
Codex
https://openai.com/blog/openai-codex/
Evaluating Large Language Models Trained on Code
Copilot的核心技术:给定函数名和功能描述,可以自动进行代码补全,或者给定代码,给出相关文档。作者团队收集了Github上所有的不重复的python代码,总计179GB,并进行了简单过滤(去掉了过大的文件(>1MB)和过长的代码(>100行或单行超过1000个字符)),在数据集上面训练了一个GPT3模型。
作者团队手动编写了164个函数(避免数据泄漏),每个函数包括代码、文档以及单元测试,平均每个问题包括7.7个测试样例,用于评估模型。Codex 12亿参数的模型能解决28.8%的问题,3亿参数的模型能解决13.2%的问题,作者团队又收集了一个跟测试集差不多的数据集用于模型微调,微调以后,得到Codex-S可以解决37.7%的问题。而使用 repeated sampling,即运行一百次模型,只要有一个输出解决了问题就算成功的话,那么Codex-S能解决77.5%的问题(CodeX能解决70.2%),而如果选择100个输出中概率最高的输出,则能解决44.5%的问题。
细节
1. 目标函数没有使用BLEU(困惑度),因为代码不同于自然语言,即使特别相似,但仍然可能不是一个合法的语句,作者使用:
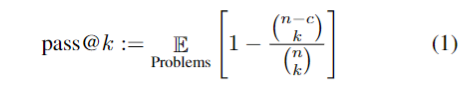
来评估模型,即生成n个输出(n>k),从中随机抽取k个输出,这k个输出只要有一个能通过单元测试的概率.
代码近似计算pass@k(为什么要近似:如果k,n很大,计算很复杂)

2. 输出代码的测试在沙盒中进行(生成的代码可能是恶意的,会让你的机器出现问题)
3. 在GPT3原有模型上微调并不能取得更好的效果,但会加速收敛
4、代码里面的空格如果不做处理会带来很多不必要的词进去,对空格做特殊处理后会减少30%的词
5. 当模型输出‘\nclass’, ‘\ndef’, ‘\n#’, ‘\nif’, or‘\nprint’等语句时,模型会终止推理,输出结果
6. 使用nucleus sampling(核采样):选择概率总和p=95%的前k个输出用于评估模型
7. 对输出做softmax得到概率之前,会除以一个超参数Temperature,来调节不同输出之间的概率差距,当pass@k中的采样数k越大时,T越大效果越好
8. 收集了跟测试集类似的数据集用于微调,1)从各种比赛中收集赛题(大约一万个),2)从Continuous Integration中收集了约40000个函数和单元测试,并过滤(CodeX对每个问题生成一百个输出,如果能解决通过测试用例则保留该样本,反之则去掉(不能通过表示该问题太难或测试用例有问题)),在这个数据集上继续训练,训练方式相同,只是该数据集有“标准答案”,得到模型Code-S
9. 使用收集到的github数据集,重新训练一个GPT3模型用于反向生成文档,Codex-D,评测Codex-D模型好坏的方式是,一是人阅读文档评测模型好坏,二是使用生成的文档重新生成代码,看能否通过单元测试
模型局限性
1. 样本有效性不够,需要训练很多的代码,模型才能输出比较简单的实验
2. Prompt应该怎么写才能获得比较理想的代码,作者找了13 basic building block(对字符串做一些简单的操作:如改变大小写、变换位置等),将文档块任意串起来,发现文档越长,生成代码的质量越差,说明docstring不宜过长
3. 对于精确、复杂的数学问题很难生成正确的代码
模型潜在的影响
1. 过度依赖:人可能会过度依赖生成的代码,如果使用者不仔细审查代码,可能会给程序带来潜在的问题
2. Misalignment:模型足够复杂的时候,可能能输出期望的代码,但如果给定一个docstring,可能只能输出一个跟训练数据风格相似,看上去正确,但并不是期望的代码
3. github男性用户居多,所写的代码可能包含性别偏见
4. 市场和经济:很多程序员可能会失业?如果训练数据里的代码对于某些包使用较多,可能导致某些特别的工具使用率增多。
5. 安全:可能某些人用它写病毒和恶意软件
6. 训练这样一个模型需要使用很多资源
7. 法律:使用的是公开代码,fair use(对公共社会有好处的话并没有什么问题),但用于商业行为可能会有法律风险,生成的代码可能跟别人一模一样,可能存在抄袭别人具有版权或者专利保护的代码的风险。
总结
作者爬了很多github的代码,训练了一个GPT3的模型,为了评估模型的效果,准备了146到题用于测试,发现大概能解决大概30%的题,效果还不错,为了进一步提高分数,又收集了一个跟测试集相似的数据集,在上面微调。
GitHub Copilot

Copilot 相比论文codex中的区别:模型都是采用GPT3,但是 Copilot 使用的数据集不仅仅是python,还有其他语言的代码作为数据集。 GitHub 上公开可用存储库的数十亿行代码的训练 。
Copilot 作为一个辅助编程工具,GitHub Copilot 可以通过提供自动完成样式的建议来帮助你编写代码。GitHub Copilot 是一个 AI 配对程序员,可在编写代码时提供自动完成样式的建议。 可以从 GitHub Copilot 接收建议,方法是开始编写要使用的代码,或者编写描述代码要执行的操作的自然语言注释。 GitHub Copilot 会分析你正在编辑的文件以及相关文件中的上下文,并在文本编辑器中提供建议。 GitHub Copilot 由 OpenAI Codex 提供支持,OpenAI Codex 是一个由 OpenAI 创建的新 AI 系统。
不仅是关键字的自动补全,语法建议,调试建议等。而是帮助开发者更快速的完成业务代码编写。简而言之,GitHub Copilot 是一种 AI 工具,可根据命名或者正在编辑的代码上下文为开发者提供代码建议。
根据官方介绍,Copilot 已经接受了来自 GitHub 上公开可用存储库的数十亿行代码的训练,它支持大多数编程语言,但官方建议使用 Python、JavaScript、TypeScript、Ruby 和 Go。Copilot 是 GitHub 和OpenAI合作的结果, OpenAI得到了微软的大力支持。它由一个名为 Codex 的全新 AI 系统提供支持,该系统基于 GPT-3 模型。
后续工作:
DeepMind AlphaCode
DeepMind推出了自动写算法竞赛题的AI AlphaCode,宣称目前在Codeforces比赛中能排到中位数。Transformer + 超大数据集来做code generation。虽然现在也有很多工作用transformer做代码预训练,或者做代码翻译或者生成。但是从这么长的题面去生成竞赛的代码确实是头一次。
AlphaCode 参加的是一个名为 Codeforces 的在线编程平台。虽然我并不熟悉 Codeforces,但曾经为了准备面试刷过 LeetCode。如果说 LeetCode 就是为了程序员进互联网大厂刷题而生,主要考察程序员的算法和数据结构的能力的话,那 Codeforces 是一个竞赛版的 LeetCode,Codeforces 上的题目更像 ACM ICPC 或者信息学奥林匹克竞赛。
Codeforces 上的题目五花八门,但是都需要参赛者编程求解。每个题目有描述,有输入样例,有正确的输出样例,即test cases。如果提交的程序能够将所有test cases都跑出正确的结果,那么就算该题通过。一道题只有10次试错机会。

Training:模型训练
AlphaCode 使用的经典的预训练+微调(Pretraining + Fine-tuning)范式。
预训练使用的是从 GitHub 爬下来的开源代码,经过了精细的预处理和清洗,大约有715GB。看到这个规模的训练数据,就知道只有屈指可数的几家巨无霸公司能够做这个预训练,实在是太大了,估计需要成千上万块GPU。预训练部分单纯就是让模型学习不同编程语言的套路,或者说学习编程语言中的语义和语法。
微调部分使用的是 CodeContests 数据集,这个数据集收集了很多类似 Codeforces 这样的编程平台上的编程题目、元数据以及人类正确和错误的代码提交结果。目的是针对 Codeforces 这样的编程竞赛,让模型学会如何生成对应的代码。这个数据集大约2GB。
AlphaCode 主要使用了编码器-解码器(Encoder-Decoder)的 seq2seq 方式建模。seq2seq 最经典的应用是机器翻译。给定源文本内容,Encoder 将自然语言编码为一些向量,Decoder 根据向量将自然语言解码为目标文本。那么对于AI自动写代码这个问题,就是输入编程题目,让模型生成目标代码。
Sampling & Evaluation:海量试错

上图为 AlphaCode 的架构,左侧(Data)为模型和数据部分,主要使用 Transformer 进行预训练和微调,右侧(Samping & Evaluation)是如何生成代码并参与 Codeforces 比赛。
AlphaCode 使用了经典的 Transformer 模型。有关 Transformer 的介绍,网络上已经有不少,我自己之前也写过一些 Transformer 和 BERT 的入门文章。关注深度学习的朋友都知道,Transfomer 作为当前大红大紫的AI模型,虽然在各个榜单上刷榜,但它并不具有人类基本的推理能力。
相比Transformer,我认为使得 AlphaCode 成功的主要在于这个 Sampling & Evaluation。这个 Sampling & Evaluation 系统有点类似搜索引擎或者推荐引擎。AI拥有存储和制作海量内容的能力,但无法知道人类真正需要什么。最关键的就是如何从海量内容中进行筛选。搜索或推荐引擎一般会对海量内容进行检索,最终呈现给用户的只有几条内容。海量的内容需要经过几大步骤:召回、粗排、精排、重排。其实就是先从海量的内容库中,先粗略筛选出一万篇的内容,再使用更精细的模型对一万篇进行一次次筛选,最终选择出与用户需求最相关的几篇内容。
AlphaCode 使用了一个 Transformer 模型,根据编程题目描述,生成百万份代码,这些生成的代码中99%可能根本跑不通。AlphaCode 使用编程题目中的test cases,验证这些生成的代码,这个过程会过滤掉99%的错误代码。
经过过滤之后,仍然可能有上千份代码能跑通,而且这些能跑通题目给出的测试样例的代码中很多非常相似。一个编程题目只有10次提交机会,每一次提交的机会都非常珍贵。不可能将上千份代码都提交上去。AlphaCode 这时候做了一个聚类(Clustering)。首先:AlphaCode 使用了第二个 Transformer 模型,根据编程题目中的文字描述,自动生成一些test cases。但是生成的test cases并不保证准确性,它是为了接下来的聚类用的。然后:将生成的test cases喂给那些代码,如果一些代码的生成结果近乎一样,说明这些代码背后的算法或逻辑相似,可被归为一类。文章称,经过聚类之后,从数目较大的类中选出代码去提交,更有胜算。
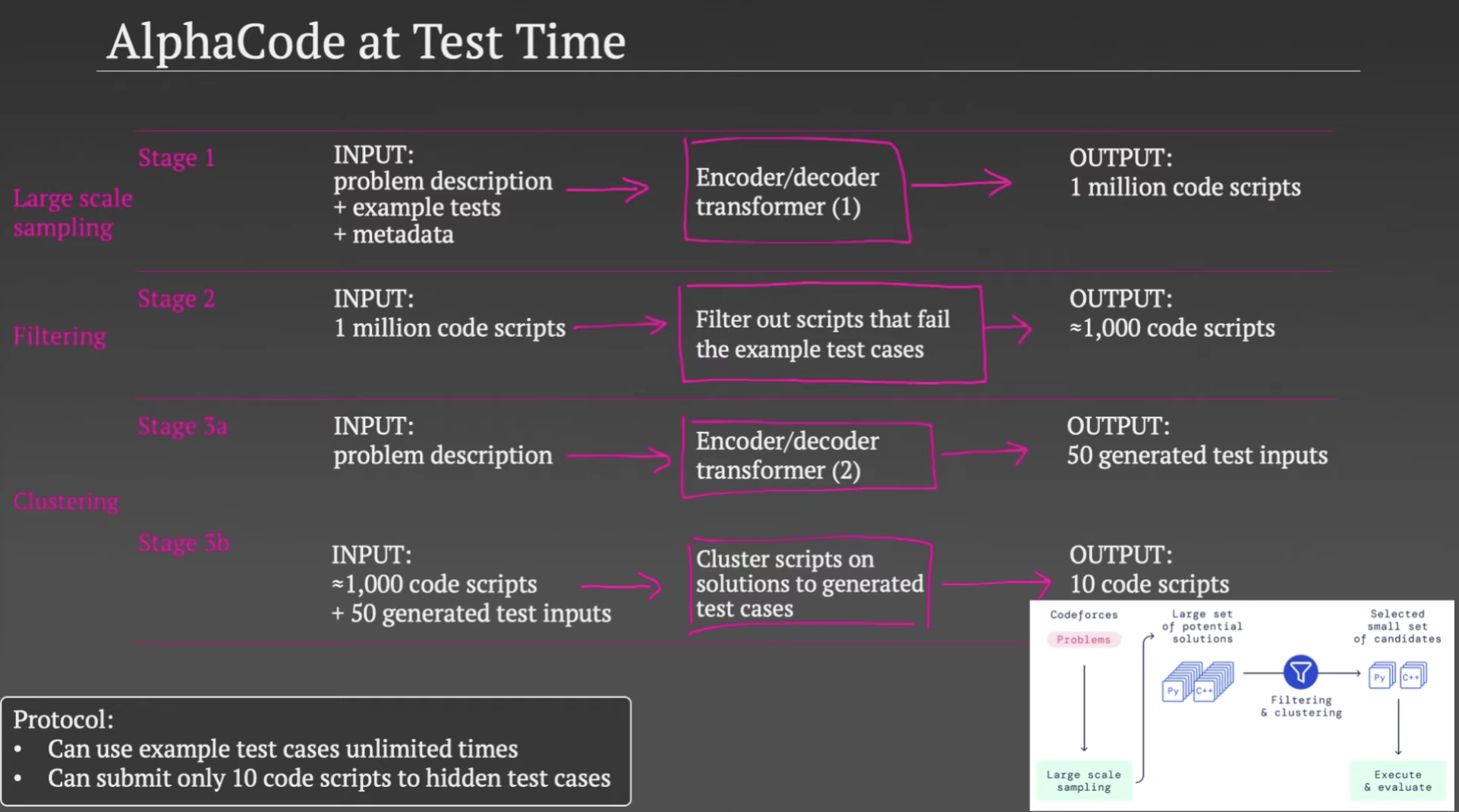
上图演示了这个过程,大致包括四步:
- 根据编程题目中的描述等信息,使用第一个Transformer模型,生成百万份代码。
- 使用编程题目中的测试样例test cases验证这百万份代码,把不能通过的过滤掉,剩下大约上千份代码。
- 使用第二个Transformer模型,生成一些test cases。
- 使用第3步生成的test cases,对第2步留下的代码进行验证并聚类,如果两份代码得到的结果相同,则分到同一类。经过聚类后,最终留下10类代码。
Capabilities & Limitations:能力和限制
深度学习是黑盒模型,我们不知道到底模型学到了什么,能否像人类一样认知和推理。论文花了很大精力和篇幅讨论了 AlphaCode 的能力和限制。
作者们提出了一个论点,即 AlphaCode 并不是单纯从训练数据中寻找相似解法,或者说 AlphaCode 并不是单纯从训练数据中拷贝代码。作者的验证方法是对比了生成的代码和训练集中的代码中的代码片段重合的情况,或者说检验 AlphaCode 是不是单纯从训练集里找一些核心代码片段并直接拷贝过来。因此,作者们认为,AlphaCode 具有解决新问题的能力,而不是照猫画虎地把训练数据拷贝搬运过来。知乎上有信息学竞赛选手感慨,有些题目对于人类专业选手来说都很难快速想出解法,但 AlphaCode 却能够得到答案。
作者们发现,模型生成的代码非常依赖编程题目中的描述。比如,同样一个解法,题目描述越冗长,AlphaCode 的求解准确度越低。但是对编程题目的一些其他改变对求解影响不大,比如更改变量名、同义词替换等。
总结
作者认为,AlphaCode 能够击败半数人类选手,主要原因在于:
- 训练数据足够大且质量高。
- Transformer 预训练模型能够将训练数据中涵盖的知识编码到模型中。
- Sampling & Evaluation 的海量试错机制,先生成海量可能的答案,再一步步缩小搜索空间。
阅读完论文和一些解读之后,我感觉至少短期内,离AI替代程序员应该还有一段距离。但是,未来,可真不好说…

微软亚洲研究院的CodeXGLEU,是近几年对代码智能任务整理最全的一个benchmark.