
AvatarCLIP:仅用自然语言驱动实现制作3D avatar动画
1. 论文和代码地址

论文地址:https://arxiv.org/abs/2205.08535
代码地址:https://github.com/hongfz16/AvatarCLIP
2. 动机
3D avatar生成在数字时代有至关重要的作用,一般而言,创建一个3Davatar需要创建一个人物形象、绘制纹理、建立骨架并使用捕捉到的动作对其进行驱动。无论哪一个步骤都需要专业人才、大量时间和昂贵的设备,为了让这项技术面向大众,本文提出了AvatarCLIP,一个zero-shot文本驱动的3Davatar生成和动画化的框架。与专业的制作软件不同,这个模型不需要专业知识,仅仅通过自然语言就可以生成想要的avatar。本文主要是利用了大规模的视觉语言预训练模型CLIP来监督人体的生成,包括几何形状、纹理和动画。使用shapeVAE来初始化人类几何形状,进一步进行体渲染,接着进行几何雕刻和纹理生成,利用motionVAE得到运动先验来生成三维动画
3. 方法
3.1模型概述
下图展示了AvatarCLIP的框架,模型分为两个部分,上面的部分是生成静态的avatar,下面的部分是生成动作。
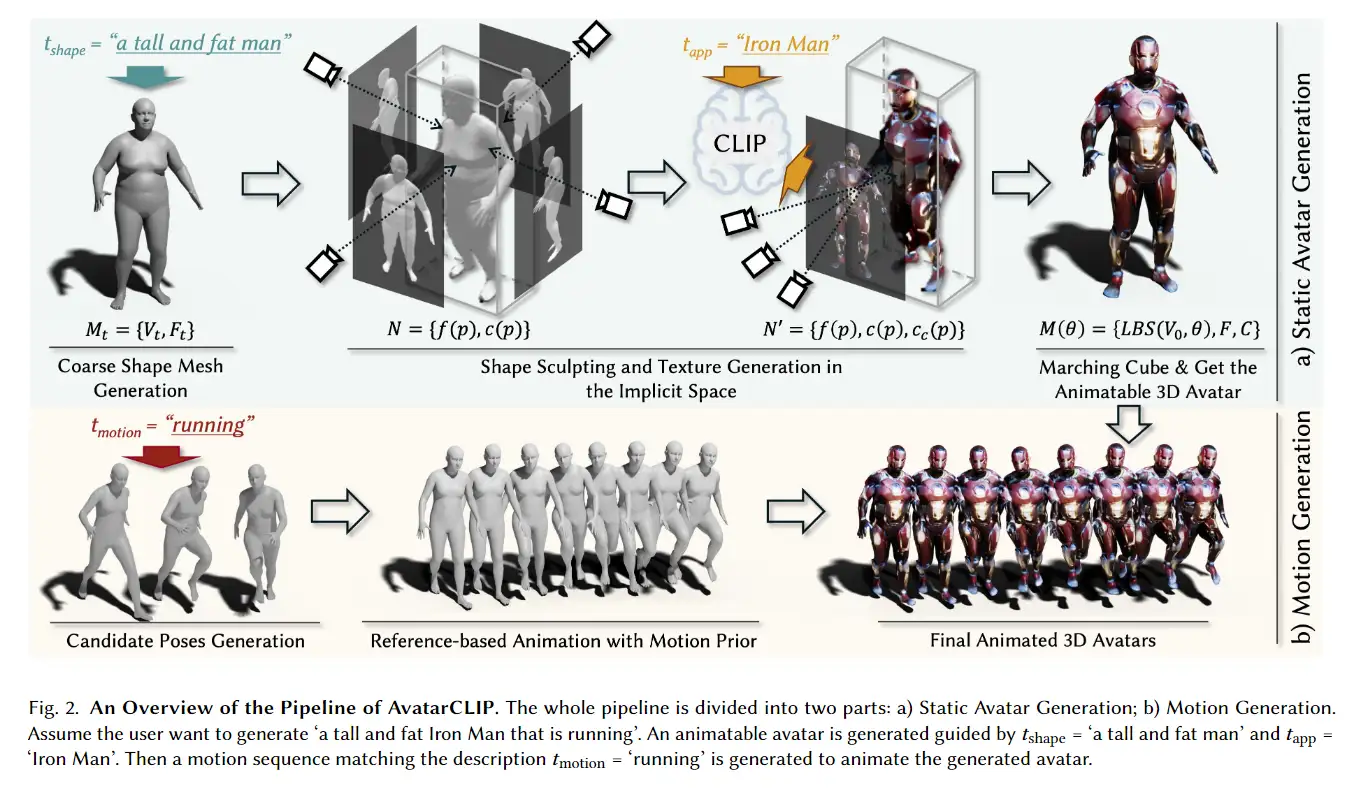
模型的输入是自然语言描述,body描述、外观描述和动作描述,模型的输出包括一个动画的3Davatar,以及一系列想要的poses。
静态avatar生成分为四步,首先根据SMPL的模板和语言提示初始化Mesh,接下来用NeuS提取mesh的隐式表示,然后使用隐式表示来构建形状和生成纹理,最后进行动画化。motion生成首先生成备选姿势,然后基于备选姿势生成动作序列。最后将动作做序列融入到动画中。
3.2静态avatar生成
3.2.1coarse shape mesh 生成
作为生成虚拟形象的第一步,生成一个粗糙的模板mesh。SMPL 被用作可能的人体形状的来源。如图 3 所示,首先通过对身体形状进行聚类来构建code-book。然后使用CLIP提取code-book和文本中身体形状渲染的特征,以获得最佳匹配的身体形状。
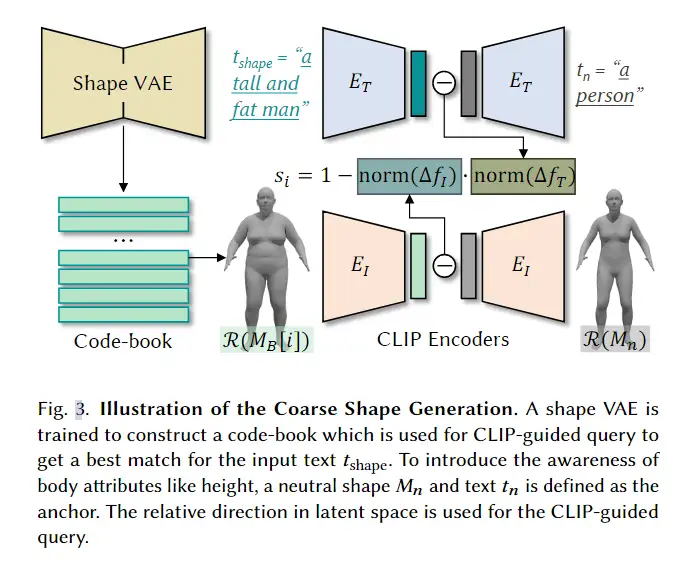
SMPL是通过主成分分析学习的,所以聚类的分布不均衡。通过训练一个shapeVAE,在VAE的隐空间使用K-Means聚类,来实现分类均匀的目的。对于CLIP引导的code-book查询,定义了一个中性状态的身体形状 以及相应的中性状态文本 作为参考。每个条目的得分 在code-book中定义为
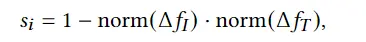
最终选择si最大的mesh 作为输出。
3.2.2隐式表达
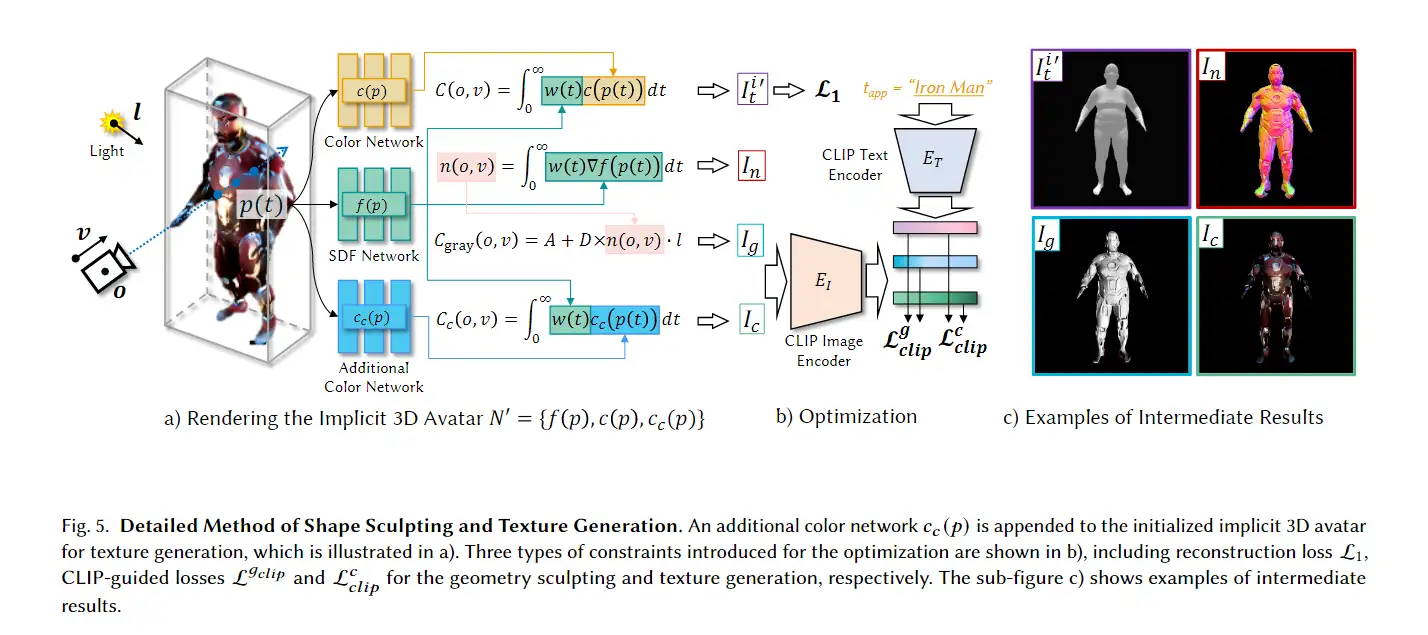
为了生成高质量的 3D avatar,形状和纹理需要进一步塑造和生成以匹配外观 app 的描述。如前所述,我们选择使用隐式表示,即 Neus,作为此步骤中的基本 3D 表示,因为它在几何和颜色上都具有优势。为了加速优化和控制形状生成,更方便生成动画,所以需要先将生成的粗糙mesh shape转化为隐式表示。
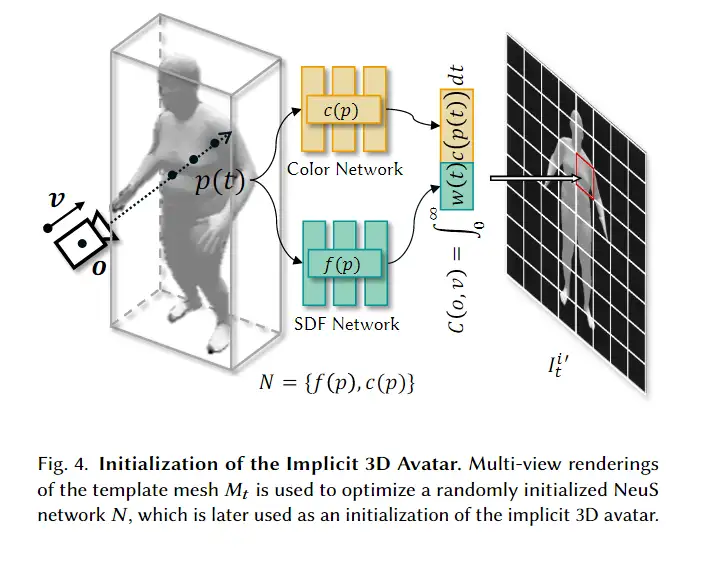
通过使用模板mesh 的多视图渲染{ }优化随机初始化的NeuS 来创建 的等效隐式表示。具体来说,如图4所示,NeuS = { ( ), ( )} 由两个子网组成。SDF网络 ( )以一定点 作为输入,输出与其最近的表面有符号距离。颜色网络 ( )以点 为输入,输出颜色。 ( ) 和 ( ) 都是使用 MLP 实现的。需要注意的是,与NeuS的原始实现相比,这里省略了颜色网络对观看方向的依赖。
视图方向依赖性最初设计用于对视角变化的阴影进行建模。在我们的例子中,对此类阴影效应进行建模是多余的,因为我们的目标是生成具有一致文本的 3D avatar,与原始设计类似, 由三部分损失函数优化:
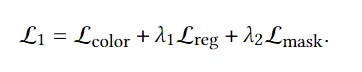
color是渲染图和ground truth之间的重建损失 reg是SDF正则化的损失 mask是仅仅重建前景的损失
3.2.3形状构建+纹理生成
通过CLIP风格化初始的NeuS N,粗糙的形状 仍应保持,所以通过保留了原来的两个子网络 ( ) 和 ( ) 并引入额外的彩色网络 ( ). 两个颜色网络共享同一SDF网络 ( ) 如图5所示。 ( )和 ( ) 负责模板网格的重建 . ( ) 连同 ( ) 负责风格化部分,并且包括目标隐式3D化身。
形式上,新的NeuS模型 ′ = { ( ), ( ), ( )} 现在由三个子网络组成,其中 ( ) 和 ( ) 由预先培训的 , 和 ( )是随机初始化的颜色网络。
损失函数如下
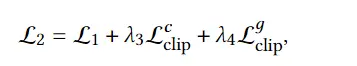
没有纹理的渲染中颜色是不需要的,我们简单的计算一个灰度的光线通过:
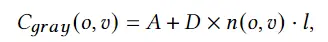
其中A服从一个均匀分布,并随机采样,D= 1-A。通过上面的式子应用到一张图片的每一个像素中,我们可以得到没有纹理渲染的图片。
在实践中,我们发现纹理渲染上的随机着色 有利于生成纹理的均匀性,这将在消融研究中稍后讨论。随机着色打开 类似于无纹理渲染,其正式定义为
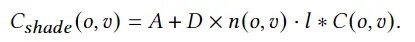
上面两种渲染过程的损失函数就损失函数的后两项,定义为:
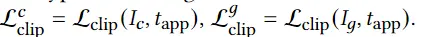
3.2.4 增强过程
为了增强优化过程的鲁棒性,使用了三种增强手段:背景随机增强;随机相机参数采样;文本提示语义增强。
随机背景增强,使得CLIP能更加focus on 需要生成的对象上,本文采用了图六中展示的背景增强的手段。

为了防止网络找到仅为几个固定相机位置提供合理渲染的捷径解决方案,我们以手动定义的重要性采样方式对每个优化迭代的相机外部参数进行随机采样,以获得更连贯和平滑的结果。我们选择使用相机的“注视”模式,该模式由注视点、相机位置和向上方向组成。
向上的方向一般是人体向上的方向,注视点采用随机采样的方法,相机位置使用半径为 从均匀分布U(1,2)采样,极角 从均匀分布U(0,2 ), 方位角 从高斯分布N(0, /3)采样,使得相机在大多数迭代中指向化身的前方。
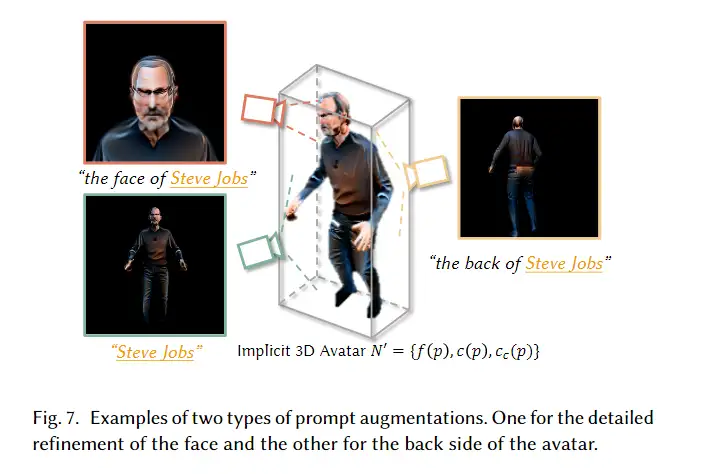
到目前为止,在整个优化过程中没有引入人类先验,这可能会导致在错误的身体部位生成纹理或不为重要的身体部位创建纹理,这将在稍后的消融研究中显示。为了防止此类问题,我们建议通过以语义感知的方式增强提示,在优化过程中明确引入人类先验。例如,如图7所示,如果 app=“乔布斯”,我们将增加 应用到两个附加提示 face=“史蒂夫·乔布斯的脸”和 back=“史蒂夫·乔布斯的背影”。对于每四次迭代,相机的注视点被设置为面部的中心,以获得面部的渲染,这将由提示进行监督 面对“面部增强”直接监督面部的生成,这对生成的化身的质量很重要,因为人类对面部更敏感。对于第二增强提示, back被用作相应的文本,以明确地指导化身背部的生成。
3.2.5动画生成
首先,中每个顶点的最近邻居 在模板网格的顶点中检索 . 混合中每个顶点的权重 从中最近的顶点复制 . 其次,使用反向LBS算法来带来avatar的站立姿势 站回零姿势 0。顶点 被转换为 0 . 最后 0可以由任何姿势驱动 使用LBS算法。因此,对于任何姿势,动画avatar都可以正式定义为:
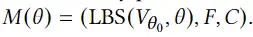
LBS算法是线性混合蒙皮,用户在几何模型给上选择一系列控制单元,并计算几何模型受这些控制单元的影响权重,用户拖动控制单元,几何模型随着控制单元发生对应的变化。
3.3motion 生成
根据经验,CLIP不能直接估计运动序列和自然语言描述之间的相似性。它也缺乏评估运动序列的平滑性或合理性的能力。这两个限制表明,仅使用CLIP监督很难生成运动。因此,必须引入其他模块来提供运动先验。然而,CLIP能够评估渲染的人体姿势和描述之间的相似性。此外,类似的姿势可以被视为预期运动的参考。基于以上观察,我们提出了一个两阶段运动生成过程:1)由CLIP引导的候选姿态生成。2) 使用具有候选姿势作为参考的运动先验来生成运动序列。
3.3.1生成candidate pose
我们首先从AMASS数据集创建code-book。为了减少维度,VPoser用于将姿势编码为 ∈ R ,然乎使用K-Means聚类来建立code-book Bz,每一个Bz然后通过解码器解码为一些列的姿势 。
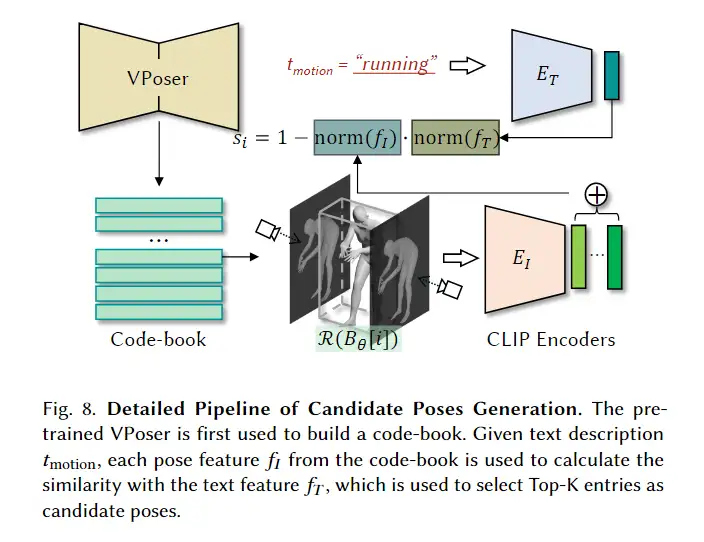
给定的文本描述 运动,每个姿势特征 从代码本中计算与文本特征的相似度 , 其用于选择Top-K条目作为候选姿势。
3.3.2motion VAE
本文提出了一种双重方法来生成与运动描述匹配的目标运动序列 运动
1) motionVAE被训练以捕获人类运动先验。
2) 我们使用候选姿态优化motion VAE的潜在代码 作为参考。
motion VAE包含encoder、decoder和重参数模块。
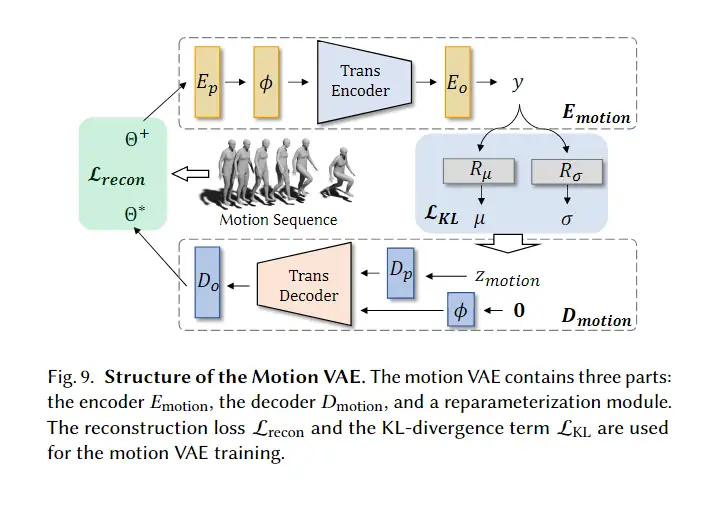
encoder模块包括projection layer、positional embedding layer 、几个transformer encoder块和output layer。输出等于
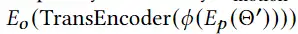
重参数模块生成一个高斯分布,两个全连接层分别计算均值和方差
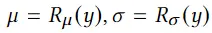
随机潜在编码z从得到的高斯分布中采样,潜在编码通过decoder解码得到motion序列
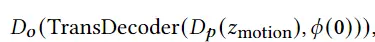
训练motion VAE过程中的损失函数定义为:
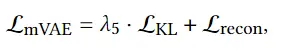
3.3.3生成运动序列
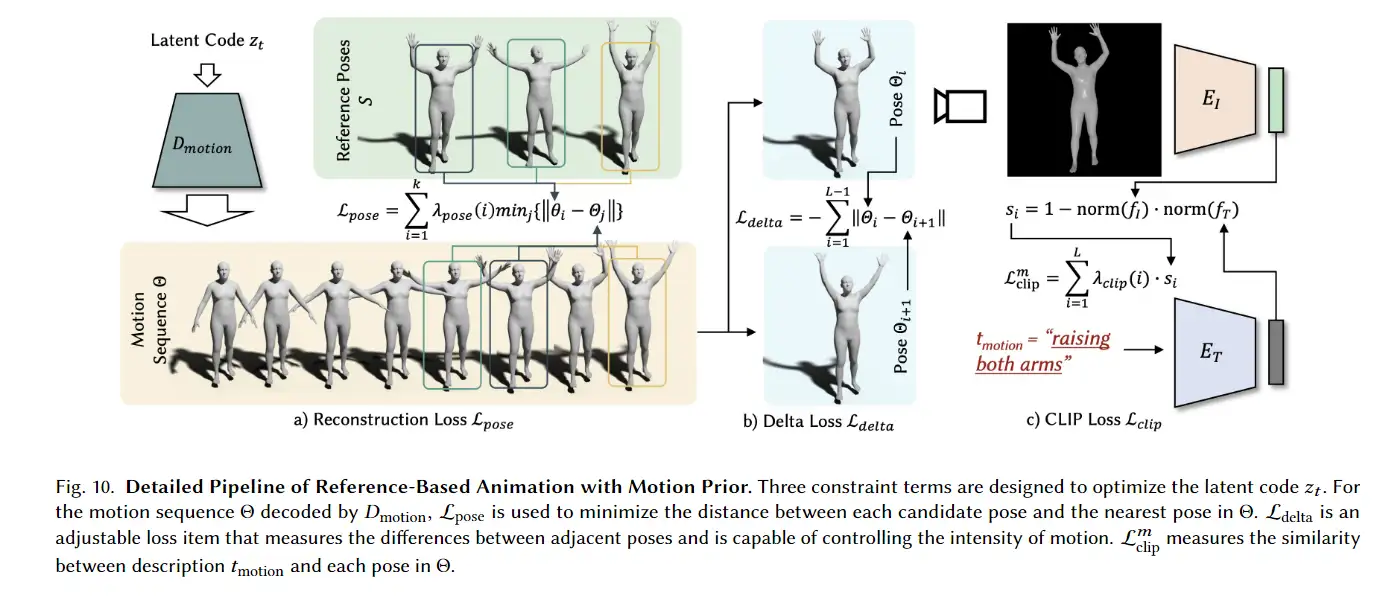
使用预训练的motion VAE,我们尝试优化其潜在代码 以合成运动序列 Θ = motion ( )。提出了三个优化约束:
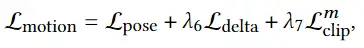
Lpose 是解码后的动作序列 Θ 和候选姿势 之间的重构项。给定参考带来 = { 1, 2,., },目标是构建一个与这些姿势足够接近的动作序列。我们建议最小化 与其最近的帧Θ 之间的距离,其中 ∈ {1, 2,., } 和 ∈ {1, 2,., }。形式上,重建损失定义为
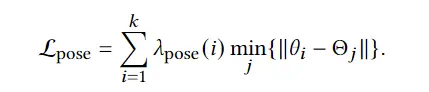
根据经验,仅使用重建损失 Lpose,生成的运动往往是过度平滑的。Ldelta 测量运动的范围,以防止运动过于平滑。作为对过度平滑运动的惩罚项。在增加 λ6 时会产生更强烈的运动。
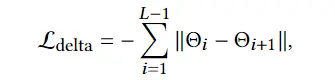
L clips 鼓励运动中的每个单一姿势匹配输入运动描述。缺乏对姿势排序的监督将导致不稳定的生成结果。此外,候选姿势可能只对最终运动序列的一小部分有贡献,这将导致意外的运动片段。为了解决这两个问题,我们设计了一个附加的CLIP引导损失项:
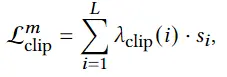
是姿势Θ和文本描述之间的相似度得分。 clip ( ) = 是一个单调递增的函数,因此 L clip 对序列中的后面姿势给予更高的惩罚。通过上述 CLIP 引导的术语,整个运动序列将与运动更加一致。
4.实验
4.1总体结果

上图展示了具有多种身体形状,外观多样,质量高。它们由生成的与输入描述合理且一致的运动序列驱动。在zero-shot style中,AvatarClip 能够生成avatar和动作并且动画化,利用预训练模型中的先验信息。最初需要专业软件专家知识的化身生成和动画的整个过程现在可以在我们提出的模型帮助下简单地由自然语言驱动。
4.2Avatar 生成
4.2.1消融实验

1)背景增强的设计
2)低纹理渲染的监督
3)纹理渲染的随机阴影
4)语义感知提示增强。
图12所示的消融设置是通过随后将上述四种设计添加到baseline中形成的。如图12的前两列所示,背景增强对纹理生成有很大影响,如果没有背景增强,纹理会变得非常暗。比较第二列和第三列,添加对无纹理渲染的监督可以大大提高几何体质量。“消融2”的几何结构有很多随机凸起,这会使表面产生噪音。而“消融3”的几何结构是光滑的,并有详细的衣服褶皱。如“消融3”和“消融4”所示,在纹理渲染图上添加随机阴影有助于生成更均匀的纹理。例如,《消融3》中的“唐纳德·特朗普”上身比下身更亮,这在《消融4》中有所改进。如果没有人体语义的意识,前面的四个设置无法为化身生成正确的面部。最后一列使用语义感知提示增强,在面部生成方面具有最佳结果。
4.2.2coarse shape 生成
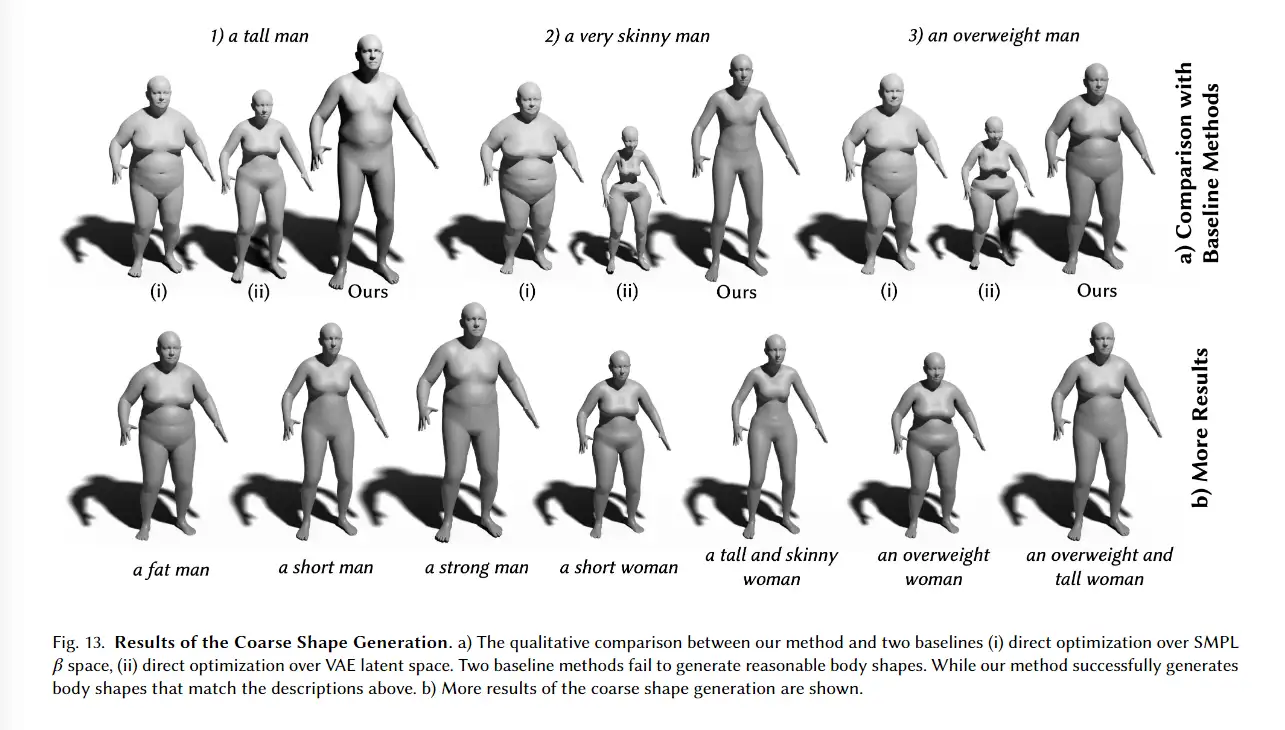
对于这一部分,我们设计了两种直观的基线方法,(i)SMPL上的直接优化 (ii)VAE潜在空间上的直接优化。如图13(a)所示,两种优化方法都无法生成与描述文本一致的身体形状。即使是相反的文本指导(例如“kinny”和“overweight”)也会导致相同的优化方向。相比之下,我们的方法稳健地生成与输入文本一致的合理身体形状。我们方法的更多样的定性结果如图13(b)所示。
4.2.3形状雕刻和纹理生成的定性结果

广泛的驾驶文本。在广泛的实验中,我们的方法能够从广泛的外观描述中生成化身,包括三种类型:1)名人,2)虚构人物和3)描述人的一般词语,如图17所示。如图17(a)所示,给定名人姓名作为外观描述,生成了名人最具标志性的服装。由于我们的语义感知提示增强设计,人脸也能正确生成。对于图17(b)所示的虚构角色生成,可以正确生成大多数文本描述的化身。有趣的是,对于具有复杂几何形状的配件的角色(例如“蝙蝠侠”的头盔、“艾尔莎”的服装),优化过程有从模板人体中“生长”出新结构的趋势。至于一般描述,我们的方法可以处理非常广泛的范围,包括常见的工作名称(例如“教授”、“医生”)、描述某个年龄段的人的词语(例如“青少年”、“老年公民”)和其他幻想职业(如“女巫”、“巫师”)。可以观察到,除了化身本身之外,还可以生成它们各自的标志性对象。例如,“园丁”用手抓花和草。
尽管上面实验和演示了大量的生成结果,但在生成宽松服装和配饰时仍存在失败案例。例如,如图17所示,“艾尔莎”的服装和“奇异博士”的斗篷并没有生成。夸张的头发和胡须(如裹着面包的阿甘)的几何形状也很难正确生成。这是由优化过程中的重建损失引起的。不鼓励“生长”,允许对几何结构进行非常有限的更改。

Zero-Shot Controlling Ability:如图18所示,我们可以通过调整语义感知提示增强来控制化身上生成的人脸,例如,比尔·盖茨穿着钢铁侠套装。此外,我们可以通过直接的文本指导来控制化身的服装,例如“穿着白衬衫的史蒂夫·乔布斯”。

Concept Mixing:如图14所示,我们展示了将奇幻元素与名人混合的示例。在保持可识别身份的同时,奇幻元素与avatar自然融合。

Geometry Quality:低纹理渲染监督的关键设计主要有助于几何生成。我们主要将AvatarCLIP与基于NeRF的改编的Dream Field进行比较。如图19所示,我们的方法在几何质量方面始终优于Dream Fields。可以生成详细的肌肉形状、盔甲曲线和布料褶皱。

除了生成质量,我们还研究了我们算法的鲁棒性与baseline Text2Mesh相比。对于每种方法,我们都使用相同的五个随机种子,对同一提示进行五次独立运行。如图20所示,我们的方法能够以高质量和与输入文本一致的方式输出结果。Text2Mesh在大多数运行中失败,这表明网格的表示对于优化是不稳定的,尤其是在监督薄弱的情况下。
4.3 motion生成
4.3.1消融实验

为了评估我们在基于参考的动画模块中的设计选择的有效性(即提出的三个约束项,运动VAE作为运动先验的使用),我们将我们的方法与两个基线方法进行了比较,如图21所示。
对于“刷牙”,(i)生成无序和不相关的姿势序列。(ii)也未能生成合理的运动,这是由于其盲目地关注于重建无序的候选姿势所导致的。通过引入重新加权机制,我们的方法不仅关注重建,还考虑了生成的运动的合理性。
对于“踢足球”,当腿踢出时,(i)(ii)中的动作序列没有剧烈变化。Ldelta在控制运动强度方面起着重要作用。至于“举起双臂”,它应该生成一个从中立姿势到举起手臂的姿势的运动序列。然而,(i)生成与预期结果相反的运动序列。(ii)引入若干不相关的行动。在Lclipm,我们的方法能够以正确的顺序和更好的描述一致性生成运动。

此外,受应聘者姿势多样性的限制,要想做出更复杂的动作,比如“拥抱”、“弹钢琴”和“运球”,是一件很有挑战性的事情。
4.3.2与baseline对比

将三种baseline方法与我们的方法进行比较。baseline(I)直接对SMPL参数θ进行优化。基线(II)直接在VPoser的潜在空间上进行优化。这两种方法都很难产生合理的姿势。Baseline(III)在VPoster中使用了多通道Real NVP,在正太分布和潜在空间分布中得到双向映射,它可以生成相对合理的姿势,但仍然明显比我们的方法差。
如图22(b)展示了广泛的驱动文本。为了证明姿势生成方法的zero-能力,我们用四类运动描述进行了实验:1)抽象的情绪描述(例如“疲惫”和“悲伤”);2) 常见动作描述(如“行走”和“蹲下”);3) 与身体部位相关的运动描述(例如“举起双臂”、“洗手”)4)涉及与物体交互的运动(例如“投篮”)。
5. 总结
为了外行人也可以实现原来复杂的3D avatar创建的目的,本文提出了AvatarCLIP。本文的模型主要依赖于大规模预训练模型VAE——包括了形状和动作先验,以及大型可泛化的视觉语言预训练模型CLIP。并且通过一系列的实验证明了模型的有效性和效率。
但是在形象创建的过程中,受到CLIP的弱监督和低分辨率的影响,生成的结果在放大之后并不是完美的。此外,在给定相同的prompt的,要产生有较大区别的形象是比较困难的。因为,优化方向是相同的,所以导致了不同的提示产生相同的结果。在动作合成阶段,受code-book设计的限制,很难产生分布外的候选姿态,这限制了产生复杂运动的能力。此外,由于缺乏video CLIP,很难生成风格化的运动。
对于预训练模型的使用,会造成许多道德问题,比如,医生对应的生成是男性, 而护士对应的生成是女性,这会造成性别歧视的问题。为了安全地使用zero-shot技术,需要开展关于大规模预训练模型的伦理问题的未来工作。此外,随着头像和动画制作的普及,用户可以很容易地制作出名人的假视频,这可能会被滥用,造成负面的社会影响。