transformerr特点:
·是一个encoder-decoder模型
·非RNN模型
·完全基于全连接和注意力
·性能远超RNN(大数据集)
回忆seq-seq模型:
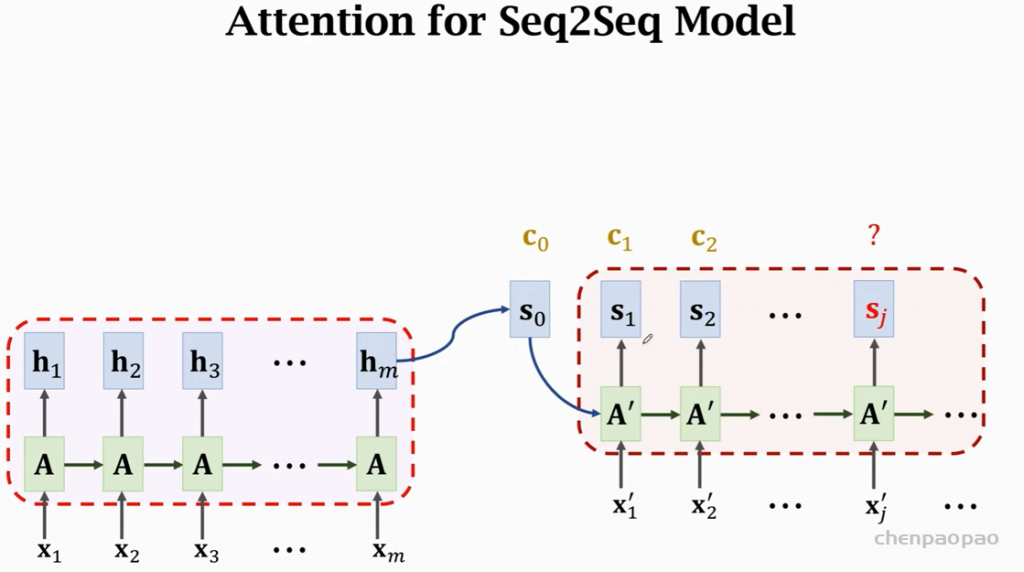
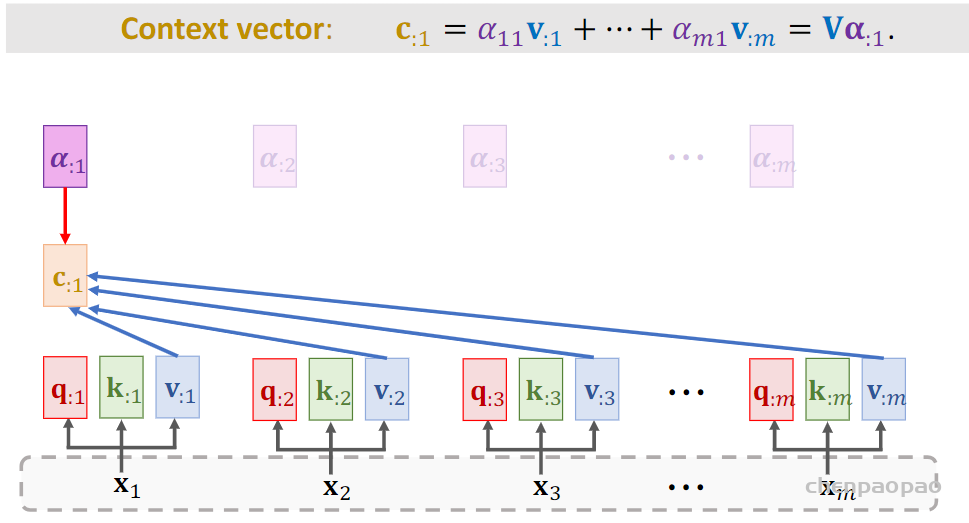
如何求c:


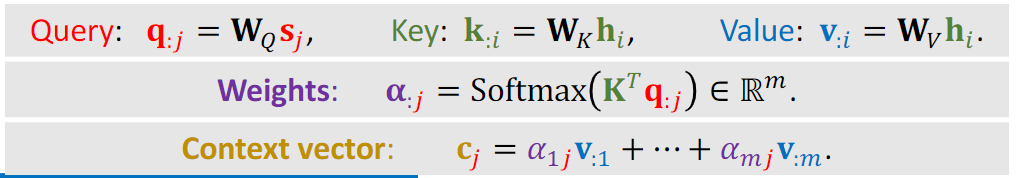
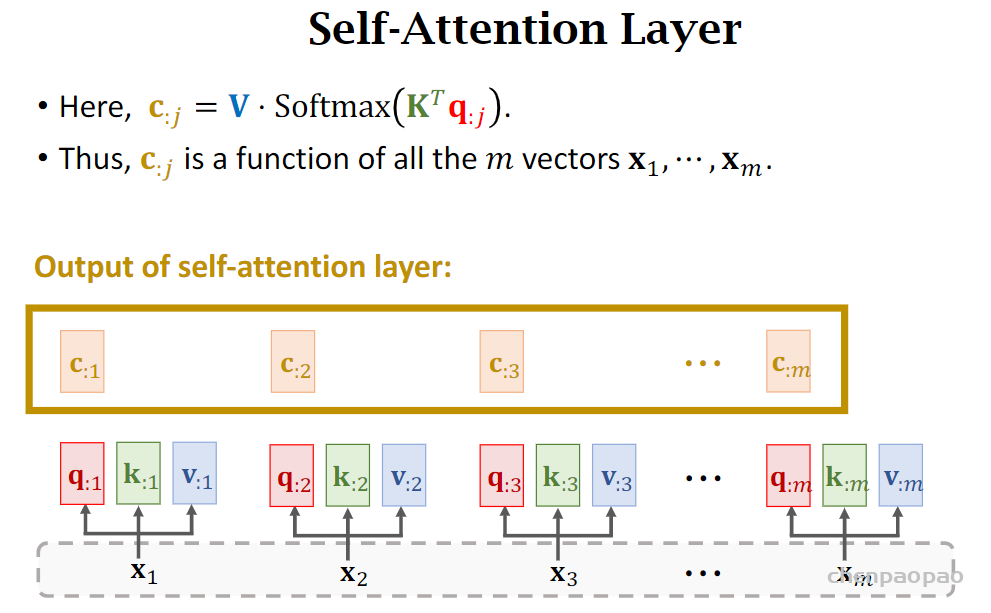
如何从RNN到transformer:自注意力层

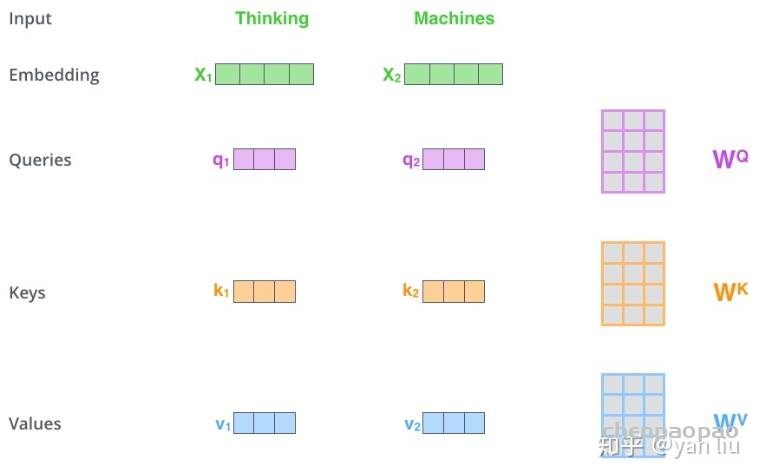
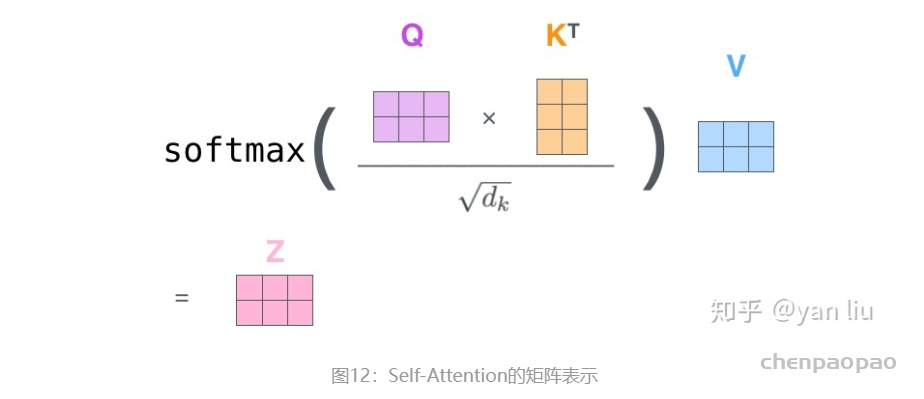
在self-attention中,每个单词有3个不同的向量,它们分别是Query向量( Q ),Key向量( K )和Value向量( V ),长度均是64。它们是通过3个不同的权值矩阵由嵌入向量 X 乘以三个不同的权值矩阵 WQ , WK , WV 得到,其中三个矩阵的尺寸也是相同的。均是 512×64 。

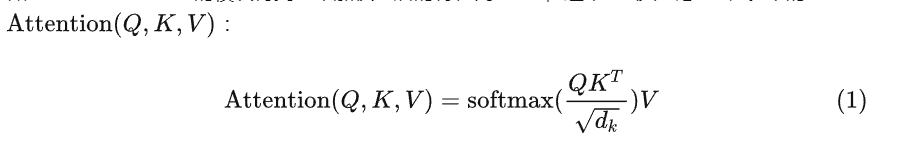

总结为如下图所示的矩阵形式:
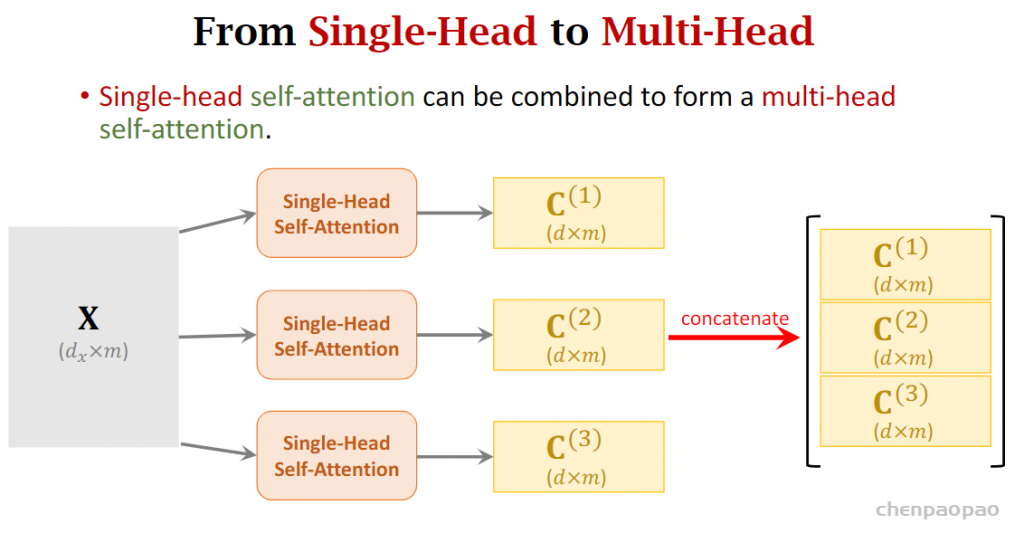
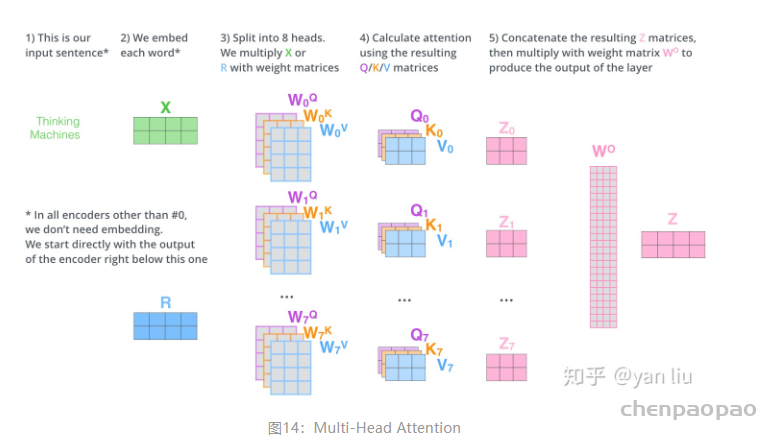
搭建transfomer:多头自注意力层
上面给出的是一个自注意力层,我们使用N个相同的层,并行,不同注意力层不共享参数。将多头的输出进行堆叠作为多头注意力层的输出。

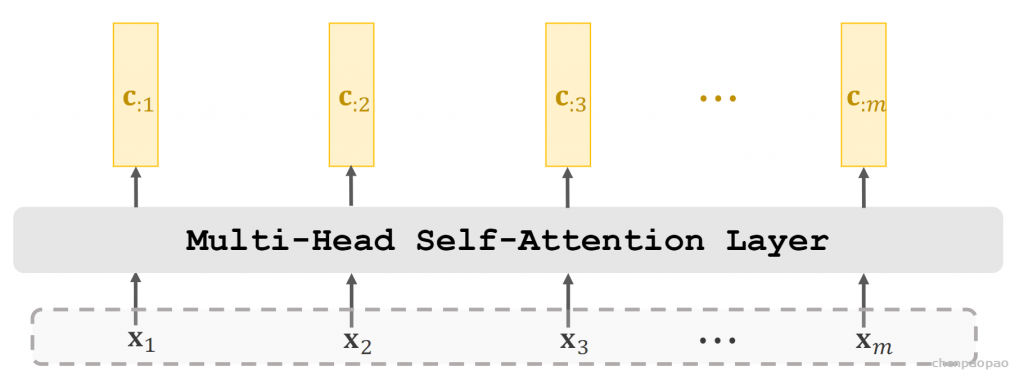

Stacked Self-Attention Layers
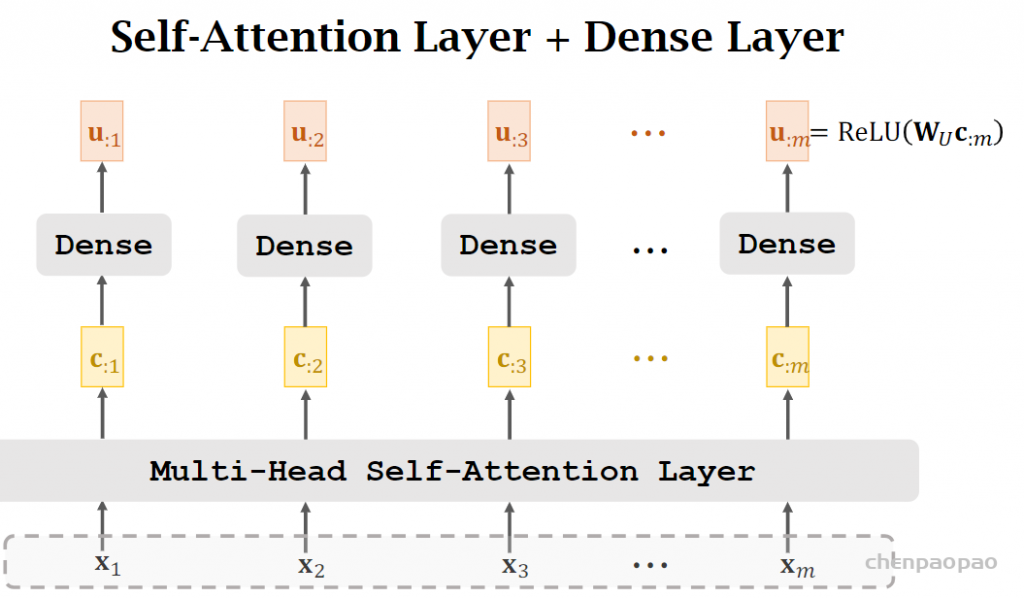
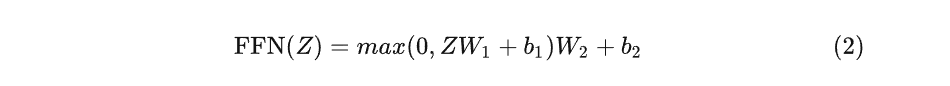
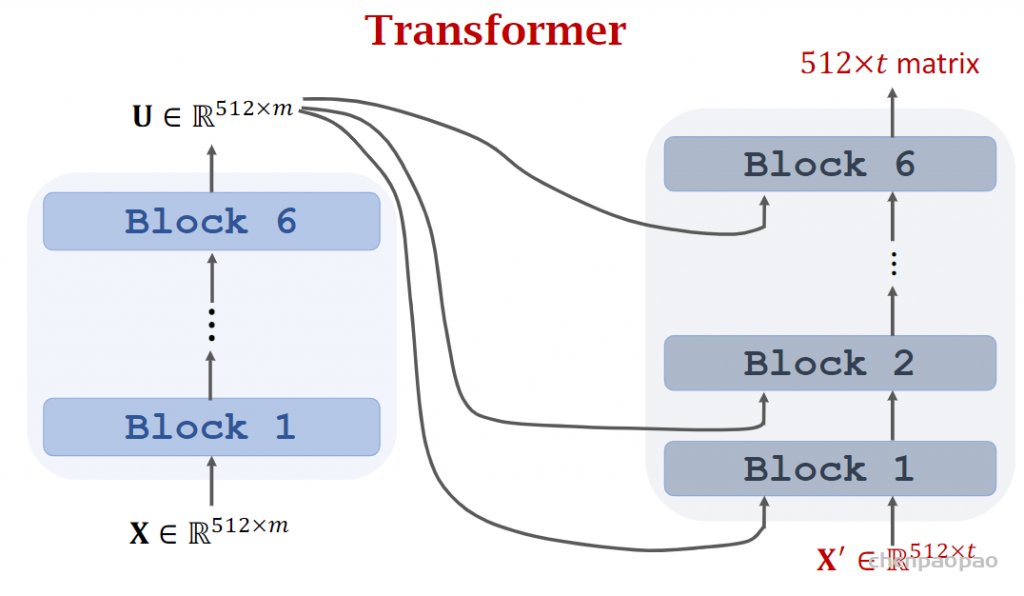
一个encoder block:
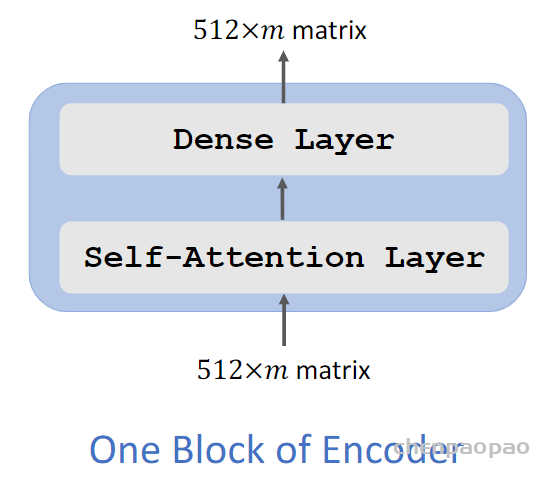
最终 堆叠6个:作为transfomer encoder:
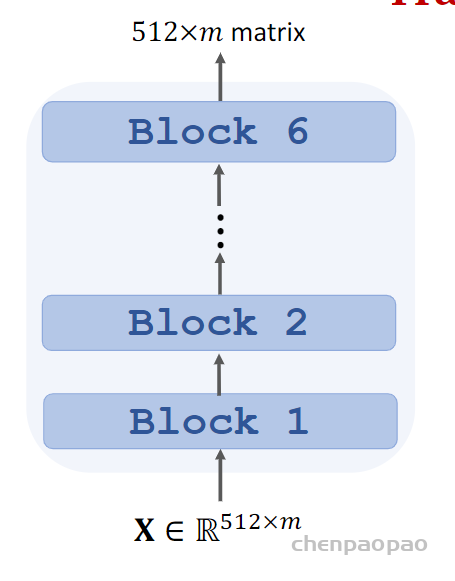
decoder部分:

encoder block:
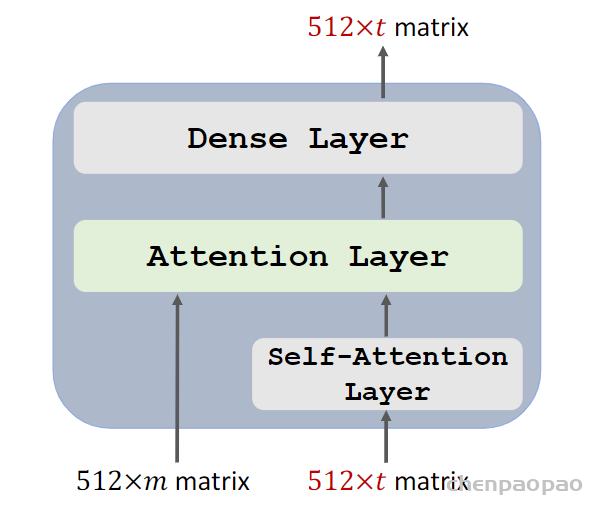
整体网络: