回顾21世纪10年代,深度学习取得了巨大的进步,产生了巨大的影响。主要驱动力是神经网络的复兴,特别是卷积神经网络(ConvNets)。十年来,视觉识别领域成功地从工程特征转变为设计(ConvNet)架构。尽管采用反向传播训练方法的卷积神经网络自上世纪八十年代已经发明了,但直到2012年我们才看到它作为视觉特征学习的真正潜力。AlexNet的引入促成了“ImageNet的时刻”,引领了计算机视觉领域的一个新时代,这个领域因此而快速演化。具有代表性的网络有VGGNet、Inceptions、Resnet、DenseNet、MobileNet、EfficientNet、RegNet等,它们分别关注精度、效率、可扩展性等方面,并且普及了很多有用的设计原则。
1、 VGGNet
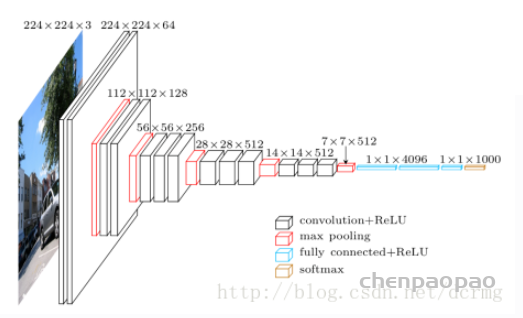
VGG16相比AlexNet的一个改进是采用连续的几个3×3的卷积核代替AlexNet中的较大卷积核(11×11,7×7,5×5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
简单来说,在VGG中,使用了3个3×3卷积核来代替7×7卷积核,使用了2个3×3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
网络结构:
2、 Inception系列网络
Inception V1
在这之前,网络大都是这样子的:

也就是卷积层和池化层的顺序连接。这样的话,要想提高精度,增加网络深度和宽度是一个有效途径,但也面临着参数量过多、过拟合等问题。(当然,改改超参数也可以提高性能)
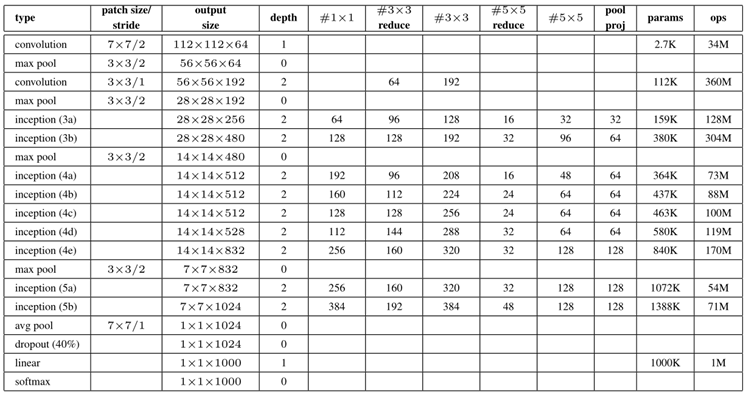
有没有可能在同一层就可以提取不同(稀疏或不稀疏)的特征呢(使用不同尺寸的卷积核)?于是,2014年,在其他人都还在一味的增加网络深度时(比如vgg),GoogleNet就率先提出了卷积核的并行合并(也称Bottleneck Layer),如下图。
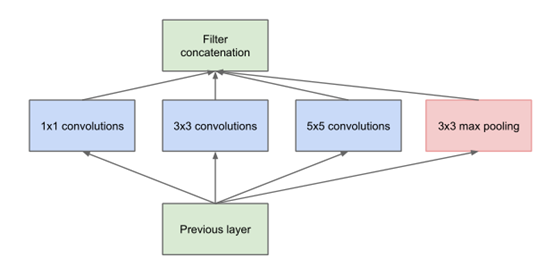
和卷积层、池化层顺序连接的结构(如VGG网络)相比,这样的结构主要有以下改进:
- 一层block就包含1×1卷积,3×3卷积,5×5卷积,3×3池化(使用这样的尺寸不是必需的,可以根据需要进行调整)。这样,网络中每一层都能学习到“稀疏”(3×3、5×5)或“不稀疏”(1×1)的特征,既增加了网络的宽度,也增加了网络对尺度的适应性;
- 通过deep concat在每个block后合成特征,获得非线性属性。
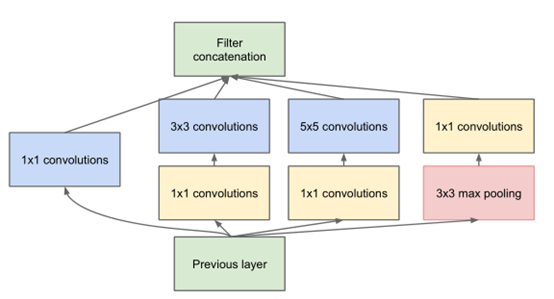
按照这样的结构来增加网络的深度,虽然可以提升性能,但是还面临计算量大(参数多)的问题。为改善这种现象,GooLeNet借鉴Network-in-Network的思想,使用1×1的卷积核实现降维操作(也间接增加了网络的深度),以此来减小网络的参数量(这里就不对两种结构的参数量进行定量比较了),如图所示。
最后实现的inception v1网络是上图结构的顺序连接,其中不同inception模块之间使用2×2的最大池化进行下采样,如表所示。
如表所示,实现的网络仍有一层全连接层,该层的设置是为了迁移学习的实现(下同)。
在之前的网络中,最后都有全连接层,经实验证明,全连接层并不是很必要的,因为可能会带来以下三点不便:
- 网络的输入需要固定
- 参数量多
- 易发生过拟合
实验证明,将其替换为平均池化层(或者1×1卷积层)不仅不影响精度,还可以减少参数量。
此外,实验室的小伙伴最近做了下实验,如果是小目标检测的话,网络的最后还是需要几层全连接层的,猜想可能是用池化的话会损失太多信息,毕竟是小目标。
———————————————————————————————–
Inception V2和Inception V3的改进,主要是基于V3论文中提到的四个原则:
- 避免表示瓶颈,尤其是在网络的前面。一般来说,特征图从输入到输出应该缓慢减小。
- 高维度特征在网络局部处理更加容易。考虑到更多的耦合特征,在卷积网络中增加非线性。可以让网络训练更快。
- 空间聚合可以以低维度嵌入进行,这样不会影响特征的表达能力。如,在进行大尺度卷积之前,先对输入进行降维。
- 平衡网络的宽度和深度。增加宽度和深度都会带来性能上的提升,两者同时增加带来了并行提升,但是要考虑计算资源的合理分配。
———————————————————————————————–
Inception v2
(注意,这里实现的inception v2的结构是在inception v3论文中有介绍)
2015年Google团队又提出了inception v2的结构,基于上面提到的一些原则,在V1的基础之上主要做了以下改进:
⑴ 使用BN层,将每一层的输出都规范化到一个N(0,1)的正态分布,这将有助于训练,因为下一层不必学习输入数据中的偏移,并且可以专注与如何更好地组合特征(也因为在v2里有较好的效果,BN层几乎是成了深度网络的必备);
(在Batch-normalized论文中只增加了BN层,而之后的Inception V3的论文提及到的inception v2还做了下面的优化)
⑵ 使用2个3×3的卷积代替梯度(特征图,下同)为35×35中的5×5的卷积,这样既可以获得相同的视野(经过2个3×3卷积得到的特征图大小等于1个5×5卷积得到的特征图),还具有更少的参数,还间接增加了网络的深度,如下图。(基于原则3)
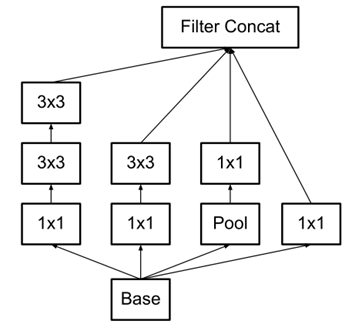
⑶ 3×3的卷积核表现的不错,那更小的卷积核是不是会更好呢?比如2×2。对此,v2在17×17的梯度中使用1*n和n*1这种非对称的卷积来代替n*n的对称卷积,既降低网络的参数,又增加了网络的深度(实验证明,该结构放于网络中部,取n=7,准确率更高),如下。(基于原则3)
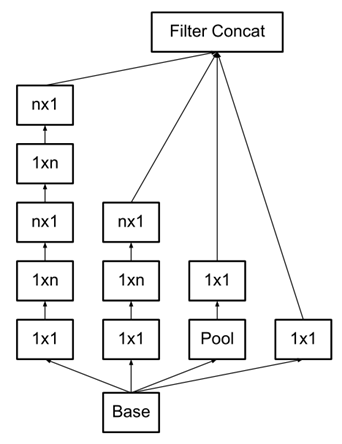
⑷ 在梯度为8×8时使用可以增加滤波器输出的模块(如下图),以此来产生高维的稀疏特征。(基于原则2)
(原则2指出,在高维特征上,采用这种结构更好,因此该模块用在了8×8的梯度上)
⑸ 输入从224×224变为229×229。
最后实现的Inception v2的结构如下表。
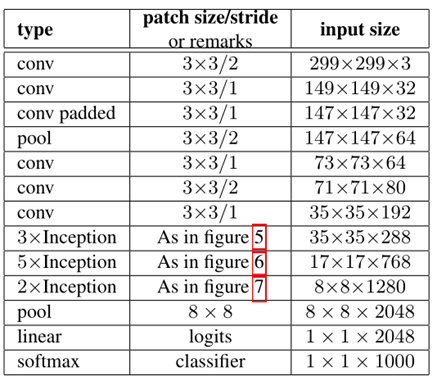
经过网络的改进,inception v2得到更低的识别误差率,与其他网络识别误差率对比如表所示。
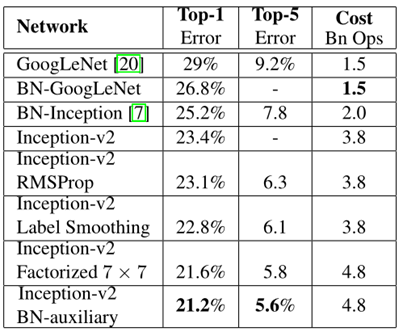
如表,inception v2相比inception v1在imagenet的数据集上,识别误差率由29%降为23.4%。
Inception v3
inception模块之间特征图的缩小,主要有下面两种方式:
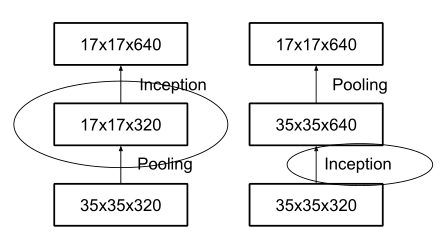
右图是先进行inception操作,再进行池化来下采样,但是这样参数量明显多于左图(比较方式同前文的降维后inception模块),因此v2采用的是左图的方式,即在不同的inception之间(35/17/8的梯度)采用池化来进行下采样。
但是,左图这种操作会造成表达瓶颈问题,也就是说特征图的大小不应该出现急剧的衰减(只经过一层就骤降)。如果出现急剧缩减,将会丢失大量的信息,对模型的训练造成困难。(上文提到的原则1)
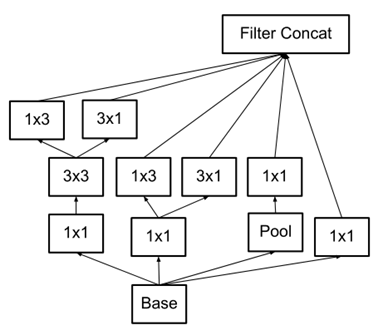
因此,在2015年12月提出的Inception V3结构借鉴inception的结构设计了采用一种并行的降维结构,如下图:
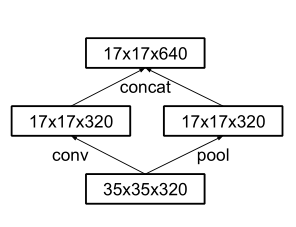
具体来说,就是在35/17/8之间分别采用下面这两种方式来实现特征图尺寸的缩小,如下图:
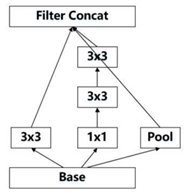
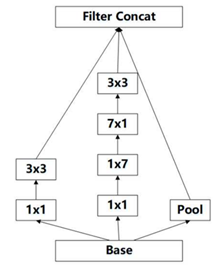
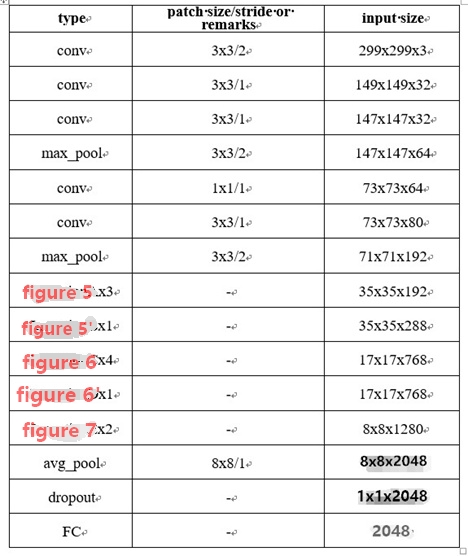
这样就得到Inception v3的网络结构,如表所示。
经过优化后的inception v3网络与其他网络识别误差率对比如表所示。
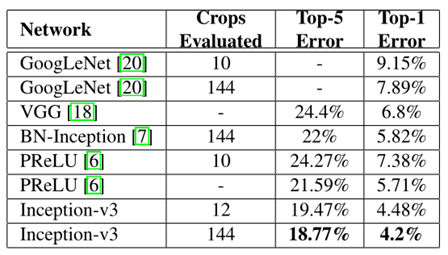
如表所示,在144×144的输入上,inception v3的识别错误率由v1的7.89%降为了4.2%。
此外,文章还提到了中间辅助层,即在网络中部再增加一个输出层。实验发现,中间辅助层在训练前期影响不大,而在训练后期却可以提高精度,相当于正则项。
Inception V4
其实,做到现在,inception模块感觉已经做的差不多了,再做下去准确率应该也不会有大的改变。但是谷歌这帮人还是不放弃,非要把一个东西做到极致,改变不了inception模块,就改变其他的。
因此,作者Christian Szegedy设计了inception v4的网络,将原来卷积、池化的顺次连接(网络的前几层)替换为stem模块,来获得更深的网络结构。stem模块结构如下
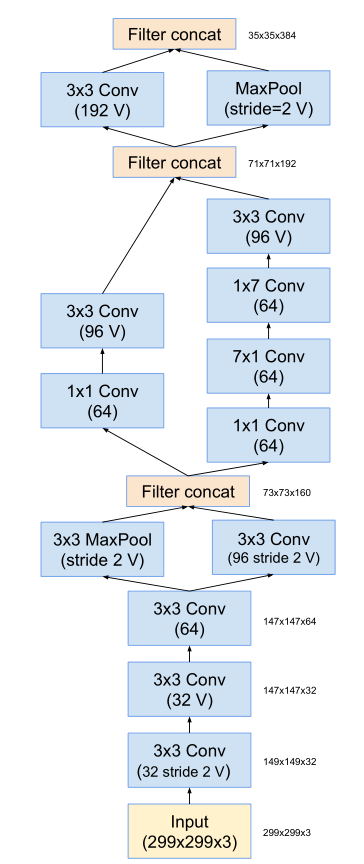
stem之后的,同v3,是inception模块和reduction模块,如下图
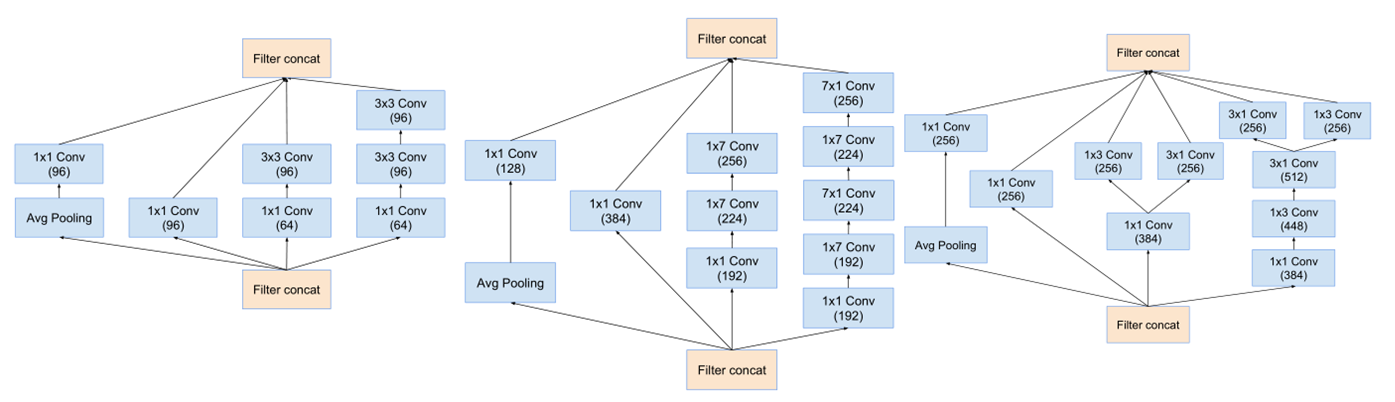
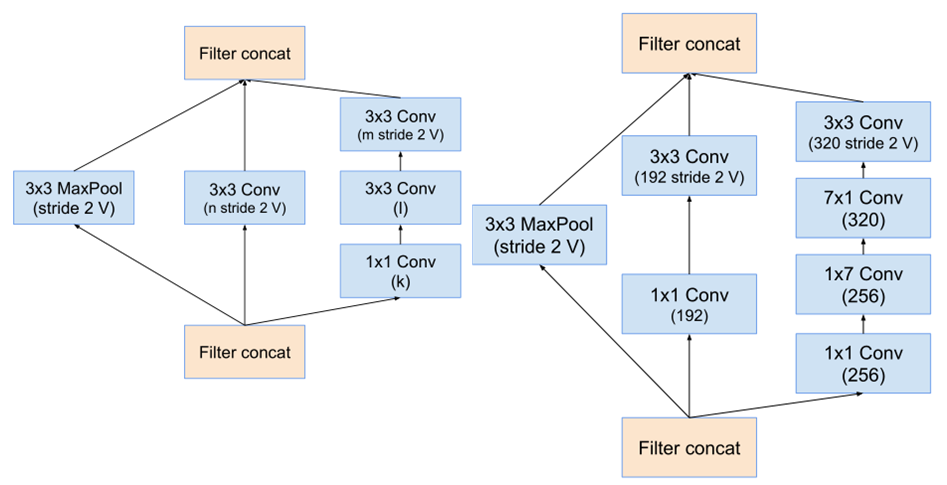
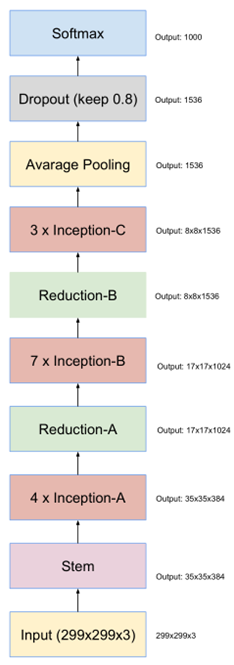
最终得到的inception v4结构如下图。
Inception-ResNet-v2
ResNet(该网络介绍见卷积神经网络结构简述(三)残差系列网络)的结构既可以加速训练,还可以提升性能(防止梯度弥散);Inception模块可以在同一层上获得稀疏或非稀疏的特征。有没有可能将两者进行优势互补呢?
Christian Szegedy等人将两个模块的优势进行了结合,设计出了Inception-ResNet网络。
(inception-resnet有v1和v2两个版本,v2表现更好且更复杂,这里只介绍了v2)
inception-resnet的成功,主要是它的inception-resnet模块。
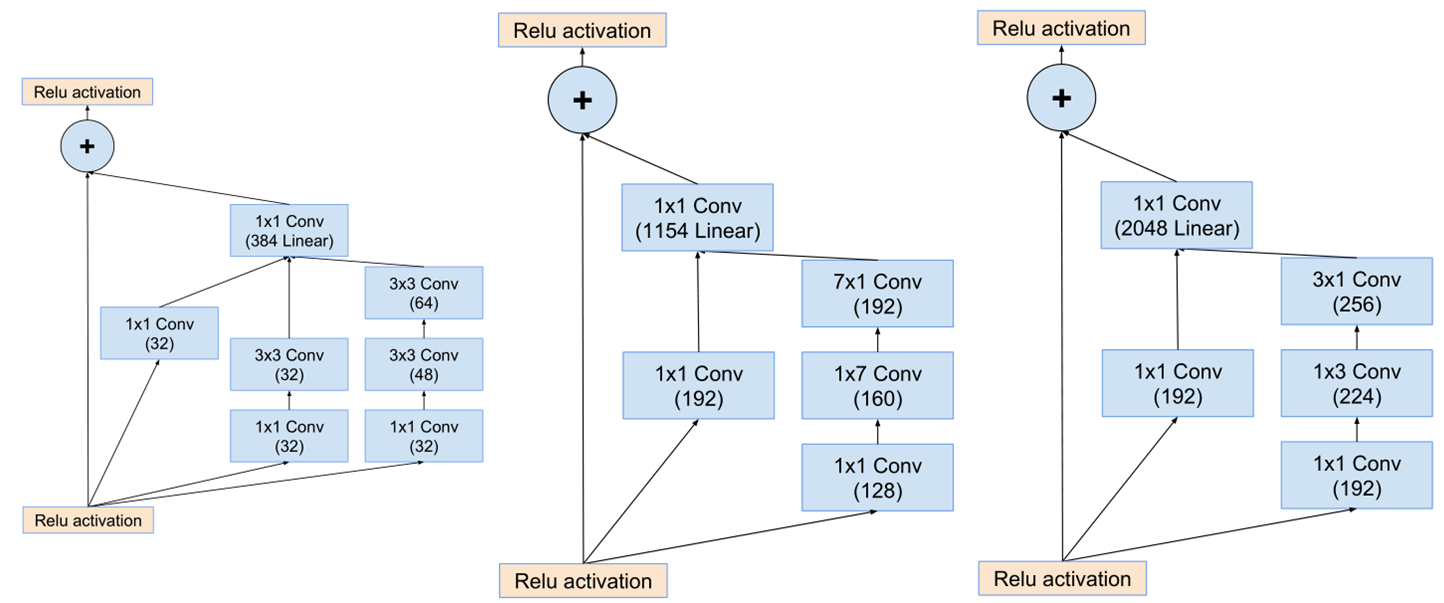
inception-resnet v2中的Inception-resnet模块如下图
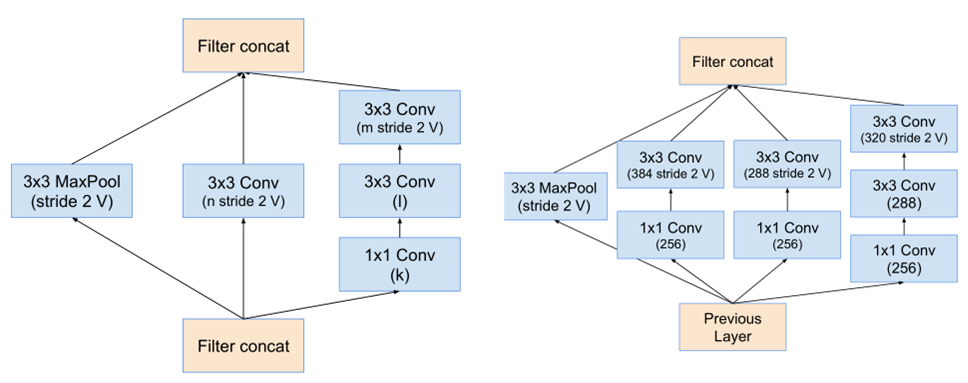
Inception-resnet模块之间特征图尺寸的减小如下图。(类似于inception v4)
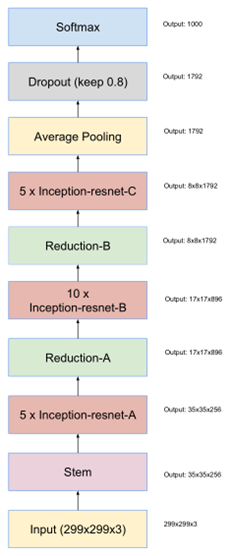
最终得到的Inception-ResNet-v2网络结构如图(stem模块同inception v4)。
经过这两种网络的改进,使得模型对图像识别的错误率进一步得到了降低。Inception、resnet网络结果对比如表所示。
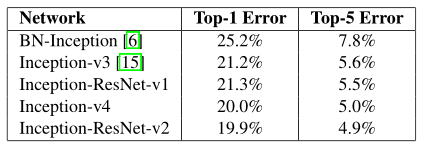
如表,Inception V4与Inception-ResNet-v2网络较之前的网络,误差率均有所下降。
3、Resnet
ResNet网络是在2015年由微软实验室提出,斩获当年ImageNet竞赛中分类任务第一名,目标检测第一名。获得COCO数据集中目标检测第一名,图像分割第一名。下图是ResNet34层模型的结构简图。
在ResNet网络中有如下几个亮点:
(1)提出residual结构(残差结构),并搭建超深的网络结构(突破1000层)
(2)使用Batch Normalization加速训练(丢弃dropout)
在ResNet网络提出之前,传统的卷积神经网络都是通过将一系列卷积层与下采样层进行堆叠得到的。但是当堆叠到一定网络深度时,就会出现两个问题。1)梯度消失或梯度爆炸。 2)退化问题(degradation problem)。在ResNet论文中说通过数据的预处理以及在网络中使用BN(Batch Normalization)层能够解决梯度消失或者梯度爆炸问题。如果不了解BN层可参考这个链接。但是对于退化问题(随着网络层数的加深,效果还会变差,如下图所示)并没有很好的解决办法。

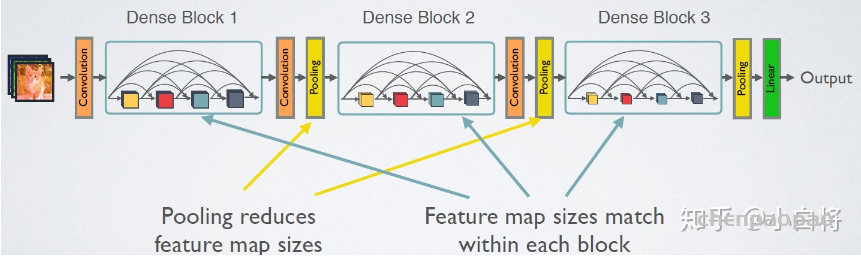
4、DenseNet
DenseNet模型,它的基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(dense connection),它的名称也是由此而来。DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用(feature reuse)。这些特点让DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能,DenseNet也因此斩获CVPR 2017的最佳论文奖.
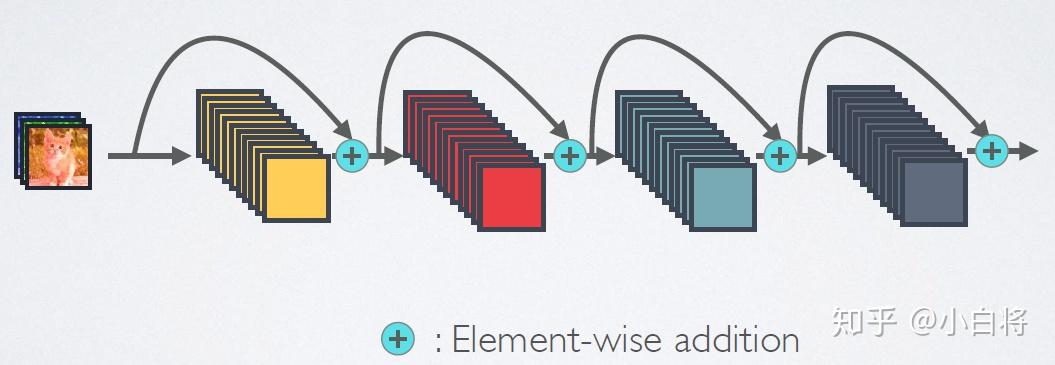
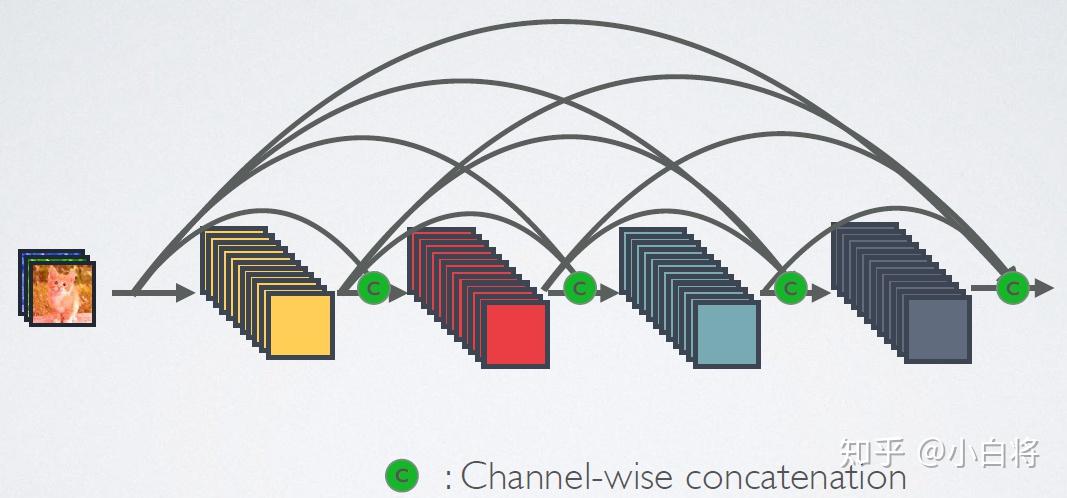
相比ResNet,DenseNet提出了一个更激进的密集连接机制:即互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入。图1为ResNet网络的连接机制,作为对比,图2为DenseNet的密集连接机制。可以看到,ResNet是每个层与前面的某层(一般是2~3层)短路连接在一起,连接方式是通过元素级相加。而在DenseNet中,每个层都会与前面所有层在channel维度上连接(concat)在一起(这里各个层的特征图大小是相同的),并作为下一层的输入。
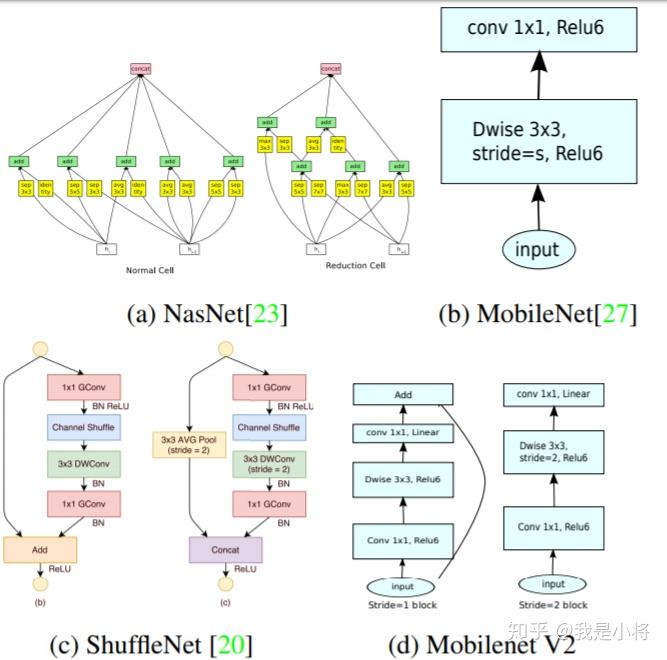
5、MobileNet
MobileNet的基本单元是深度级可分离卷积(depthwise separable convolution),其实这种结构之前已经被使用在Inception模型中。深度级可分离卷积其实是一种可分解卷积操作(factorized convolutions),其可以分解为两个更小的操作:depthwise convolution和pointwise convolution,如图1所示。Depthwise convolution和标准卷积不同,对于标准卷积其卷积核是用在所有的输入通道上(input channels),而depthwise convolution针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道,所以说depthwise convolution是depth级别的操作。而pointwise convolution其实就是普通的卷积,只不过其采用1×1的卷积核。图2中更清晰地展示了两种操作。对于depthwise separable convolution,其首先是采用depthwise convolution对不同输入通道分别进行卷积,然后采用pointwise convolution将上面的输出再进行结合,这样其实整体效果和一个标准卷积是差不多的,但是会大大减少计算量和模型参数量。
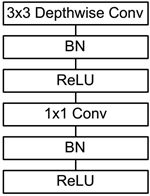
前面讲述了depthwise separable convolution,这是MobileNet的基本组件,但是在真正应用中会加入batchnorm,并使用ReLU激活函数,所以depthwise separable convolution的基本结构如图3所示。
MobileNet的网络结构如表1所示。首先是一个3×3的标准卷积,然后后面就是堆积depthwise separable convolution,并且可以看到其中的部分depthwise convolution会通过strides=2进行down sampling。然后采用average pooling将feature变成1×1,根据预测类别大小加上全连接层,最后是一个softmax层。如果单独计算depthwise
convolution和pointwise convolution,整个网络有28层(这里Avg Pool和Softmax不计算在内)。我们还可以分析整个网络的参数和计算量分布,如表2所示。可以看到整个计算量基本集中在1×1卷积上,如果你熟悉卷积底层实现的话,你应该知道卷积一般通过一种im2col方式实现,其需要内存重组,但是当卷积核为1×1时,其实就不需要这种操作了,底层可以有更快的实现。对于参数也主要集中在1×1卷积,除此之外还有就是全连接层占了一部分参数。
MobileNetv2
MobileNetv2相比v1的两个主要改进:linear bottleneck和inverted residual。
v2的加入了1×1升维,引入Shortcut并且去掉了最后的ReLU,改为Linear。步长为1时,先进行1×1卷积升维,再进行深度卷积提取特征,再通过Linear的逐点卷积降维。将input与output相加,形成残差结构。步长为2时,因为input与output的尺寸不符,因此不添加shortcut结构,其余均一致。
首先利用3×3的深度可分离卷积提取特征,然后利用1×1的卷积来扩张通道。用这样的block堆叠起来的MobileNetV1既能较少不小的参数量、计算量,提高网络运算速度,又能的得到一个接近于标准卷积的还不错的结果,看起来是很美好的。
但是!
有人在实际使用的时候, 发现深度卷积部分的卷积核比较容易训废掉:训完之后发现深度卷积训出来的卷积核有不少是空的.
这是为什么?
作者认为这是ReLU这个浓眉大眼的激活函数的锅。(没想到你个浓眉大眼的ReLU激活函数也叛变革命了???)
针对这个问题,可以这样解决:既然是ReLU导致的信息损耗,将ReLU替换成线性激活函数。我们当然不能把所有的激活层都换成线性的啊,所以我们就悄咪咪的把最后的那个ReLU6换成Linear。作者将这个部分称之为linear bottleneck。对,就是论文名中的那个linear bottleneck。
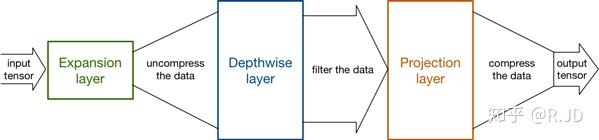
现在还有个问题是,深度卷积本身没有改变通道的能力,来的是多少通道输出就是多少通道。如果来的通道很少的话,DW深度卷积只能在低维度上工作,这样效果并不会很好,所以我们要“扩张”通道。既然我们已经知道PW逐点卷积也就是1×1卷积可以用来升维和降维,那就可以在DW深度卷积之前使用PW卷积进行升维(升维倍数为t,t=6),再在一个更高维的空间中进行卷积操作来提取特征:

也就是说,不管输入通道数是多少,经过第一个PW逐点卷积升维之后,深度卷积都是在相对的更高6倍维度上进行工作。
回顾V1的网络结构,我们发现V1很像是一个直筒型的VGG网络。我们想像Resnet一样复用我们的特征,所以我们引入了shortcut结构,这样V2的block就是如下图形式:
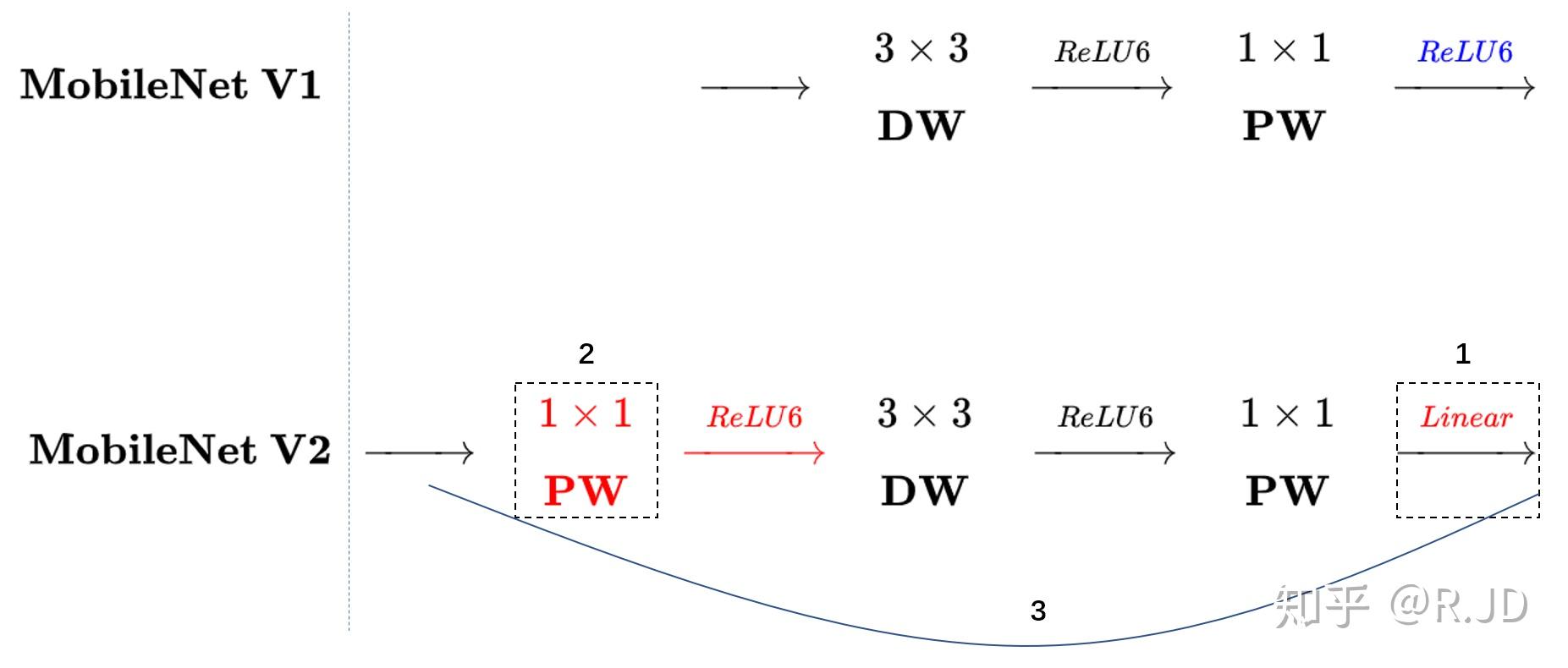
对比一下V1和V2:
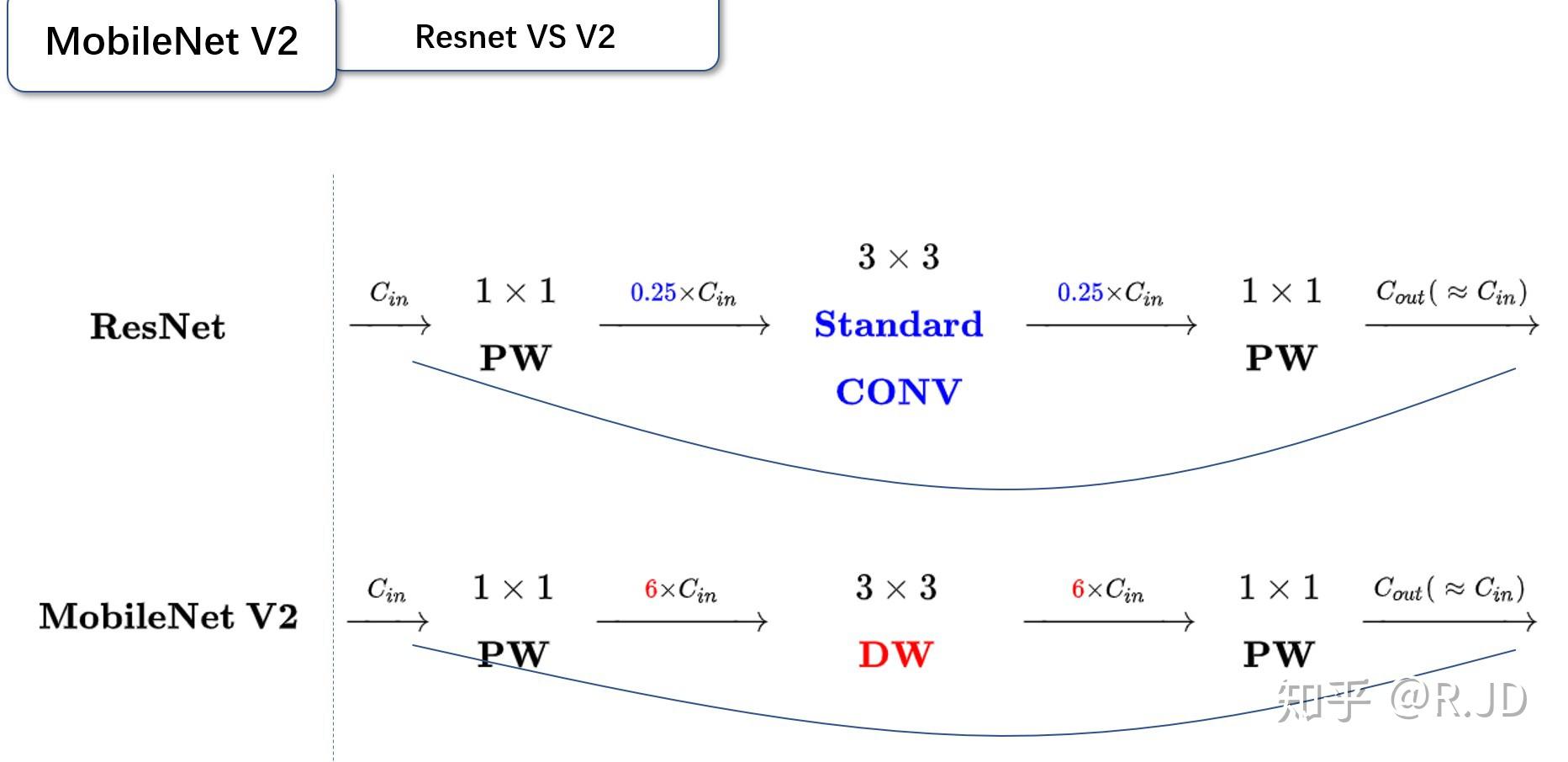
可以发现,都采用了 1×1 -> 3 ×3 -> 1 × 1 的模式,以及都使用Shortcut结构。但是不同点呢:
- ResNet 先降维 (0.25倍)、卷积、再升维。
- MobileNetV2 则是 先升维 (6倍)、卷积、再降维。
刚好V2的block刚好与Resnet的block相反,作者将其命名为Inverted residuals。就是论文名中的Inverted residuals。
6、EfficientNet
该论文提出了一种新的模型缩放方法,它使用一个简单而高效的复合系数来以更结构化的方式放大 CNNs。 不像传统的方法那样任意缩放网络维度,如宽度,深度和分辨率,该论文的方法用一系列固定的尺度缩放系数来统一缩放网络维度。 通过使用这种新颖的缩放方法和 AutoML[5] 技术,作者将这种模型称为 EfficientNets ,它具有最高达10倍的效率(更小、更快)。
模型扩展的有效性在很大程度上依赖于baseline网络。为了进一步提高性能,作者还开发了一个新的基线网络,通过使用 AutoML MNAS 框架执行神经结构搜索,优化了准确性和效率。 最终的架构使用移动反向bottleneck卷积(MBConv) ,类似于 mobileenetv2和 MnasNet。
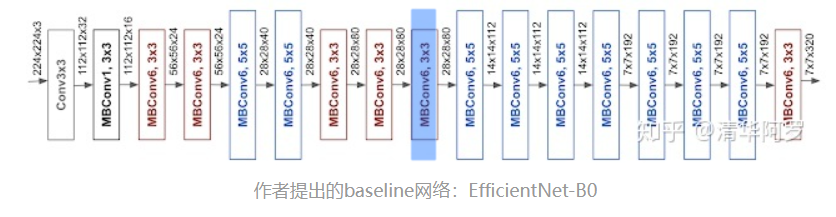
移动翻转瓶颈卷积(mobile inverted bottleneck convolution,MBConv),类似于 MobileNetV2 和 MnasNet,由深度可分离卷积Depthwise Convolution和SENet构成。
每个MBConv的网络结构如下:
MBConv = 1×1升维 + Depthwise Convolution + SENet + 1×1降维 + add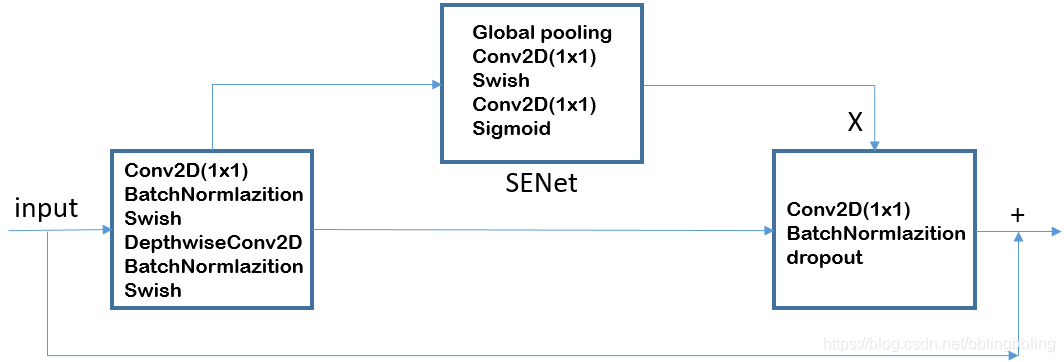
SENet
该网络为压缩与激发网络(Squeeze-and-Excitation Network,SENet),即注意力机制。该思想由Momenta公司提出,并发于2017CVPR。SENet网络的创新点在于关注channel之间的关系,希望模型可以自动学习到不同channel特征的重要程度。
其中第一个FC层降维,降维系数为r,然后ReLU激活,最后的FC层恢复原始的维度。
SENet添加位置示意: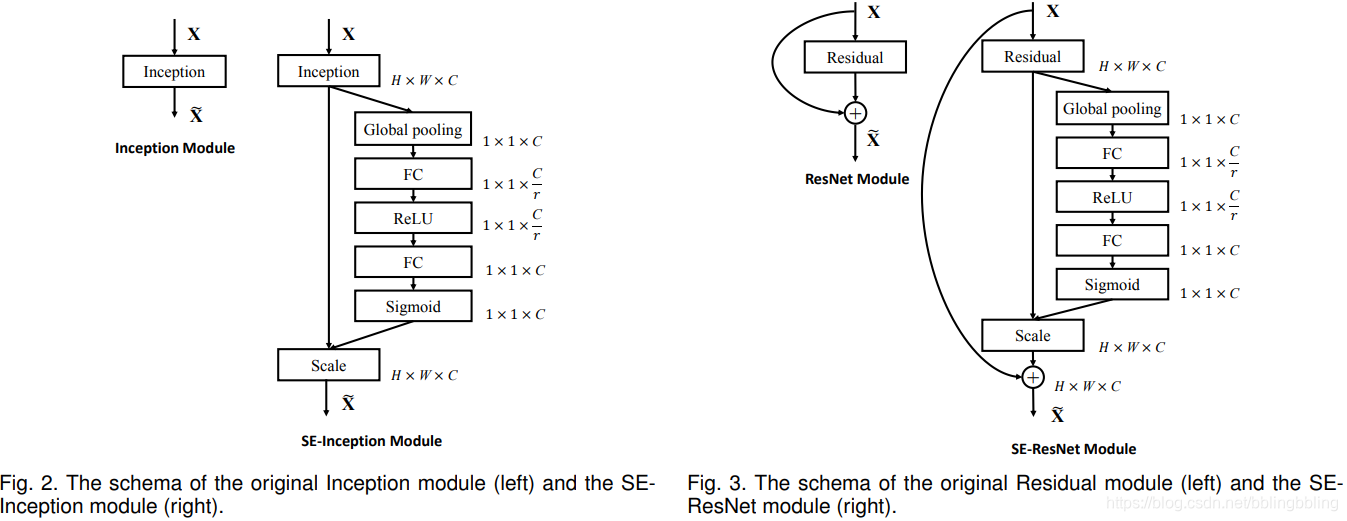
代码实现
7、RegNet
本文的基本贡献有三方面。
- 提出了设计空间的设计原则。
- 根据这些原则,一个有效的设计空间被引入(RegNet)
- 介绍了一组SoTA网络(RegNetX和RegNetY)。
我们首先设计了一个 AnyNet,它包含三个部分
- Stem 一个简单的网络输入头
- body 网络中主要的运算量都在这里
- head 用于预测分类的输出头
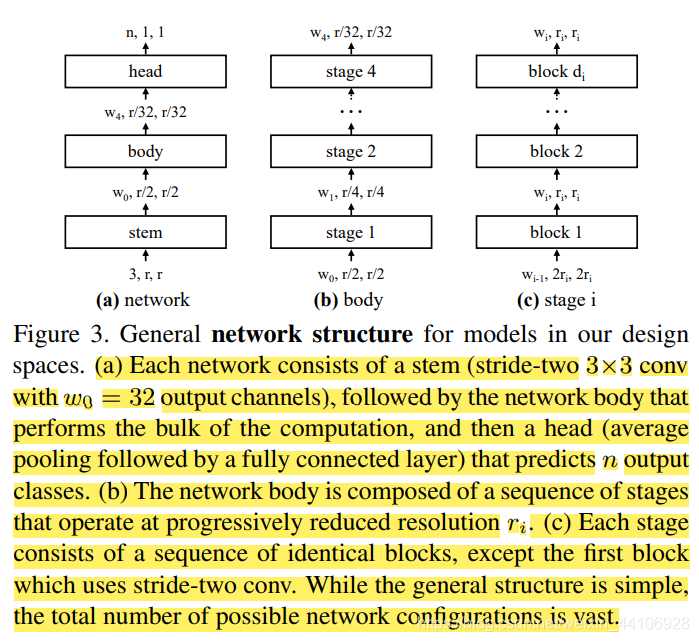
我们将 stem 和 head 固定下来,并专注于网络 body 设计。因为 body 部分的参数量最多,运算量也多,这部分是决定网络准确性的关键
而 Body 结构,通常包含 4 个 stage,每个 stage 都会进行降采样。而 1 个 stage 是由多个 block 进行堆叠得到的。
论文中,我们的 Block 采取的是带有组卷积的残差 BottleNeck Block(即 ResNext 里的结构),我们称在这样 Block 限制条件下的搜索空间为 AnyNetX ,Block 的结构如下:
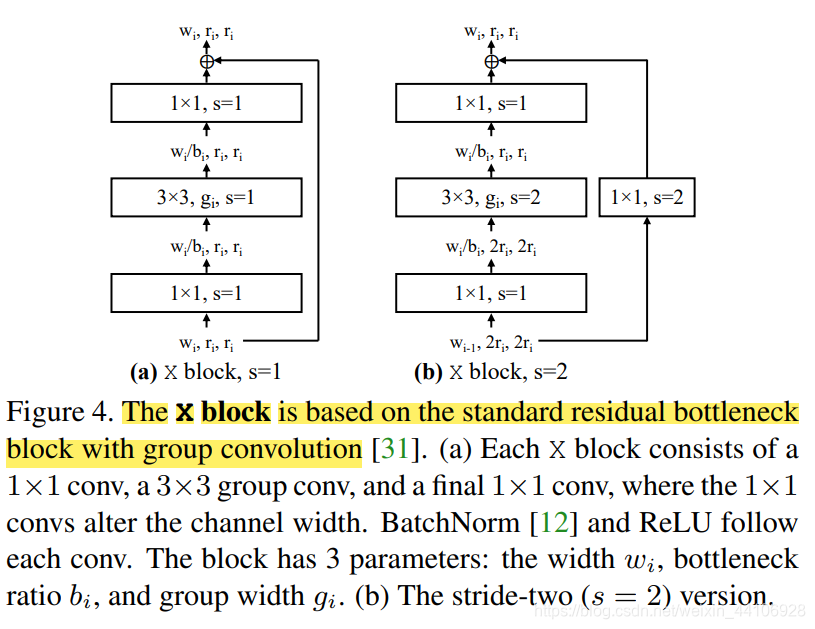
此时 AnyNetX 中有 16 个自由度可以设计,包含了 4 个 stage,每个 stage 有 4 个 Block 参数:
- block 的数目 di
- block 的宽度 wi
- Bottleneck 的通道缩放比例 bi
- 分组数目 gi
此时我们在这样的条件下进行采样,缩小网络设计空间:
- di ≤ 16
- wi ≤ 1024 (其中 wi 可被 8 整除)
- bi ∈ {1, 2, 4}
- gi ∈ {1, 2, . . . , 32}
因此我们在 AnyNetX 衍生出其他搜索空间
- AnyNetXa 就是原始的 AnyNetX
- AnyNetXb 在 AnyNetX 基础上,每个 stage 使用相同的 Bottleneck 缩放比例 bi。并且实验得出缩放比例 bi <= 2 时最佳,参考下图最右边子图

- AnyNetXc 在 AnyNetXb 的基础上共享相同的分组数目 gi。由上图的左图和中间图可得知,从 A->C 的阶段,EDF 并没有受到影响,而我们此时已经减少了
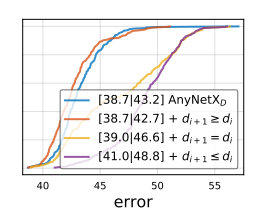
- AnyNetXd 在 AnyNetXc 的基础上逐步增加 Block 的宽度 wi。此时网络性能有明显提升!
{kind=link}
- AnyNetXe 在 AnyNetXd 的基础上在除了最后一个 stage 上,逐步增加 Block 的数量(深度)di。网络性能略微有提升