
当我们千辛万苦完成了前面的数据获取、数据清洗、模型训练、模型评估等等步骤之后,终于等到“上线”啦。想到辛苦训练出来的模型要被调用还有点小激动呢,可是真当下手的时候就有点懵了:模型要怎么部署?部署在哪里?有什么限制或要求?
模型训练重点关注的是如何通过训练策略来得到一个性能更好的模型,其过程似乎包含着各种“玄学”,被戏称为“炼丹”。整个流程包含从训练样本的获取(包括数据采集与标注),模型结构的确定,损失函数和评价指标的确定,到模型参数的训练,这部分更多是业务方去承接相关工作。一旦“炼丹”完成(即训练得到了一个指标不错的模型),如何将这颗“丹药”赋能到实际业务中,充分发挥其能力,这就是部署方需要承接的工作。
目前来说,我还没有真正的接触工业界的模型应用,仅仅只是在学术界进行模型训练和探索。部署只是简单的将模型推理代码直接部署在服务器上,因此也没有考虑过模型在工业界的部署,对于工业应用来说,模型的表现和推理速度同等重要,因此,如何提高模型的推理速度成为模型能否落地的关键因素。
部署流程大致分为以下几个步骤:模型转换、模型量化压缩、模型打包封装 SDK。这里我们主要探讨模型转换。
模型转换主要用于模型在不同框架之间的流转,常用于训练和推理场景的连接。目前主流的框架都以 ONNX 或者 caffe 为模型的交换格式,另外,根据需要,还可以在中间插入计算图优化,对计算机进行推理加速(诸如常见的 CONV/BN 的算子融合)。
模型部署
在软件工程中,部署指把开发完毕的软件投入使用的过程,包括环境配置、软件安装等步骤。类似地,对于深度学习模型来说,模型部署指让训练好的模型在特定环境中运行的过程。相比于软件部署,模型部署会面临更多的难题:
1)运行模型所需的环境难以配置。深度学习模型通常是由一些框架编写,比如 PyTorch、TensorFlow。由于框架规模、依赖环境的限制,这些框架不适合在手机、开发板等生产环境中安装。
2)深度学习模型的结构通常比较庞大,需要大量的算力才能满足实时运行的需求。模型的运行效率需要优化。
因为这些难题的存在,模型部署不能靠简单的环境配置与安装完成。经过工业界和学术界数年的探索,模型部署有了一条流行的流水线:
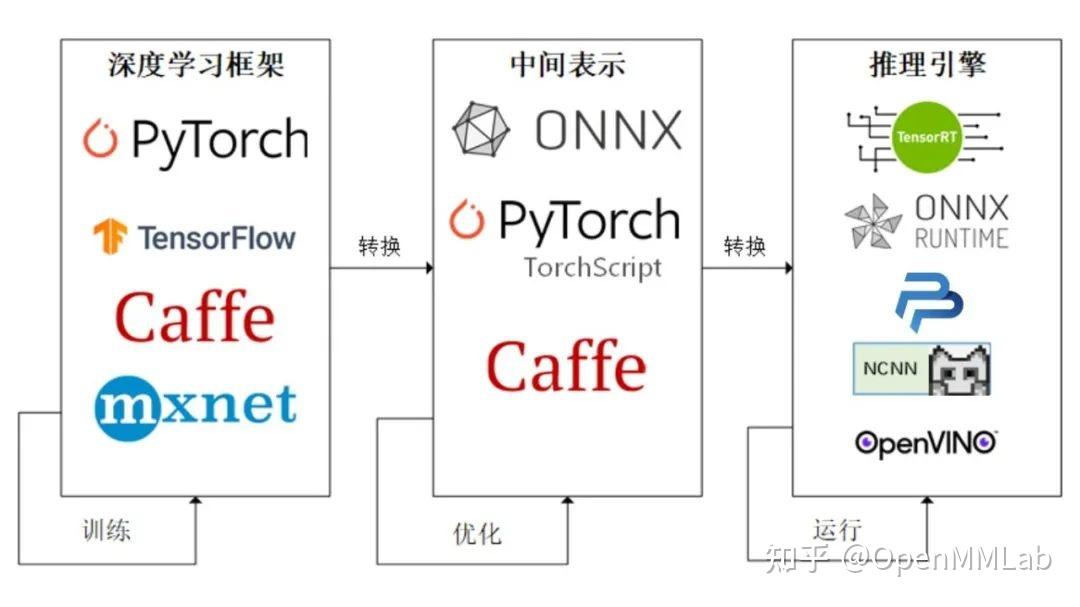
为了让模型最终能够部署到某一环境上,开发者们可以使用任意一种深度学习框架来定义网络结构,并通过训练确定网络中的参数。之后,模型的结构和参数会被转换成一种只描述网络结构的中间表示,一些针对网络结构的优化会在中间表示上进行。最后,用面向硬件的高性能编程框架(如 CUDA,OpenCL)编写,能高效执行深度学习网络中算子的推理引擎会把中间表示转换成特定的文件格式,并在对应硬件平台上高效运行模型。
这一条流水线解决了模型部署中的两大问题:使用对接深度学习框架和推理引擎的中间表示,开发者不必担心如何在新环境中运行各个复杂的框架;通过中间表示的网络结构优化和推理引擎对运算的底层优化,模型的运算效率大幅提升。