
端到端类型
用MPI(Multi-Plane Image )代替NeRF的RGBσ作为网络的输出

来自字节跳动视觉技术团队的研究者将 NeRF 和 Multiplane Image(MPI)结合,提出了一种新的三维空间表达方式 MINE。该方法通过对单张图片做三维重建,实现新视角合成和深度估算。
开源了训练代码(基于LLFF数据集的toy example),paper里面数据集的pretrained models,并提供了demo代码:
相关工作
近年来,在新视角合成这个领域里,最火爆的方法无疑是 ECCV 2020 的 NeRF [5]。与传统的一些手工设计的显式三维表达(Light Fields,LDI,MPI 等)不同,NeRF 把整个三维空间的几何信息与 texture 信息全部用一个 MLP 的权重来表达,输入任意一个空间坐标以及观察角度,MLP 会预测一个 RGB 值和 volume density。目标图片的渲染通过 ray tracing 和 volume rendering 的方式来完成。尽管 NeRF 的效果非常惊艳,但它的缺点也非常明显:
- 一个模型只能表达一个场景,且优化一个场景耗时久;
- per-pixel 渲染较为低效;
- 泛化能力较差,一个场景需要较多的照片才能训练好。
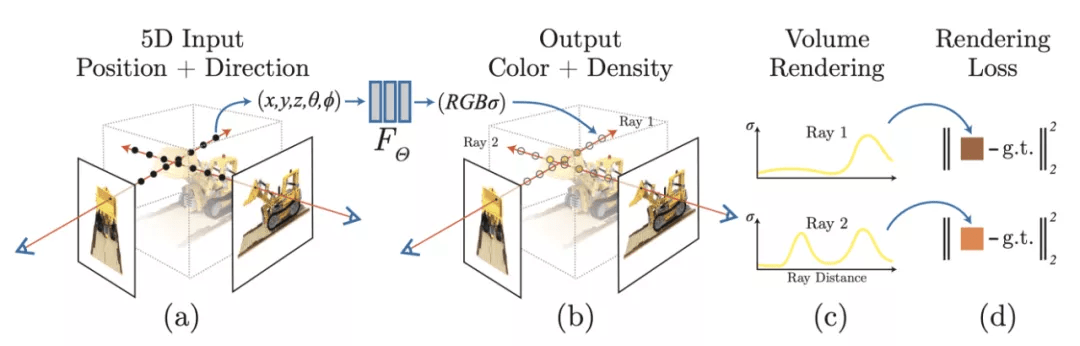
另外一个与该研究较相关的是 MPI(Multiplane Image)[1, 2, 3]。MPI 包含了多个平面的 RGB-alpha 图片,其中每个平面表达场景在某个深度中的内容,它的主要缺点在于深度是固定及离散的,这个缺点限制了它对三维空间的表达能力。[1, 2, 3] 都能方便地泛化到不同的场景,然而 MPI 各个平面的深度是固定且离散的,这个缺点严重限制了它的效果。

结合了NeRF和Multiplane Image(MPI),提出了一种新的三维空间表达方式MINE。MINE利用了NeRF的思路,将MPI扩展成了连续深度的形式。输入单张RGB图片,我们的方法会对source相机的视锥(frustum)做稠密的三维重建,同时对被遮挡的部分做inpainting,预测出相机视锥的三维表达。利用这个三维表达,给出target相机相对于source相机的在三维空间中的相对位置和角度变化(rotation and translation),我们可以方便且高效地渲染出在目标相机视图下的RGB图片以及深度图。
MINE在KITTI,RealEstate10K以及Flowers Light Fields数据集上,生成质量大幅超过了当前单视图合成的state-of-the-art。同时,在深度估计benchmark iBims-1和NYU-v2上,虽然我们在训练中只使用了RGB图片和sparse深度监督,MINE在单目深度估计任务上取得了非常接近全监督state-of-the-art的performance,并大幅超越了其他弱监督的方法。
Introduction and Related Works
视图合成(novel view synthesis)需要解决的问题是:在一个场景(scene)下,输入一个或多个图片,它们各自的相机内参和外参(source camera pose),之后对于任意的相机位置和角度(target camera pose),我们想要生成场景在该相机视图下的RGB图片。要解决这个问题,我们的模型需要学会场景的几何结构,同时对被遮挡的部分做inpainting。学术界设计了很多利用learning的方法预测场景的3D/2.5D表达,其中跟我们较相关的是MPI(Multiplane Image)[1, 2, 3]。MPI包含了多个平面的 RGB-α图片,其中每个平面表达场景在某个深度中的内容,它的主要缺点在于深度是固定及离散的,这个缺点限制了它对三维空间的表达能力。
近年来,这个领域的当红炸子鸡无疑是ECCV 2020的NeRF [5]。与传统的一些手工设计的显式三维表达(Light Fields,LDI,MPI等)不同,NeRF把整个三维空间的几何信息与texture信息全部用一个MLP的权重来表达,输入任意一个空间坐标以及观察角度,MLP会预测一个RGB值和volume density。目标图片的渲染通过ray tracing和volume rendering的方式来完成。尽管NeRF的效果非常惊艳,但它的缺点也非常明显:1. 一个模型只能表达一个场景,且优化一个场景耗时久;2. per-pixel渲染较为低效;3. 泛化能力较差,一个场景需要较多的照片才能训练好。
方法综述
该团队采用一个 encoder-decoder 的结构来生成三维表达:
- Encoder 是一个全卷积网络,输入为单个 RGB 图片,输出为 feature maps;
- Decoder 也是一个全卷积网络,输入为 encoder 输出的 feature map,以及任意深度值(repeat + concat),输出该深度下的 RGB-sigma 图片;
- 最终的三维表达由多个平面组成,也就是说在一次完整的 forward 中,encoder 需要 inference 一次,而 decoder 需要 inference N 次获得个 N 平面。
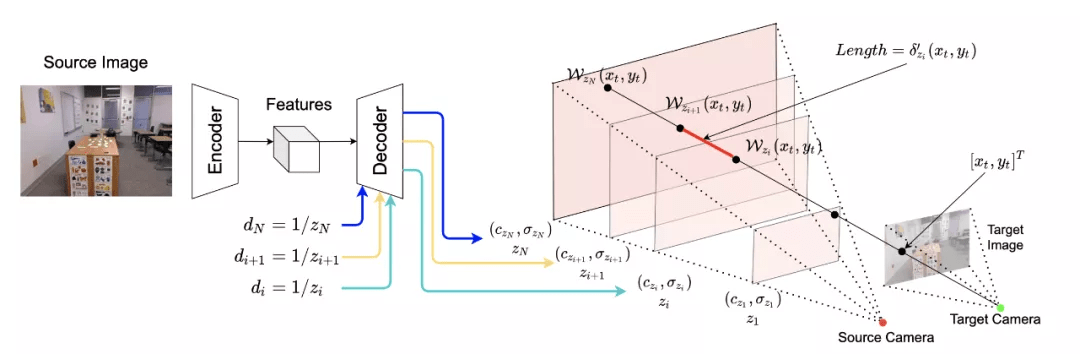
获得三维表达后,不再需要任何的网络 inference,渲染任意 target 相机 pose 下的视角只需要两步:
- 利用 homography wrapping 建立像素点间的 correspondence。可以想象,从 target 相机射出一条光线,这条光线与 target 图片的一个像素点相交,然后,研究者延长这条射线,让它与 source 相机视锥的各个平面相交。相交点的 RGB-sigma 值可以通过 bilinear sampling 获得;
- 利用 volume rendering 将光线上的点渲染到目标图片像素点上,获得该像素点的 RGB 值与深度。
三维表达与渲染
1. Planar Neural Radiance Field

2. Rendering Process


完成这两步之后,我们就可以通过上面volume rendering的公式渲染任意target camera下的视图了。需要注意的是,在获得3D表达后,渲染任意target camera pose下的视图都只需要这两个步骤,无需再做额外的网络inference。
Scale 校正

MINE 可以利用 structure-from-motion 计算的相机参数与点云进行场景的学习,在这种情况下,深度是 ambiguous 的。由于在这个方法中,深度采样的范围是固定的。所以需要计算一个 scale factor,使网络预测的 scale 与 structure-from-motion 的 scale 进行对齐。团队利用通过 Structure from Motion 获得的每个图片的可见 3D 点 P 以及网络预测的深度图 Z 计算 scale factor:

获得 scale factor 后,对相机的位移进行 scale:

需要注意的是,由于需要和 ground truth 比较,所以在训练和测试时需要做 scale calibration。而在部署时不需要做这一步。
端到端的训练
MINE 可以仅通过 RGB 图片学习到场景的三维几何信息,训练 Loss 主要由两部分组成:
1.Reconsturction loss——计算渲染出的 target 图片与 ground truth 的差异:

2.Edge-aware smoothness loss——确保在图片颜色没有突变的地方,深度也不会突变,这里主要参考了 monodepth2 [6] 种的实现:

3.Sparse disparity loss——在训练集各场景的 scale 不一样时,利用 structure-from-motion 获得的稀疏点云辅助场景几何信息的学习:

MINE 与 MPI、NeRF 的比较
MINE 是 MPI 的一种连续深度的扩展,相比于 MPI 和 NeRF,MINE 有几个明显的优势:
- 与 NeRF 相比,MINE 能够泛化到训练集没有出现过的场景;
- 与 NeRF 的逐点渲染相比,MINE 的渲染非常高效;
- 与 MPI 相比,MINE 的深度是连续的,能稠密地表示相机的视锥;
- MPI 通过 alpha 合成(alpha compositing)进行渲染,但该方法与射线上点之间的距离无关,而 MINE 利用 volume rendering 解决了这个限制。
然而,MINE 也有一些自身的局限性:
- 由于输入是单张图片,MINE 无法表达相机视锥以外的三维空间;
- 由于 MINE 的输入里没有观察角度,所以其无法对一些复杂的 view-dependent 效果(如光盘上的彩虹等)进行建模。
[1]. Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, Noah Snavely. Stereo Magnification: Learning View Synthesis using Multiplane Images. (SIGGRAPH 2018)
[2]. Ben Mildenhall, Pratul P. Srinivasan, Rodrigo Ortiz-Cayon, Nima Khademi Kalantari, Ravi Ramamoorthi, Ren Ng, Abhishek Kar. Local Light Field Fusion: Practical View Synthesis with Prescriptive Sampling Guidelines. (SIGGRAPH 2019)
[3]. Richard Tucker, Noah Snavely. Single-View View Synthesis with Multiplane Images. (CVPR 2020)