
Huggingface Transformers 是基于一个开源基于 transformer 模型结构提供的预训练语言库,它支持 Pytorch,Tensorflow2.0,并且支持两个框架的相互转换。框架支持了最新的各种NLP预训练语言模型,使用者可以很快速的进行模型的调用,并且支持模型further pretraining 和 下游任务fine-tuning。
- paper: https://arxiv.org/pdf/1910.03771.pdf (EMNLP Best Demo 2020)
- github: https://github.com/huggingface/transformers
- 官方教程: https://huggingface.co/transformers

该库是使用 BERT 等预训练模型的最常用的库,甚至超过了google等开源的源代码。它的设计原则保证了它支持各种不同的预训练模型,并且有统一的合理的规范。使用者可以很方便的进行模型的下载,以及使用。同时,它支持用户自己上传自己的预训练模型到Model Hub中,提供其他用户使用。对于NLP从业者,可以使用这个库,很方便地进行自然语言理解(NLU) 和 自然语言生成(NLG)任务的SOTA模型使用。
特色:
- 超级 简单,快速上手
- 适合于所有人 – NLP研究员,NLP应用人员,教育工作者
- NLU/NLG SOTA 模型支持
- 减少预训练成本,提供了30+预训练模型,100+语言 – 支持Pytorch 与 Tensorflow2.0 转换。
- 以下为部分整合的预训练语言模型, ref: Transformers Github:

🤗 Transformers 提供了数以千计的预训练模型,支持 100 多种语言的文本分类、信息抽取、问答、摘要、翻译、文本生成。它的宗旨让最先进的 NLP 技术人人易用。
🤗 Transformers 提供了便于快速下载和使用的API,让你可以把预训练模型用在给定文本、在你的数据集上微调然后通过 model hub 与社区共享。同时,每个定义的 Python 模块均完全独立,方便修改和快速研究实验。
🤗 Transformers 支持三个最热门的深度学习库: Jax, PyTorch and TensorFlow — 并与之无缝整合。你可以直接使用一个框架训练你的模型然后用另一个加载和推理。
在线演示
你可以直接在模型页面上测试大多数 model hub 上的模型。 我们也提供了 私有模型托管、模型版本管理以及推理API。
这里是一些例子:
- 用 BERT 做掩码填词
- 用 Electra 做命名实体识别
- 用 GPT-2 做文本生成
- 用 RoBERTa 做自然语言推理
- 用 BART 做文本摘要
- 用 DistilBERT 做问答
- 用 T5 做翻译
快速上手
我们为快速使用模型提供了 pipeline (流水线)API。流水线聚合了预训练模型和对应的文本预处理。下面是一个快速使用流水线去判断正负面情绪的例子:
>>> from transformers import pipeline
# 使用情绪分析流水线
>>> classifier = pipeline('sentiment-analysis')
>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
第二行代码下载并缓存了流水线使用的预训练模型,而第三行代码则在给定的文本上进行了评估。这里的答案“正面” (positive) 具有 99 的置信度。
许多的 NLP 任务都有开箱即用的预训练流水线。比如说,我们可以轻松的从给定文本中抽取问题答案:
>>> from transformers import pipeline
# 使用问答流水线
>>> question_answerer = pipeline('question-answering')
>>> question_answerer({
... 'question': 'What is the name of the repository ?',
... 'context': 'Pipeline has been included in the huggingface/transformers repository'
... })
{'score': 0.30970096588134766, 'start': 34, 'end': 58, 'answer': 'huggingface/transformers'}
除了给出答案,预训练模型还给出了对应的置信度分数、答案在词符化 (tokenized) 后的文本中开始和结束的位置。你可以从这个教程了解更多流水线API支持的任务。
要在你的任务上下载和使用任意预训练模型也很简单,只需三行代码。这里是 PyTorch 版的示例:
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
>>> model = AutoModel.from_pretrained("bert-base-uncased")
>>> inputs = tokenizer("Hello world!", return_tensors="pt")
>>> outputs = model(**inputs)
这里是等效的 TensorFlow 代码:
>>> from transformers import AutoTokenizer, TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
>>> model = TFAutoModel.from_pretrained("bert-base-uncased")
>>> inputs = tokenizer("Hello world!", return_tensors="tf")
>>> outputs = model(**inputs)
词符化器 (tokenizer) 为所有的预训练模型提供了预处理,并可以直接对单个字符串进行调用(比如上面的例子)或对列表 (list) 调用。它会输出一个你可以在下游代码里使用或直接通过 ** 解包表达式传给模型的词典 (dict)。
模型本身是一个常规的 Pytorch nn.Module 或 TensorFlow tf.keras.Model(取决于你的后端),可以常规方式使用。 这个教程解释了如何将这样的模型整合到经典的 PyTorch 或 TensorFlow 训练循环中,或是如何使用我们的 Trainer 训练器)API 来在一个新的数据集上快速微调。
为什么要用 transformers?
- 便于使用的先进模型:
- NLU 和 NLG 上表现优越
- 对教学和实践友好且低门槛
- 高级抽象,只需了解三个类
- 对所有模型统一的API
- 更低计算开销,更少的碳排放:
- 研究人员可以分享亿训练的模型而非次次从头开始训练
- 工程师可以减少计算用时和生产环境开销
- 数十种模型架构、两千多个预训练模型、100多种语言支持
- 对于模型生命周期的每一个部分都面面俱到:
- 训练先进的模型,只需 3 行代码
- 模型在不同深度学习框架间任意转移,随你心意
- 为训练、评估和生产选择最适合的框架,衔接无缝
- 为你的需求轻松定制专属模型和用例:
- 我们为每种模型架构提供了多个用例来复现原论文结果
- 模型内部结构保持透明一致
- 模型文件可单独使用,方便魔改和快速实验
什么情况下我不该用 transformers?
- 本库并不是模块化的神经网络工具箱。模型文件中的代码特意呈若璞玉,未经额外抽象封装,以便研究人员快速迭代魔改而不致溺于抽象和文件跳转之中。
-
TrainerAPI 并非兼容任何模型,只为本库之模型优化。若是在寻找适用于通用机器学习的训练循环实现,请另觅他库。 - 尽管我们已尽力而为,examples 目录中的脚本也仅为用例而已。对于你的特定问题,它们并不一定开箱即用,可能需要改几行代码以适之。
了解更多
| 章节 | 描述 |
|---|---|
| 文档 | 完整的 API 文档和教程 |
| 任务总结 | 🤗 Transformers 支持的任务 |
| 预处理教程 | 使用 Tokenizer 来为模型准备数据 |
| 训练和微调 | 在 PyTorch/TensorFlow 的训练循环或 Trainer API 中使用 🤗 Transformers 提供的模型 |
| 快速上手:微调和用例脚本 | 为各种任务提供的用例脚本 |
| 模型分享和上传 | 和社区上传和分享你微调的模型 |
| 迁移 | 从 pytorch-transformers 或 pytorch-pretrained-bert 迁移到 🤗 Transformers |
Transformers model hub
Transformers model hub 提供了不同的预训练语言模型,包含了常见的Robert/BERT/XLNET/以及BART 等,几乎所有的最新模型都可以在上面找到。用户可以很方便地对模型进行调用,只需要一个模型的名字,就可以获取模型文件。
model = AutoModel.from_pretrained(model_name)设计原则 Design Principles
Transformers 的设计是为了:
- 研究者可以进行拓展
- 单个modeling的文件,直接在一个文件中就可以修改模型所需要的所有部分,最小化的模块设计。
- 算法工程师可以轻松使用 – 可以使用 pipeline 直接调用,获取开箱即用的任务体验,例如情感分析的任务等。可以使用trainers 进行训练,支持fp16,分布式等
- 工业实践中可以快速部署且鲁棒性良好
- CPU/GPU/TPU支持,可以进行优化,支持torchscript 静态图,支持ONNX格式
库设计 Library Design
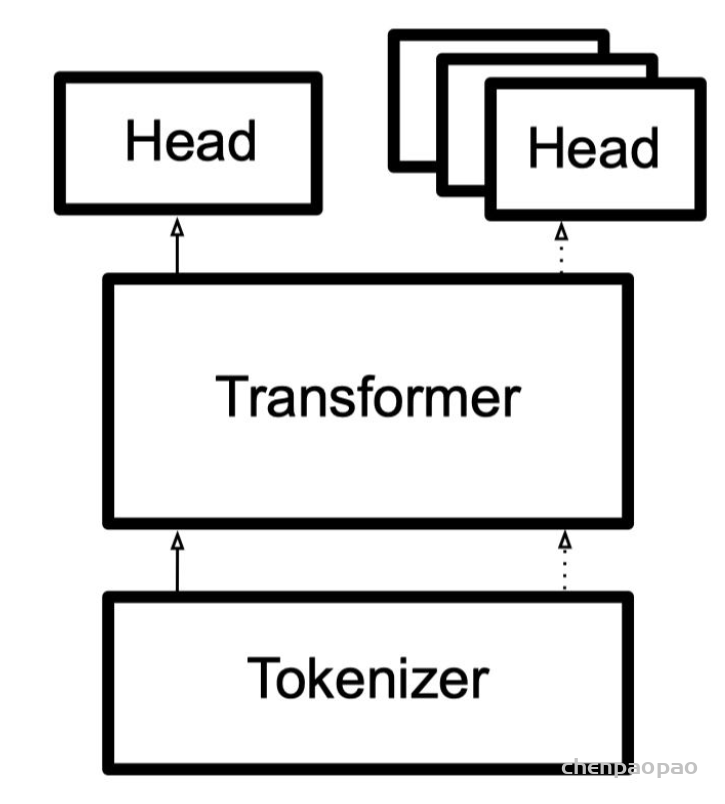
transformers 库包含了机器学习相关的主要三个部分:数据处理process data, 模型应用 apply a model, 和做出预测make predictions。分别对应的如下三个模块:Tokenizer,Transformers,以及 Head。
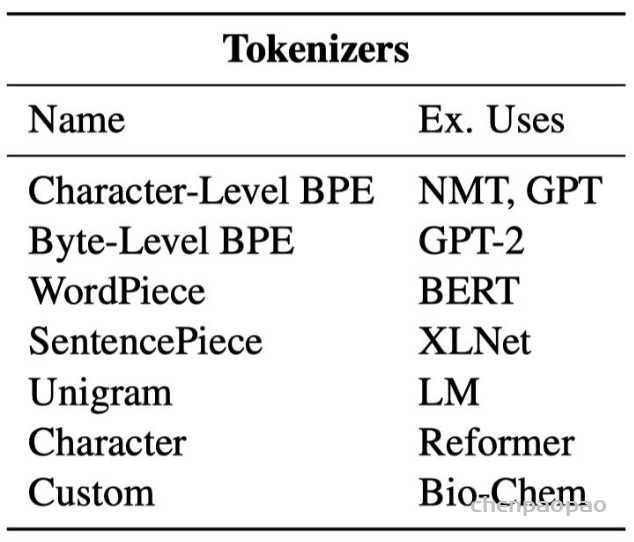
- Tokenizers 分词器,支持不同的分词。主要作用是将输入进行分词化后,并转化为相应模型需要的embedding。
Tokenizer 类支持从预训练模型中进行加载或者直接手动配置。这些类存储了 token 到 id 的字典,并且可以对输入进行分词,和decode。huggingface transformers 已经提供了如下图的相关tokenizer 分词器。用户也可以很轻松的对tokenizer 里的特殊字符进行更换,例如CLS/SEP。或者是对Tokenizer模型的字典进行大小修改等。
Tokenizer 提供了很多有用的方法,例如padding,truncating,用户可以很方便的对其进行使用。
Transformer transformers 指的是各种基于transformer结构的预训练语言模型,例如BERT,GPT等。它将输入的sparse的序列,转化为上下文感知的的 contextual embedding。
encoder 模型的计算图通常就是对模型输入进行一系列的 self-attention 操作,然后得到最后的encoder的输出。通常情况下,每个模型都是在一个文件中被定义完成的,这样方便用户进行更改和拓展。
针对不同的模型结构,都采用相同的API,这使得用户可以快速地使用不同的其他模型。transformers 提供 一系列的Auto classes,使得快速进行模型切换非常方便。
model = AutoModel.from_pretrained(model_name)-
Head 不同于attention的head,这边的 head 指的是下游任务的输出层,它将模型的contextual embedding 转化为特定任务的预测值,包含如下的不同的head:
-
Pretraining Head
- Casual Language Modeling(普通自回归的语言模型):GPT, GPT-2,CTRL
- Masked Language Modeling(掩码语言模型):BERT, RoBERTa
- Permuted Language Modeling(乱序重排语言模型):XLNet
-
Fine-tuning Head
- Language Modeling:语言模型训练,预测下一个词。主要用于文本生成
- Sequence Classification:文本分类任务,情感分析任务
- Question Answering:机器阅读理解任务,QA
- Token Classification:token级别的分类,主要用于命名实体识别(NER)任务,句法解析Tagging任务
- Multiple Choice:多选任务,主要是文本选择任务
- Masked LM:掩码预测,随机mask一个token,预测该 token 是什么词,用于预训练
- Conditional Generation:条件生成任务,主要用于翻译以及摘要任务。
-
Pretraining Head
这些模型的head,是在模型文件集中上,包装的另外一个类,它提供了额外的输出层,loss函数等。 这些层的命名规范也很一致,采用的是: XXXForSequenceClassification
其中 XXX 是模型的下游任务(fine-tuning) 或者与训练 pretraining 任务。一些head,例如条件生成(conditional generation),支持额外的功能,像是sampling and beam search。
下图解释了每个head 的输入和输出以及数据集。
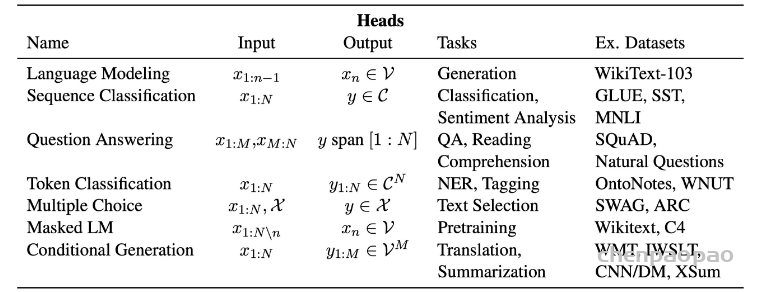
下面的代码展示了如何使用 transformers 进行下游的文本分类任务:
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)Huggingface Transformer 使用方法(教程)
Transformers提供了数以千计针对于各种任务的预训练模型模型,开发者可以根据自身的需要,选择模型进行训练或微调,也可阅读api文档和源码, 快速开发新模型。
0、Setup
1)安装一个非常轻量级的 Transformers
!pip install transformers然后
import transformers2)建议安装开发版本,几乎带有所有用例需要的依赖项
!pip install transformers[sentencepiece]一、模型简介 Transformer models
1. pipelines 简单的小例子
Transformers 库中最基本的对象是
pipeline()函数。它将模型与其必要的预处理和后处理步骤连接起来,使我们能够直接输入任何文本并获得答案:
当第一次运行的时候,它会下载预训练模型和分词器(tokenizer)并且缓存下来。
from transformers import pipeline
classifier = pipeline("sentiment-analysis") # 情感分析
classifier("I've been waiting for a HuggingFace course my whole life.")
# 输出
# [{'label': 'POSITIVE', 'score': 0.9598047137260437}]也可以传几句话:
classifier(
["I've been waiting for a HuggingFace course my whole life.", "I hate this so much!"]
)
# 输出
'''
[{'label': 'POSITIVE', 'score': 0.9598047137260437},
{'label': 'NEGATIVE', 'score': 0.9994558095932007}]
'''目前可用的一些pipeline 有:
feature-extraction特征提取:把一段文字用一个向量来表示fill-mask填词:把一段文字的某些部分mask住,然后让模型填空ner命名实体识别:识别文字中出现的人名地名的命名实体question-answering问答:给定一段文本以及针对它的一个问题,从文本中抽取答案sentiment-analysis情感分析:一段文本是正面还是负面的情感倾向summarization摘要:根据一段长文本中生成简短的摘要text-generation文本生成:给定一段文本,让模型补充后面的内容translation翻译:把一种语言的文字翻译成另一种语言zero-shot-classification
这些pipeline的具体例子可见:Transformer models – Hugging Face Course
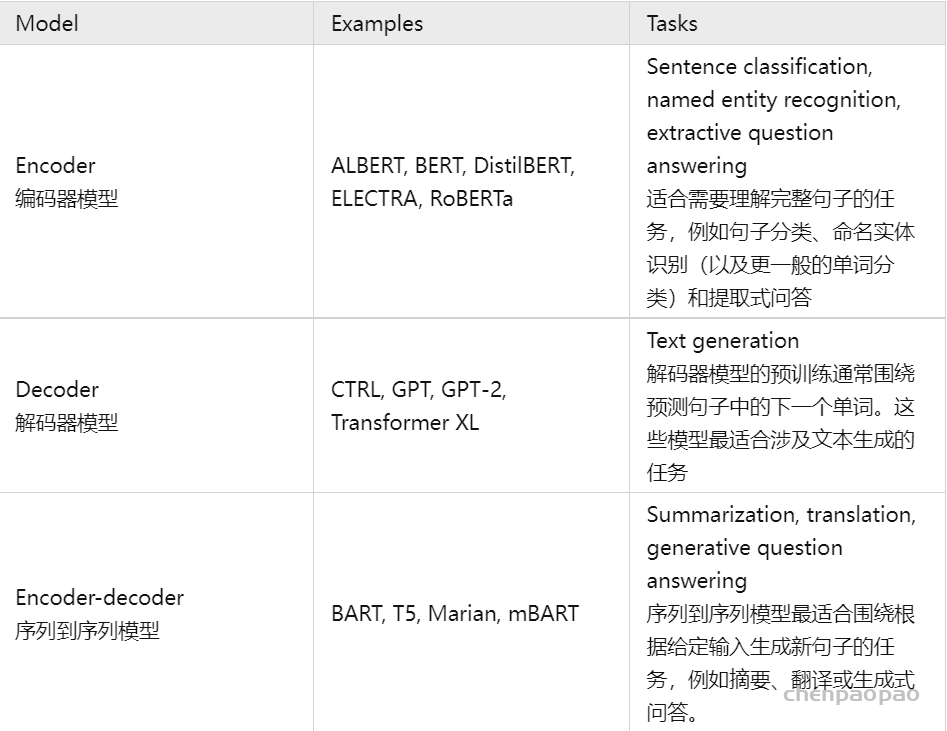
2. 各种任务的代表模型
二、 使用 Using Transformers
1. Pipeline 背后的流程
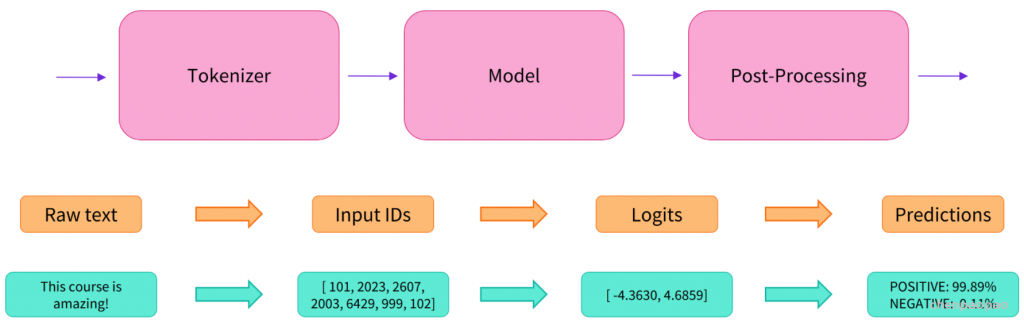
在接收文本后,通常有三步:Tokenizer、Model、Post-Processing。
1)Tokenizer
与其他神经网络一样,Transformer 模型不能直接处理原始文本,故使用分词器进行预处理。使用AutoTokenizer类及其from_pretrained()方法。
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)若要指定我们想要返回的张量类型(PyTorch、TensorFlow 或普通 NumPy),我们使用return_tensors参数
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)PyTorch 张量的结果:
输出本身是一个包含两个键的字典,input_ids和attention_mask。
{
'input_ids': tensor([
[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],
[ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0]
]),
'attention_mask': tensor([
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
])
}2)Model
Transformers 提供了一个AutoModel类,它也有一个from_pretrained()方法:
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)如果我们将预处理过的输入提供给我们的模型,我们可以看到:
outputs = model(**inputs)
print(outputs.last_hidden_state.shape)
# 输出
# torch.Size([2, 16, 768])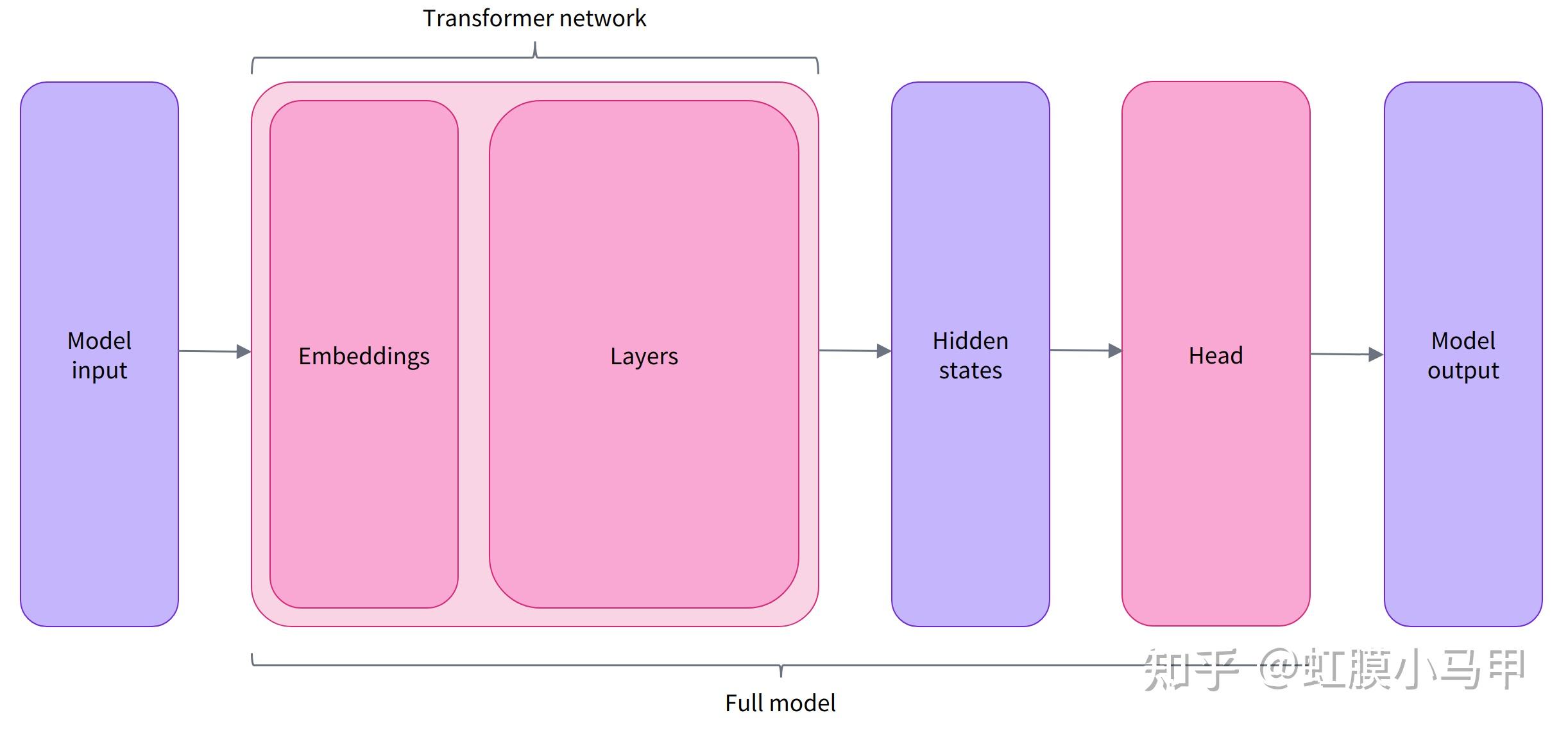
Transformers 中有许多不同的架构可用,每一种架构都围绕着处理特定任务而设计,清单:
*Model(retrieve the hidden states)*ForCausalLM*ForMaskedLM*ForMultipleChoice*ForQuestionAnswering*ForSequenceClassification*ForTokenClassification
and others
3)Post-Processing
模型最后一层输出的原始非标准化分数。要转换为概率,它们需要经过一个SoftMax层(所有 Transformers 模型都输出 logits,因为用于训练的损耗函数一般会将最后的激活函数(如SoftMax)与实际损耗函数(如交叉熵)融合 。
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)2. Models
1)创建Transformer
from transformers import BertConfig, BertModel
# Building the config
config = BertConfig()
# Building the model from the config
model = BertModel(config)2)不同的加载方式
from transformers import BertModel
model = BertModel.from_pretrained("bert-base-cased")3)保存模型
model.save_pretrained("directory_on_my_computer")4)使用Transformer model
sequences = ["Hello!", "Cool.", "Nice!"]
encoded_sequences = [
[101, 7592, 999, 102],
[101, 4658, 1012, 102],
[101, 3835, 999, 102],
]
import torch
model_inputs = torch.tensor(encoded_sequences)3. Tokenizers
1)Loading and saving
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
tokenizer("Using a Transformer network is simple")
# 输出
'''
{'input_ids': [101, 7993, 170, 11303, 1200, 2443, 1110, 3014, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
'''
# 保存
tokenizer.save_pretrained("directory_on_my_computer")2)Tokenization
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
sequence = "Using a Transformer network is simple"
tokens = tokenizer.tokenize(sequence)
print(tokens) # 输出 : ['Using', 'a', 'transform', '##er', 'network', 'is', 'simple']
# 从token 到输入 ID
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids) # 输出:[7993, 170, 11303, 1200, 2443, 1110, 3014]3) Decoding
decoded_string = tokenizer.decode([7993, 170, 11303, 1200, 2443, 1110, 3014])
print(decoded_string) # 输出:'Using a Transformer network is simple'4. 处理多个序列 Handling multiple sequences
1) 模型需要一批输入 Models expect a batch of inputs
将数字列表转换为张量并将其发送到模型:
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence = "I've been waiting for a HuggingFace course my whole life."
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
input_ids = torch.tensor([ids])
print("Input IDs:", input_ids)
output = model(input_ids)
print("Logits:", output.logits)
# 输出
'''
Input IDs: [[ 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012]]
Logits: [[-2.7276, 2.8789]]
'''2) 填充输入 Padding the inputs
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence1_ids = [[200, 200, 200]]
sequence2_ids = [[200, 200]]
batched_ids = [
[200, 200, 200],
[200, 200, tokenizer.pad_token_id],
]
print(model(torch.tensor(sequence1_ids)).logits)
print(model(torch.tensor(sequence2_ids)).logits)
print(model(torch.tensor(batched_ids)).logits)
# 输出
'''
tensor([[ 1.5694, -1.3895]], grad_fn=<AddmmBackward>)
tensor([[ 0.5803, -0.4125]], grad_fn=<AddmmBackward>)
tensor([[ 1.5694, -1.3895],
[ 1.3373, -1.2163]], grad_fn=<AddmmBackward>)
'''5. 总结 Putting it all together
我们已经探索了分词器的工作原理,并研究了分词 tokenizers、转换为输入 ID conversion to input IDs、填充 padding、截断 truncation和注意力掩码 attention masks。Transformers API 可以通过高级函数为我们处理所有这些。
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)# 可以标记单个序列
sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
# 还可以一次处理多个序列
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
model_inputs = tokenizer(sequences)# 可以根据几个目标进行填充
# Will pad the sequences up to the maximum sequence length
model_inputs = tokenizer(sequences, padding="longest")
# Will pad the sequences up to the model max length
# (512 for BERT or DistilBERT)
model_inputs = tokenizer(sequences, padding="max_length")
# Will pad the sequences up to the specified max length
model_inputs = tokenizer(sequences, padding="max_length", max_length=8)# 还可以截断序列
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
# Will truncate the sequences that are longer than the model max length
# (512 for BERT or DistilBERT)
model_inputs = tokenizer(sequences, truncation=True)
# Will truncate the sequences that are longer than the specified max length
model_inputs = tokenizer(sequences, max_length=8, truncation=True)# 可以处理到特定框架张量的转换,然后可以将其直接发送到模型。
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
# Returns PyTorch tensors
model_inputs = tokenizer(sequences, padding=True, return_tensors="pt")
# Returns TensorFlow tensors
model_inputs = tokenizer(sequences, padding=True, return_tensors="tf")
# Returns NumPy arrays
model_inputs = tokenizer(sequences, padding=True, return_tensors="np")Special tokens
分词器在开头添加特殊词[CLS],在结尾添加特殊词[SEP]。
sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
print(model_inputs["input_ids"])
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
# 输出
'''
[101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102]
[1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012]
'''
print(tokenizer.decode(model_inputs["input_ids"]))
print(tokenizer.decode(ids))
# 输出
'''
"[CLS] i've been waiting for a huggingface course my whole life. [SEP]"
"i've been waiting for a huggingface course my whole life."
'''# 总结:从分词器到模型
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
tokens = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
output = model(**tokens)Huggingface Transformers库学习笔记(二):使用Transformers(上)(Using Transformers Part 1): https://blog.csdn.net/u011426236/article/details/115460564