
网址: https://distill.pub/2017/ctc/
在语音识别中,我们的数据集是音频文件和其对应的文本,不幸的是,音频文件和文本很难在单词的单位上对齐。除了语言识别,在OCR,机器翻译中,都存在类似的Sequence to Sequence结构,同样也需要在预处理操作时进行对齐,但是这种对齐有时候是非常困难的。如果不使用对齐而直接训练模型时,由于人的语速的不同,或者字符间距离的不同,导致模型很难收敛。
我们可以设计一个规则,比如“一个字符对应十个语音输入”。但是人们的语速是不同的,所以这种规则总是可以被打破的。另一种方法是手动将每个字符与其在音频中的位置对齐。从建模的角度来看,这工作得很好,我们知道每个输入时间步的基本事实。 然而,这对数据集的标注工作是非常耗时的。
这个问题不仅仅出现在语音识别中。我们在许多其他地方看到它。来自图像或笔画序列的手写识别就是一个例子。

CTC(Connectionist Temporal Classification 连接时序分类)是一种避开输入与输出手动对齐的一种方式,是非常适合语音识别或者OCR这种应用的。
给定输入序列 𝑋=[𝑥1,𝑥2,…,𝑥𝑇] 以及对应的标签数据 𝑌=[𝑦1,𝑦2,..,𝑦𝑈] ,例如语音识别中的音频文件和文本文件。我们的工作是找到 𝑋 到 𝑌 的一个映射,这种对时序数据进行分类的算法叫做Temporal Classification。
对比传统的分类方法,时序分类有如下难点:
- 𝑋 和 𝑌 的长度都是变化的;
- 𝑋 和 𝑌 的长度是不相等的;
- 对于一个端到端的模型,我们并不希望手动设计𝑋 和 𝑌 的之间的对齐。
CTC提供了解决方案,对于一个给定的输入序列 𝑋 ,CTC给出所有可能的 𝑌 的输出分布。根据这个分布,我们可以输出最可能的结果或者给出某个输出的概率。我们会要求CTC有效地完成下面这两件事。
1、损失函数:给定输入序列 𝑋 ,我们希望最大化 𝑌 的后验概率 𝑃(𝑌|𝑋) , 𝑃(𝑌|𝑋) 应该是可导的,这样我们能执行梯度下降算法;
2、测试:给定一个训练好的模型和输入序列 𝑋 ,我们希望输出概率最高的 𝑌 :
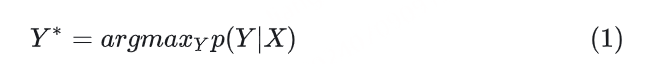
当然,在测试时,我们希望 𝑌∗ 能够尽快的被搜索到。
算法详解
给定输入 𝑋 ,CTC输出每个可能输出及其条件概率。问题的关键是CTC的输出概率是如何考虑 𝑋 和 𝑌 之间的对齐的,这种对齐也是构建损失函数的基础。所以,首先我们分析CTC的对齐方式,然后我们在分析CTC的损失函数的构造。
1.1 对齐
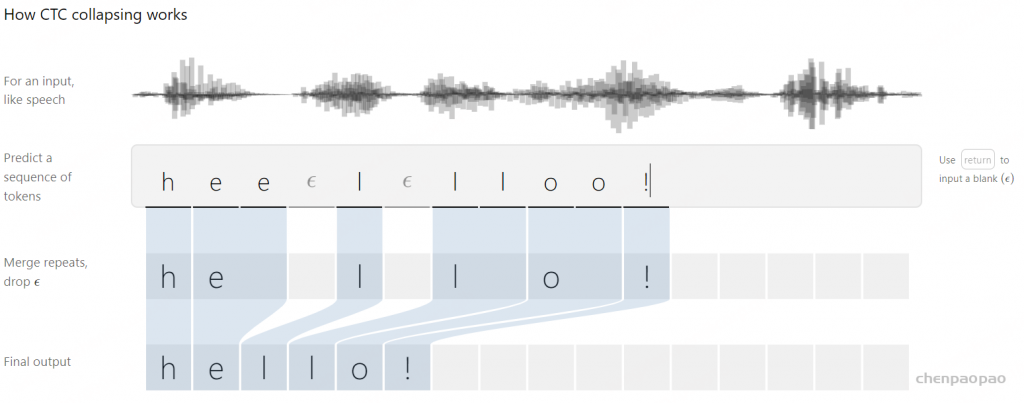
需要注意的是,CTC本身是不需要对齐的,但是我们需要知道 𝑋 的输出路径和最终输出结果的对应关系,因为在CTC中,多个输出路径可能对应一个输出结果,举例来理解。例如在OCR的任务中,输入 𝑋 是含有“CAT”的图片,输出 𝑌 是文本[C, A, T]。将 𝑋 分割成若干个时间片,每个时间片得到一个输出,一个最简答的解决方案是合并连续重复出现的字母,如图2.
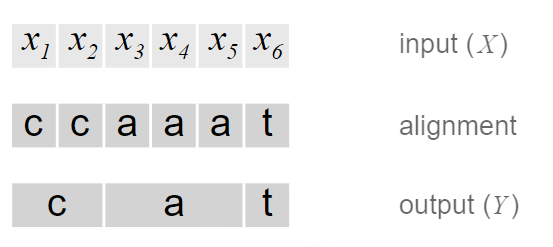
这个问题有两个缺点:
- 几乎不可能将 𝑋 的每个时间片都和输出Y对应上,例如OCR中字符的间隔,语音识别中的停顿;
- 不能处理有连续重复字符出现的情况,例如单词“HELLO”,按照上面的算法,输出的是“HELO”而非“HELLO”。
为了解决上面的问题,CTC引入了空白字符 𝜖 ,例如OCR中的字符间距,语音识别中的停顿均表示为 𝜖 。所以,CTC的对齐涉及去除重复字母和去除 𝜖 两部分,如图3。


这种对齐方式有三个特征:
- 𝑋 与 𝑌 之间的时间片映射是单调的,即如果 𝑋 向前移动一个时间片, 𝑌 保持不动或者也向前移动一个时间片;
- 𝑋 与 𝑌 之间的映射是多对一的,一个或多个输入元素可以与单个输出元素对齐,但反之则不然,所以也有了特征3;
- 𝑋 的长度大于等于 𝑌 的长度。
1.2 损失函数
CTC对齐为我们提供了一种从每个时间步的概率到输出序列的概率的自然方法。

也就是说,对应标签 𝑌 ,其关于输入 𝑋 的后验概率可以表示为所有映射为 𝑌 的路径之和,我们的目标就是最大化 𝑌 关于 𝑥=𝑦 的后验概率 𝑃(𝑌|𝑋) 。假设每个时间片的输出是相互独立的,则路径的后验概率是每个时间片概率的累积,公式及其详细含义如图5。

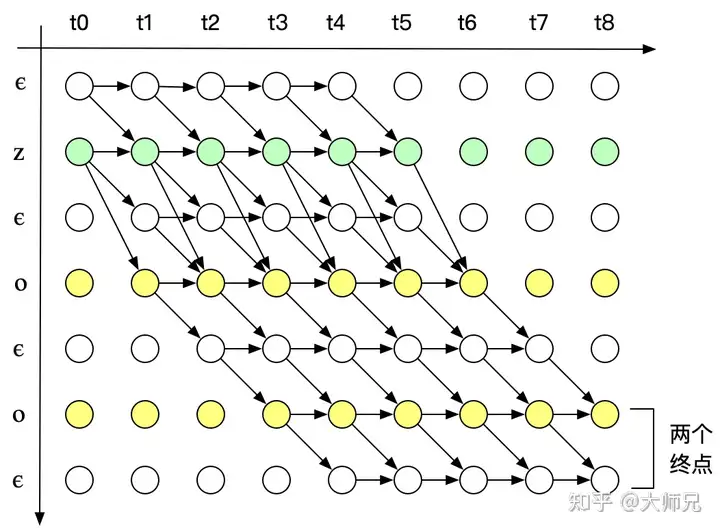
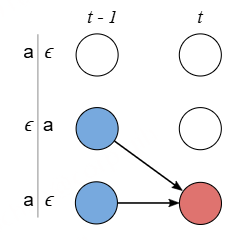
上面的CTC算法存在性能问题,对于一个时间片长度为 𝑇 的 𝑁 分类任务,所有可能的路径数为 𝑁𝑇 ,在很多情况下,这几乎是一个宇宙级别的数字,用于计算Loss几乎是不现实的。在CTC中采用了动态规划的思想来对查找路径进行剪枝,算法的核心思想是如果路径 𝜋1 和路径 𝜋2 在时间片 𝑡 之前的输出均相等,我们就可以提前合并他们,如图6。
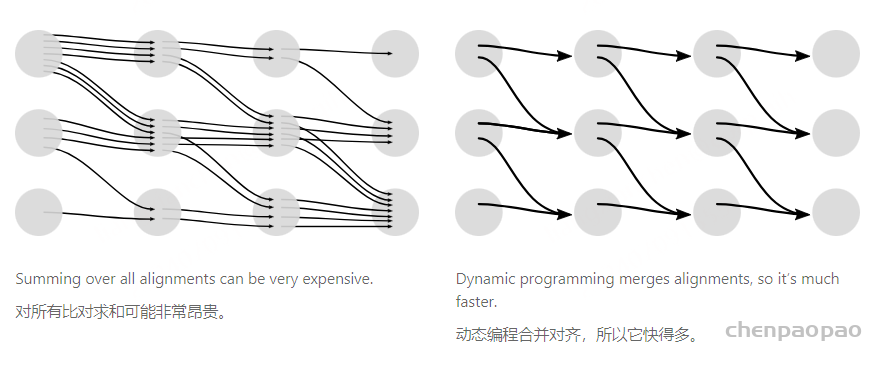
其中,横轴的单位是 𝑋 的时间片,纵轴的单位是 𝑌 插入 𝜖 的序列 𝑍 。例如对于单词“ZOO”,插入 𝜖 后为:
𝑍={𝜖,𝑍,𝜖,𝑂,𝜖,𝑂,𝜖}
我们用 𝛼𝑠,𝑡 表示路径中已经合并的在横轴单位为 𝑡 ,纵轴单位为 𝑠 的节点。根据CTC的对齐方式的三个特征,输入有9个时间片,标签内容是“ZOO”, 𝑃(𝑌|𝑋) 的所有可能的合法路径如下图:


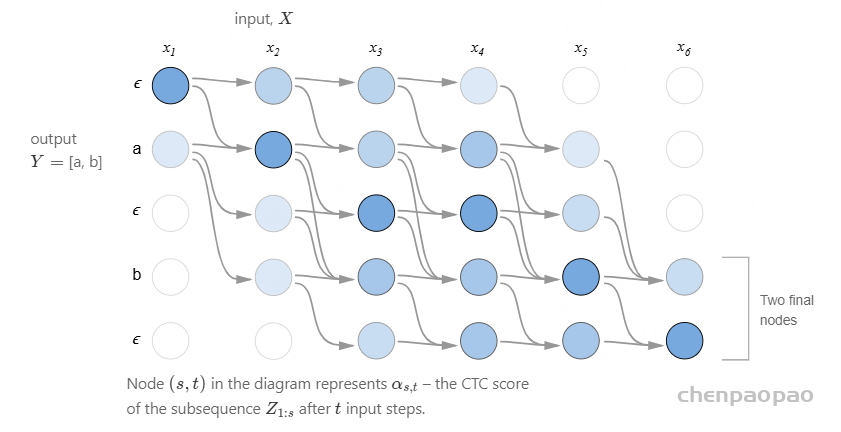
有两个有效的起始节点和两个有效的最终节点,因为序列开头和结尾的 𝜖ϵ 是可选的。完全概率是最后两个节点的和。现在我们可以有效地计算损失函数,下一步是计算梯度并训练模型。CTC损失函数相对于每个时间步的输出概率是可微的,因为它只是它们的总和和乘积。考虑到这一点,我们可以解析地计算损失函数相对于(未归一化的)输出概率的梯度,并从那里像往常一样运行反向传播。
对于数据集 𝐷 ,模型的优化目标是最小化负对数似然:
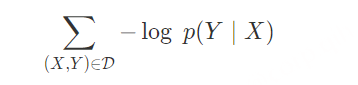
1.3 预测
当我们训练好一个RNN模型时,给定一个输入序列 𝑋 ,我们需要找到最可能的输出,也就是求解
𝑌∗=argmax𝑌𝑝(𝑌|𝑋)
求解最可能的输出有两种方案,一种是Greedy Search,第二种是beam search
1.3.1 Greedy Search
每个时间片均取该时间片概率最高的节点作为输出:
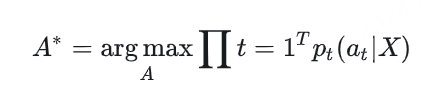
1.3.2 Beam Search
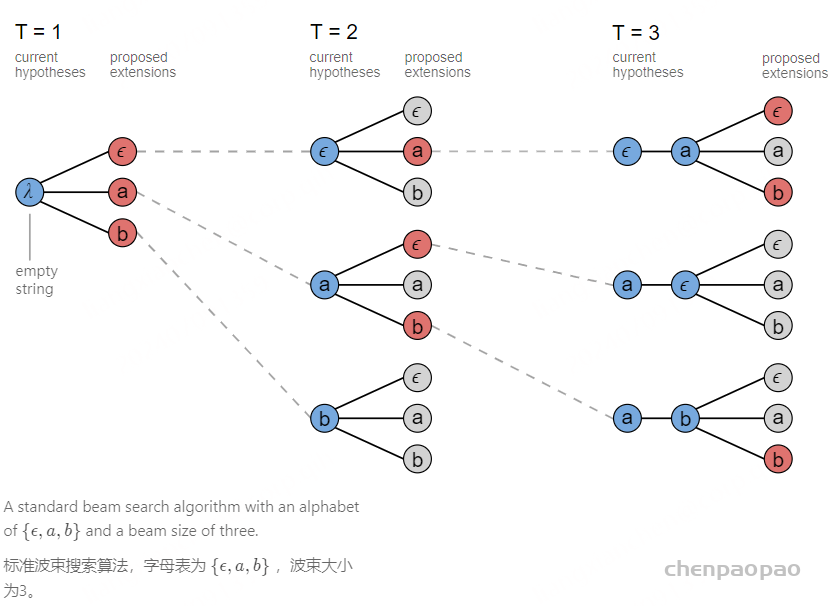
Beam Search是寻找全局最优值和Greedy Search在查找时间和模型精度的一个折中。一个简单的beam search在每个时间片计算所有可能假设的概率,并从中选出最高的几个作为一组。然后再从这组假设的基础上产生概率最高的几个作为一组假设,依次进行,直到达到最后一个时间片,下图是beam search的宽度为3的搜索过程,红线为选中的假设。
到目前为止,我们提到了CTC的一些重要属性。在这里,我们将更深入地了解这些属性是什么以及它们提供了什么样的权衡。
CTC的性质:
- 条件独立:CTC的一个非常不合理的假设是其假设每个时间片都是相互独立的,这是一个非常不好的假设。在OCR或者语音识别中,各个时间片之间是含有一些语义信息的,所以如果能够在CTC中加入语言模型的话效果应该会有提升。
- 单调对齐:CTC的另外一个约束是输入 𝑋 与输出 𝑌 之间的单调对齐,在OCR和语音识别中,这种约束是成立的。但是在一些场景中例如机器翻译,这个约束便无效了。
- 多对一映射:CTC的又一个约束是输入序列 𝑋 的长度大于标签数据 𝑌 的长度,但是对于 𝑌 的长度大于 𝑋 的长度的场景,CTC便失效了。
Practitioner’s Guide
到目前为止,我们已经对 CTC 有了概念性的理解。在这里,我们将为从业者提供一些实现技巧。
软件:即使对 CTC 有深入的了解,实施也很困难。该算法有几个边缘情况,应该用较低级别的编程语言编写快速实现。开源软件工具使入门变得更加容易:
- 百度研究已经开源了warp-ctc。该软件包是用 C++ 和 CUDA 编写的。CTC 损失函数在 CPU 或 GPU 上运行。绑定可用于 Torch、TensorFlow 和 PyTorch。
- TensorFlow 为 CPU 内置了 CTC loss and CTC beam search 束搜索函数。
- Nvidia 还在cuDNN 版本 7 及更高版本中提供了 CTC 的 GPU 实现。
Numerical Stability:计算 CTC 损失在数值上是不稳定的。避免这种情况的一种方法是在每个时间步长归一化 α。在实践中,这对于中等长度的序列来说已经足够好了,但对于长序列来说,它仍然会下溢。更好的解决方案是使用 log-sum-exp 技巧计算对数空间中的损失函数。 4 在对数空间中计算两个概率之和时,使用恒等式.还应使用 log-sum-exp 技巧在 log-space 中进行推理。
Beam Search:
使用波束搜索解码器时的一个常见问题是要使用的波束的大小。准确性和运行时间之间存在权衡。我们可以检查光束尺寸是否在良好的范围内。为此,首先计算推断输出 ci. 的 CTC 分数,然后计算真值输出 cg. 的 CTC 分数 如果两个输出不同,我们应该有cg<ci. Ifci<<cg ,那么真值输出在模型下实际上具有更高的概率,并且光束搜索未能找到它。在这种情况下,可能需要大幅增加光束尺寸。