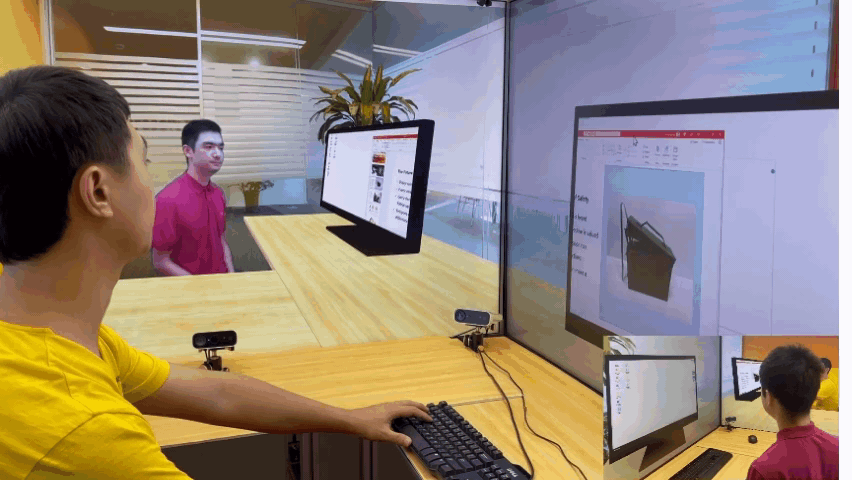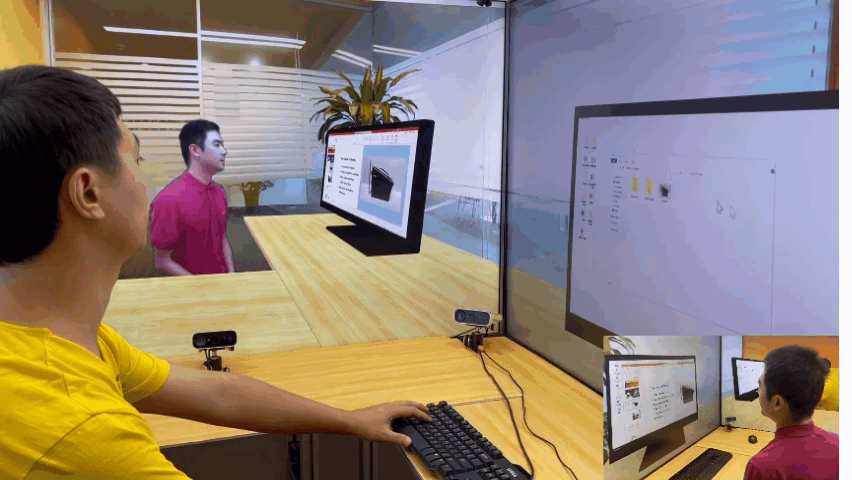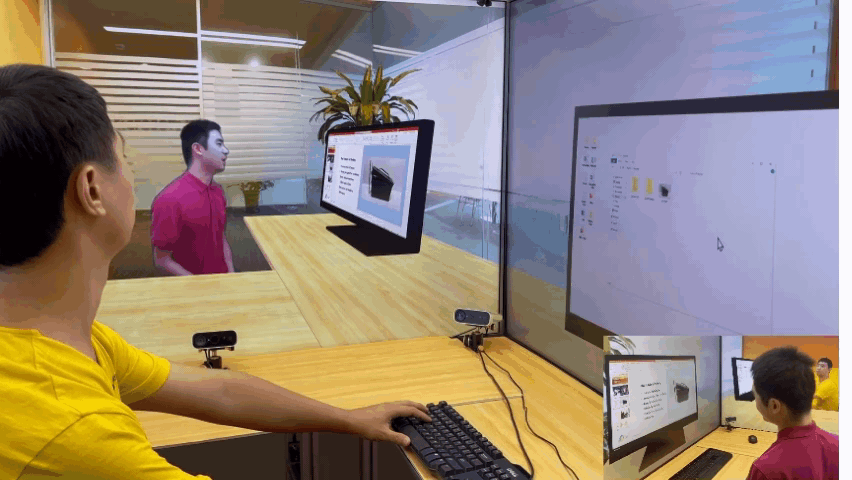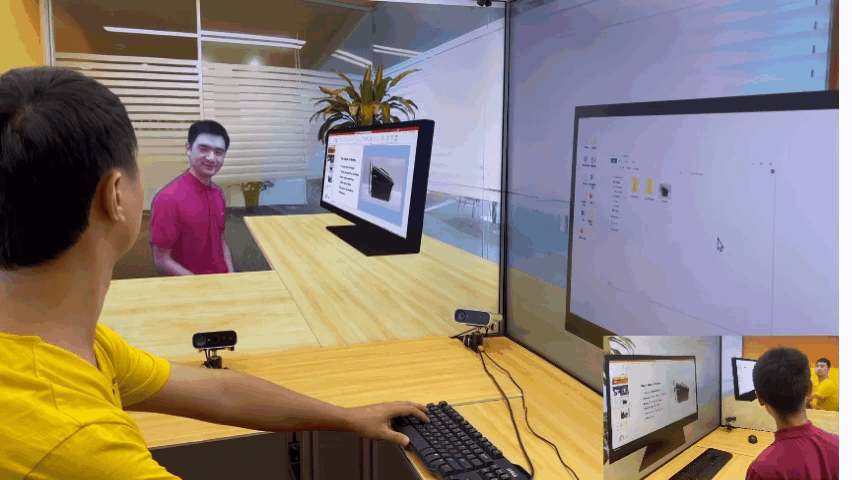
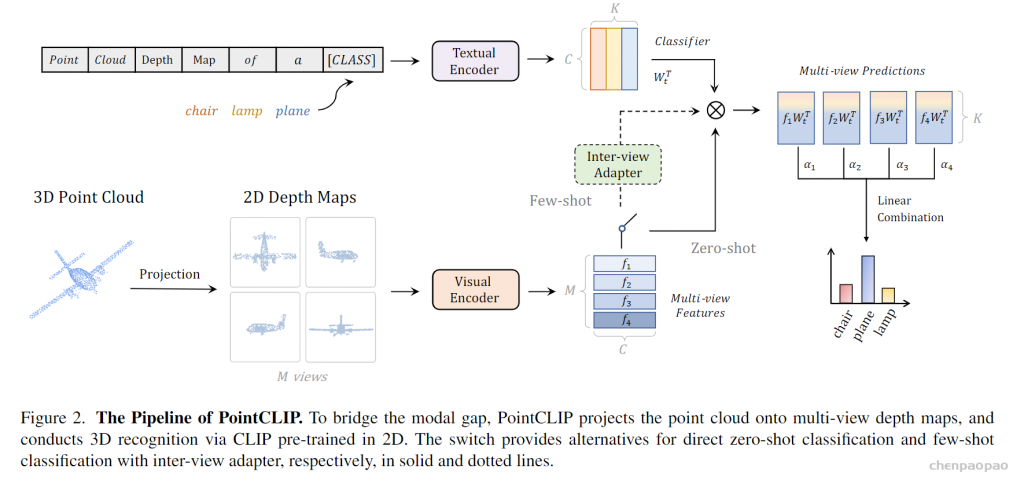
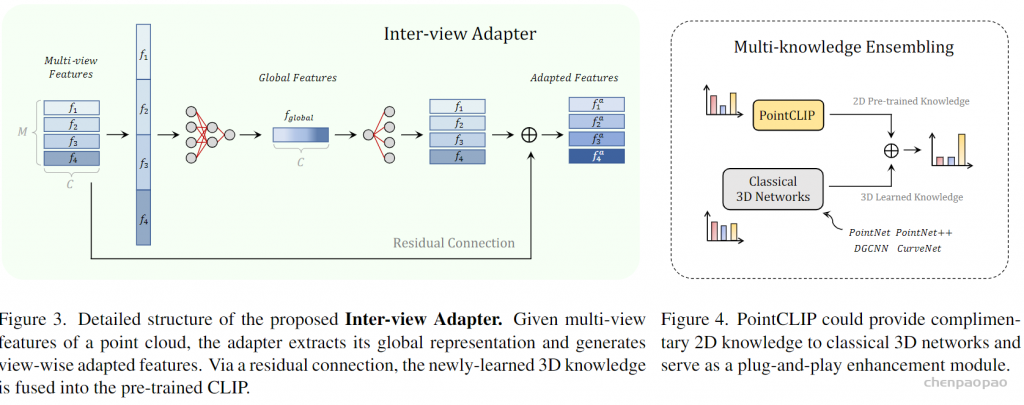
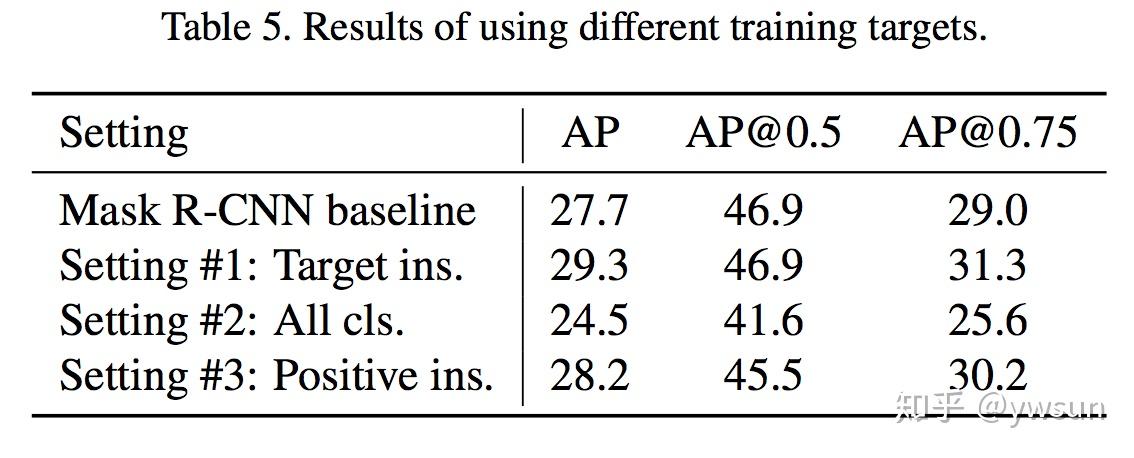
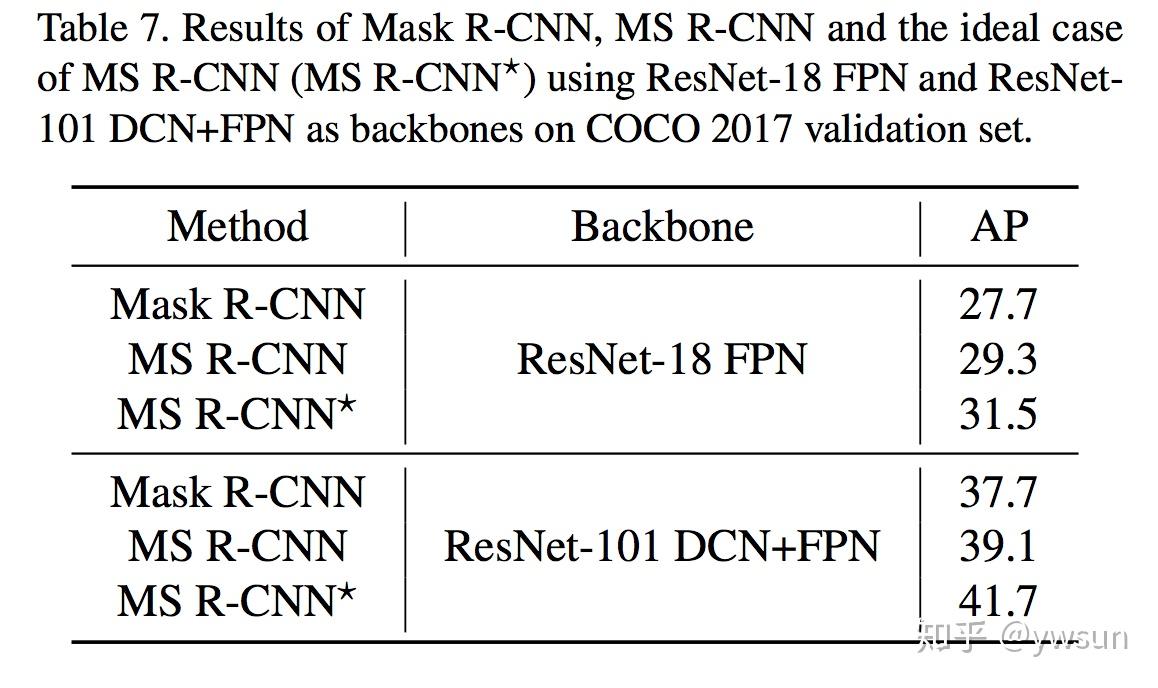
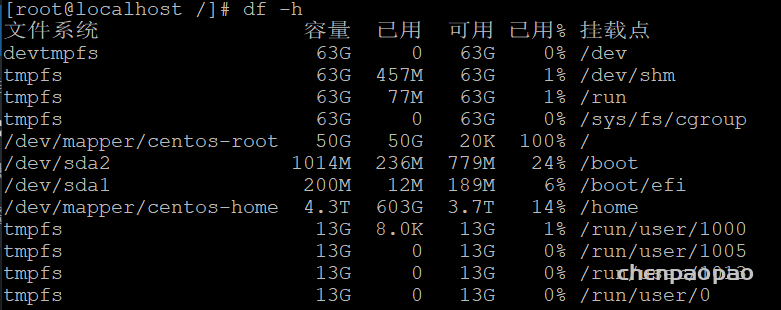
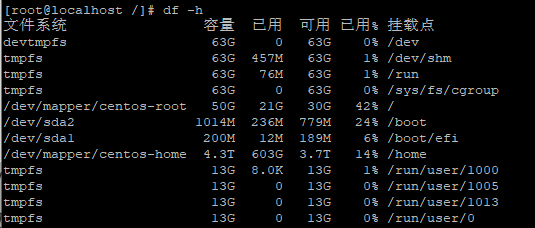
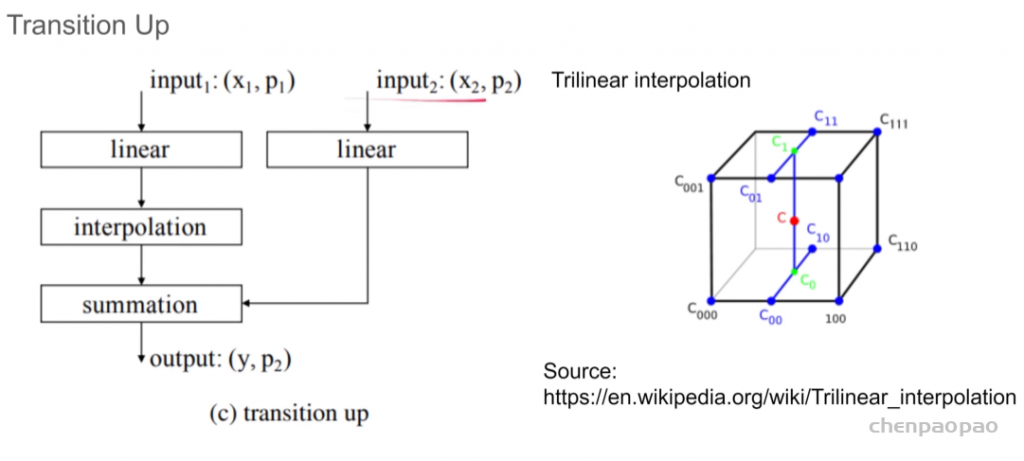
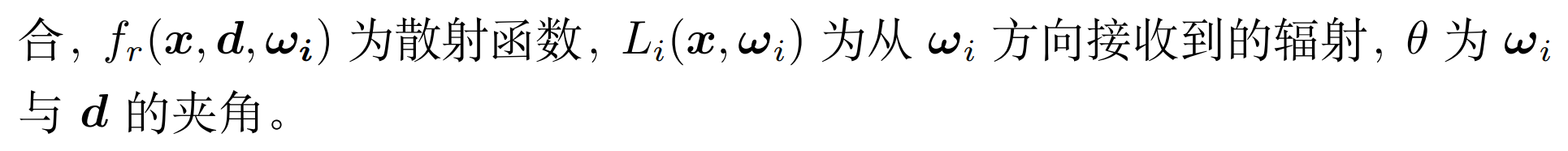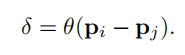微软亚洲研究院的研究项目 3D 视频会议系统 VirtualCube,可以让在线会议的与会者建立自然的眼神交互,沉浸式的体验就像在同一个房间内面对面交流一样。该技术的相关论文被全球虚拟现实学术会议 IEEE Virtual Reality 2022 接收并获得了大会的最佳论文奖(Best Paper Award – Journal Papers Track)。
为了解决这些问题,微软亚洲研究院提出了创新的 3D 视频会议系统——VirtualCube,它可以在远程视频会议中建立起真人等大的 3D 形象,无论是正面沟通,还是侧方交流,系统都能够正确捕捉到与会者的眼神、动态,建立起眼神和肢体交流。相关论文被全球虚拟现实学术会议 IEEE Virtual Reality 2022 接收并获得了大会的最佳论文奖(Best Paper Award – Journal Papers Track)
VirtualCube 系统具有三大优势:
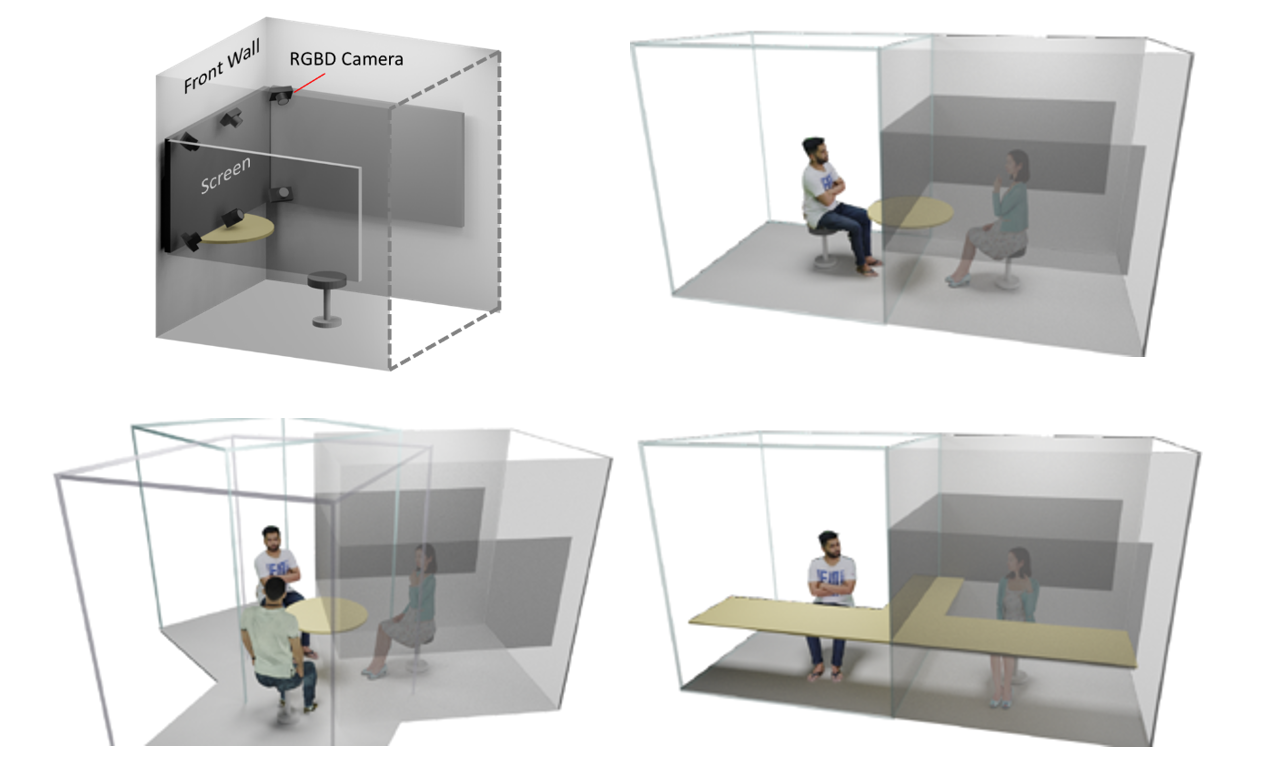
标准化、简单化,全部使用现有的普通硬件设备。与办公场所中常见的格子间(Cubicle)类似,每个 VirtualCube 都提供了一致的物理环境和设备配置:与会者正前方安装有6个 Azure Kinect RGBD 摄像头,以捕捉真人的图像和眼神等动作;在与会者的正面和左右两侧还各有一个大尺寸的显示屏,以创造出身临其境的参会感。使用现有的、标准化的硬件能够大大简化用户设备校准的工作量,从而实现 3D 视频系统的快速部署和应用。
感。使用现有的、标准化的硬件能够大大简化用户设备校准的工作量,从而实现 3D 视频系统的快速部署和应用。
实时、高质量渲染真人图像。VirtualCube 可以捕捉到参与者的各种细微变化,包括人的皮肤颜色、纹理,面部或衣服上的反射光泽等,并实时渲染生成真人大小的 3D 形象,显示在远程与会者的屏幕中。而且虚拟会议环境的背景也可以根据用户的需求自由选择。
任意变换会议场景,都能身临其境
V-Cube View和V-Cube Assembly算法双剑合璧,沉浸式会议体验不再是难题
其实业界对 3D 视频会议的研究从未间断过。早在2000年,就有人曾提出过与类似混合现实技术有关的畅想。基于这个设想,科研人员一直在探索如何将视频会议以更逼真、更自然的方式呈现,期间也出现了不同的技术路线和解决方案,但都没有达到理想的效果。对此,微软亚洲研究院主管研究员张译中和杨蛟龙表示,过往的研究仍然有很多没有解决的问题:首先,在真实环境下,无论放置怎样的单目摄像设备,即使图像质量再高,与会者也很难形成自然的眼神交流,特别是多人会议的情况;其次,很多研究针对特定的会议场景进行优化,如两个人面对面的会议或三人的圆桌会议,很难支持不同的会议设置;第三,虽然在影视界我们能够看到一些逼真的虚拟人,但那是需要专业的技术和影视团队长时间打磨和优化才能实现的,仍然需要一定的手工劳动,目前无法进行实时捕捉和实时渲染。
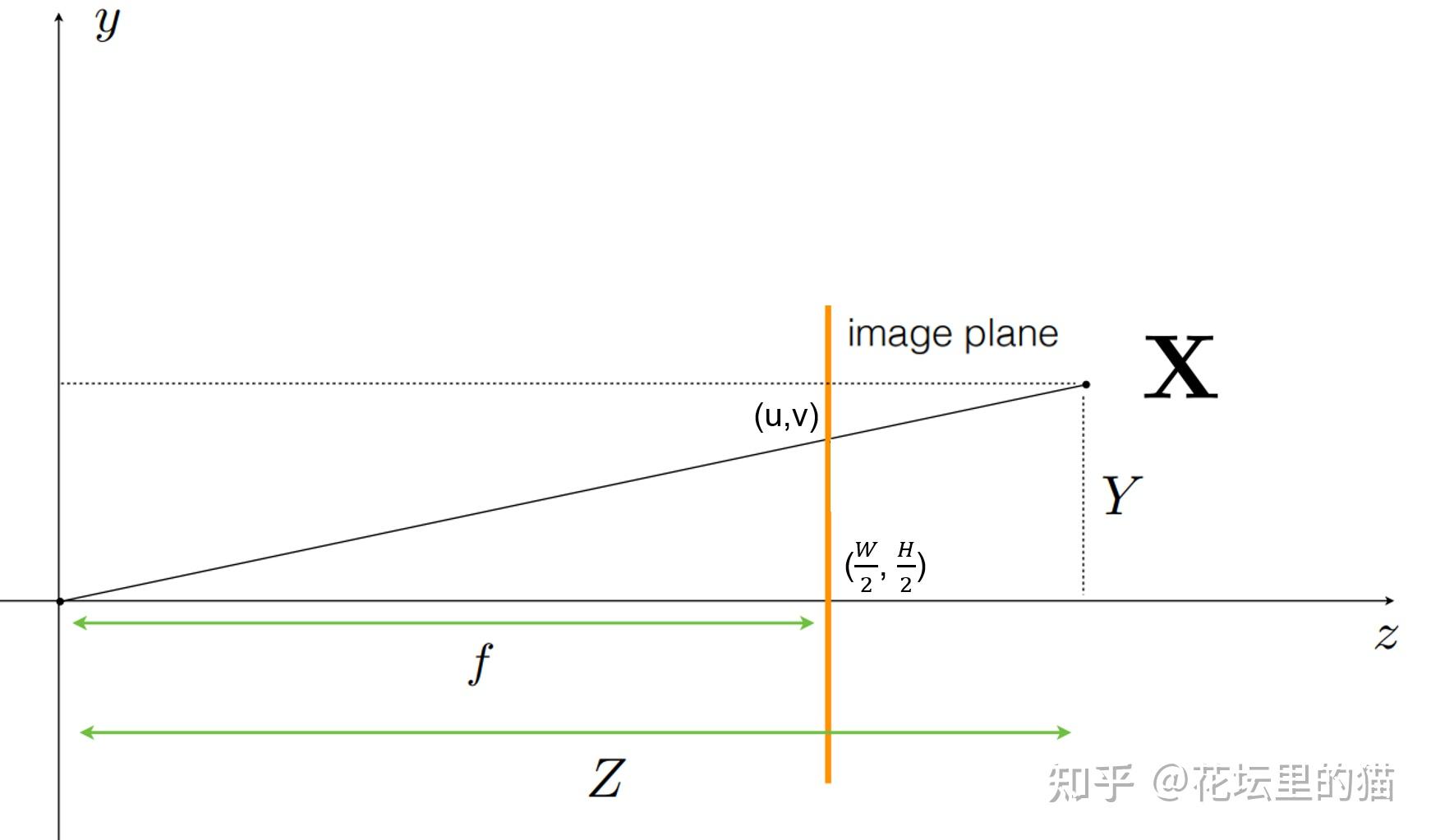
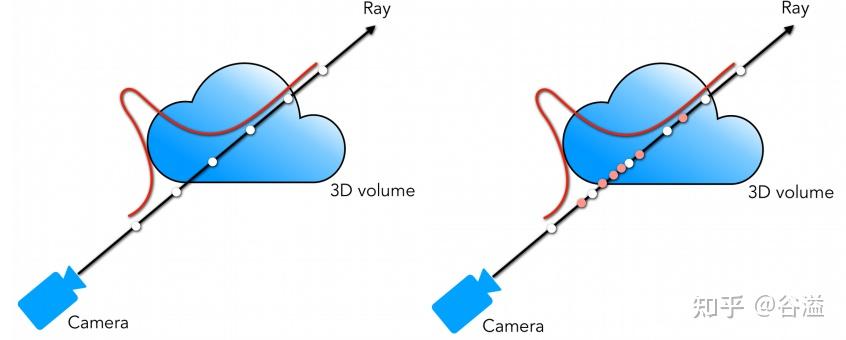
总之, ray tracing就是借由这个概念算出在 image平面上的 2D投影该长什么样子。实际上这边的名词蛮复杂的 (至少对非图学出身的笔者来说),像是 ray tracing、 ray casting、 ray marching什么的。为了避免混淆视听,这边就先不解释过多了。
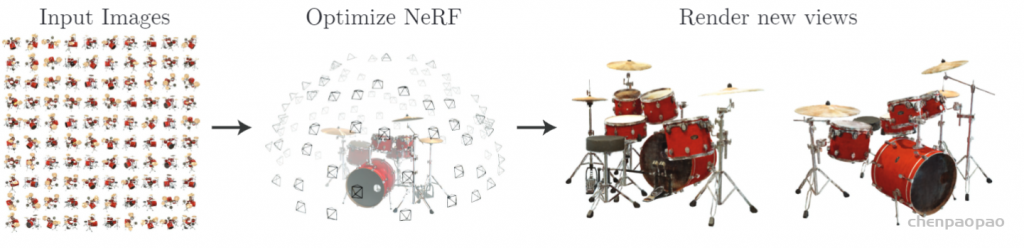
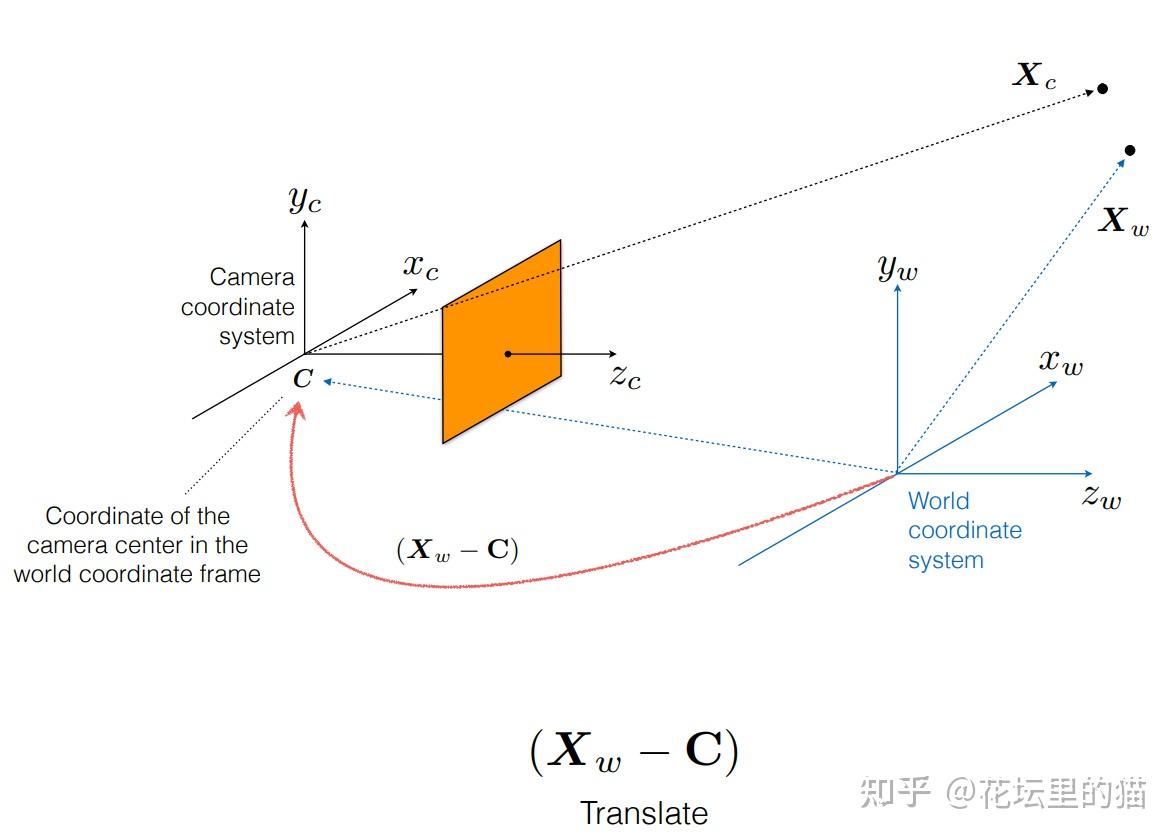
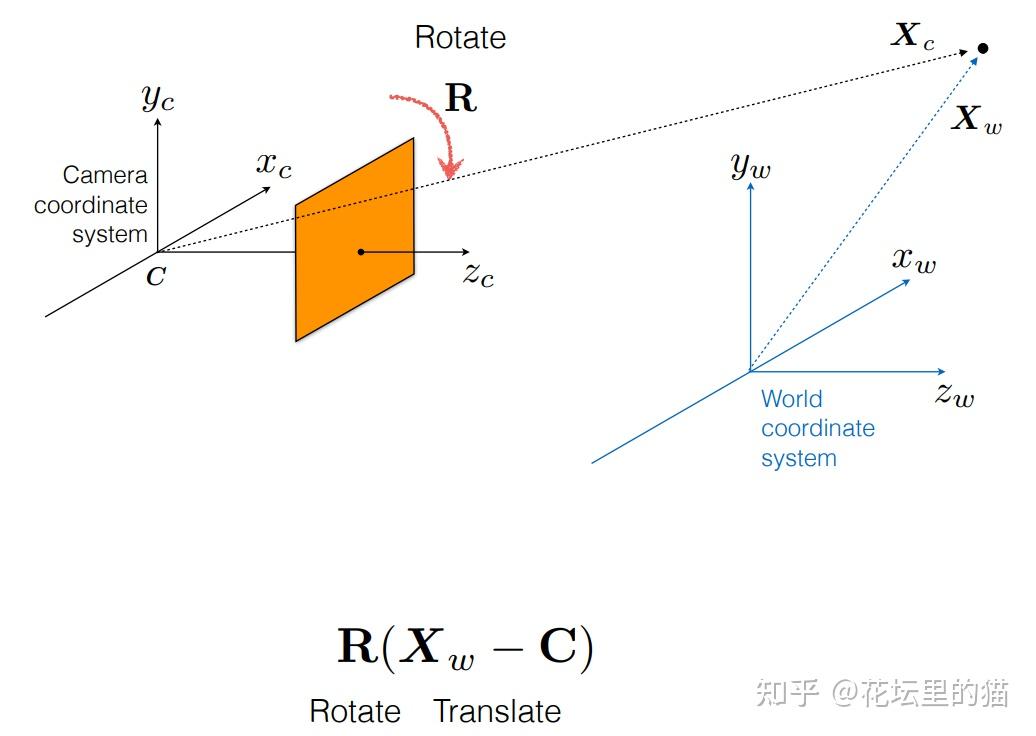
接下来,就开始正式介绍 NeRF的细节。
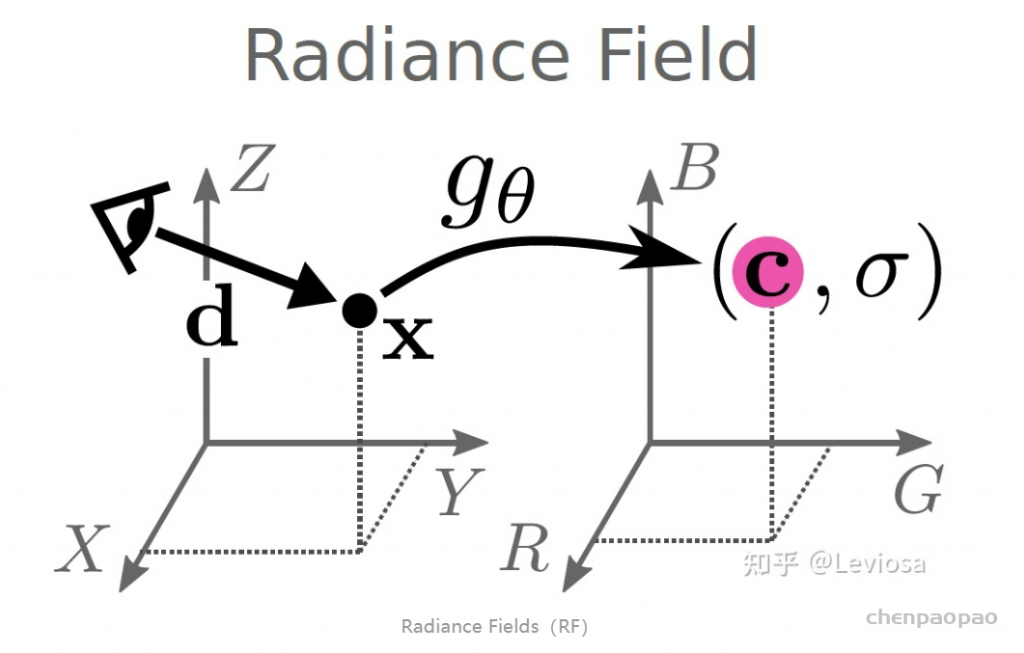
Neural Radiance Fields (NeRF)-神经辐射场
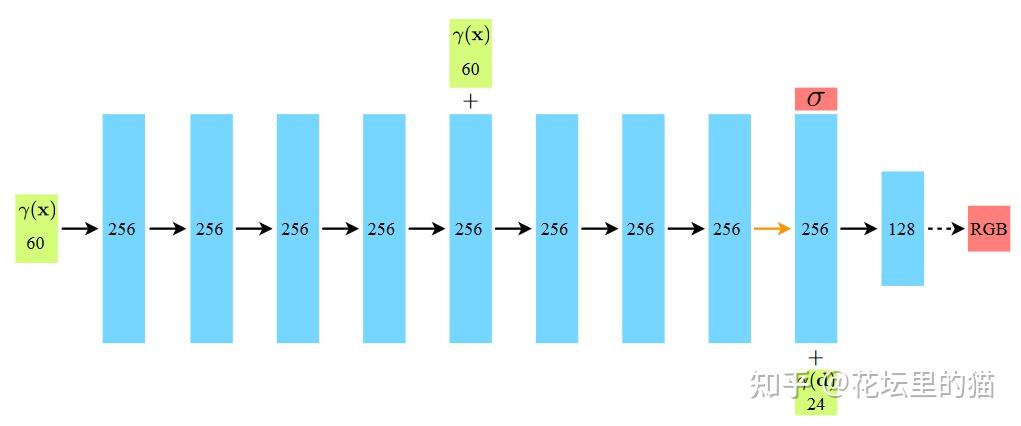
NeRF网路的输入是一组 5D的参数,包含一组 3D的 location X = (x, y, z)跟一组 2D的 view direction (θ, φ),实事上这个 view direction表示为 3D Cartesian unit vector(笛卡尔单位矢量),称为 d。而NeRF网路的输出则是一组 emitted color (如RPG的c=(r, g, b)) 与 volume density σ。
首先由于体素渲染需要沿着光线进行积分,而积分在计算机中是以离散的乘积和进行计算的,那么这里就涉及到在光线上进行点的采样。NeRF在光线的点采样过程中的进行了一些设计。首先为了避免大量的点采样导致的计算量的激增,NeRF设计了coarse to fine的采样策略。在coarse采样阶段,采用了带有扰动的均匀采样方法。第一步在光线的边界之间进行深度空间的均匀采样:
z_steps = torch.linspace(0, 1, N_samples, device=rays.device)
z_vals = near * (1-z_steps) + far * z_steps
在GRAF之后,GIRAFFE实现了composition。在NeRF、GRAF中,一个Neural Radiance Fields表示一个场景,one model per scene。而在GIRAFFE中,一个Neural Radiance Fields只表示一个物体,one object per scene(背景也算一个物体)。这样做的妙处在于可以随意组合不同场景的物体,可以改变同一场景中不同物体间的相对位置,渲染生成更多训练数据中没有的全新图像。
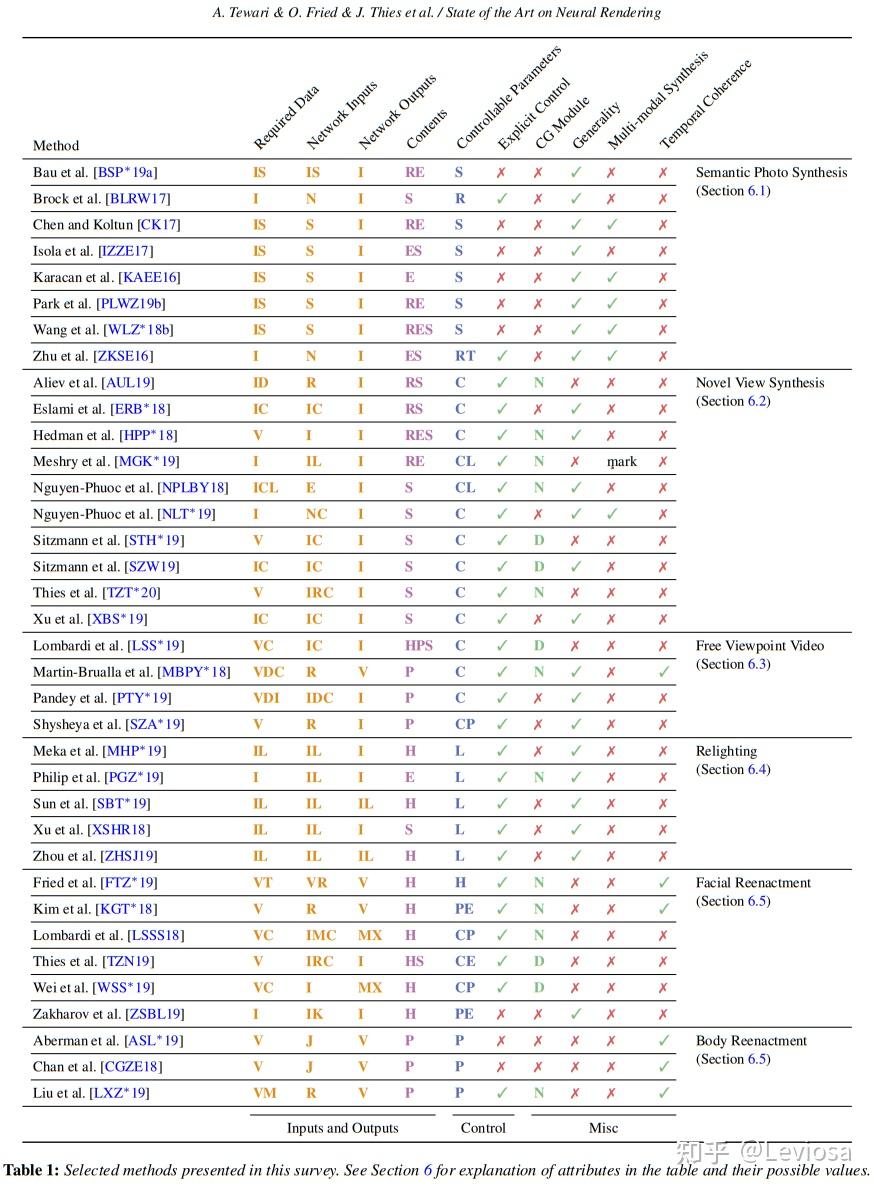
在针对这个更宽泛的概念的综述State of the Art on Neural Rendering中,Neural Rendering的主要研究方向被分为5类,NeRF在其中应属于第2类“Novel View Synthesis”(不过这篇综述早于NeRF发表,表中没有NeRF条目)。
Neural Rendering的5类主要研究方向
表中彩色字母缩写的含义:
在这篇综述中,Neural Rendering被定义为:
Deep image or video generation approaches that enable explicit or implicit control of scene properties such as illumination, camera parameters, pose, geometry, appearance, and semantic structure.
融入了 Prompt 的模式大致可以归纳成 “Pre-train, Prompt, and Predict”,在该模式中,下游任务被重新调整成类似预训练任务的形式。例如,通常的预训练任务有 MLM(Masked Language Model),在文本情感分类任务中,对于 “I love this movie” 这句输入,可以在后面加上 Prompt:”the movie is ___”,组成如下这样一句话:
Prompt 在 PLM debias 方面的应用。由于 PLM 在预训练过程中见过了大量的人类世界的自然语言,所以很自然地会受到一些影响。举一个简单的例子,比如说训练语料中有非常多 “The capital of China is Beijing”,导致模型每次看到 “capital” 的时候都会预测出 “Beijing”,而不是去分析到底是哪个国家的首都。在应用的过程中,Prompt 还暴露了 PLM 学习到的很多其它 bias,比如种族歧视、性别对立等。这也许会是一个值得研究的方向
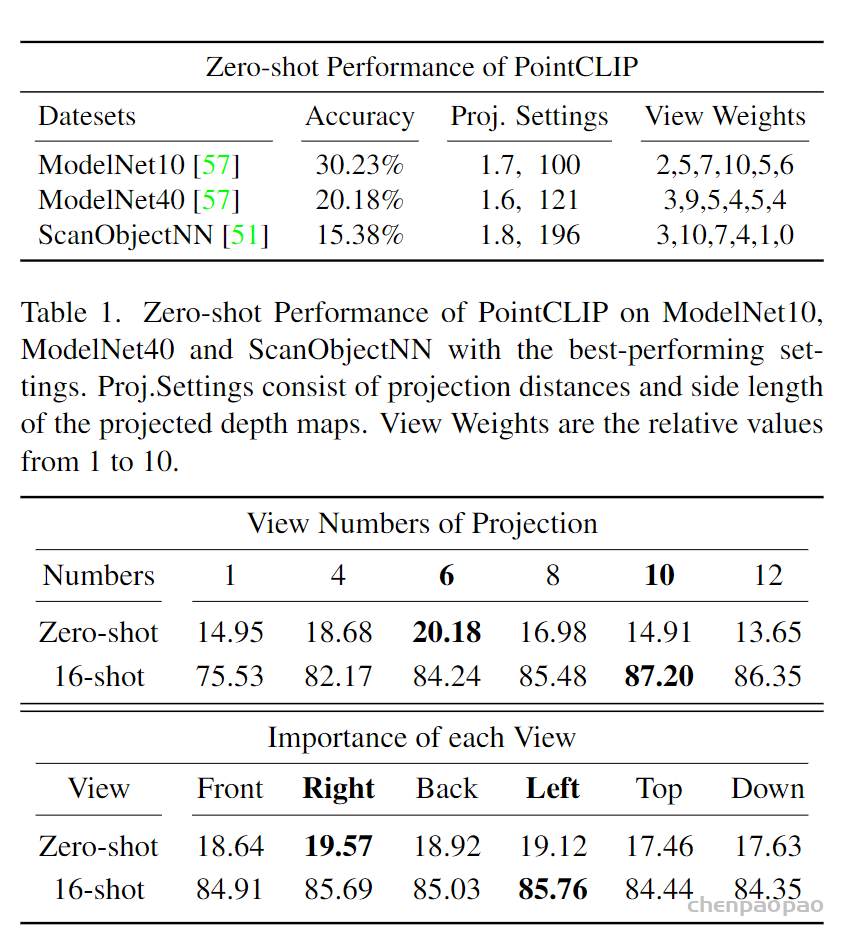
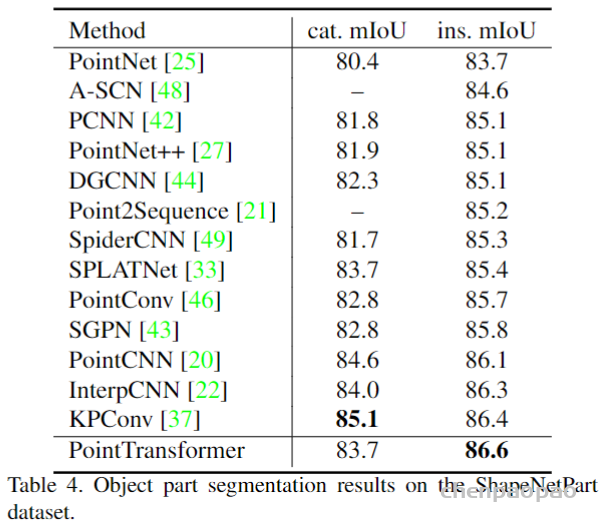
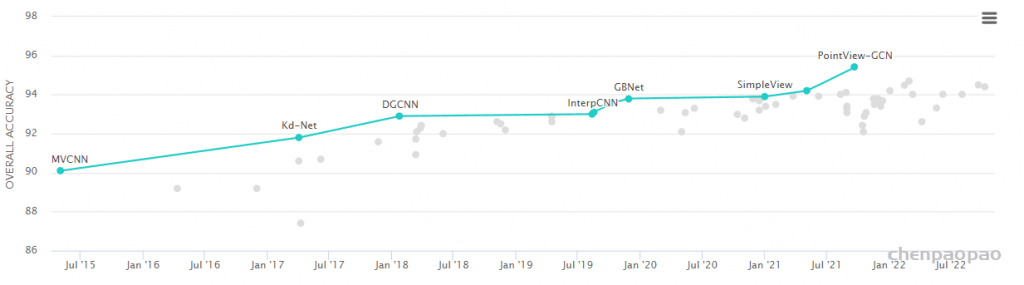
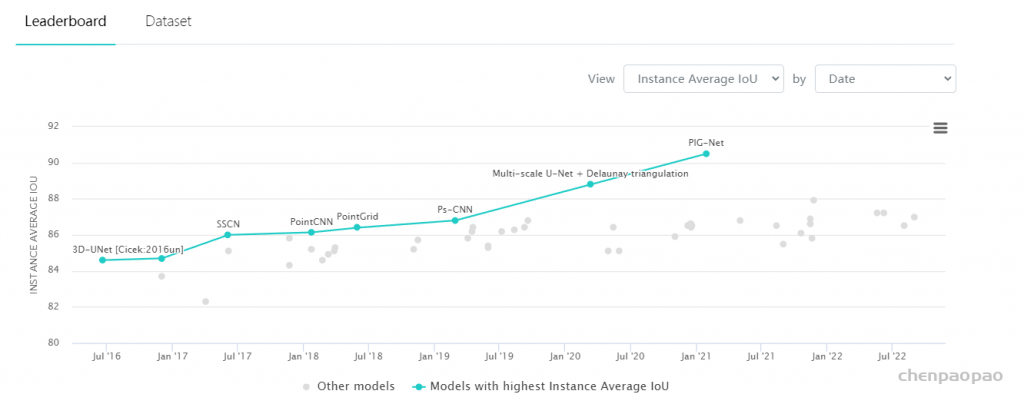
3D Point Cloud Classification on ModelNet40 3D Point Cloud Classification on ModelNet40 3D Part Segmentation on ShapeNet-Part3D Semantic Segmentation on SemanticKITTI