论文:Point Transformer
作者单位:牛津大学, 港中文(贾佳亚等), Intel Labs

transformer应用到了点云任务处理中。为点云设计了自注意力层,并使用它们来构造诸如语义场景分割,object part分割和对象分类等任务的自注意力网络。
attention层设计:
这里的y是输出的feature,ϕ、ψ、α都是逐点特征变换的一种方式(比如mlp),δ是一个位置编码函数,ρ是正则化函数,简单来说,xi是点i的feature向量,先通过特征变换将点i和点j(Xj是Xi的邻域上的点,而非全局的,目的是减少计算量)的特征得到,这里的β是关系函数,通过这个函数得到两个点特征之间的关系,也就是建立每个点特征之间的关系,然后加上位置编码函数δ,γ是映射函数,也就是映射到某一维度而用。在这基础上就可以设计这里的重点,Point transformer层了

输入是(x,p)也就是每个点的位置信息,首先通过两个线性函数编码不同主次点的特征向量(也就是得到前面的key向量),再用一个MLP得到位置函数,也就是前面的查询向量),两者结合得到relation关系,然后再用一个线性函数得到它的值向量,将relation和值向量结合,也就是前面说的对于每个点既关注它的和其他点之间的语义关系,也关注它和其他点之间的位置关系,最后输出y作为点云处理结果。
位置函数也就是计算查询向量的那个函数:
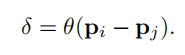
p就是各自点的三维坐标值,θ是一个MLP层,而前面的线性函数也就是ax+b的形式(就是linear层)
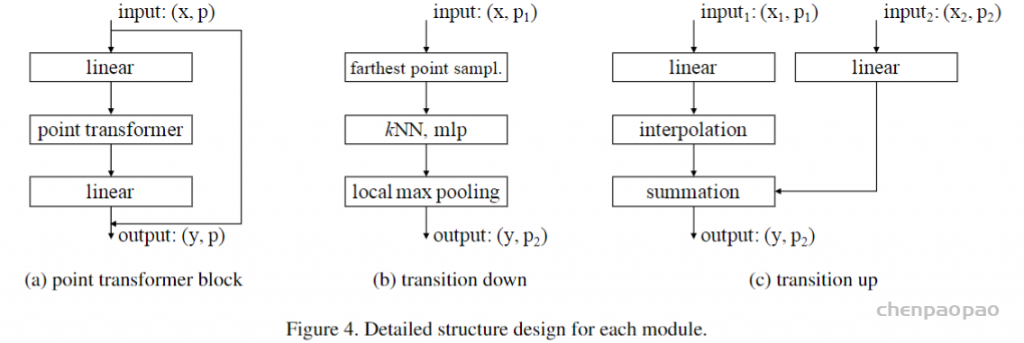
定义完了transformer层,就可以定义一个block来作为基本的block(下图a):
输入是点集合x(拥有各自的三维点坐标等点特征),输出就是将每个点x的更新后的特征输出:
down的功能是根据需要减少点集的基数,简单来说就是减少点,而up就是根据两个不同数量的点来得到结合后的结果,常常使用在U型网络设计中(也就是当前层结果是结合了当前层的输入和之前某一层不同维度的输出而得到)
transition down:
step1:farthest point sample,把p1个点采样到 p个点,通过MLP改变特征向量(y,p),通过KNN算法,把p个点分成p2类,每个类内部做最大池化得到最终输出(y,p2)。

up模块:input1 如何才能扩充点数:通过线性插值算法
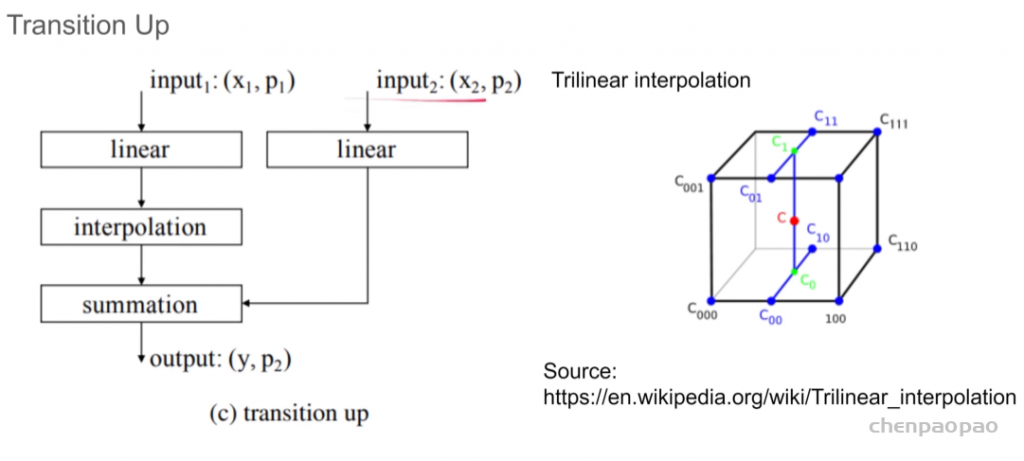
网络结构:

实验结果:
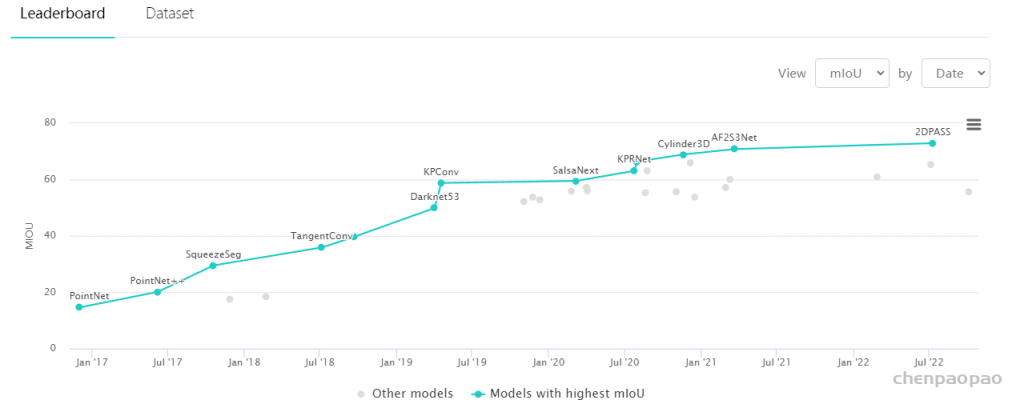
用于大规模语义场景分割的具有挑战性的S3DIS数据集上,Point Transformer在Area 5上的mIoU达到70.4%,比最强的现有模型高3.3个绝对百分点,并首次超过70%mIoU阈值 。

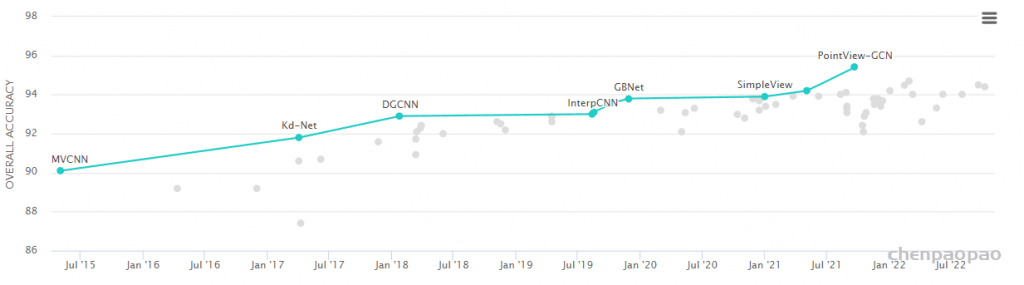
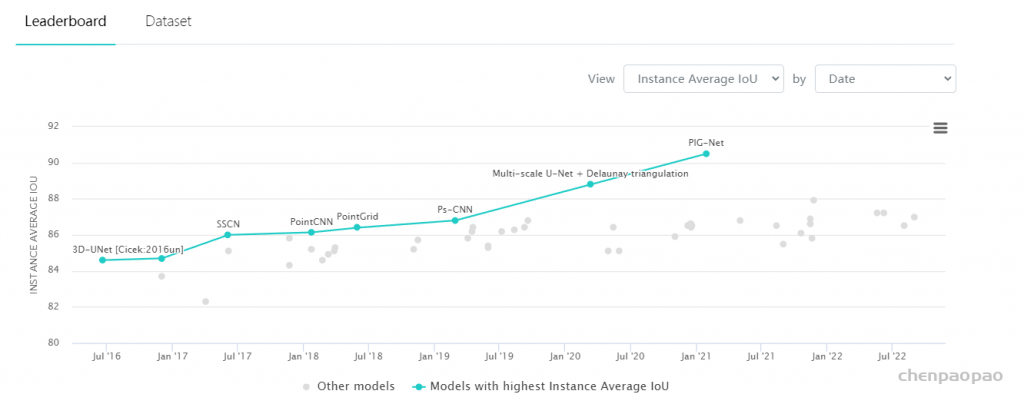
在ModelNet40和ShapeNetPart数据集上的性能表现:

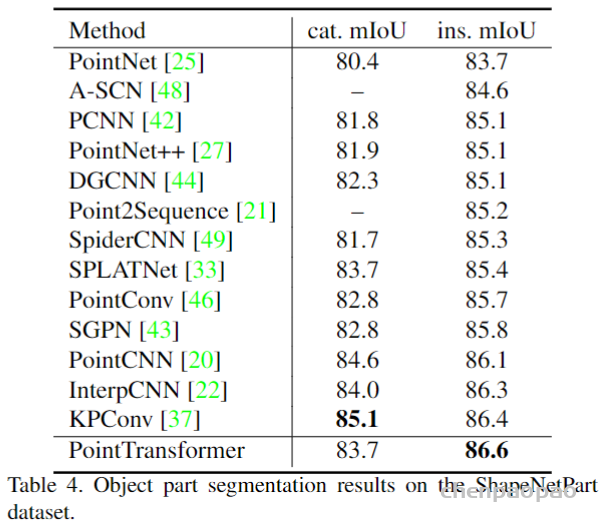
目前paper with code 网站的排名: