code:https://github.com/microsoft/Swin-Transformer
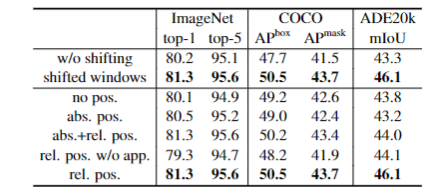
Swin MLP 代码来自 Swin Transformer 的官方实现。Swin Transformer 作者们在已有模型的基础上实现了 Swin MLP 模型,证明了 Window-based attention 对于 MLP 模型的有效性。
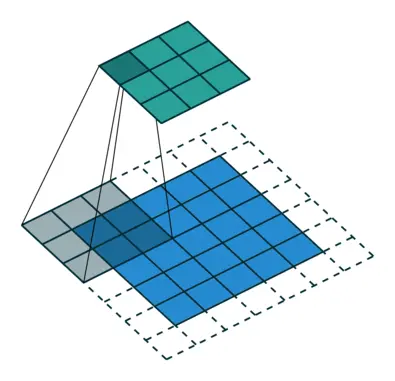
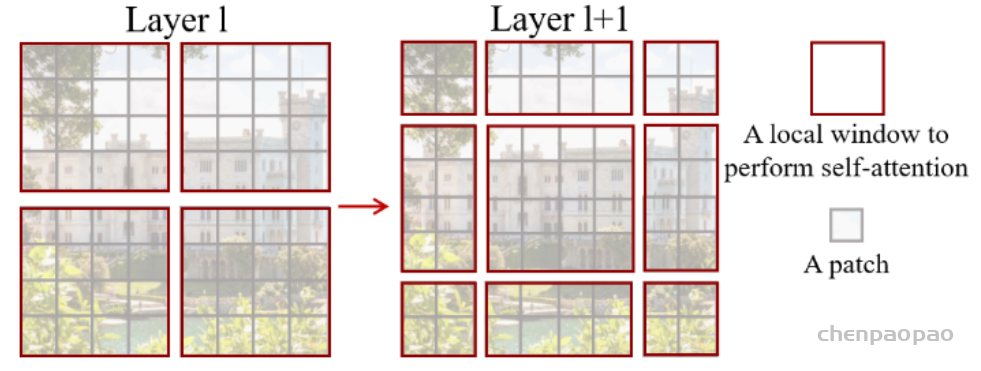
把张量 (B, H, W, C) 分成 window (B×H/M×W/M, M, M, C),其中M是 window_size。这一步相当于得到 B×H/M×W/M 个大小为 (M, M, C) 的 window。
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
把 window (B×H/M×W/M, M, M, C) 变回张量 (B, H, W, C)。
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
一个 Swin MLP Block
class SwinMLPBlock(nn.Module):
r""" Swin MLP Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
drop (float, optional): Dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.shift_size = 0
self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.padding = [self.window_size - self.shift_size, self.shift_size,
self.window_size - self.shift_size, self.shift_size] # P_l,P_r,P_t,P_b
self.norm1 = norm_layer(dim)
# use group convolution to implement multi-head MLP
self.spatial_mlp = nn.Conv1d(self.num_heads * self.window_size ** 2,
self.num_heads * self.window_size ** 2,
kernel_size=1,
groups=self.num_heads)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
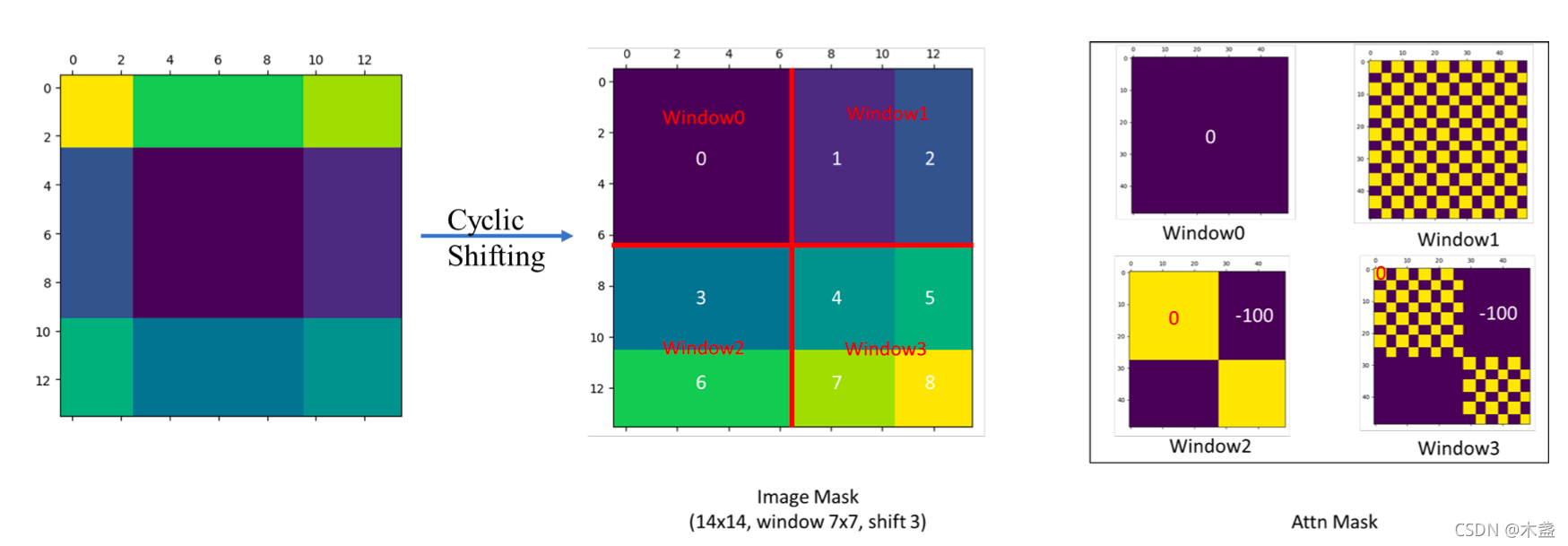
# shift
if self.shift_size > 0:
P_l, P_r, P_t, P_b = self.padding
shifted_x = F.pad(x, [0, 0, P_l, P_r, P_t, P_b], "constant", 0)
else:
shifted_x = x
_, _H, _W, _ = shifted_x.shape
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# Window/Shifted-Window Spatial MLP
x_windows_heads = x_windows.view(-1, self.window_size * self.window_size, self.num_heads, C // self.num_heads)
x_windows_heads = x_windows_heads.transpose(1, 2) # nW*B, nH, window_size*window_size, C//nH
x_windows_heads = x_windows_heads.reshape(-1, self.num_heads * self.window_size * self.window_size,
C // self.num_heads)
spatial_mlp_windows = self.spatial_mlp(x_windows_heads) # nW*B, nH*window_size*window_size, C//nH
spatial_mlp_windows = spatial_mlp_windows.view(-1, self.num_heads, self.window_size * self.window_size,
C // self.num_heads).transpose(1, 2)
spatial_mlp_windows = spatial_mlp_windows.reshape(-1, self.window_size * self.window_size, C)
# merge windows
spatial_mlp_windows = spatial_mlp_windows.reshape(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(spatial_mlp_windows, self.window_size, _H, _W) # B H' W' C
# reverse shift
if self.shift_size > 0:
P_l, P_r, P_t, P_b = self.padding
x = shifted_x[:, P_t:-P_b, P_l:-P_r, :].contiguous()
else:
x = shifted_x
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
f"window_size={self.window_size}, shift_size={self.shift_size}, mlp_ratio={self.mlp_ratio}"
注意 F.pad(x, [0, 0, P_l, P_r, P_t, P_b], “constant”, 0) 的对象是 x,维度是 (B, H, W, C)。
padding相当于是第3维 (C 这一维) 不填充,第2维 (W 这一维) 左右分别填充 P_l, P_r,第1维 (H 这一维) 左右分别填充 P_t, P_b。
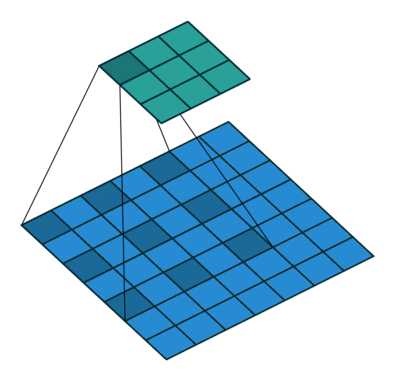
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C:
这句代码把 shifted_x 分成 nW*B 个 windows,其中每个 window 的维度是 (window_size, window_size, C)。
# reverse shift
if self.shift_size > 0:
P_l, P_r, P_t, P_b = self.padding
x = shifted_x[:, P_t:-P_b, P_l:-P_r, :].contiguous()
else:
x = shifted_x
这里是如果进行了 shift 操作,则最后取得结果也应该是没有 padding 的部分,正好是 shifted_x[:, P_t:-P_b, P_l:-P_r, :]。
一个 Swin MLP Block 的 FLOPs,注意 WSA 的计算量是:
FLOPs (WSA) = (window_size * window_size)^2 * dim * number_window
def flops(self):
flops = 0
H, W = self.input_resolution
# norm1
flops += self.dim * H * W
# Window/Shifted-Window Spatial MLP
if self.shift_size > 0:
nW = (H / self.window_size + 1) * (W / self.window_size + 1)
else:
nW = H * W / self.window_size / self.window_size
flops += nW * self.dim * (self.window_size * self.window_size) * (self.window_size * self.window_size)
# mlp
flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
# norm2
flops += self.dim * H * W
return flops
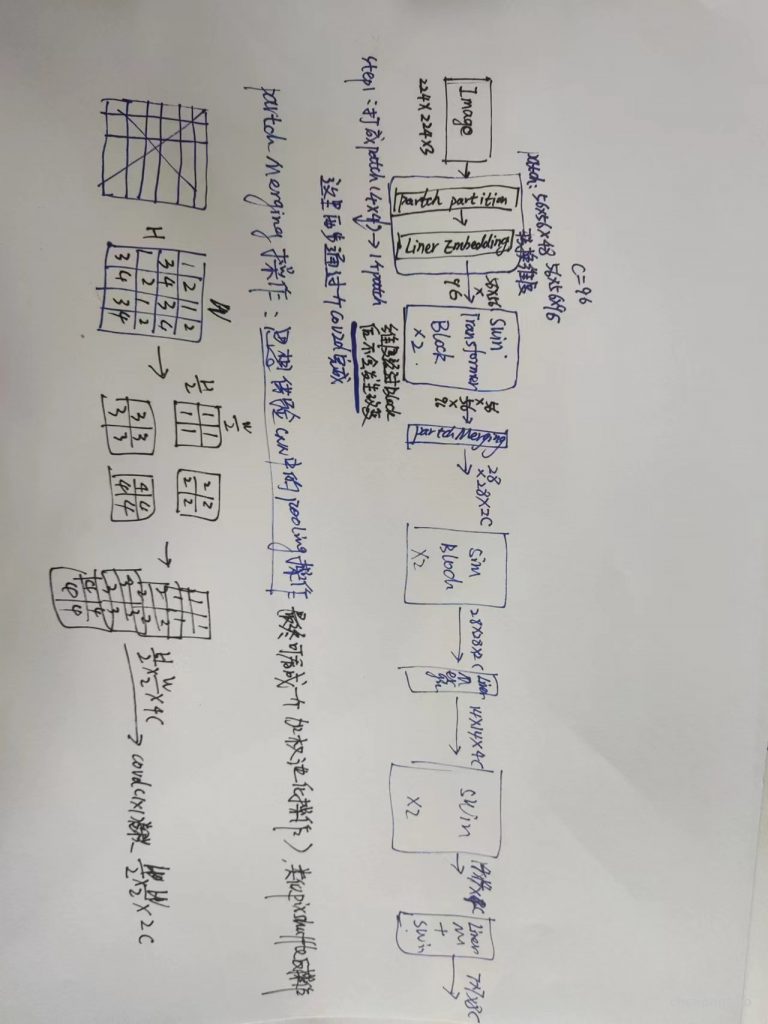
每个 stage 之间的 PatchMerging连接,把 resolution 变为一半,dim 变为2倍。
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
def flops(self):
H, W = self.input_resolution
# norm
flops = H * W * self.dim
# reduction
flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
return flops
- Patch Merging 操作把相邻的 2×2 个 tokens 给合并到一起,得到的 token 的维度是4C。
Patch Merging 操作再通过一次线性变换把维度降为2C。
一个 Swin MLP Layer
class BasicLayer(nn.Module):
""" A basic Swin MLP layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
drop (float, optional): Dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., drop=0., drop_path=0.,
norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
# build blocks
self.blocks = nn.ModuleList([
SwinMLPBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
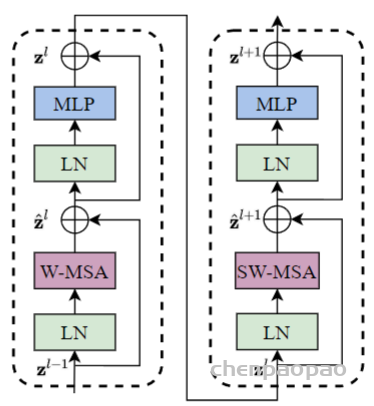
shift_size=0 if (i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
drop=drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
def flops(self):
flops = 0
for blk in self.blocks:
flops += blk.flops()
if self.downsample is not None:
flops += self.downsample.flops()
return flops
- 包含 depth 个 Swin MLP Block。
注意计算 FLOPs 的方式:每个 blk 和 downsample 都自带 flops() 方法,可以直接来调用。
PatchEmbedded 操作
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x
def flops(self):
Ho, Wo = self.patches_resolution
flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops
- 和 ViT 的 Patch Embedded 操作一样,本质上是一个 K=patch size,s=patch size 的 nn.Conv2d 操作,注意卷积 FLOPs 的计算公式即可。
SwinMLP 整体模型架构
class SwinMLP(nn.Module):
r""" Swin MLP
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin MLP layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
drop_rate (float): Dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
use_checkpoint=False, **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# absolute position embedding
if self.ape:
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
drop=drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, (nn.Linear, nn.Conv1d)):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'absolute_pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table'}
def forward_features(self, x):
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def flops(self):
flops = 0
flops += self.patch_embed.flops()
for i, layer in enumerate(self.layers):
flops += layer.flops()
# adaptive average pool
flops += self.num_features * self.patches_resolution[0] * self.patches_resolution[1] // (2 ** self.num_layers)
# head
flops += self.num_features * self.num_classes
return flops
- 由4个 Stage 组成,每个 Stage 由 BasicLayer 实现。
传入的 depths 代表每个 Stage 的层数,比如 Swin-T 就是:[2, 2, 6, 2]。










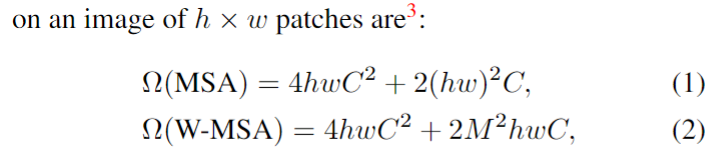






















{kind=link}