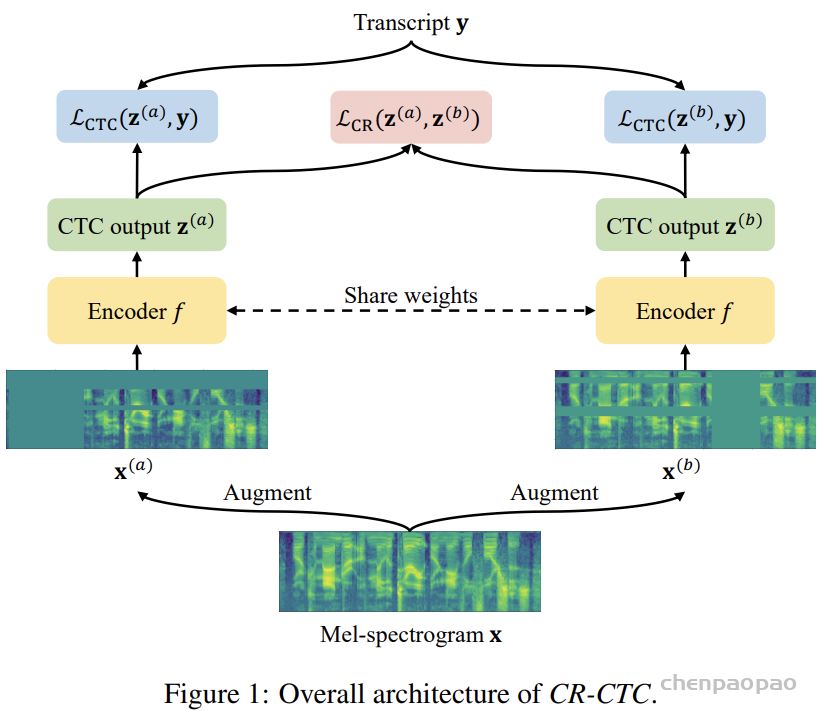
将监督标签从字符级转移到音素级 ,明确地将编码器的容量用于声学到音素的映射,而不是过早地进行语义锚定,同时鼓励语言学习模型(LLM)更多地关注语义推理。这种设计实现了声学建模与语义推理的更清晰解耦,提高了两个模块的角色专业化程度。此外,采用音素预测作为预训练目标,鼓励编码器学习语言依赖性较弱的底层声学表征,从而为扩展到新的语言和方言提供更大的潜力。
为了赋予编码器原生流媒体处理能力,在预训练阶段引入了动态分块机制。具体来说,编码器在分块流媒体约束下处理完整的语音,其中每个批次的块大小和可见左侧上下文块的数量都是动态采样的。这使得编码器能够适应各种流媒体配置,从而实现灵活操作,以适应不同部署场景下不同的延迟预算。
Stage 2: Alignment & Stage 3: IA-SFT
在传统的训练范式中,对齐和联合 SFT 是在预训练完全完成后依次执行的。如图 2 所示,我们为 NIM4-ASR 提出了一种编码器迭代机制,该机制允许在预训练完成之前开始对齐,而 IA-SFT 在对齐完成后启动,并与剩余的预训练过程异步进行。为了确定何时初始化或更新对齐和 IA-SFT 使用的编码器,我们使用中心核对齐(CKA) 跟踪编码器表示的动态变化。CKA 将不断演化的编码器与在整个预训练过程中初始化并定期更新的参考检查点进行比较。给定从同一评估集中提取的两组编码器表示 E(a),E(b) ,CKA 定义为
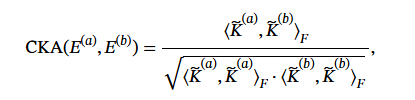
第二阶段:对齐。 预训练达到 50 万步后,我们开始监测编码器,此时编码器开始呈现相对稳定的优化趋势。我们将 50 万步时的编码器快照作为初始参考检查点,之后每隔 1 万步预训练评估一次 CKA。当演化中的编码器与当前参考检查点之间的 CKA 分数首次低于预定义阈值.在对齐过程中,编码器和 LLM 均被冻结,仅训练适配器。在我们的设置中,首次触发发生在预训练约 101 万步时,对齐阶段持续 130 万步
第三阶段:IA-SFT。 对齐完成后,我们在联合 SFT 之前执行 IA-SFT 作为中间阶段。IA-SFT 保持编码器冻结,并基于异步预训练过程生成的编码器快照序列训练适配器-LLM 堆栈。具体步骤如下:
(i)初始化与监控。IA -SFT 在对齐完成后开始,使用从对齐过程中继承的编码器进行 100 万步的训练,同时编码器预训练并行进行。CKA 评估从之前更新的参考检查点恢复,并每隔 1 万步预训练步骤重复进行一次,监控表征偏移。
(ii)CKA 触发更新。 每当 CKA 分数低于预定义阈值时,当前预训练编码器的快照就会热插拔到 IA-SFT 分支中,并相应地更新参考检查点。
(iii)最终更新。 更新周期(ii)重复进行,直到预训练达到其 200 万步的最大值。预训练完成后,无论 CKA 得分如何,都将应用最终编码器更新,并且 IA-SFT 运行最后 200 万步。
在我们的实现中,IA-SFT 使用 101 万步预训练时的编码器检查点进行 100 万步训练,再使用 132 万步预训练时的编码器检查点进行 100 万步训练,最后使用完全预训练的编码器进行 200 万步训练——总共在三个编码器版本上进行了 400 万步训练。在 IA-SFT 过程中,编码器保持冻结状态,但会定期从异步预训练过程中更新,从而保持声学基础。这使得模型能够在不出现表征漂移风险的情况下加深跨模态对齐。从课程学习的角度来看,IA-SFT 逐步将 LLM 暴露于更精细的编码器表征中,使其能够学习不变模式并提高对声学扰动的鲁棒性。此外,由于对齐和 IA-SFT 与预训练异步运行,因此整个训练流程仍然保持高效。
Stage 4: Late Joint SFT
在编码器预训练和 IA-SFT 完成后,语音表征与 LLM 嵌入空间之间建立了稳健的初始跨模态映射。随后,我们执行后期联合 SFT,其中编码器、适配器和 LLM 以端到端的方式联合优化。与传统的联合训练相比,由于前期阶段已经最小化了模态差异,LLM 梯度引起的表征漂移风险显著降低。因此,这些梯度主要作为微调信号,无缝地优化声学到音素的映射以及音素到语义的关联。从几何角度来看,前期的对齐阶段建立了一个稳定的跨模态流形,使后续优化处于损失函数曲面的低曲率区域。在该区域内,梯度更新是对决策边界和流形几何结构的局部优化,而不是引起大规模的拓扑重构。
Stage 5: Context SFT
首先从训练语料库构建关键词集 S 。所有转录文本均被解析以提取候选短语,然后使用 Qwen3-30B-A3B-Instruct进行过滤,以保留命名实体,例如人名、兴趣点(POI)、媒体名称和专有名词。在训练过程中,我们提高长时长话语的采样比例,并按照以下模板,将从 S 中采样的关键词以概率方式注入到提示中作为上下文提示:

每个训练实例,我们首先从转录文本中存在的 S 中提取相关关键词。此外,对于每个关键词,我们以一定的概率从 S 中提取发音相同或高度相似的另一个关键词作为干扰项。相关关键词和干扰项被连接起来,然后添加到 {context} 字段中。干扰项的加入可以防止语言学习模型 (LLM) 过度依赖上下文线索而牺牲语义合理性。在此阶段,编码器、适配器和 LLM 会进行联合训练。
此阶段的设计目的在于实现热词定制,而非跨回合对话的一致性。对于多回合场景,还可以将从对话历史中提取的关键词添加到当前提示中。这种策略以紧凑的形式保留了关键的上下文信息,同时保持了比句子层面方法更低的推理延迟。
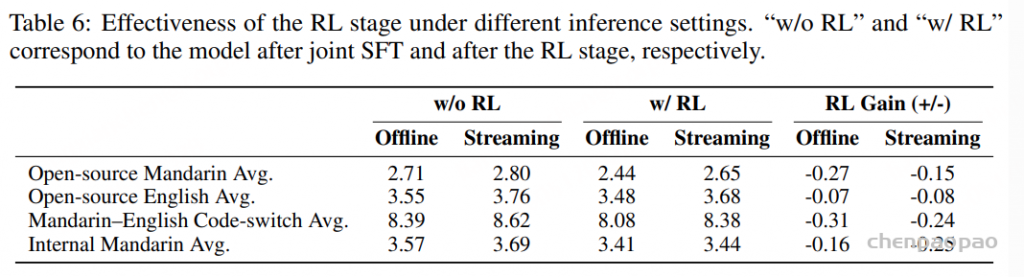
Stage 6: ASR Specialized RL
GRPO,奖励函数:
- Accuracy reward
- Hallucination reward
- Context reward
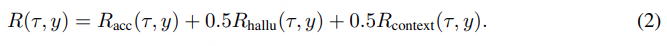
Additional Stage: Phoneme Head Training for RAG
完成强化学习(RL)阶段后,主训练流程结束。接下来,我们引入一个额外的阶段来训练图 1 所示的 RAG 模块所需的音素头。在该阶段,编码器继承强化学习后检查点的结构和权重并保持冻结状态,而音素头则从预训练的 CTC 头初始化并保持可训练状态。训练目标和配置与预训练阶段一致。经过微调后,音素头可以将编码器表示转换为音素假设,供后续检索模块使用。
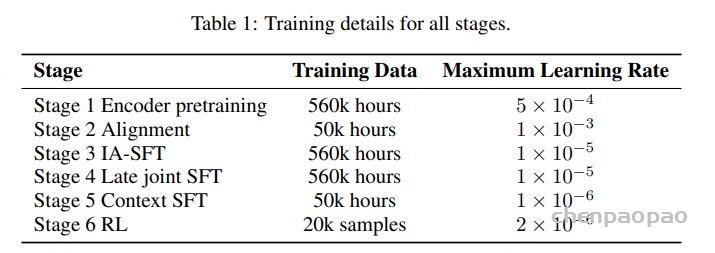
Training Setup
Robustness enhancement under noisy and silent conditions。应用了多种数据增强技巧来提高模型的鲁棒性。除了标准的 SpecAugmentation 和速度扰动之外,我们还随机地将一些真实的声学干扰(例如人声、车辆噪声和背景音乐)注入到 20%的干净训练样本中,以模拟具有挑战性的真实世界环境。这些噪声注入的信噪比(SNR)是从均值为 10 dB、标准差为 5 dB 的正态分布中随机抽取的。
Inference
优化流式推理
Encoder 与 LLM 解耦部署,Encoder 部署在 Triton,Adaptor + LLM 部署在 vLLM,CTC Head + RAG 部署在 CPU
Prompt 结构设计
[Static Prefix]
↓
[Streaming Speech Embeddings] 增量 append 到 context
↓
[Dynamic Hotword Context] 动态更新热词两种 Streaming ASR Paradigm:
增量假设刷新(hypothesis refresh)
vs
incremental context extension(增量上下文扩展)
| 方案 | hypothesis refresh | incremental extension |
| ------------------- | ------------------ | --------------------- |
| 历史是否重复 decode | 是 | 否 |
| KV Cache 是否重建 | 经常 | 基本不 |
| 是否实时 partial output | 强 | 弱 |
| TTFT | 更低 | 略高 |
| Tail latency | 高 | 低 |
| 适合场景 | 长会议 | 实时语音助手 |
Phoneme-based RAG(音素级热词检索)
文本 -> 音素序列,使用 Aho-Corasick 自动机,采用 Hard Matching不做模糊匹配,Retrieval Error 比 Retrieval Miss 更危险。
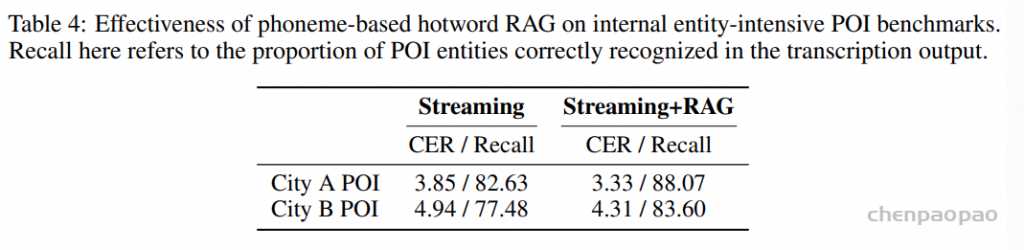
为了实现高效的热词定制,NIM4-ASR 构建了一个基于音素的热词数据库以及相应的检索算法,如图 1 所示。将每个热词文本预先转换为音素-词元序列,并将其存储为键值对,其中键是音素序列,值是对应的热词文本。这些音素序列首先根据音素词汇表转换为离散索引,然后使用 Aho-Corasick 自动机算法重构为带有失败链接的 trie 树。在推理过程中,编码器上的音素头通过贪婪解码生成音素假设,这些假设被转换为索引序列,并由自动机在一次遍历中扫描完成。当无法扩展部分匹配时,自动机将沿着失败链接找到最长的有效后缀状态,而不是从头开始重新搜索,从而能够以假设长度的线性时间复杂度检索所有候选热词。
为了减少冗余的上下文提示,我们采用了一种最长匹配过滤策略:被较长跨度完全覆盖的较短匹配项将被丢弃,仅保留最长的实体。例如,如果热词“NIO”和“NIO House”在同一假设中同时匹配,则仅保留“NIO House”。检索到的热词文本随后被连接起来,并与语音嵌入一起作为上下文提示注入到 LLM 提示中,从而为解码提供上下文感知的偏置。由于索引级映射的存储效率以及 Aho-Corasick 自动机的线性时间复杂度(仅取决于查询长度而非数据库大小),热词数据库可以轻松扩展到数百万条记录,同时保持每次查询的亚毫秒级检索延迟。
值得注意的是,我们的热词定制旨在优化命名实体(例如地点名称和媒体标题)的识别,这类热词数据库可能非常庞大,并且可能包含大量语音相似甚至同音的条目。为了确保在这种大规模环境下的检索精度,我们在 RAG 模块中采用了硬匹配策略,仅检索精确的音素序列匹配,而非近似匹配或编辑距离最小的匹配。经验表明,检索漏检通常比检索错误危害更小,因为 LLM 仍然可以利用内部语言知识和上下文恢复正确的实体。相比之下,软匹配更容易引入相似但错误的热词,即使模型在一定程度上能够应对噪声上下文提示,这些错误热词仍然会干扰解码。
Evaluation
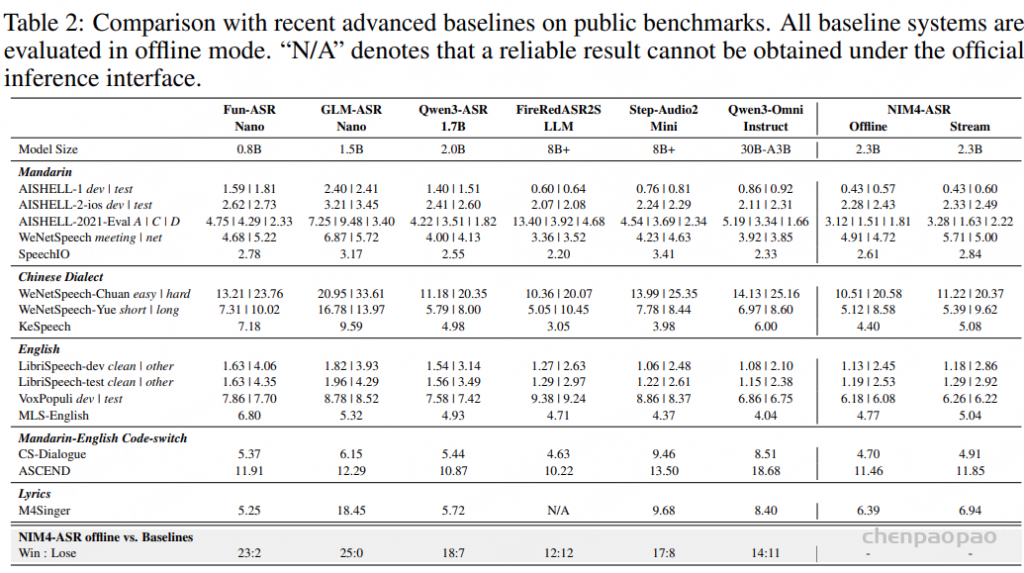
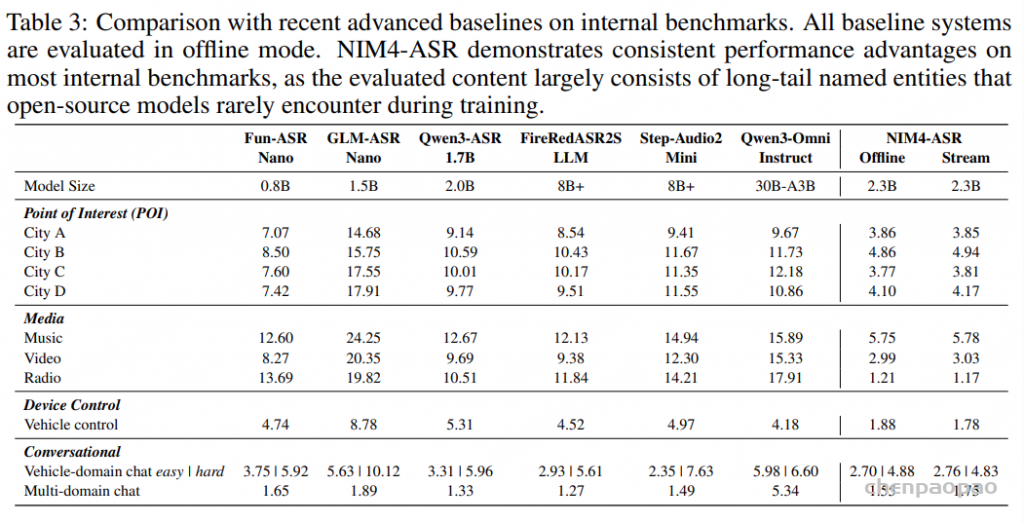
总结:
NIO 车载场景出发的工业论文,偏向工程落地。phoneme-level encoder 预训练、IA-SFT 防 drift、ASR-RL、百万热词 RAG——每个模块都是真实生产痛点的解法。CKA 动态监控 encoder 表示偏移这个手段很细。但核心数据不公开,学术可复现性为零;”25 个 benchmark SOTA”要打折——主要赢在内部实体密集场景;Streaming 支持是”优化了”而非”重新设计了”。热词检索口音/方言效果差。未来将对话历史作为附加上下文信息纳入多轮交互场景,以提高跨轮次转录的一致性。