
paper:https://arxiv.org/abs/2201.03545 CVPR 2022.Facebook AI Research
github:https://github.com/facebookresearch/ConvNeXt
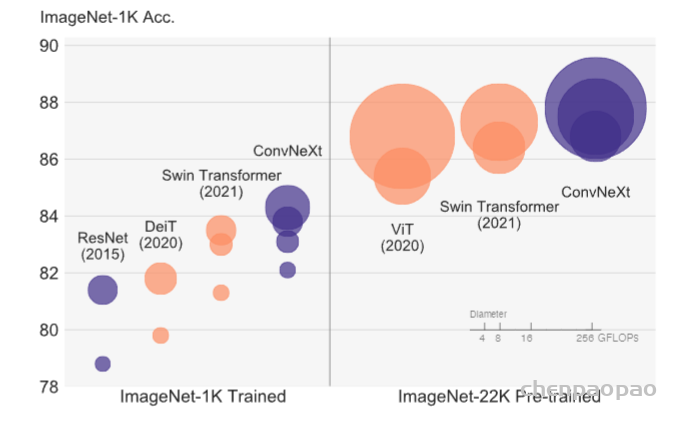
作者提出了ConvNeXt,一个完全由标准 ConvNet 模块构建的纯 ConvNet 模型。ConvNeXt 准确、高效、可扩展且设计非常简单。
2020年以来,ViT一直是研究热点。ViT在图片分类上的性能超过卷积网络的性能,后续发展而来的各种变体将ViT发扬光大(如Swin-T,CSwin-T等),值得一提的是Swin-T中的滑窗操作类似于卷积操作,降低了运算复杂度,使得ViT可以被用做其他视觉任务的骨干网络,ViT变得更火了。本文探究卷积网络到底输在了哪里,卷积网络的极限在哪里。在本文中,作者逐渐向ResNet中增加结构(或使用trick)来提升卷积模型性能,最终将ImageNet top-1刷到了87.8%。作者认为本文所提出的网络结构是新一代(2020年代)的卷积网络(ConvNeXt),因此将文章命名为“2020年代的卷积网络”。
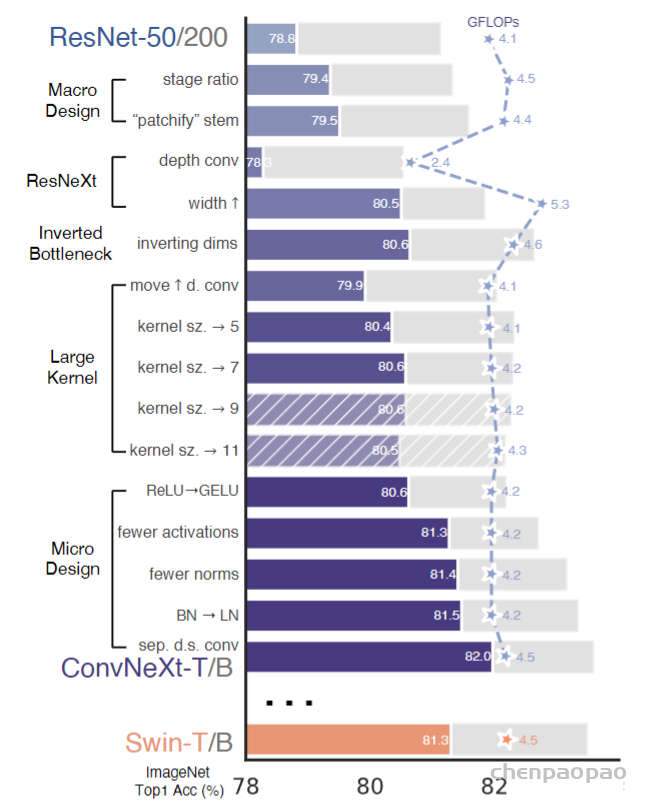
作者的出发点时Resnet-50模型。首先使用用于训练视觉变压器的类似训练技术训练它,与原始Resnet-50相比,获得了较大的改进效果。这将是我们的基线。然后,我们研究了一系列设计决策,总结为1)宏观设计,2)Resnext,3)inverted bottleneck,4)使用大的核,以及5)各种层的微型设计。
1、训练技巧:
作者认为,除了网络结构,训练技巧也会影响最终的效果,除了vision Transformers的结构 ,vision Transformers的一些训练技巧也给作者带来 一些启发。作者使用swin transformer的训练技巧,应用在基线模型中:
1、增加 epoch到300
2、使用AdamW优化器
3、数据增强技术(cutmix、mixup等等)
结果分类准确率由76.1%上升到78.8%。具体训练config如下:

2、宏观设计
作者借鉴了Swin-T的两个设计:
- 每阶段的计算量(调整每个阶段block数量)
- 对输入图片下采样方法
对于第一点类似Swin-T四个阶段1:1:9:1的计算量,作者将ResNet-50每个阶段block数调整为3,3,9,3(原来为3,4,6,3),增加第三阶段计算量,准确率由78.8%提升至79.4%。
这个每阶段计算量的设计:感觉很多模型都是在中间部分的计算量最多 ,两头的计算量最小,这种设计的效果最好。
对于第二点Swin-T融合压缩2×2的区域,作者则使用4×4步长为4的卷积对输入图片进行下采样,这样每次卷积操作的感受野不重叠,准确率由79.4%提升至79.5%。
3、类ResNeXt设计
depthwise conv中的逐channel卷积操作和self-attention中的加权求和很类似,因此作者采用depthwise conv替换普通卷积。参照ResNeXt,作者将通道数增加到96,准确率提升至80.5%,FLOPs相应增大到了5.3G。相比之下原始的ResNet-50 FLOPs为4G,运算量增大很多。
4、Inverted Bottleneck
在depthwise conv的基础上借鉴MobileNet的inverted bottleneck设计(维度先扩增4倍在缩减),将block由下图(a)变为(b)。因为depthwise不会使channel之间的信息交互,因此一般depthwise conv之后都会接1 × 1 × C的pointwise conv。这一顿操作下来准确率只涨了0.1%到80.6%。在后文说明的大模型上涨点多一点。
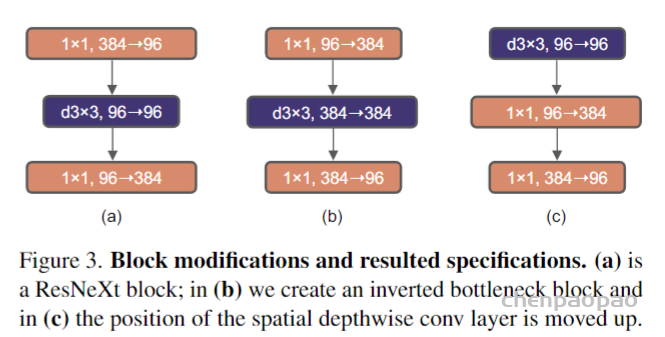
Moving up depthwise conv layer
首先,考虑到卷积核太大会导致计算复杂度上升,不方便作者去寻找大卷积核。因此作者借鉴transformer里面MSA block 放在了1*1卷积之前,把7*7的 depthwise conv layer 放在1*1卷积之前,这样, depthwise conv layer 的通道数下降,相应计算量也下降,但性能下降到了79.9%
增大卷积kernel
作者认为更大的感受野是ViT性能更好的可能原因之一,作者尝试增大卷积的kernel,使模型获得更大的感受野。首先在pointwise conv的使用上,作者为了获得更大的感受野,将depthwise conv提前到1 × 1 conv之前,之后用384个1 × 1 × 96的conv将模型宽度提升4倍,在用96个1 × 1 × 96的conv恢复模型宽度。反映在上图中就是由(b)变为(c)。由于3×3的conv数量减少,模型FLOPs由5.3G减少到4G,相应地性能暂时下降到79.9%。
然后作者尝试增大depthwise conv的卷积核大小,证明7×7大小的卷积核效果达到最佳。
其他乱七八糟的尝试
借鉴最初的Transformer设计,作者将ReLU替换为GELU;ViT的K/Q/V计算中都没有用到激活函数和归一化层,于是作者也删除了大量的激活函数和归一化层,仅在1 × 1卷积之间使用激活函数,仅在7 × 7卷积和1 × 1 卷积之间使用归一化层,同时将BN升级为LN。最终block结构确定如下:

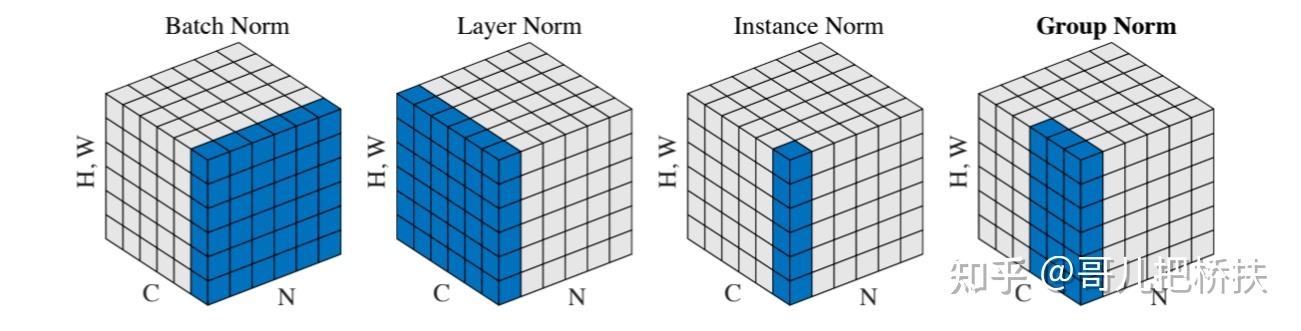
顺便复习一下各种归一化方法:
最后仿照Swin-T,作者将下采样层单独分离出来,单独使用2 × 2卷积层进行下采样。为保证收敛,在下采样后加上Layer Norm归一化。最终加强版ResNet-50准确率82.0%(FLOPs 4.5G)。
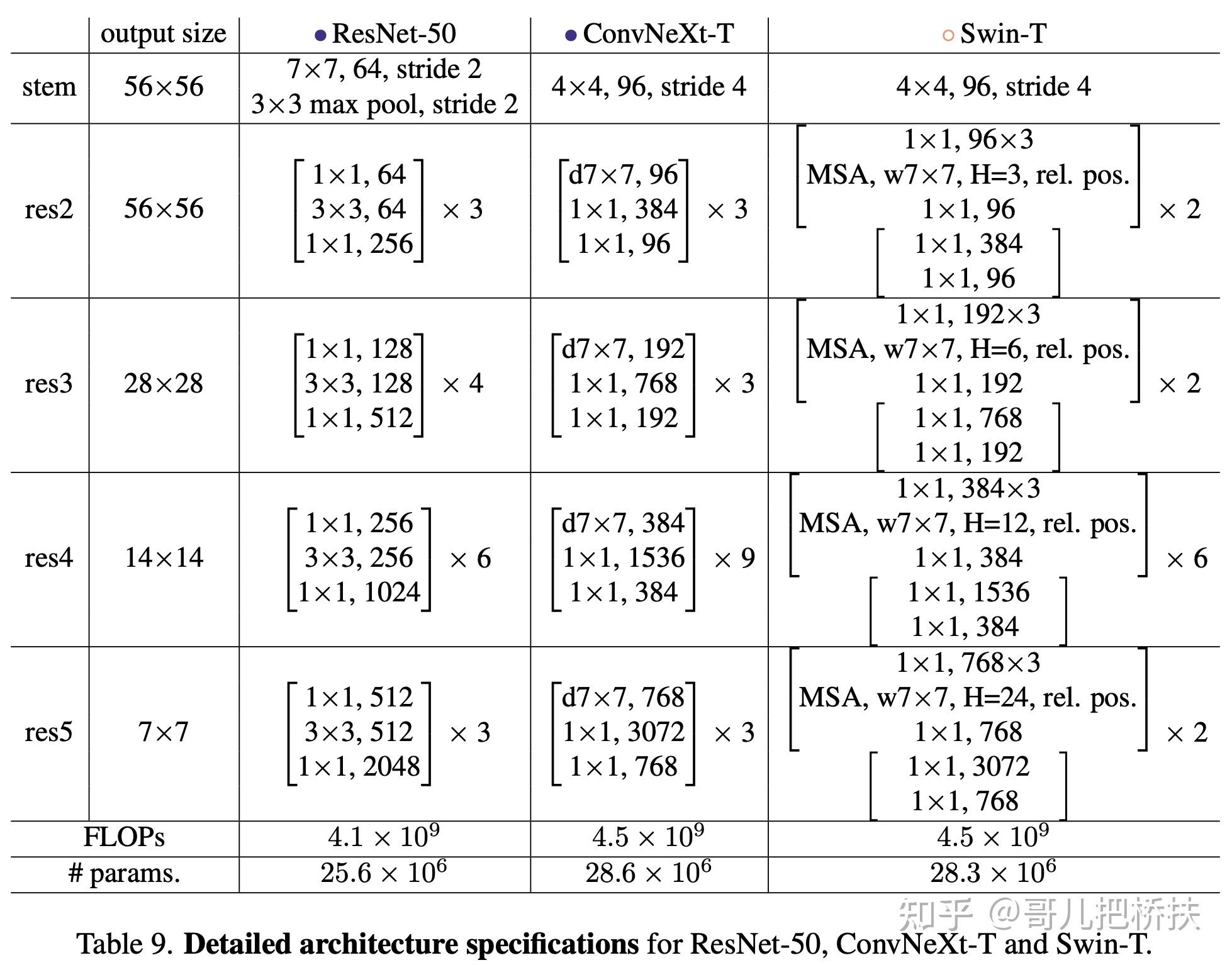
总的来说ResNet-50、本文模型和Swin-T结构差别如下:
实验结果
作者在ResNet-50加强版的基础上又提出了多个变体(ConvNeXt-T/B/L/XL),从实验结果上看ResNet-50加强版性能收益较为突出,越是大模型性能收益越低。
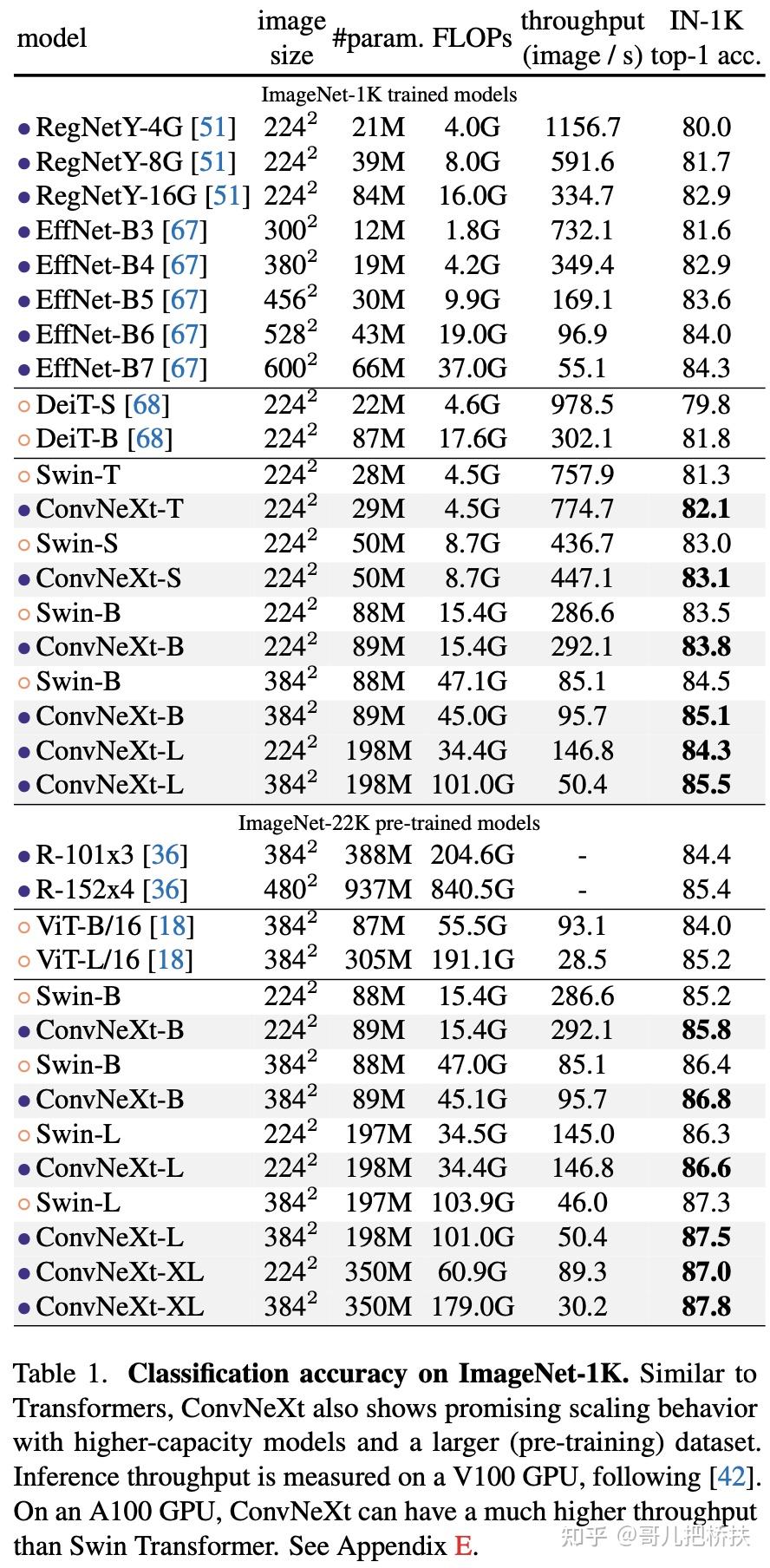
在检测、分割下游任务中ConvNeXt也获得了与Swin-T相似或更好的结果。结果就不细说了。
消融实验
每一部分具体涨点效果如下:
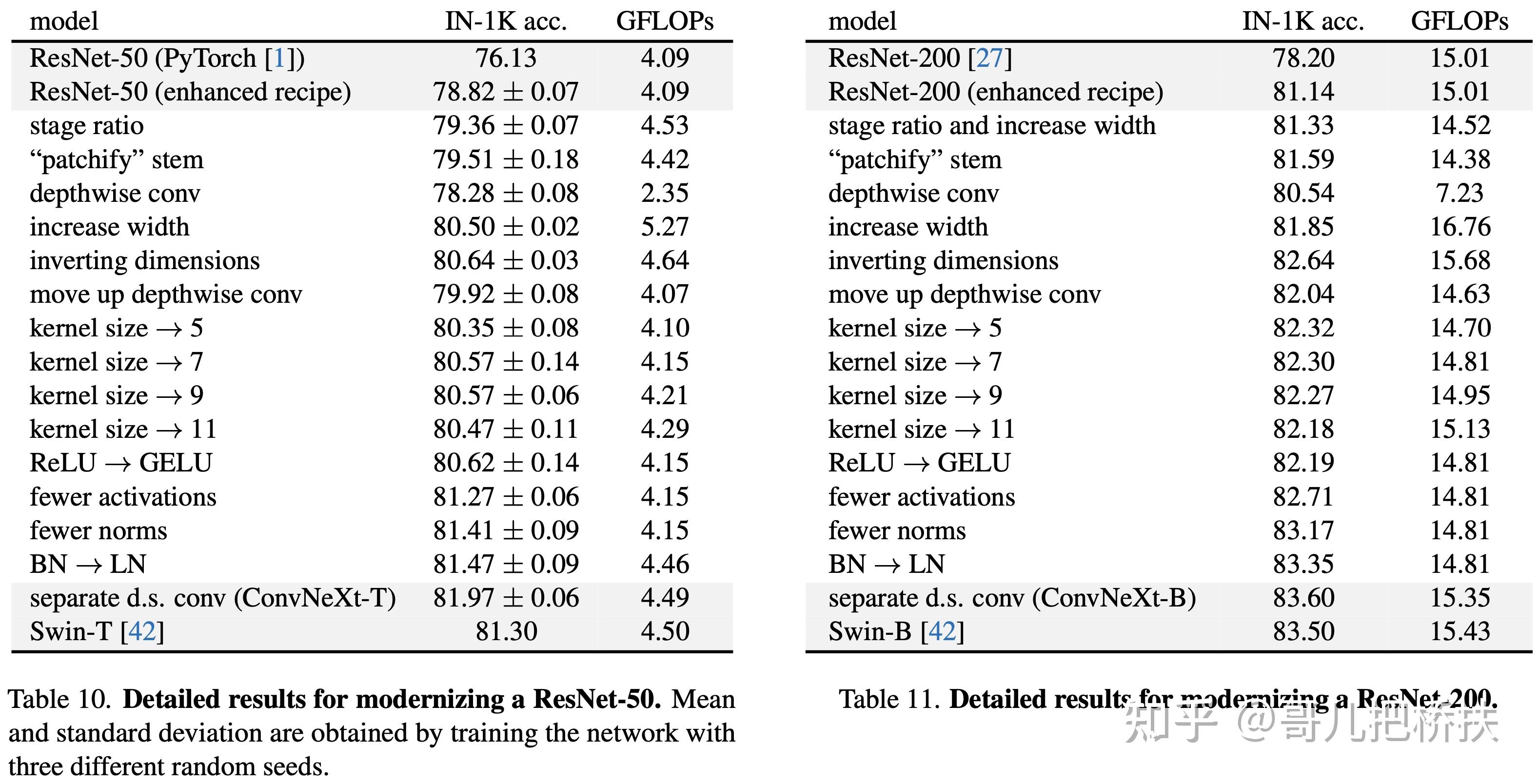
总的来说本文实验做的比较充分,总结一下,卷积网络涨点可以尝试:
- 对输入下采样时尝试无重叠小一点的卷积层,例如4 × 4,stride=4的卷积;
- block中采用大卷积核,例如7 × 7;
- depthwise conv + inverted bottleneck + moving up depthwise layer的block结构;
- 减少激活/归一化层,ReLU换成GELU,BN换成LN;
- 使用2×2 conv + LN下采样。