
主页:https://www.albertpumarola.com/research/D-NeRF/index.html
https://github.com/albertpumarola/D-NeRF
D-NeRF: Neural Radiance Fields for Dynamic Scenes https://arxiv.org/abs/2011.13961
Abstract
NeRF只能重建静态场景,本文提出的方法可以把神经辐射场扩展到动态领域,可以在单相机围绕场景旋转一周的情况下重建物体的刚性和非刚性运动。由此把时间作为附加维度加到输入中,同时把学习过程分为两个阶段:第一个把场景编码到基准空间,另一个在特定时间把这种基准表达形式map到变形场景中。两个map都用fcn学习,训练完后可以通过控制相机视角和时间变量达到物体运动的效果。
Introduction

和已有的4d方式不同点有:
- 只需单相机
- 无需预先算好一个三维重建
- 可以端到端
想做的就是在原始nerf五维输入上加个时间t,完成
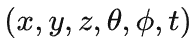
到density和radiance的输出。不过如果直接加,时间冗余没有很好的利用,效果并不好。所以分两个模块:

而且可以产生完整三维mesh,捕捉时变几何。
Pipeline

Formulation

Method
Canonical network(规范网络)
希望找到一种场景的表示能把所有图的相关点的信息都汇聚起来。网络 Ψx 用来编码基准空间中的密度和颜色,给一个坐标x,通过fcn输出256维向量再和d concatenate起来输出density和color
Deformation network(变形网络)
Ψt 训练用来估计某一具体时刻的场景和基准空间中场景的变形场(deformation field),给一个坐标x,输出是这个点和基准空间中的这个点的位移。并且把基准空间场景设为t=0
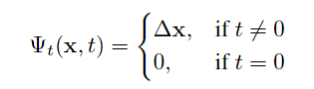
也用了位置编码,x十维,d,t都是四维
Volume rendering
带时间的渲染公式为:

p(ℎ,t) 表示canonical space中由x(h)变换来的点所以其实渲染的时候还是在canonical space里边进行渲染的离散化形式。

Experiment
可以出mesh,depth:

还可以合成阴影:
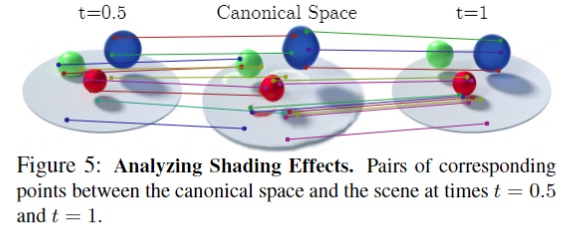
相比其他方法:

