
代码链接:https://github.com/raoyongming/DenseCLIP
论文链接:https://arxiv.org/abs/2112.01518
最近的研究表明,使用对比图像文本对进行大规模的预训练可能是从自然语言监督中学习高质量视觉表示的有前途的方法。得益于更广泛的监督来源,这一新范式在下游分类任务和可迁移性方面展现出了不错的结果。
然而,将从图像-文本对中学习到的知识转移到更复杂的密集预测任务的问题几乎没有被研究 。在这项工作中,作者通过隐式和显式地利用CLIP的预训练的知识,提出了一个新的密集预测框架。
具体而言,作者将CLIP中的原始图像-文本匹配问题 转换为像素-文本匹配问题 ,并使用像素-文本得分图来指导密集预测模型的学习。通过进一步使用来自图像的上下文信息来提示语言模型,能够促进模型更好地利用预训练的知识。
本文的方法与模型无关,可以应用于任意密集预测模型和各种预训练的视觉主干,包括CLIP模型和ImageNet预训练的模型。广泛的实验证明了本文的方法在语义分割,目标检测和实例分割任务上的卓越性能。

在本文中,作者研究了如何将预训练的CLIP模型迁移到密集的预测任务 。与传统的ImageNet预训练模型相比,一个明显的挑战是上游对比预训练任务和下游像素预测任务之间的差距,前者涉及图像和文本的实例级表示,而后者仅基于像素级别的视觉信息。
为了解决这个问题,作者提出了一个新的语言指导的密集预测框架,名为DenseCLIP 。
如上图所示,它是通过隐式和显式地利用来自CLIP模型的预训练的知识而为各种密集预测任务而设计的。利用预训练的知识的一种隐式方法是直接微调下游数据集上的模型。结果表明,通过对超参数进行一些修改,CLIP模型可以优于传统的ImageNet预训练模型(如下图所示)。
但是直接的方法不能充分利用CLIP模型的潜力。受CLIP中的原始对比学习框架的启发,作者提出将CLIP中的原始图像-文本匹配问题转换为像素-文本匹配问题,并使用像素-文本得分图来明确地指导密集预测模型的学习 。
通过进一步使用图像中的上下文信息,使用Transformer模块来提示语言模型,能够通过优化文本嵌入,使模型更好地利用预训练的知识。
Preliminaries: Overview of CLIP
CLIP由两个编码器组成,包括一个图像编码器 (ResNet或ViT) 和一个文本编码器 (Transformer)。CLIP的目标是通过对比目标在预训练期间对齐视觉和语言的嵌入空间。
为了学习更多可迁移的预训练知识,CLIP收集4亿图像-文本对进行模型训练。迁移CLIP的知识,对于下游分类任务,一种简单但有效的方法是基于模板(如“a photo of a [CLS]”)构建一组文本提示,其中[CLS]可以替换为实际的类名。
然后给定一个图像,可以使用CLIP来计算图像和嵌入空间中的文本提示之间的相似性,并且得分最高的类被视为最终预测。最近,一些作品已经表明CLIP可以通过很少的样本获得强大的分类性能。因此,这就出现了一个有趣的问题: CLIP强大的能力是否可以迁移到像密集预测这样更复杂的视觉任务中?
但是,这种扩展是不容易的。首先,如何在密集预测任务中利用视觉语言预训练模型是一个几乎没有被研究的问题。尽管一种简单的解决方案是仅像预训练的2D主干一样使用图像编码器,但作者认为文本编码器中包含的语言先验也非常重要 。
其次,由于上游对比预训练任务与下游每像素预测任务之间存在巨大差距,因此将知识从CLIP转移到密集预测更加困难 ,前者考虑图像和文本的实例级表示,后者仅基于视觉信息,但需要像素级输出。

Language-Guided Dense Prediction
为了解决上述问题,作者提出了本文的语言指导的密集预测框架,该框架可以更好地利用CLIP预训练模型中的语言先验。本文的模型结构如上图所示。作者发现,除了全局图像特征之外,还可以从CLIP图像编码器的最后一层中提取语言兼容的特征图。
为了说明这一点,下面首先详细描述CLIP图像编码器的结构。以ResNet 编码器为例,总共有4个阶段,将特征图表示为。与原始的ResNet不同,CLIP添加了一个注意力池化层。
具体而言,CLIP首先对执行全局平均池化,以获得全局特征 ,其中是从主干网络第4阶段开始的特征图的高度,宽度和通道数。然后将concat的特征输入到多头自注意层(MHSA) 中:

在CLIP的标准训练过程中,全局特征用作图像编码器的输出,而其他输出通常被忽略。然而,作者发现z有两个有趣的特性:
1)z仍然保留了足够的空间信息,因此可以用作特征图 。
2)因为MHSA对每个输入元素都是对称的,所以z可能和 相似 。根据以上观察结果,作者可以将z用作语言兼容的特征图。
为了获得文本特征,可以从模板“a photo of a [CLS].”中构造文本提示使用K类名称,并使用CLIP文本编码器将特征提取。然后,使用语言兼容的特征图z和文本特征t通过以下方式计算像素文本得分图
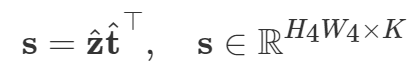
其中和是沿通道维度的z和t的l2归一化版本。得分图表示了像素文本匹配的结果,这是本文框架中最关键的要素之一。首先,可以将分数图视为具有较低分辨率的分割结果,因此可以使用它们来计算辅助分割损失。
其次,将分数映射concat到最后一个特征映射,以显式地合并语言先验,即。本文的框架是与模型无关的,因为修改的特征图可以像往常一样直接用于分割或检测。
Context-Aware Prompting
先前的研究已经证明,减少视觉或语言领域的差距可以显着提高CLIP模型在下游任务中的性能。因此,作者寻求其他方法来改进文本特征t,而不是使用人类预先定义的模板。
Language-domain prompting
与原始CLIP不同,原始CLIP使用人工设计的模板,如“a photo of a [CLS]”。CoOp引入了可学习的文本上下文,通过使用反向传播直接优化上下文,在下游任务中实现更好的可迁移性。受CoOp的启发,作者还在框架中使用可学习的文本上下文作为baseline,其中仅包括语言域提示。文本编码器的输入变为:
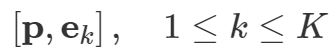
其中是可学习的文本上下文,而是第k类名称的嵌入。
Vision-to-language prompting
包括视觉上下文的描述可以使文本更加准确。例如,“a photo of a cat in the grass.”比“a photo of a cat.”更准确。因此,作者研究了如何使用视觉上下文来重新提取文本特征。通常可以使用Transformer decoder中的交叉注意机制来建模视觉和语言之间的相互作用。
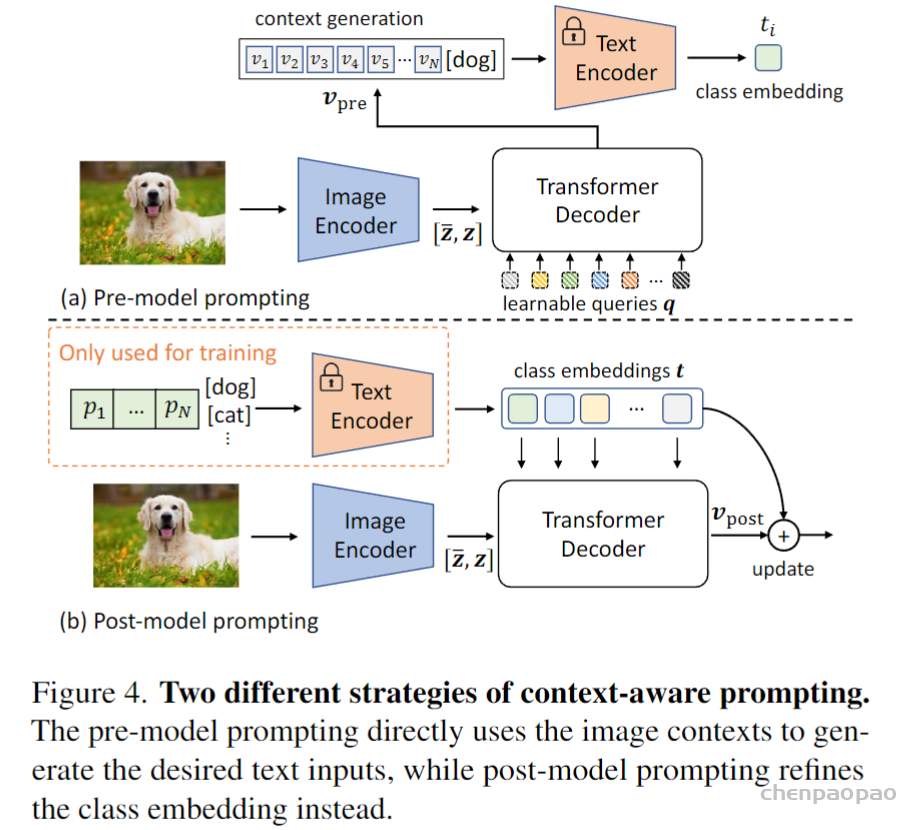
作者提出了两种不同的上下文感知提示策略,如上图所示。作者考虑的第一个策略是pre-model prompting 。将特征传递给Transformer解码器以编码视觉上下文
其中是一组可学习的查询,而是提取的视觉上下文。
另一种选择是在文本编码器之后重新定义文本特征,即post-model prompting 。在此变体中,作者使用CoOp生成文本特征,并直接将其用作Transformer解码器的查询
尽管这两个变体的目标是相同的,但作者认为post-model prompting更好 ,主要有两个原因:
1)模型后提示是高效的。由于文本编码器的输入依赖于图像,因此在推理过程中,预模型提示需要额外的文本编码器前向传递。在后模型提示的情况下,可以存储训练后提取的文本特征,从而减少文本编码器在推理过程中带来的开销。
2) 实验结果表明,模型后提示可以比模型前提示获得更好的性能。