
DiT原文: https://arxiv.org/abs/2212.09748 Code:https://github.com/facebookresearch/DiT Huggingface:https://huggingface.co/spaces/wpeebles/DiT
DiT扩散模型,出自谢赛宁与Sora研发之一威廉·皮波尔斯合著的一篇论文《Scalable diffusion models with transformers》,它不仅将 Transformer 成功应用到了扩散模型上,还深入探究了transformer架构在扩散模型上的scalability能力。
核心思想:提出了一种新的(可扩展)扩散模型架构,称为 DiT,该架构使用 Transformer 替换了传统的 U-Net 主干。
扩散模型大部分是采用UNet架构来进行建模,UNet可以实现输出和输入一样维度,所以天然适合扩散模型。扩散模型使用的UNet除了包含基于残差的卷积模块,同时也往往采用self-attention。自从ViT之后,transformer架构已经大量应用在图像任务上,随着扩散模型的流行,也已经有工作尝试采用transformer架构来对扩散模型建模,这篇文章我们将介绍Meta的工作DiT:Scalable Diffusion Models with Transformers,它是完全基于transformer架构的扩散模型,这个工作不仅将transformer成功应用在扩散模型,还探究了transformer架构在扩散模型上的scalability能力,其中最大的模型DiT-XL/2在ImageNet 256×256的类别条件生成上达到了SOTA(FID为2.27)。
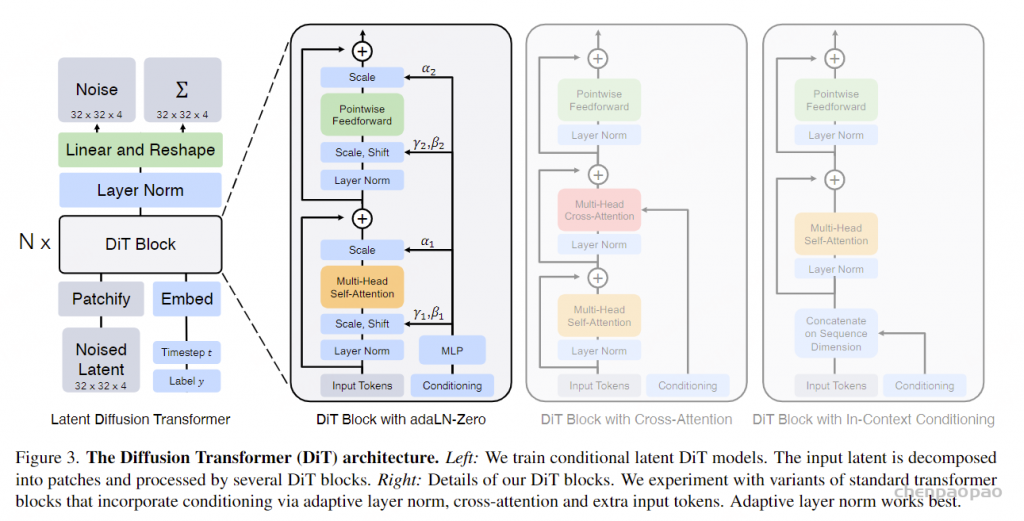
DiT基本沿用了ViT的设计,如下图所示,首先采用一个patch embedding来将输入进行patch化,即得到一系列的tokens。其中patch size属于一个超参数,它直接决定了tokens的数量,这会影响模型的计算量。DiT的patch size共选择了三种设置:𝑝=2,4,8。注意token化之后,这里还要加上positional embeddings,这里采用非学习的sin-cosine位置编码。
将输入token化之后,就可以像ViT那样接transformer blocks了。但是对于扩散模型来说,往往还需要在网络中嵌入额外的条件信息,这里的条件包括timesteps以及类别标签(如果是文生图就是文本,但是DiT这里并没有涉及)。要说明的一点是,无论是timesteps还是类别标签,都可以采用一个embedding来进行编码。DiT共设计了四种方案来实现两个额外embeddings的嵌入,具体如下:
- In-context conditioning:将两个embeddings看成两个tokens合并在输入的tokens中,这种处理方式有点类似ViT中的cls token,实现起来比较简单,也不基本上不额外引入计算量。
- Cross-attention block:将两个embeddings拼接成一个数量为2的序列,然后在transformer block中插入一个cross attention,条件embeddings作为cross attention的key和value;这种方式也是目前文生图模型所采用的方式,它需要额外引入15%的Gflops。
- Adaptive layer norm (adaLN) block:采用adaLN,这里是将time embedding和class embedding相加,然后来回归scale和shift两个参数,这种方式也基本不增加计算量。
- adaLN-Zero block:采用zero初始化的adaLN,这里是将adaLN的linear层参数初始化为zero,这样网络初始化时transformer block的残差模块就是一个identity函数;另外一点是,这里除了在LN之后回归scale和shift,还在每个残差模块结束之前回归一个scale,如上图所示。
论文对四种方案进行了对比试验,发现采用adaLN-Zero效果是最好的,所以DiT默认都采用这种方式来嵌入条件embeddings。
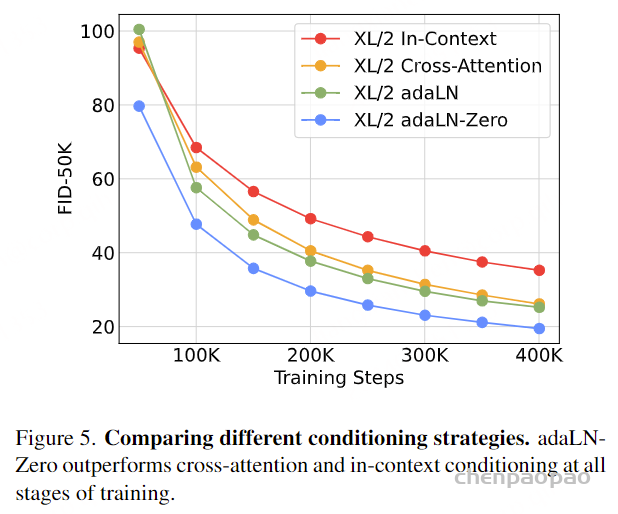
虽然DiT发现adaLN-Zero效果是最好的,但是这种方式只适合这种只有类别信息的简单条件嵌入,因为只需要引入一个class embedding;但是对于文生图来说,其条件往往是序列的text embeddings,采用cross-attention方案可能是更合适的。 由于对输入进行了token化,所以在网络的最后还需要一个decoder来恢复输入的原始维度,DiT采用一个简单的linear层来实现,直接将每个token映射为𝑝×𝑝×2𝐶的tensor,然后再进行reshape来得到和原始输入空间维度一样的输出,但是特征维度大小是原来的2倍,分别用来预测噪音和方差。
注意这里先进行LayerNorm,同时也引入了zero adaLN,并且decoder的linear层也采用zero初始化。 仿照ViT,DiT也设计了4种不同规模的模型,分别是DiT-S、DiT-B、DiT-L和DiT-XL,其中最大的模型DiT-XL参数量为675M,计算量Gflops为29.1(256×256图像,patch size=4时)。
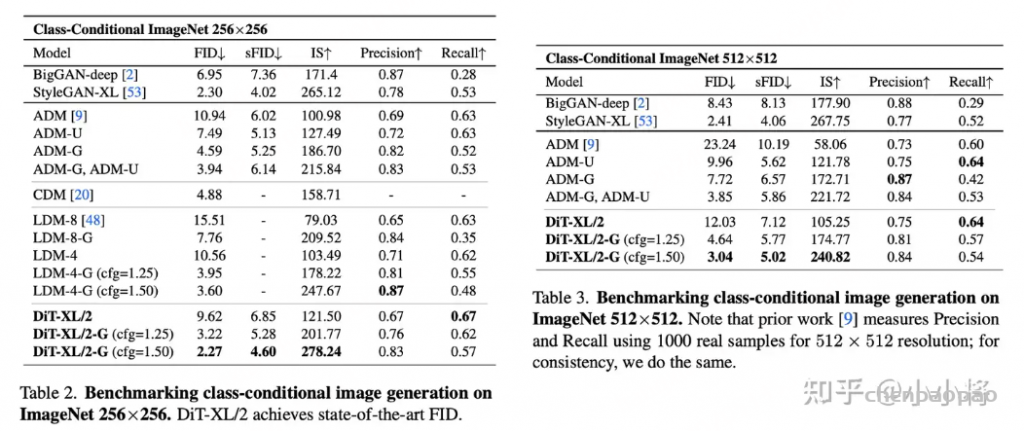
在具体性能上,最大的模型DiT-XL/2采用classifier free guidance可以在class-conditional image generation on ImageNet 256×256任务上实现当时的sota。
虽然DiT看起来不错,但是只在ImageNet上生成做了实验,并没有扩展到大规模的文生图模型。而且在DiT之前,其实也有基于transformer架构的扩散模型研究工作,比如U-ViT,目前也已经有将transformer应用在大规模文生图(基于扩散模型)的工作,比如UniDiffuser,但是其实都没有受到太大的关注。目前主流的文生图模型还是采用基于UNet,UNet本身也混合了卷积和attention,它的优势一方面是高效,另外一方面是不需要位置编码比较容易实现变尺度的生成,这些对具体落地应用都是比较重要的。