
paper:https://arxiv.org/abs/2206.02743
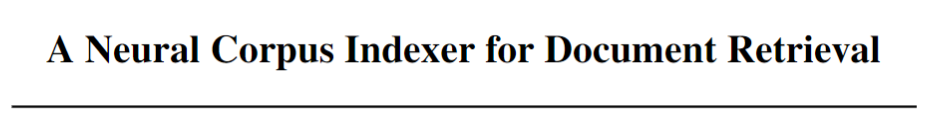
最近一篇Neural Corpus Indexer基于transformer的文档检索引发了争论。【知乎】所指论文为NeurIPS2022 Outstanding Paper A Neural Corpus Indexer for Document Retrieval。 根据OpenReview上的Revisions记录,Rebuttal阶段的最后修改应该是https://openreview.net/references/pdf?id=y45TgWUfyF,此时Table 1内容为:
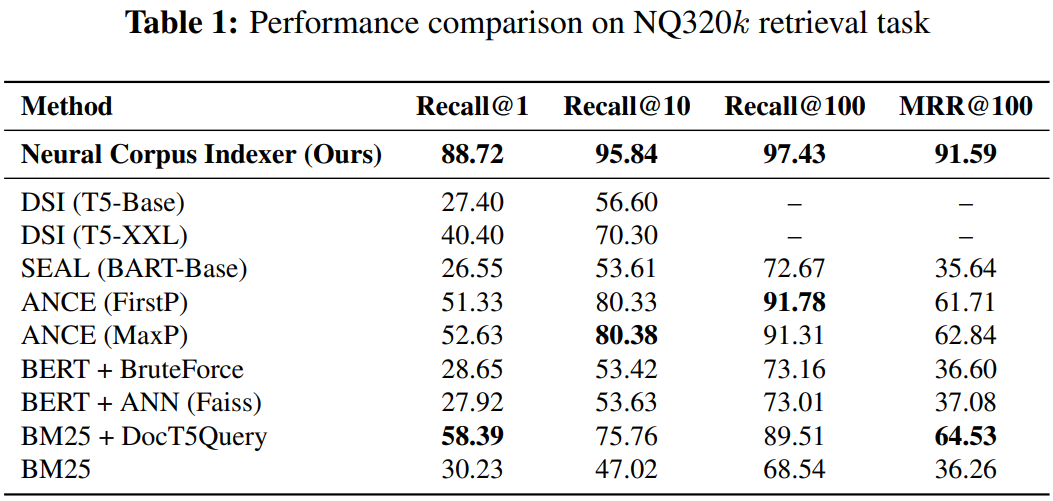
但Camera Ready版本是https://openreview.net/references/pdf?id=-bt0HSi9__,此时Table 1的内容为:
特别值得注意的是,在Rebuttal阶段,作者的General Response指出他们的工作即使去掉query generation进行公平比较,也远胜于基线:

但是根据Camera Ready版本的Table 1(见上)和Table 3

NCI(Base) w/ QG是65.86 NCI(Large) w/ QG是66.23 NCI(Base) w/o QG是46.41。如果NCI(Large) w/o QG像w/ QG的设置一样只比Base高0.37,那么它将低于Table 1中的SEAL(Large),而根据General Response,作者认可SEAL是w/o QG的设置。
反思:其实在机器学习里面,如果你的实验有了好的结果,尤其是特别好的结果,那么90%的情况都是有bug造成的。所以在效果比较好的情况时候一定要去仔细检查,看看是否有数据泄漏的情况。这个错误是比较常见的。
文本检索:在一堆的文本里面,将那些跟Query相关的文档找出来。是信息检索里最大的分支。相关信息检索的会议有:SigIR、WSDN、KDD、 NeurIPS (这个 NeurIPS 上文本检索的文章比较少,是一个偏算法的会议)
摘要:
当前最主流的的文档检索解决方案主要是基于索引检索方法,索引就是指对文档做一下哈希值或者embedding,但是索引很难直接针对最终检索目标结果进行优化。 因为哈希是一个固定的算法,或者词嵌入也不一定是根据用户最终的目标来做训练的。在这篇论文中,我们的目标是展示一个端到端的深度神经网络网络统一训练和检索阶段,可以显着提高召回率。在检索方面,召回率相比于准确率更加重要,因为需要把相关的文档全部都找出来,不希望遗漏。在这个文章中,作者提出了一个基于equence-to-sequence network(NCI),针对特定的query来说直接生成相关文档的id。为了提升NCI性能,提出了一个解码器(refix-aware weight-adaptive decoder),还使用了一些其他技术:query的生成、带语义的文档的ID和一致性的正则表达项。
摘要的写法比较常见:该领域之前的方法是怎样的,我们使用一个神经网络做一个端到端的学习,从原始的数据直接生成你要的一个结果。
导言:
文档检索和排序是标准网络搜索引擎的两个关键阶段。 第一,文档检索阶段就是给定一个query,来查询相关的候选文档,然后进行排名阶段为每个文档提供更精确的排名分数。 排名阶段通常由深度神经网络,将每对查询和文档作为输入并预测它们的相关性分数。 然而,一个精确的排名模型是非常昂贵的(对每一个查询对都要去预测分数),所以通常只有一百或一千个检索的候选结果。 因此,召回性能文档检索阶段对网络搜索引擎的有效性至关重要。(检索的这几百个候选结果应该要把所有相关的都包含进来才好)。
其实除了检索的召回率很重要,对于一个检索系统来说,性能是十分重要的,作者在这没有提到,对于一个搜索引擎来说,文档数量在千百亿以上,这个也是这篇文章的一个硬伤,就是太贵了。
现有的文档检索方法可以分为两类,即term-based和基于语义的方法。基于 term 术语的检索方法一般会构建一个倒排索引对整个网络语料库(可以认为就是一个字典,字典里的每个key就是查询,key的值就是对应这个文档id(key出现在该文档中))这个方法非常高效,但它们几乎无法捕获文档语义并且无法检索到类似的不同措辞的文件(比如我输入“文件”,找到的结果只是含有该“文件“的文档,对于文件的相似表达”file“,无法检索到)。 因此,提出了基于语义的方法 来减轻这种差异。基于语义的方法就是把query和文档分别映射成向量(使用twin-tower architecture架构)。然后使用近似K紧邻搜索感兴趣的的K个文档。这种方法的缺点:对于精确匹配exact match,(苹果13和苹果12)表现不好。另外就是ANN近邻算法某些情况(query和文档之间的关系复杂)下也不太好。
端到端的相关工作:一个是DSI,Differentiable Search Index,文本到文本的生成,一个纯transformer,DSI 中的解码器没有充分利用文档标识符的层次结构。第二个SEAL 通过利用段落中的所有 n-gram 作为其标识符id。
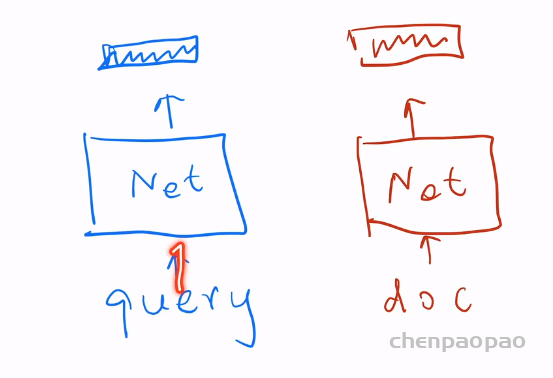
Neural Corpus Indexer
神经语料库索引器 (NCI) 是一种序列到序列的神经网络模型。 该模型将查询作为输入并输出最相关的文档标识符 (docid),它可以通过大量<query, docid>对进行训练。
下图就是这个模型的示意图。每次用户输入的是查询query,模型输出的是docID。那文本检索中的文档在哪?文档不可能作为输入送进模型,因为文档数量太大了,开销比较大。这个模型预测的时候不会看到文档的信息,但是做检索肯定需要模型知道各个文档的信息,所以就需要把这些文档全部放入这个模型。所以这部分数据分为两部分,一部分就是<query,docID>查询对。另一部分就是大量的被检索的文档<doc,docID>,因为模型预测的是query到docid的映射,所以需要让模型记住文档和docid的关系,常见做法就是用<doc,docid>无标号的数据去让模型记住全部的文档,当然这里可以把一个<doc,docID>对拆分成多个<query,docid>对,就是把doc里的句子给拆分成query会比较好做一些。模型的设计里有一些比较重要的点:(1)如何设计一个docID,而并非简单的数字,最好docID能够表示doc之间的语义信息。(2)如何将文档分出比较好的query,使得文档自己的语义和它的ID之间做好映射。同时分出的query能够跟预测时候的用户查询query有一定的相似性。(3)模型如何设计?编解码器和loss
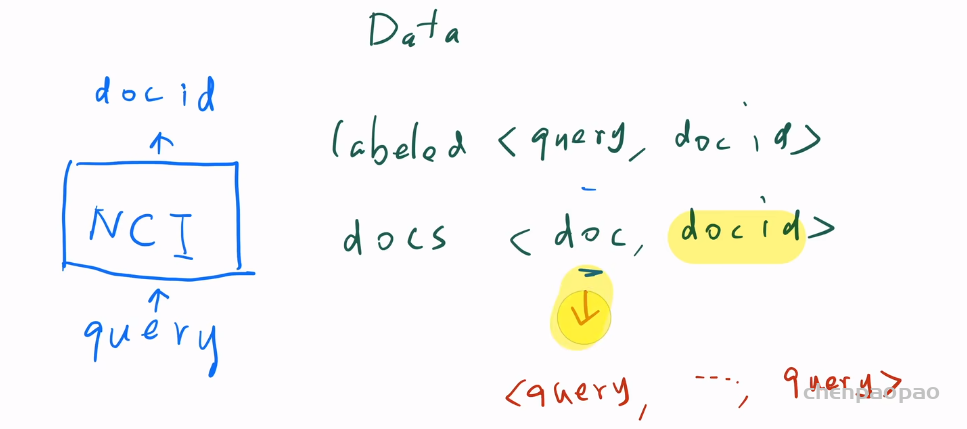
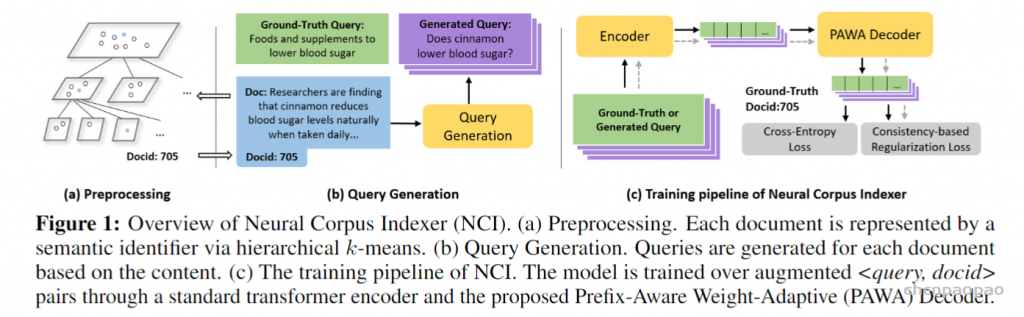
上图就是对应的三个关键点。
- 如何生成语义的ID:层次Kmeans算法

首先,上图中所有的灰点都代表不同的文档,首先对所有的文档做一个K-means聚类(k=3),不同的类给与不同的id(1,2,3),作为文档id的前缀,如果某个类里面的文档数量多于某个阈值C,他就会对这个类进一步做K-means,继续分出K个子类和对应的id。因此如果两个文档的前缀相近,表示俩个文档的距离比较近。这种层次化标号的好处是如果面对10000中类别标号,直接用一个softmax来对其分类是不好的,有了层次化的标号,就可以分层次预测类别。
- 从文本生成query
1、DocT5Query:sequence to sequence的模型,将Doc 翻译成 Query的模型。如何使用:将用于检索的文档输入到该模型,来获得多个query的输出(随机采样方法)。
2、Document as Query,像DSI一样,先把每个文档最先的64个term词作为一个query。然后随机在文档的随机位置选择10组,每组64个词作为query。(共11个query)
Prefix-aware weight-adaptive decoder:
r0,r1,r2就是不同层次的类别的id。相比传统的解码器,作者更加考虑到了r0,r1,r2之间的相对位置关系,因此解码器的输入不再是r0,r1,而是包含位置的(1,r0),(2,r1)。实验表明包含位置的解码器输入对于模型提升很大!!!!
另外作者认为在解码器的最后的softmax的全值W对于不同的ri是一样的,这样是不好的,因此希望不同的r对应不同权重。
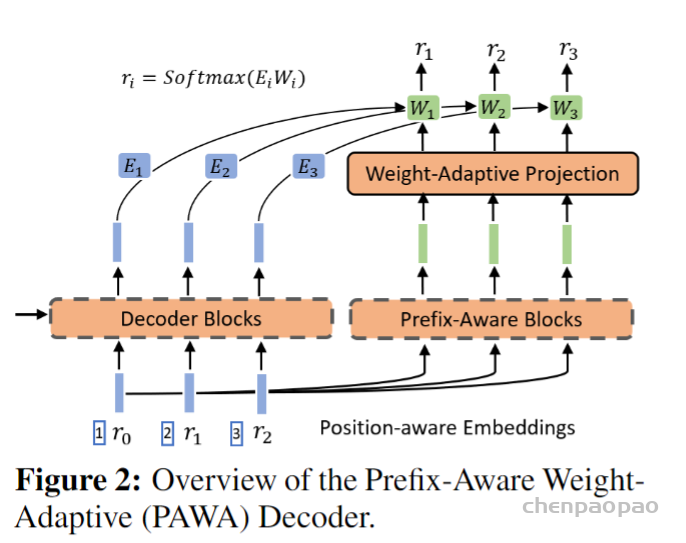
因此新的Wi如下所示:不仅包含Wi,也包含前面的r0到ri-1的这些信息。

损失函数:
1、增加一个对比学习损失函数,希望同一个query生成的id之间相似度更加接近一些。
2、标准的 cross entropy损失函数
实验
数据集(问答数据集文档来自wiki):

评价指标:
1、Recall@N:表示在获得的N个结果中有没有自己想要的文档
2、MRR: 表示返回结果的排序情况,我们想要的文档在所有结果中的排序情况
结果:


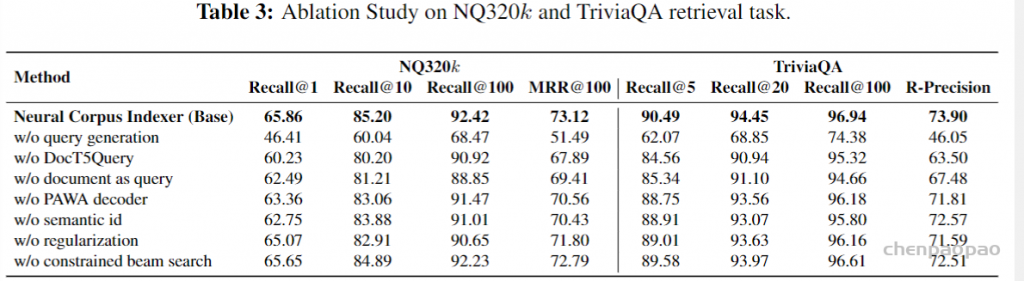
性能:在32G的v100上面,时延在100ms还是可以的,但是吞吐量只有50多个query对于搜索引擎来说是不能忍受的。工业部署上还是有一定的距离。

缺点:1、大数据集:目前只是在32万的文档上训练结果,但要是真的用于web搜索,数以亿计的文档需要的模型会很大。2、推理的时延和吞吐量 3、面对新的文档,如何去更新模型?