
1、DreamFusion(谷歌)
项目主页:https://dreamfusion3d.github.io/
paper: https://arxiv.org/abs/2209.14988
code: https://github.com/ashawkey/stable-dreamfusion
该文章解决的是3D重建领域的少视角重建(Sparse-view Reconstruction)问题,结合了扩散模型和NeRF。
摘要
最近扩散模型在上亿级别的文本-图像对数据上训练在文本图像生成上取得巨大的进展,将这种方法应用于3D合成,需要大规模的有标签的3D数据集和高效的架构来去噪3D数据,而这两者目前都不存在。在这项工作中,通过使用预先训练好的二维的文本到图像的扩散模型来绕开这些限制进行文本到3D的合成。本文引入一种基于概率密度蒸馏的损失函数,可以使用2D的扩散模型作为先验用于优化参数化图像生成器。使用这个损失函数就像一个DeepDream-like的过程,(这里的DeepDream是谷歌提出,使用梯度上升的方法可视化网络每一层的特征,即用一张噪声图像输入网络,反向更新的时候不更新网络权重,而是更新初始图像的像素值,以这种训练图像的方式可视化网络)。本文梯度下降优化一个随机初始化的3D模型使得任意随机视角随机渲染的图像都达到较低的损失。生成的模型可以任意修改,不需要三维数据,也不需要修改扩散模型。
本文的方法和DreamFields的方法类似,但是用一个2D扩散模型蒸馏推导而来的损失函数取代CLIP。这个损失函数是通过概率密度蒸馏而来的,就是用KL- divergence最小化前向过程和反向的概率密度,这里的反向过程是是与训练好的2D扩散模型,因为反向过程也是一个估计score的过程,所以我理解这就是他叫 score distillation sampling的原因吧。
该工作基于的3D表示方法也是NeRF中的一种。事实上,基于NeRF的重建方法通常需要针对特定场景的大量的视图,并且对于训练集中出现频率较少的视角,其关于该视角的重建结果也会很差。而对于少视角3D重建,虽然最近已经有很多工作结合了深度网络和渲染公式来完成这样的任务,但是它们要么缺乏3D一致性,要么感知质量比较差。
在3D生成领域,DreamFusion使用文本扩散模型优化3D表示,并且取得了非常好的效果。
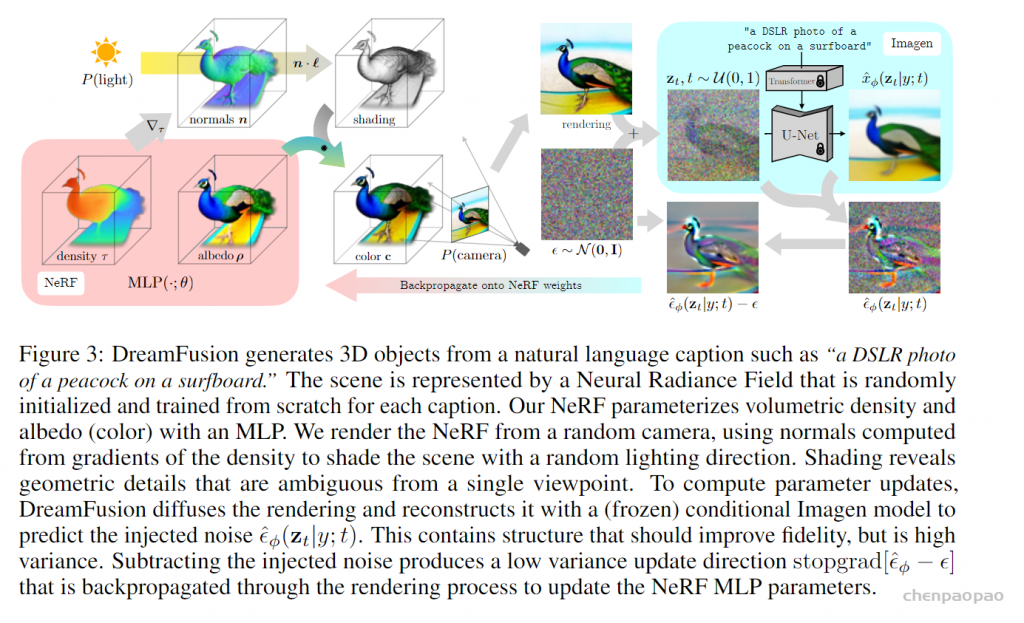
如上图,这是DreamFusion的架构图,右边一部分就是Diffusion Model,这里用的是一个预训练的模型,左边一部分就是NeRF,是一个目标场景的3D表示,虽然画的花里胡哨的,但是其实思路非常直白简单:训练的时候锁住Diffusion的梯度,增加视角guidance,用生成结果来优化和训练NeRF;泛化阶段只需要使用优化后的NeRF就可以了。在这里,Diffsuion的作用是根据文本生成相应视角和内容的图片,NeRF的作用是约束3D一致性。
2、Magic3D(NVIDIA)
高分辨率文本到3D内容创建:
项目主页:https://deepimagination.cc/Magic3D/
论文:https://arxiv.org/abs/2211.10440
人们只需要输入一段文字比如「一只坐在睡莲上的蓝色箭毒蛙」,AI 就能给你生成个纹理造型俱全的 3D 模型出来。Magic3D 还可以执行基于提示的 3D 网格编辑:给定低分辨率 3D 模型和基本提示,可以更改文本从而修改生成的模型内容。此外,作者还展示了保持画风,以及将 2D 图像样式应用于 3D 模型的能力。
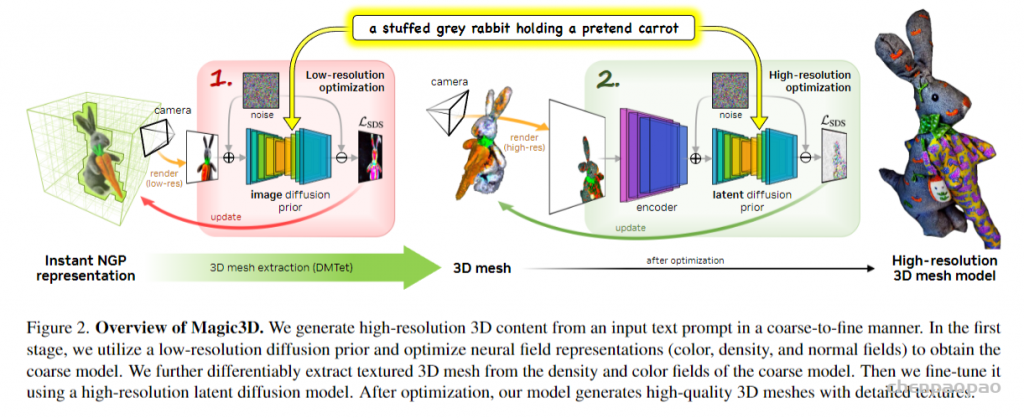
类似于 DreamFusion 用文本生成 2D 图像,再将其优化为体积 NeRF(神经辐射场)数据的流程,Magic3D 使用两阶段生成法,用低分辨率生成的粗略模型再优化到更高的分辨率。
英伟达的方法首先使用低分辨率扩散先验获得粗糙模型,并使用稀疏 3D 哈希网格结构进行加速。用粗略表示作为初始,再进一步优化了带纹理的 3D 网格模型,该模型具有与高分辨率潜在扩散模型交互的高效可微分渲染器。
Magic3D 可以在 40 分钟内创建高质量的 3D 网格模型,比 DreamFusion 快 2 倍(后者平均需要 1.5 小时),同时还实现了更高的分辨率。
Magic3D 可以在较短的计算时间内根据文本 prompt 合成高度详细的 3D 模型。Magic3D 通过改进 DreamFusion 中的几个主要设计选择来使用文本 prompt 合成高质量的 3D 内容。
具体来说,Magic3D 是一种从粗到精的优化方法,其中使用不同分辨率下的多个扩散先验来优化 3D 表征,从而生成视图一致的几何形状以及高分辨率细节。Magic3D 使用监督方法合成 8 倍高分辨率的 3D 内容,速度也比 DreamFusion 快 2 倍。
Magic3D 的整个工作流程分为两个阶段:
- 在第一阶段,该研究优化了类似于 DreamFusion 的粗略神经场表征,以实现具有基于哈希网格(hash grid)的内存和计算的高效场景表征。
- 在第二阶段该方法切换到优化网格表征。这个步骤很关键,它允许该方法在高达 512 × 512 的分辨率下利用扩散先验。由于 3D 网格适用于快速图形渲染,可以实时渲染高分辨率图像,因此该研究利用基于光栅化的高效微分渲染器和相机特写来恢复几何纹理中的高频细节。
3、Point-E(OpenAI)
Point·E,可以依据文本提示直接生成 3D 点云:
项目主页:https://openai.com/research/point-e
Github: https://github.com/openai/point-e
通常意义上,文本到 3D 合成的方法分为两类:
方法 1:直接在成对的 (text, 3D) 数据或无标签的 3D 数据上训练生成模型。
此类方法虽然可以利用现有的生成模型方法,有效地生成样本,但由于缺乏大规模 3D 数据集,因此很难扩展到复杂的文本提示。
方法 2:利用预先训练好的 text-to-image 模型,优化可区分的 3D 表征。
此类方法通常能够处理复杂多样的文本提示,但每个样本的优化过程都代价高昂。此外,由于缺乏强大的 3D prior,此类方法可能会陷入 local minima(无法与有意义或连贯的 3D 目标一一对应)。
Point·E 结合了 text-to-image 模型以及 image-to-3D 模型,综合以上两种方法的优势,进一步提升了 3D 建模的效率,只需要一个 GPU、一两分钟即可完成文本到 3D 点云的转换。
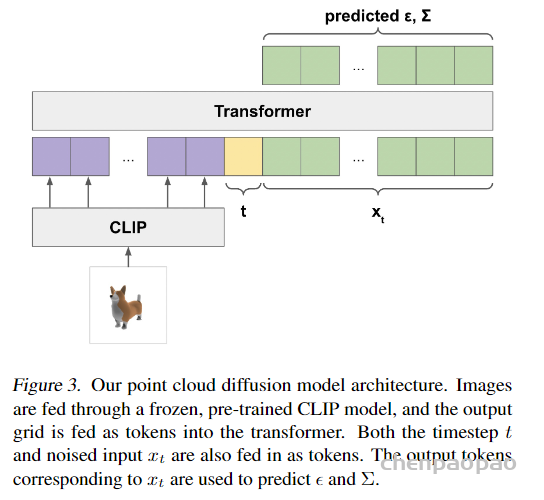
Point·E 中,text-to-image 模型利用了大型语料库 (text, image pair),使其对复杂的文本提示也能处理得当;image-to-3D 模型则是在一个较小的数据集 (image, 3D pair) 上训练的。
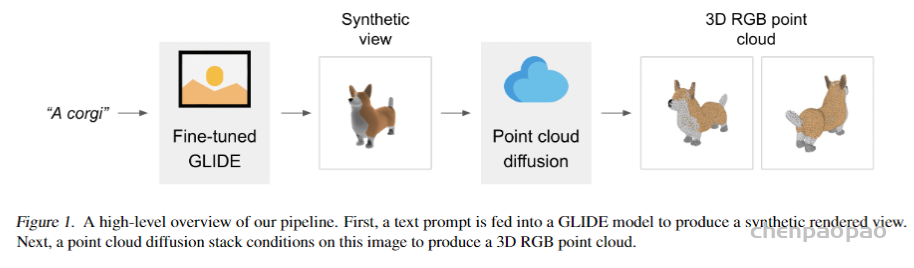
用 Point·E 依据文本提示生成 3D 点云的过程分为三个步骤:
1、依据文本提示,生成一个合成视图 (synthetic view)
2、依据合成视图,生成 coarse point cloud (1024 point)
3、基于低分辨率点云和合成视图,生成 fine point cloud (4096 Point)
由于数据格式和数据质量对训练结果影响巨大,Point·E 借助 Blender,将所有训练数据都转换为了通用格式。
Blender 支持多种 3D 格式,并配有优化的渲染 engine。Blender 脚本将模型统一为一个 bounding cube,配置一个标准的 lighting 设置,最后使用 Blender 内置的实时渲染 engine 导出 RGBAD 图像。
4、Zero-1-to-3: Zero-shot One Image to 3D Object
项目链接:
https://zero123.cs.columbia.edu/
源码:
https://github.com/cvlab-columb
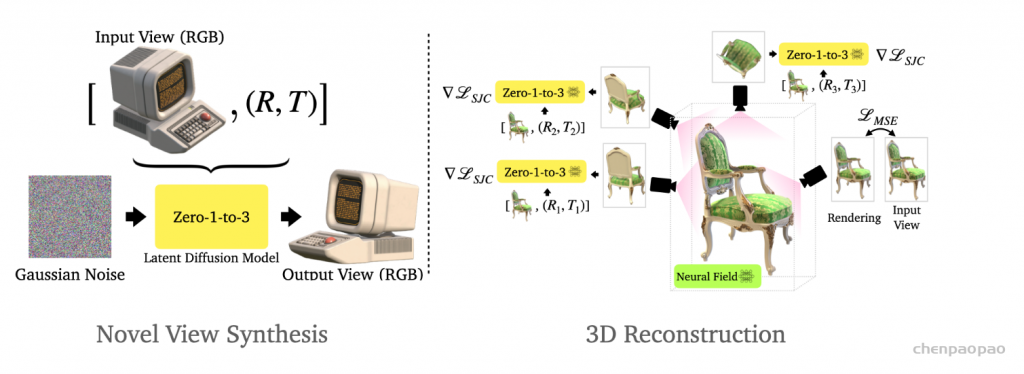
Method
We learn a view-conditioned diffusion model that can subsequently control the viewpoint of an image containing a novel object (left). Such diffusion model can also be used to train a NeRF for 3D reconstruction (right). Please refer to our paper for more details or checkout our code for implementation.
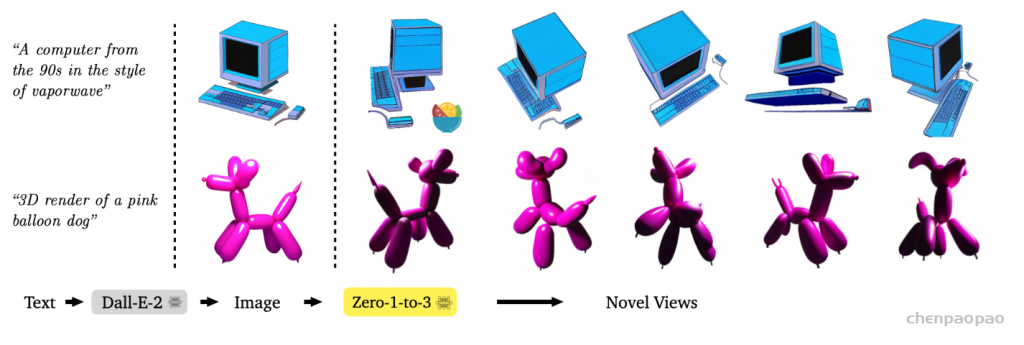
Text to Image to Novel Views
Here are results of applying Zero-1-to-3 to images generated by Dall-E-2.
5、SceneDreamer:从2D图像中学习生成无限3D场景
来自南洋理工大学 S-Lab 的研究者提出了一个新的框架 SceneDreamer,专注于从海量无标注自然图片中学习无界三维场景的生成模型。
- 项目主页:https://scene-dreamer.github.io/
- 代码:https://github.com/FrozenBurning/SceneDreamer
- 论文:https://arxiv.org/abs/2302.01330
- 在线 Demo:https://huggingface.co/spaces/FrozenBurning/SceneDreamer
为满足元宇宙中对 3D 创意工具不断增长的需求,三维场景生成最近受到了相当多的关注。3D 内容创作的核心是逆向图形学,旨在从 2D 观测中恢复 3D 表征。考虑到创建 3D 资产所需的成本和劳动力,3D 内容创作的最终目标将是从海量的互联网二维图像中学习三维生成模型。最近关于三维感知生成模型的工作在一定程度上解决了这个问题,多数工作利用 2D 图像数据生成以物体为中心的内容(例如人脸、人体或物体)。然而,这类生成任务的观测空间处于有限域中,生成的目标占据了三维空间的有限区域。这就产生了一个问题,我们是否能从海量互联网 2D 图像中学习到无界场景的 3D 生成模型?比如能够覆盖任意大区域,且无限拓展的生动自然景观
想要达成这样的目标,我们面临着如下三个挑战:
1)无界场景缺乏高效三维表征:无边界场景常常占据了一个任意大的欧氏空间,这凸显了高效且具备表现力的底层三维表征的重要性。
2)缺乏内容对齐:已有三维生成工作使用具备对齐性质的数据集(如人脸、人体、常用物体等),这些有界场景中的目标物体通常具备类似的语义、相近的尺度位置和方向。然而,在海量的无标注二维图像中,不同物体或场景常常具备迥异的语义,且拥有多变的尺度、位置和方向。这样缺乏对齐的性质会带来生成模型训练的不稳定性。
3)缺乏相机位姿先验:三维生成模型依赖于准确相机位姿或相机位姿分布的先验来实现图像到三维表征的逆向渲染过程。但互联网自然图像来源于不同的场景和像源,让我们无法获取其相机位姿准确信息或先验。
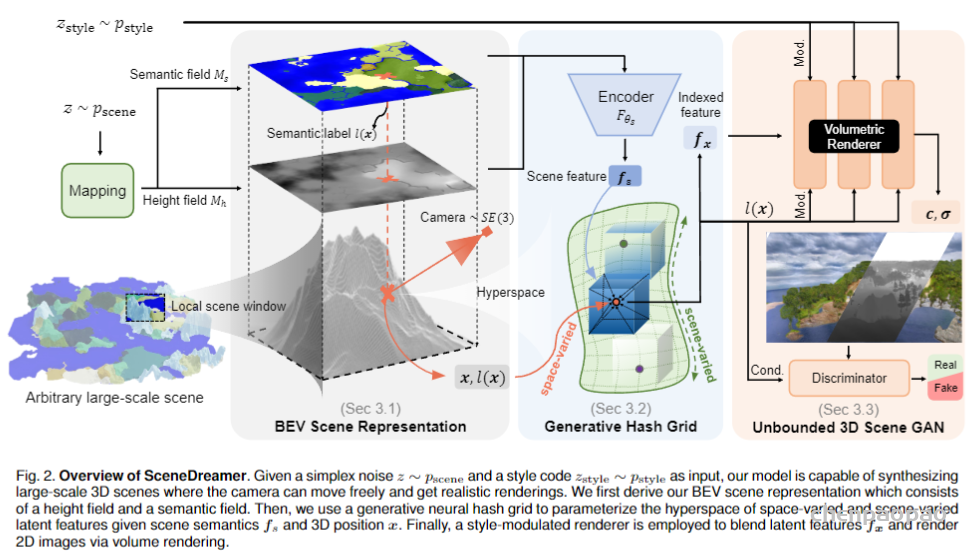
为此我们提出了一个原则性的对抗学习框架 SceneDreamer,从海量的无标注自然图像中学习生成无界三维场景。该框架包含三个主要模块:1)高效且高表现力的鸟瞰(BEV)三维场景表征;2)学习场景通用表征的生成式神经哈希网格;3)由风格驱动的体积渲染器,并经过对抗学习的方式直接从二维图像中进行训练。
6、 Shap・E,合成 3D 条件生成式模型
我们先来看一下生成效果。与根据文字生成图像类似,Shap・E 生成的 3D 物体模型主打一个「天马行空」。

本文提出的 Shap・E 是一种在 3D 隐式函数空间上的潜扩散模型,可以渲染成 NeRF 和纹理网格。在给定相同的数据集、模型架构和训练计算的情况下,Shap・E 更优于同类显式生成模型。研究者发现纯文本条件模型可以生成多样化、有趣的物体,更彰显了生成隐式表征的潜力。
不同于 3D 生成模型上产生单一输出表示的工作,Shap-E 能够直接生成隐式函数的参数。训练 Shap-E 分为两个阶段:首先训练编码器,该编码器将 3D 资产确定性地映射到隐式函数的参数中;其次在编码器的输出上训练条件扩散模型。当在配对 3D 和文本数据的大型数据集上进行训练时, 该模型能够在几秒钟内生成复杂而多样的 3D 资产。与点云显式生成模型 Point・E 相比,Shap-E 建模了高维、多表示的输出空间,收敛更快,并且达到了相当或更好的样本质量。
研究者首先训练编码器产生隐式表示,然后在编码器产生的潜在表示上训练扩散模型,主要分为以下两步完成:
1. 训练一个编码器,在给定已知 3D 资产的密集显式表示的情况下,产生隐式函数的参数。编码器产生 3D 资产的潜在表示后线性投影,以获得多层感知器(MLP)的权重;
2. 将编码器应用于数据集,然后在潜在数据集上训练扩散先验。该模型以图像或文本描述为条件。
研究者在一个大型的 3D 资产数据集上使用相应的渲染、点云和文本标题训练所有模型。
3D 编码器:

潜在扩散
生成模型采用基于 transformer 的 Point・E 扩散架构,但是使用潜在向量序列取代点云。潜在函数形状序列为 1024×1024,并作为 1024 个 token 序列输入 transformer,其中每个 token 对应于 MLP 权重矩阵的不同行。因此,该模型在计算上大致相当于基础 Point・E 模型(即具有相同的上下文长度和宽度)。在此基础上增加了输入和输出通道,能在更高维度的空间中生成样本。
7、Make-it-3D:diffusion+NeRF从单张图像生成高保真的三维物体
Title: Make-It-3D: High-Fidelity 3D Creation from A Single Image with Diffusion Prior
Paper: https://arxiv.org/pdf/2303.14184.pdf
Code: https://make-it-3d.github.io/

人类具有一种与生俱来的能力,可以轻松地想象3D几何和虚构出从不同角度看物体的外观,这基于他们对世界的先验知识。
在本文中,研究者的目标是实现类似的目标:从一个真实或人工生成的单张图像中创建高保真度的3D内容。这将为艺术表达和创意开辟新的途径,例如为像Stable Diffusion这样的前沿2D生成模型创建的幻想图像带来3D效果。通过提供一种更易于访问和自动化的创建视觉上惊人的3D内容的方法,研究者希望吸引更广泛的受众加入到轻松的3D建模世界中来。
本文探讨了仅使用单张图像创建高保真度3D内容的问题。这本质上是一项具有挑战性的任务,需要估计潜在的3D几何结构,并同时产生未见过的纹理。为了解决这个问题,论文利用训练好的2D扩散模型的先验知识作为3D生成的监督。论文的方法名为:Make-It-3D,采用两阶段优化pipeline:第一阶段通过在前景视图中结合参考图像的约束和新视图中的扩散先验来优化神经辐射场;第二阶段将粗略模型转化为纹理点云,并利用参考图像的高质量纹理,结合扩散先验进一步提高逼真度。大量实验证明,论文的方法在结果上显著优于先前的方法,实现了预期的重建效果和令人印象深刻的视觉质量。论文的方法是第一个尝试从单张图像为一般对象创建高质量3D内容的方法,可用于text-to-3D的创建和纹理编辑等各种应用。
论文的主要贡献总结如下:
- 论文提出了Make-It-3D框架,使用2D扩散模型作为3D-aware先验,从单个图像中创建高保真度的3D物体。该框架不需要多视图图像进行训练,并可应用于任何输入图像,无论是真实的还是生成的。
- 通过两个阶段的创建方案,Make-It-3D是首个实现普适对象高保真3D创建的工作。生成的3D模型展现出精细的几何结构和逼真的纹理,与参考图像相符。
- 除了图像到3D创建之外,论文的方法还能实现高质量text-to-3D创建和纹理编辑等多种应用。
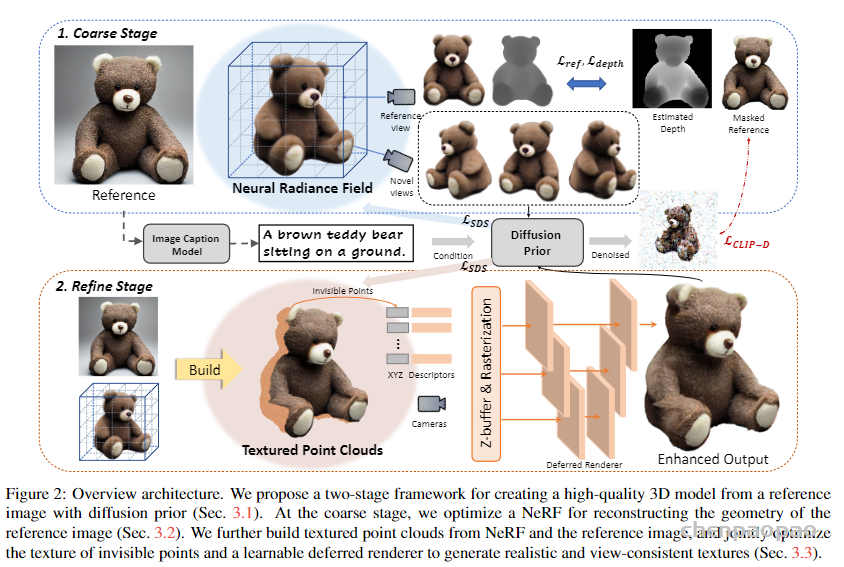
论文利用了文本-图像生成模型和文本-图像对比模型的先验知识,通过两阶段(Coarse Stage和Refine Stage)的学习来还原高保真度的纹理和几何信息,所提出的两阶段三维学习框架如图2所示。
8、ProlificDreamer:直接文本生成高质量3D内容
论文:《ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation》
清华大学 TSAIL 团队最新提出的文生 3D 新算法 ProlificDreamer,在无需任何 3D 数据的前提下能够生成超高质量的 3D 内容。ProlificDreamer 算法为文生 3D 领域带来重大进展。利用 ProlificDreamer,输入文本 “一个菠萝”,就能生成非常逼真且高清的 3D 菠萝:

在数字创作和虚拟现实等领域,从文本到三维模型(Text-to-3D)的技术具有重要的价值和广泛的应用潜力。这种技术可以从简单的文本描述中生成具体的 3D 模型,为设计师、游戏开发者和数字艺术家提供强大的工具。然而,为了根据文本生成准确的 3D 模型,传统方法需要大量的标记 3D 模型数据集。这些数据集需要包含多种不同类型和风格的 3D 模型,并且每个模型都需要与相应的文本描述相关联。创建这样的数据集需要大量的时间和人力资源,目前还没有现成的大规模数据集可供使用。由谷歌提出的 DreamFusion [1] 利用预训练的 2D 文本到图像扩散模型,首次在无需 3D 数据的情况下完成开放域的文本到 3D 的合成。但是 DreamFusion 提出的 Score Distillation Sampling (SDS) [1] 算法生成结果面临严重的过饱和、过平滑、缺少细节等问题。高质量 3D 内容生成目前仍然是非常困难的前沿问题之一。ProlificDreamer 论文提出了 Variational Score Distillation(VSD)算法,从贝叶斯建模和变分推断(variational inference)的角度重新形式化了 text-to-3D 问题。具体而言,VSD 把 3D 参数建模为一个概率分布,并优化其渲染的二维图片的分布和预训练 2D 扩散模型的分布间的距离。可以证明,VSD 算法中的 3D 参数近似了从 3D 分布中采样的过程,解决了 DreamFusion 所提 SDS 算法的过饱和、过平滑、缺少多样性等问题。此外,SDS 往往需要很大的监督权重(CFG=100),而 VSD 是首个可以用正常 CFG(=7.5)的算法。
与以往方法不同,ProlificDreamer 并不单纯优化单个 3D 物体,而是优化 3D 物体对应的概率分布。通常而言,给定一个有效的文本输入,存在一个概率分布包含了该文本描述下所有可能的 3D 物体。基于该 3D 概率分布,我们可以进一步诱导出一个 2D 概率分布。具体而言,只需要对每一个 3D 物体经过相机渲染到 2D,即可得到一个 2D 图像的概率分布。因此,优化 3D 分布可以被等效地转换为优化 2D 渲染图片的概率分布与 2D 扩散模型定义的概率分布之间的距离(由 KL 散度定义)。这是一个经典的变分推断(variational inference)任务,因此 ProlificDreamer 文中将该任务及对应的算法称为变分得分蒸馏(Variational Score Distillation,VSD)。具体而言,VSD 的算法流程图如下所示。其中,3D 物体的迭代更新需要使用两个模型:一个是预训练的 2D 扩散模型(例如 Stable-Diffusion),另一个是基于该预训练模型的 LoRA(low-rank adaptation)。该 LoRA 估计了当前 3D 物体诱导的 2D 图片分布的得分函数(score function),并进一步用于更新 3D 物体。该算法实际上在模拟 Wasserstein 梯度流,并可以保证收敛得到的分布满足与预训练的 2D 扩散模型的 KL 散度最小。
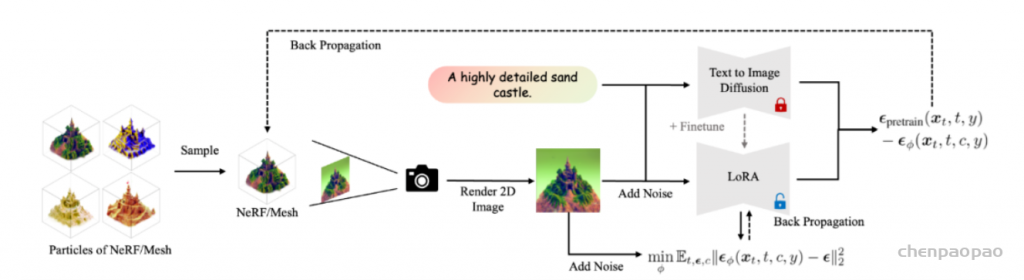
3D表示+2D Diffusion做3D任务的四个流派:
- 用Diffusion优化3D隐式场(其中Diffusion是预训练的),特别是NeRF相关工作,例如DreamFusion和SparseFusion;
- 使用3D Unet定制3D Diffusion,特别是point cloud相关工作;
- 把3D表示拆解并且重新拼接,变成超多通道2D图像,直接复用2D Diffusion,特别是Triplane相关工作,例如3D Neural Field Generation using Triplane Diffusion;
- 把2D Diffusion的Unet()换成一个renderer+encoder的结构,即间接引入3D约束,例如RenderDiffusion;
- 将3D约束编码成条件,用来约束2D Diffusion,例如DiffPose;
9: GET3D 英伟达:噪声—->3D物体
A Generative Model of High Quality 3D Textured Shapes Learned from Images (NeurIPS 2022 )
代码:https://github.com/nv-tlabs/GET3D

GET3D 包括两个分支:
1.几何分支:可微的输出任意拓扑的表面mesh
2.纹理分支:根据查询的表面点来产生 texture field,还可以扩展到表面的其他属性,比如材质
训练过程中,一个有效的可微栅格器将生成的带纹理 3D 模型投影到 2D 的高分辨率图片。整个过程都是可微分的,使得整个对抗训练可以从 discriminator 传递到两个分支。


10. DragGAN meets GET3D for interactive mesh generation and editing.
https://github.com/ashawkey/Drag3D
https://github.com/XingangPan/DragGAN
