
https://zhuanlan.zhihu.com/p/693885420
A Survey on Multimodal Large Language Models
https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
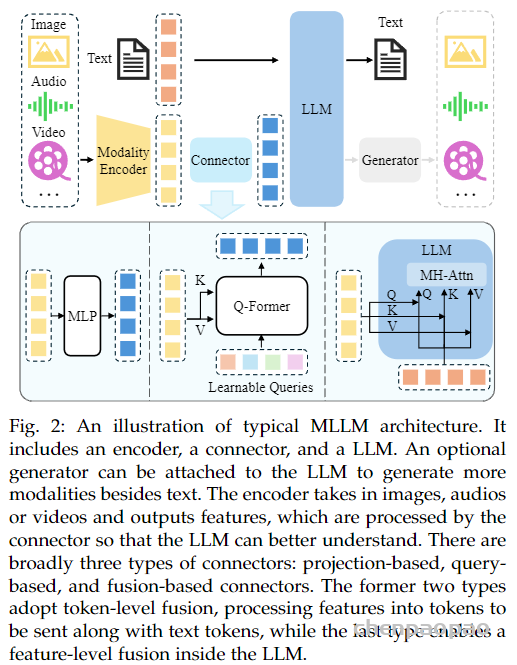
本文回顾了多模态LLM (视觉-语言模型) 近一年来的模型架构演进,对其中有代表性的工作进行了精炼总结.这篇综述一张图总结了多模态LLM的典型架构:
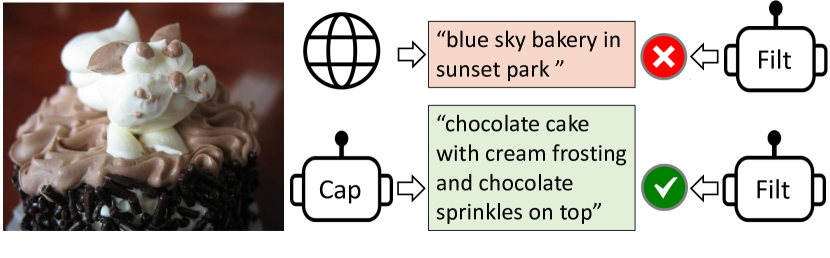
BLIP
【2022.01发布】https://arxiv.org/abs/2201.12086
统一视觉-语言理解和生成,使用captioner+filter高效利用互联网有噪数据
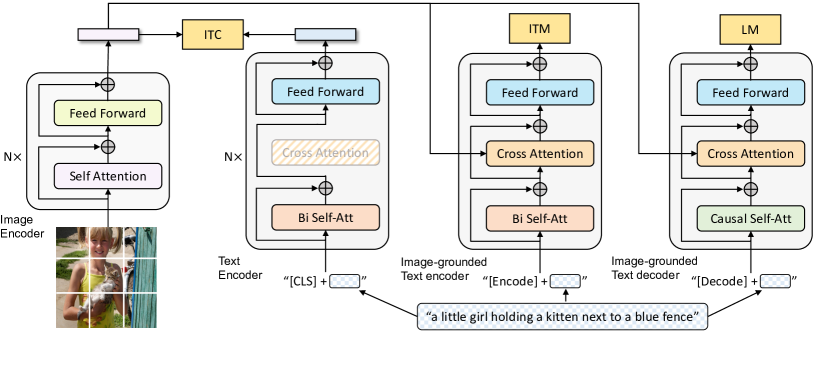
模型架构:
- Image/text encoder: ITC loss对齐视觉和语言表征,基于ALBEF提出的momentum distillation
- Image-grounded text encoder: ITM loss建模视觉-语言交互,区分positive/negative图文对,使用hard negative mining挖掘更高相似度的负例优化模型
- Image-grounded text decoder: LM loss实现基于图像的文本解码,将双向self-attention替换为causal self-attention
BLIP-2
【2023.01发布】https://arxiv.org/abs/2301.12597
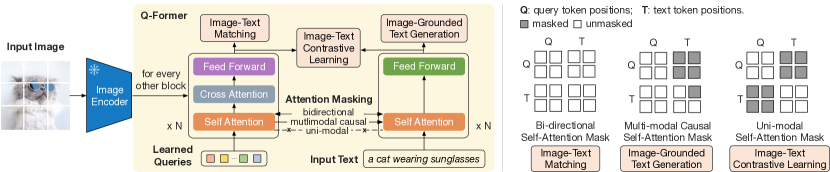
使用相对轻量的Q-Former连接视觉-语言模态,通过两阶段训练:第1阶段基于冻住的视觉编码器,第2阶段基于冻住的LLM
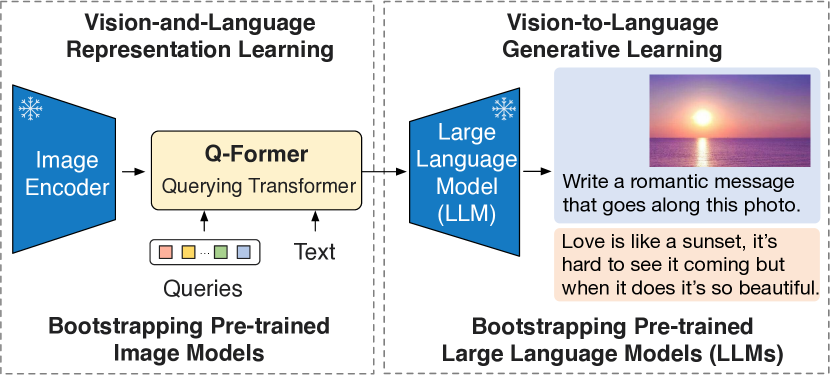
第1阶段:同样优化ITC/ITM/LM loss,使用不同的self-attention mask,query和text端共享self-attention参数,使得可学习的query embedding提取与text语义最相关的视觉表征;使用BERT-base初始化,32个768维的query作为信息瓶颈
- ITC:计算每个query与text的相似度,取最大的;使用batch内negatives,不再使用momentum queue
- ITM:对每个query与text的分类logits取平均,使用hard negatives mining挖掘难负例
- LM:text token和frozen image encoder不能直接交互,要求query能提取有益的视觉特征
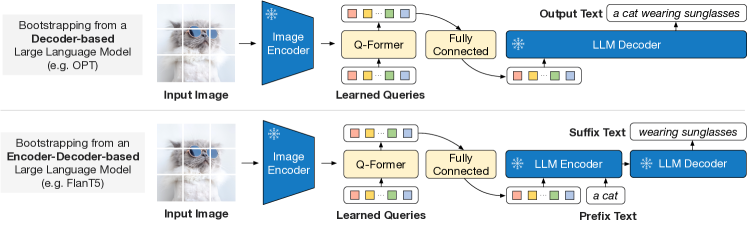
第2阶段:可基于decoder-only/encoder-decoder LLM进行适配,FC层对齐维度
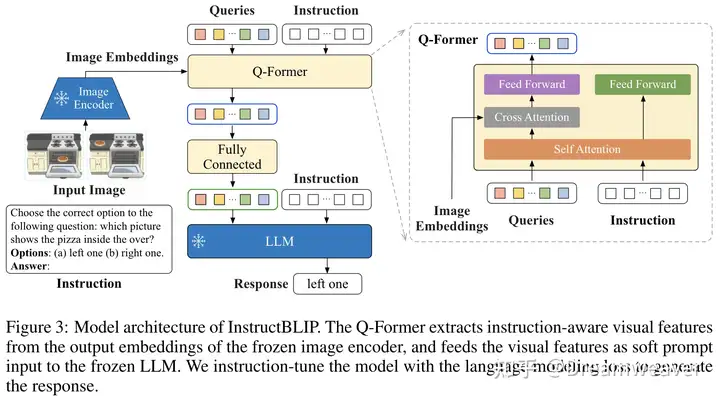
LLaVA
【2023.04发布】https://arxiv.org/abs/2304.08485
- 使用仅文本模态的GPT-4生成视觉-语言指令遵循数据,用于微调多模态LLM
- 使用图片的dense captions和bounding boxes作为prompt,可以生成对话、细节描述、复杂推理等指令
- CLIP ViT-L/14 + Vicuna,使用简单的线性层进行映射
- 更复杂的:Flamingo中gated cross-attention,BLIP-2中的Q-former
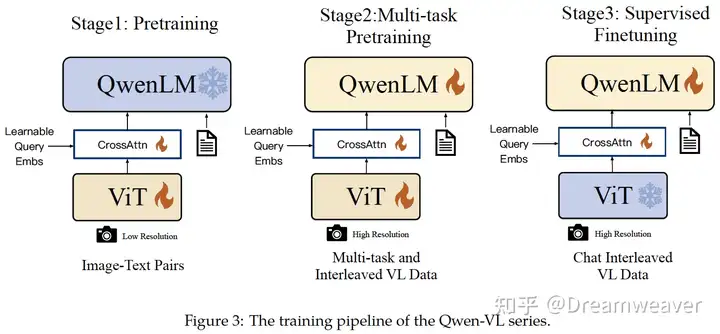
Qwen-VL
【2023.08发布】https://arxiv.org/abs/2308.12966
支持中英双语、多图像输入
Qwen-7B + OpenCLIP ViT-bigG,输入图像直接resize到视觉编码器输入
位置感知的VL adapter:使用基于Q-former的单层的cross-attention,将图像特征维度压缩到256,在query-key pairs中引入2D绝对位置编码增强位置信息
图像输入:<img>256-dim图像特征</img>
bounding box输入输出:<box>(X_topleft, Y_topleft), (X_bottomright, Y_bottomright)</box>, <ref>…</ref>标记box所指内容
三阶段训练:
stage1. 预训练:基于大规模、弱标注、网络爬取的图像-文本对,输入分辨率224×224,冻住LLM,训练ViT和Q-former,主要目的是模态对齐
stage2. 多任务预训练:基于7种下游视觉-语言理解任务的高质量、细粒度标注数据训练,输入分辨率448×448,图像/文本数据交错,训练整个模型
stage3. 指令微调:提升指令遵循和多轮对话能力,冻住ViT,训练LLM和Q-former
Qwen-VL-Plus和Qwen-VL-Max提升了视觉推理能力、图像细节的识别/提取/分析能力(尤其是文本导向的任务)、支持高分辨率和极端纵横比的输入图像;在部分中文场景超过了GPT-4V和Gemini
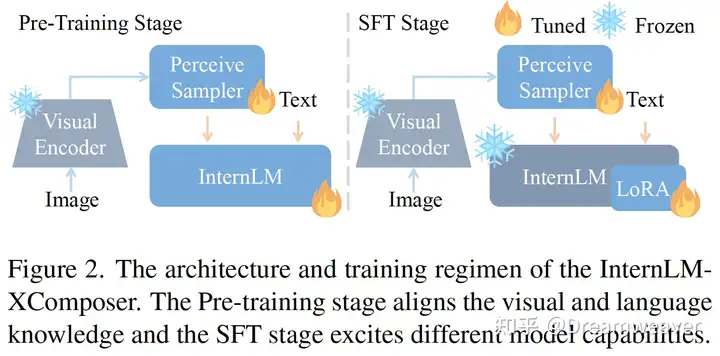
InternLM-XComposer
【2023.09发布】https://arxiv.org/abs/2309.15112
交错图文构成:自动在输出文本中插入合适的图片
EVA-CLIP ViT + InternLM-7B + Q-former (将图像特征压缩到64个embedding)
两阶段训练:
stage1. 预训练:冻住ViT,训练LLM和Q-former
stage2. 监督微调:包括多任务训练和指令微调,冻住ViT和LLM,训练Q-former,对LLM进行LoRA微调,增强指令遵循和图文混排能力
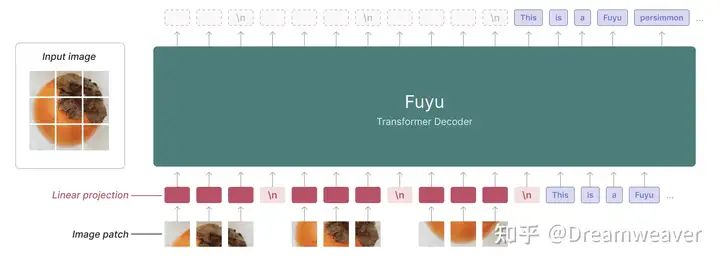
Fuyu-8B
【2023.10发布】https://huggingface.co/adept/fuyu-8b
模型架构和训练过程简单,易于scaling;支持任意图像分辨率;推理速度快
decoder-only的transformer,没有专门的图像编码器;image patch直接线性映射到transformer第一层
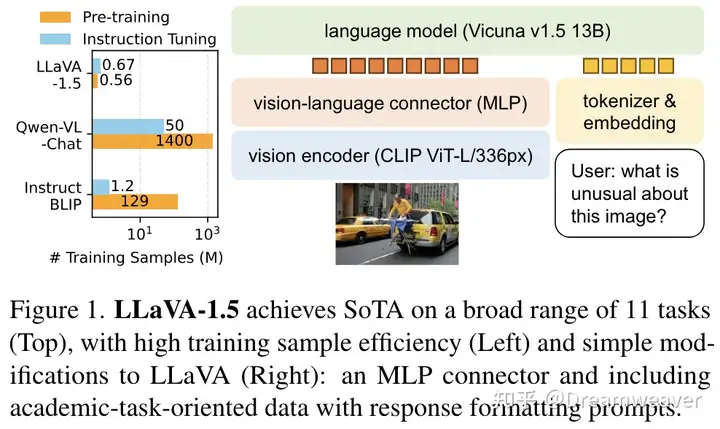
LLaVA-1.5
【2023.10发布】https://arxiv.org/abs/2310.03744
仍使用MLP作为模态连接,突出了训练的数据高效性
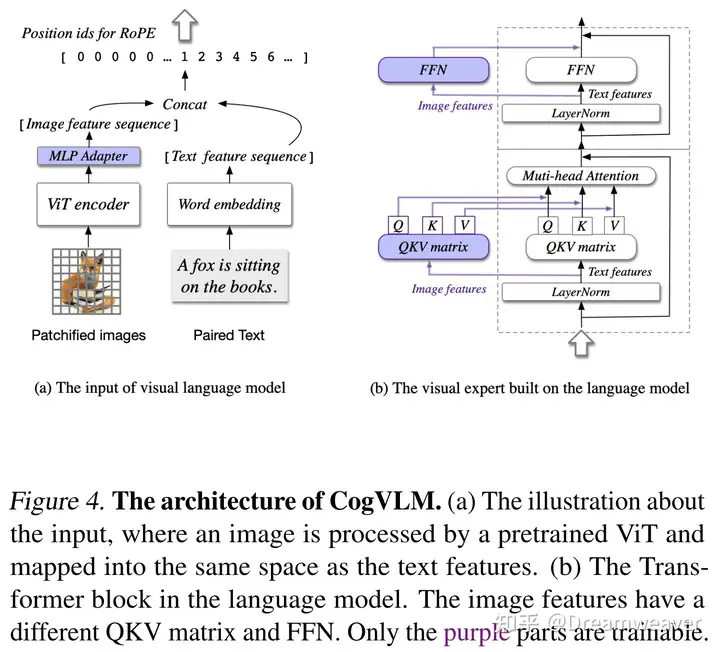
CogVLM
【2023.11发布】https://arxiv.org/abs/2311.03079
深度视觉-语言模态融合,而不影响LLM原有的语言能力:冻住LLM和ViT,在attention和FFN层训练一份视觉专家模块
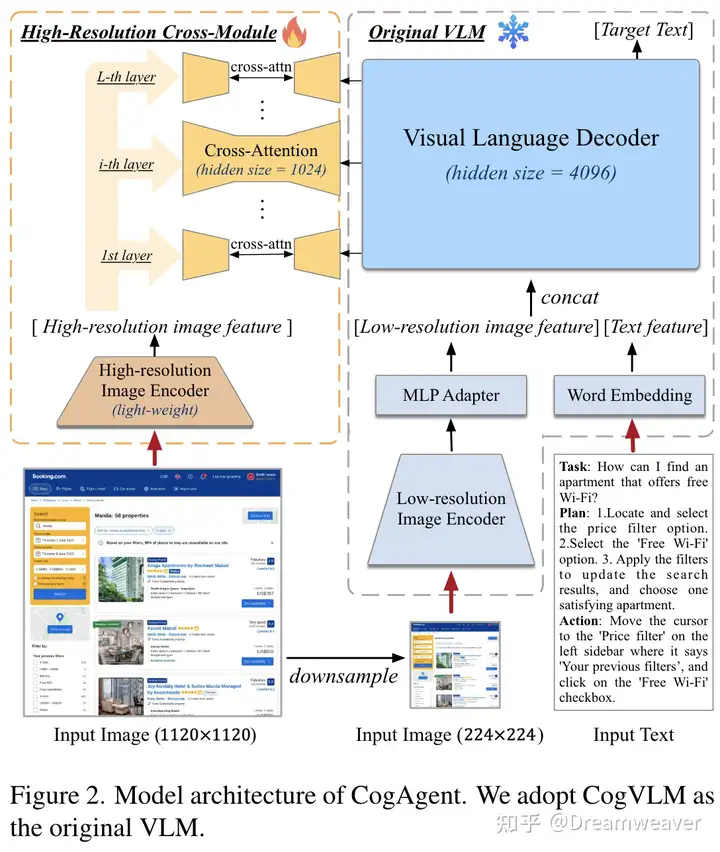
CogAgent
【2023.12发布】https://arxiv.org/abs/2312.08914
针对GUI场景的多模态理解和导引,使用高分辨率-低分辨率双编码器,支持1120×1120的屏幕输入
高分辨率分支使用更轻量的ViT,基于cross-attention将高分辨率图像特征与LLM每层进行融合
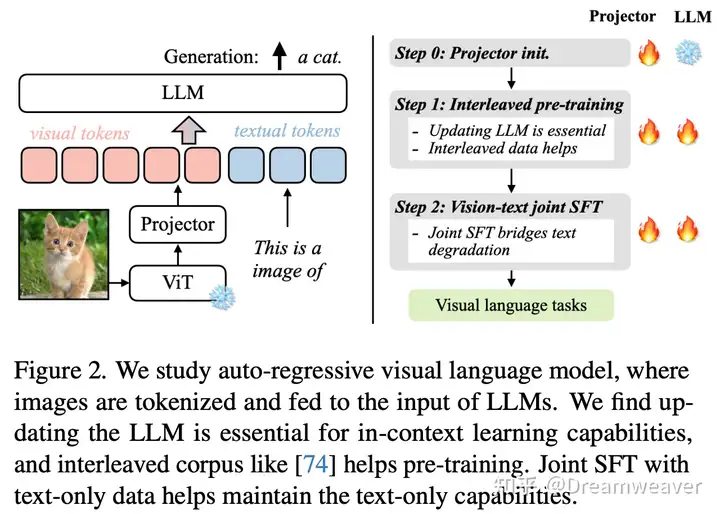
VILA
【2023.12发布】https://arxiv.org/abs/2312.07533
探索了视觉-语言模型训练的设计选择:
- 预训练阶段冻住LLM虽然能取得较好的zero-shot性能,但上下文学习能力依赖对LLM的微调
- 图文交错的预训练数据是有益的,只用图文数据对效果不够好
- 将纯文本的指令微调数据加入SFT阶段有助于缓解纯文本任务的能力退化,同时也能够增强视觉-语言任务的准确性
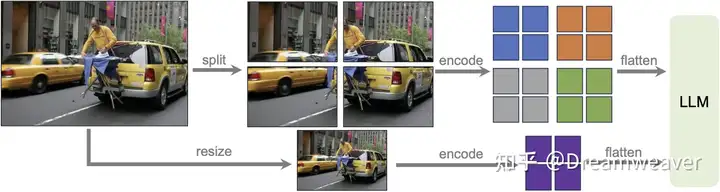
LLaVA-Next
【2024.01发布】https://llava-vl.github.io/blog/2024-01-30-llava-next/
相对于LLaVA-1.5,保持了极简的设计和数据高效性:
- 提高了输入图像的分辨率 (4x),支持3种纵横比:672×672, 336×1344, 1344×336
- 更好的视觉推理和OCR能力:更好的指令微调数据配比
- 更好的多场景视觉对话:更好的世界知识和逻辑推理
- 更高效的部署和推理:SGLang
动态高分辨率:视觉编码器支持336×336的图像输入,对于672×672的图像,按照{2,2}的grid split成4个图像patch过encoder,downsample到336×336也过encoder,特征拼接作为visual tokens输入到LLM中
收集高质量用户数据,包括真实场景中反映用户更广泛意图的指令数据,利用GPT-4V进行数据构造
多模态文档/图表数据,增强文档OCR和图表理解能力
InternLM-XComposer2
【2024.01发布】https://arxiv.org/abs/2401.16420
提出了新的模态对齐方法partial LoRA:只在image token上添加LoRA参数,保证预训练语言知识的完整性,这样一个更轻量的视觉编码器同样有效
OpenAI CLIP ViT-L/14 + InternLM2-7B + partial LoRA (rank=256)
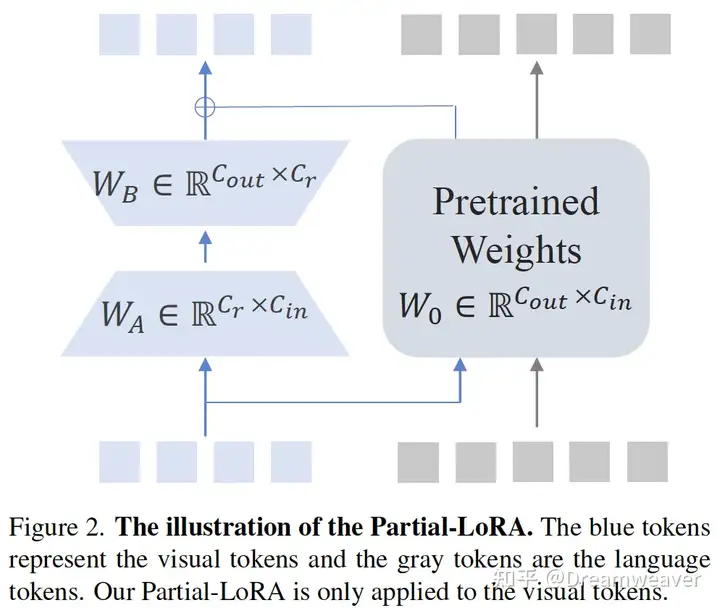
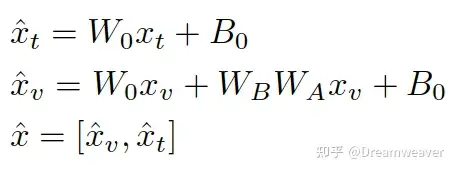
两阶段训练:
stage1. 预训练:冻住LLM,微调ViT和partial LoRA模块,包括通用语义对齐(理解图像基本内容)、世界知识对齐(进行复杂的知识推理)、视觉能力增强(OCR、物体定位、图表理解)
stage2. 监督微调:微调整个模型,包括多任务训练、自由形式图文排布
InternLM-XComposer2-4KHD
2024.04发布了4KHD版本:https://arxiv.org/abs/2404.06512
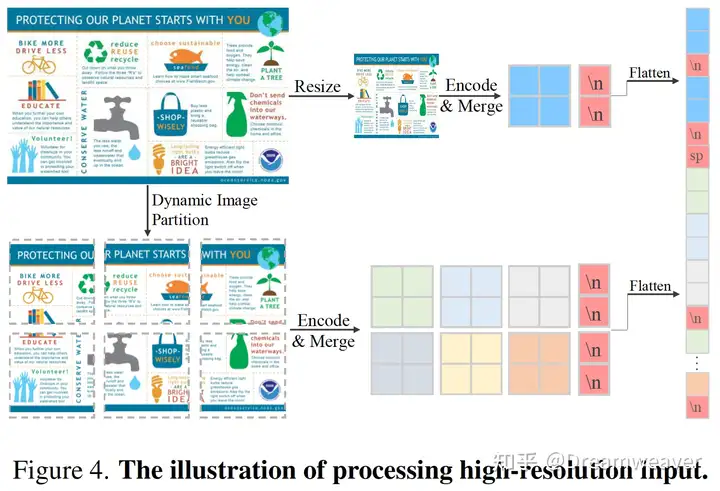
支持动态分辨率(336px → 4K (3840×1600)):改进了patch division范式,保持训练图像原有的纵横比,自动变化patch数目,基于336×336的ViT配置layout
动态图像划分:将输入图像resize and pad到336的整数倍宽高
结合图像的global和local视角:global视角由输入直接resize到336×336,使用sep token分隔两种视角的token
图像2D结构的换行符:可学习的\n token分隔图像token行
Mini-Gemini
【2024.03发布】https://arxiv.org/abs/2403.18814
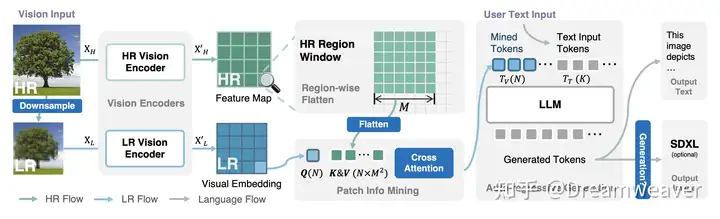
使用双视觉编码器提取低分辨率embedding作为query,高分辨率特征区域作为key/value,两者之间做cross-attention,输出挖掘的tokens作为prompt前缀,输入到LLM做推理,外接图像解码器生成图像(SDXL)
LLaVA-NeXT系列
LLaVA-1.5
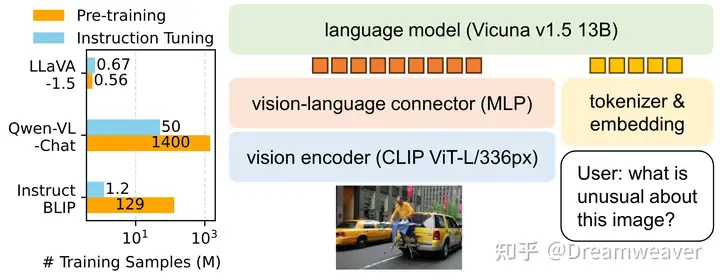
23年10月,LLaVA-1.5发布,通过在视觉和语言模态间添加简单的MLP层实现了训练样本高效性,为多模态大模型在低数据业务场景的落地提供了可能。
[2310.03744] Improved Baselines with Visual Instruction Tuning
LLaVA-NeXT
24年1月,LLaVA-NeXT(1.6)发布,在1.5的基础上保持了精简的设计和数据高效性,支持更高的分辨率、更强的视觉推理和OCR能力、更广泛场景的视觉对话。模型分为两阶段训练:阶段1预训练只训练连接层,阶段2指令微调训练整个模型。
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge
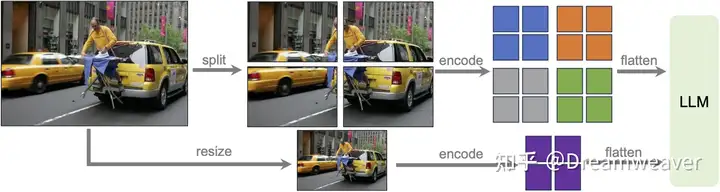
- 动态高分辨率AnyRes:如上图,为了让模型能感知高分辨率图像的复杂细节,对图像进行网格划分。比如,对于672×672的图像,一方面按2×2的网格切分为4张336px的输入图像送给ViT编码成特征,另一方面将图像直接resize到336px进行编码,最后将两部分特征合并输入到LLM中,这样模型具备了全局和局部的视觉推理能力。
- 指令数据混合:一方面保证指令数据具有高质量、多样性,反映真实场景的广泛用户意图;另一方面,补充文档和表格数据,提升模型的OCR和图表理解能力。
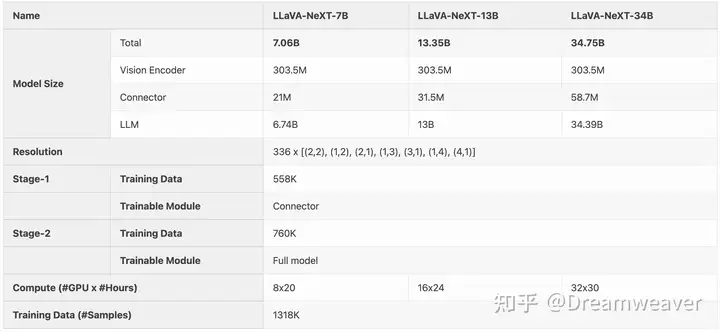
- 扩大LLM尺寸:考虑了7B、13B、34B的LLM。
24年5月,团队发布基于更强LLM的LLaVA-NeXT版本,支持LLaMA3(8B)和Qwen1.5(72B/110B)。更大的LLM提供更好的视觉世界知识和逻辑推理能力,最大的模型接近GPT-4V的性能,同时保证了训练高效性。
LLaVA-NeXT: Stronger LLMs Supercharge Multimodal Capabilities in the Wild
LLaVA-NeXT-Video
24年4月,LLaVA-NeXT-Video发布,展现出强大的zero-shot视频理解能力。LLaVA-NeXT中的高分辨率图像动态划分可以很自然地迁移到视频模态用来表示视频的多帧,使得只在图文模态上训练的LLaVA-NeXT能在视频任务上泛化。此外,推理时的长度泛化用于有效处理超出LLM最大长度的长视频输入。基于LLaVA-NeXT-Image模型,作者发布了在视频数据上监督微调的LLaVA-NeXT-Video,以及在AI反馈的监督下使用DPO偏好对齐的LLaVA-NeXT-Video-DPO。使用SGLang部署和推理,支持可扩展的大规模视频推理。可以想到,这有助于海量视频的高效文本标注,催生了未来更强大视频生成模型。
LLaVA-NeXT: A Strong Zero-shot Video Understanding Model

- AnyRes:可以将N帧视频看作{1xN}的网格,而LLM的最大长度限制了可以处理的帧数,很自然地会考虑对图像进行下采样减少每帧token数,但作者发现为保证效果仍只能处理16帧。
- 长度泛化:基于LLM的长度外推技术(RoPE的线性扩展),推理时扩展2倍,从之前的16帧扩展到56帧,大大提升了模型分析长视频序列的能力。
- 基于LLM反馈的DPO偏好优化:偏好数据由LLM生成,视频表示为详细的说明文字,带来了很大的性能增益。
- 对于视频数据的微调,作者进行了ablation study:(1) 在LLaVA-NeXT图像级指令微调后,继续在视频级指令上增量微调;(2) 在LLaVA-NeXT图像级预训练后,在图像级和视频级数据联合微调,每个batch数据包含一种类型或者混合两种类型,实验表明混合图像和视频模态数据效果最佳。
指令微调Ablation Study
团队还分享了视觉指令微调过程中除数据之外的因素的ablation study,从模型架构、视觉表征、训练策略角度进行分析。
LLaVA-NeXT: What Else Influences Visual Instruction Tuning Beyond Data?
-
模型架构:扩展LLM比扩展视觉编码器更有效,视觉输入配置(分辨率、token数)比视觉编码器大小更关键。
- 学习率:为了训练更稳定,视觉编码器的学习率通常应该比LLM学习率小10倍~5倍,更大的LLM需要更小的学习率,尽量避免loss跑飞。
- 视觉编码器:相较于模型大小,基于分辨率、token数的视觉特征支持编码更多的视觉细节,预训练数据支持编码更多的视觉知识,作用更重要。
-
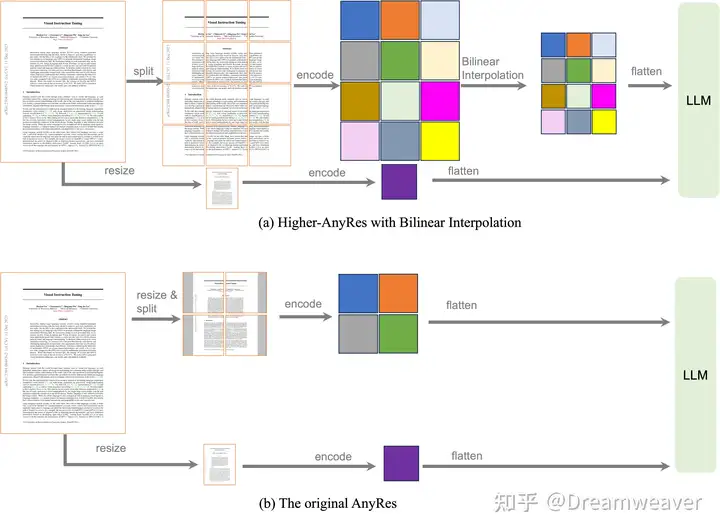
视觉表征:分辨率、特征空间视觉token数都重要,相对来说扩展分辨率更有效,建议使用AnyRes时下采样。
- 对于更高分辨率图像或者更长的视频,AnyRes需要更多的格子。比如,对于超过768×768的图像,以前的方案首先resize到768×768会导致细节丢失。这里考虑划分成更多的格子,然后对编码的特征进行双线性插值(下采样)到更小的特征,以防止视觉token数过多。
- 训练策略:在互联网级低质数据上大规模预训练后,指令微调前,增加一个阶段,使用一些高质量合成数据增强知识。
LLaVA-NeXT-Interleave
24年6月,LLaVA-NeXT-Interleave发布,提出图文交错格式可以作为通用模版统一不同的视觉模态,比如单图像(multi-patch)、多图像(multi-image)、视频(multi-frame)、3D(multi-view)。在保证LLaVA-NeXT单图像输入的性能下,可以提高其它模态任务的性能,而且在不同模态任务上具有初步的迁移能力。这种大一统的模型支持更广泛真实场景的应用,比如多页PPT的总结和问答、生成图像编辑的提示词、多文档的汇总和比较。
LLaVA-NeXT: Tackling Multi-image, Video, and 3D in Large Multimodal Models
作者在训练策略上进行了ablation study:
- 从LLaVA-NeXT单图像模型继续训练,从stage2单图像指令微调后的模型开始训练效果更好,可以继承单图像任务的指令遵循能力。
- 两种组织格式:将所有图像token放在最前面,在文本中使用特殊token指代图像 (in-the-front),将图像token放在其原来的位置,与文本交错 (interleaved)。实验表明,在训练阶段混合两种格式有助于在推理阶段这两种格式都取得更好的性能。
InternVL系列
InternVL-1.0
23年12月,上海AI Lab @OpenGVLab发布InternVL。该工作在模态对齐中视觉编码器和LLM之间在参数规模和特征表征能力上存在较大的差距,自然地提出扩大视觉端的参数量到6B (InternViT-6B),然后使用不同质量的图文数据逐渐与LLM对齐。此外,连接层的参数量也扩大了,类似Q-Former,这里设计了一个8B的语言中间件QLLaMA,使用Chinese-LLaMA的参数初始化增强其跨语言理解能力,新增96个可学习query token和cross-attention层 (1B),实现视觉和语言模态进一步对齐。
[2312.14238] InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
下图是InternVL的三阶段渐进式训练策略,训练数据质量逐渐提高,最开始使用大规模有噪的图文对进行对比预训练 (类似CLIP),接着加入冻结参数的QLLaMA连接件,只学习cross-attention,使用图文匹配/对比/生成loss (类似BLIP),最后引入LLM进行监督微调,赋予多模态对话和问答能力。
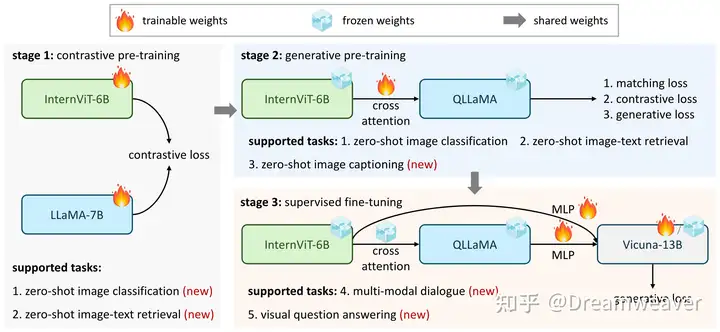
InternVL训练的多阶段性赋予其内在的多功能性,通过灵活组合不同模块,可以支持各种视觉-语言任务,如下图。

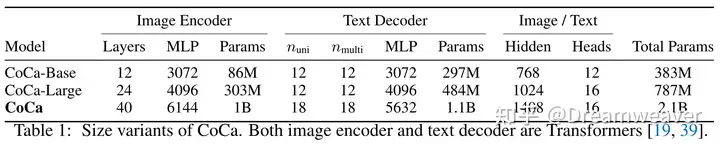
这里值得讨论的一个点在于,InternVL为了让视觉端和语言端参数量平衡,对视觉端和连接层都进行了scale up。一个很自然的问题是,视觉端真的需要这么heavy的参数量吗?因为当前最新的LLaVA-NeXT仍然使用约300M的ViT和轻量的MLP连接层,仅通过扩展LLM提升多模态任务性能。我的个人拙见是,视觉理解包括感知和推理,感知部分可能并不需要那么大的参数量,而推理部分作用于high-level的视觉特征,通过微调LLM赋予其理解推理视觉模态的能力,所以为了性能、效率和稳定性的平衡,似乎这里scale up必要性不是很强,当然这里值得深入实验的验证和讨论。看到这篇论文中的图,让我想到了22年Google的Coca论文,作者把文本解码器按层对半划开,浅层一半用于文本单模态,深层一半用于图文多模态,可以看到下图视觉端参数量占比也相当高。
[2205.01917] CoCa: Contrastive Captioners are Image-Text Foundation Models
InternVL-1.5
24年4月,InternVL-1.5发布,综合性能更强,且支持推理时高达4K的分辨率。
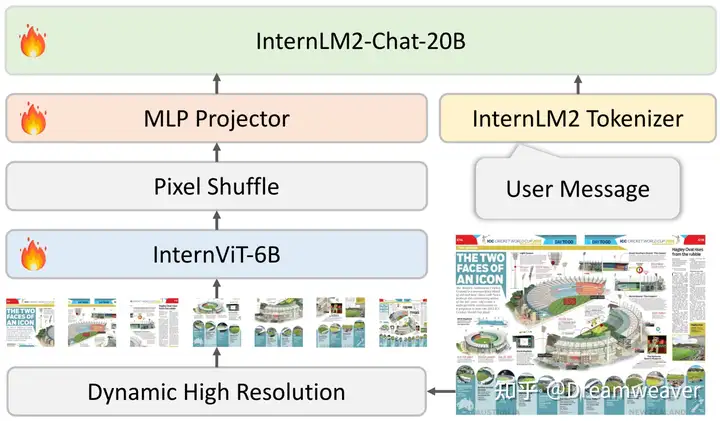
上图为模型整体架构,采用了类LLaVA的ViT+MLP+LLM范式,结合了增强的InternViT-6B-448px-V1.5和中英双语InternLM2-Chat-20B,总体参数约26B。相比于InternVL-1.0,在输入端支持了动态高分辨率,连接层改为轻量的MLP,使用pixel shuffle操作将输出的视觉token数减为1/4。训练分为两阶段,预训练阶段训练InternViT和MLP映射,随后微调整个模型。
- 这里不再使用Q-Former作为连接层的原因,可以参考作者 @Weiyun 大佬的回答:多模态大语言模型(MLLM)为什么最近的工作中用BLIP2中Q-Former结构的变少了? – Weiyun的回答 – 知乎,大致意思是说相比于MLP,Q-Former参数量大收敛更慢,数据量小的场景无法达到LLaVA-1.5这样的性能,而且提高数据量和计算量,Q-Former也没有明显的性能优势。
- 这里的pixel shuffle操作来源于16年的一篇论文,本质是对特征元素进行重排列,将 (𝐶×𝑟2,𝐻,𝑊) 的特征变换为 (𝐶,𝐻×𝑟,𝑊×𝑟) ,对特征进行了空间维度的上采样,但通道维度缩小为原来的 1/𝑟2 。这里输出的视觉token数可以理解为通道数,主要目的是通过提升特征维度换取更少的token数,从而可以支持更高的图像分辨率。这样,448×448的输入图像,patch size=14,总共有32×32=1024个token,设置上采样系数r=2,则该图像可以表示为256个token。
接着我们来看InternVL-1.5的三个重要改进:
- InternViT增强:V1.2版本去掉了模型的最后3层,将分辨率扩展为固定448×448,而V1.5进一步扩展为动态448×448,即每张训练图像可分块,每块大小为448×448,支持1~12个块。此外,还增强了数据规模、质量和多样性,提高了OCR和高分辨率处理能力。
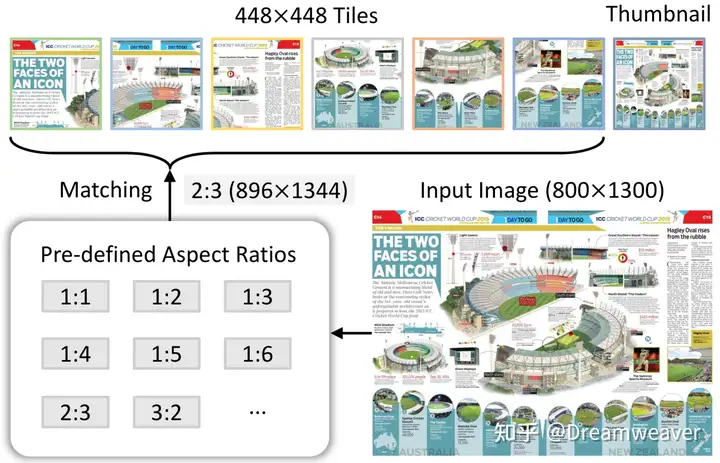
- 动态高分辨率:基于图像的分辨率和纵横比,将图像切分为448×448的分块,训练阶段最多12块,测试阶段可以外推到40块,即4K分辨率,这样模型训练和推理能适应多种分辨率和纵横比,避免了强行resize带来的失真和细节丢失。如下图,具体来说,对于一张800×1300的图像,从预定义的纵横比中匹配一个最接近的纵横比2:3,然后将图像resize到896×1344,并切分为多个448×448的图像块,再添加一个缩略视图 (直接resize到448×448) 用于图像全局理解。
- 高质量中英双语数据集:包含自然场景、图表、文档、对话等多样化的数据,借助LLM实现数据集英文到中文的转换。
此外,翻译的prompt值得我们学习:
System:
You are a translator proficient in English and {language}. Your task is to translate the following English text into {language}, focusing on a natural and fluent result that avoids “translationese.” Please consider these points:
1. Keep proper nouns, brands, and geographical names in English.
2. Retain technical terms or jargon in English, but feel free to explain in {language} if necessary.
3. Use {language} idiomatic expressions for English idioms or proverbs to ensure cultural relevance.
4. Ensure quotes or direct speech sound natural in {language}, maintaining the original’s tone.
5. For acronyms, provide the full form in {language} with the English acronym in parentheses.
User:
Text for translation: {text}
Assistant:
{translation results}作者在ablation study部分研究了更大的LLM是否需要更大的视觉编码器,实际上是针对我们上面对InternVL-1.0视觉端参数量的问题的实验。实验对比了LLaVA-NeXT和InternVL-1.2,两者都使用34B的LLM,在尽量保证对比公平的条件下,实验证明更大的视觉模型能提供模型解决多模态任务的整体性能(不过原论文好像没有给具体数据?)。团队后续也发布了蒸馏版的视觉模型InternViT-300M-448px,与LLaVA-NeXT的视觉端保持了同等规模。
MiniCPM-V系列
MiniCPM-V是 @面壁智能 发布的一系列支持高效端侧部署的多模态LLM。
MiniCPM-V 2.0
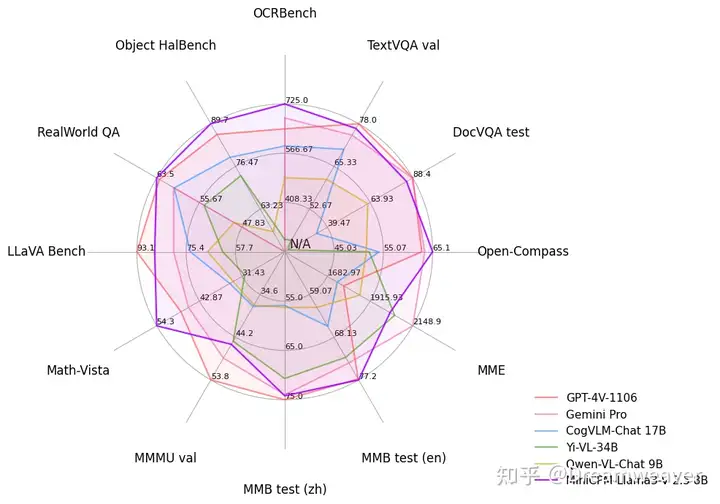
24年4月,MiniCPM-V 2.0发布,仅有2.8B参数,整体性能超过了Yi-VL 34B、CogVLM-Chat 17B、Qwen-VL-Chat 10B等更大的开源模型,OCR能力突出,支持中英双语对话,部分指标接近Gemini Pro。
视觉编码器使用SigLIP SO400M/14-384px,LLM使用MiniCPM-2.4B,连接层使用Flamingo中的Perceiver Resampler (类似Q-Former使用可学习query提取显著视觉信息,但不以输入文本为条件)。基于自研的RLHF-V实现可信行为对齐,在缓解多模态幻觉问题上接近GPT-4V。基于自研的LLaVA-UHD支持高达1344×1344的分辨率和任意纵横比输入。基于自研的VisCPM实现跨语言的多模态能力泛化,进而有良好的中英双语能力。此外,该模型在端侧部署内存开销较小、速度较快,即便是处理高分辨率的图像。官方还提供了安卓端部署的mlc-MiniCPM示例。
MiniCPM-Llama3-V 2.5
24年5月,MiniCPM-Llama3-V 2.5发布,总共8B参数,整体性能超过了GPT-4V-1106、Gemini Pro、Qwen-VL-Max、Claude 3等闭源模型,OCR和指令遵循能力进一步增强 (增强了全文本OCR提取、表格到Markdown转换等功能),支持超过30种语言对话,在量化、编译优化、高效推理等加持下,同样可以在端侧高效部署。
在MiniCPM-V 2.0基础上,LLM替换为Llama3-8B-Instruct,基于更新的RLAIF-V进一步降低幻觉率。当前,官方支持了llama.cpp和ollama的高效CPU推理、GGUF 16-bit量化、LoRA微调等实用功能。
VILA1.5
24年5月,NVIDIA发布VILA1.5,提供视频理解能力,开源了3B/8B/13B/40B的模型,位于当前开源榜单MMMU和Video-MME前列。VILA详见我的上篇文章,这里简单回顾一下:VILA在大规模交错图文数据上预训练,从而具有多图理解能力,作者通过实验发现:(1) 图文交错排布比较关键;(2) 交错图文预训练过程中微调LLM能赋予其上下文学习的能力;(3) 混合只有文本的指令数据有助于提升性能;(4) 压缩视觉token可以扩展视频帧数。
CogVLM2
24年5月,智谱 @GLM大模型 发布CogVLM2,随后发布了GLM-4V。CogVLM2基于Llama3-8B-Instruct,支持8K上下文、1344×1344分辨率、中英双语对话。GLM-4V-9B替换为GLM-4-9B语言模型,采取同样的数据和训练策略,去除CogVLM原有的视觉专家,将模型大小减为13B。CogVLM和CogAgent详见我的上篇文章。
Cambrian-1
24年6月,LeCun&谢赛宁团队发布Cambrian-1,关注以视觉为中心的多模态LLM,开源了8B/13B/34B的模型。当前多模态LLM仍存在较大的视觉缺陷,需要增强视觉表征以更好地和语言模态交互,赋予模型在真实场景更强的感知定位能力。这项研究的一大意义在于影响多模态LLM的工作开始重视视觉表征质量的提升,而非一直scale up LLM。
[2406.16860] Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
如上图,该工作围绕多模态LLM的5个核心设计要素展开研究,分别是:视觉表征、连接器设计、指令微调数据、指令微调策略、评估基准。
- 视觉表征
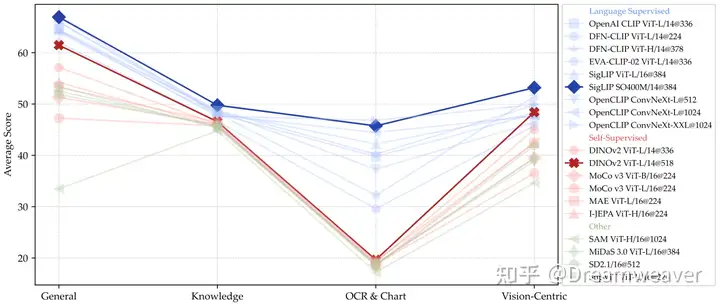
作者评估了多种视觉编码器及其组合,下图表明以语言监督的CLIP模型优势较强,但自监督方法在提供充足数据和适当微调的情况下性能也能接近。而且,结合多种类型的视觉编码器有助于提升多模态LLM的性能,尤其是以视觉为中心的任务。注意到,高分辨率的编码器大大增强了图表和以视觉为中心任务的性能,而基于ConvNet的架构适合处理这类任务。
2. 连接器设计
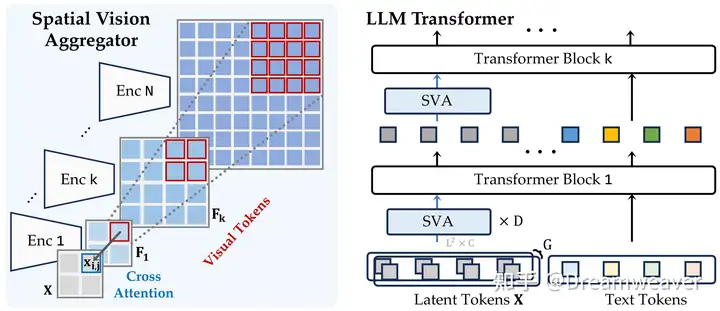
提出Spatial Vision Aggregator (SVA),一个动态的、具备空间感知的连接器,以将 (来自多个视觉编码器的) 视觉特征与LLM深度融合。如下图,该方法设置一些可学习的latent query tokens,通过cross-attention与多个视觉特征交互 (视觉特征作为key/value)。SVA的设计有两点要素:(1) 通过显式定义每个query token对应的视觉特征图子区域,引入空间inductive bias,便于模型在处理视觉信息时保留对空间结构的理解,更准确地定位和整合局部特征;(2) 在LLM的多层聚合视觉特征,让模型在不同层级特征上反复利用视觉信息,增强模型对视觉内容的深入推理能力。该方法可以有效减少需要的视觉token数,例如相比于Mini-Gemini和LLaVA-NeXT,Cambrian-1的视觉token数是其20%。
3. 指令微调数据
作者发布了指令微调数据集Cambrian-10M,综合了OCR、通用VQA、纯语言等指令数据,还筛选了质量更高的7M版本。不同类型的视觉指令数据能赋予模型不同的能力,因此数据配比的平衡性也很关键,实验结果表明,平衡OCR、通用数据和语言数据的比例很重要。此外,在实验中作者发现,训练好的多模态LLM可能在基准测试上指标表现好,但实际对话能力弱,回复简短。因此,作者在训练期间引入了额外的系统提示,鼓励模型输出更长的回答和思维链推理,增强数学推理等任务的表现。
4. 指令微调策略
作者遵循LLaVA的两阶段训练策略,先使用适配数据只微调中间的MLP连接层,再打开LLM和连接器微调。结果表明,第一阶段对连接器的预训练可以提高性能,而使用更多的适配数据可以进一步增强。此外,作者对比了是否微调视觉编码器带来的性能影响,表明微调视觉编码器能增强性能,尤其对自监督预训练的视觉编码器 (如DINO v2、MoCo v3、MAE等),在以视觉为中心的测试上提升明显。
5. 以视觉为中心的基准CV-Bench
现有多数benchmark无法正确评估模型的视觉感知定位能力,而且相应的样本数量有限。CV-Bench重新利用现有视觉benchmark中的样本,包含2638个以视觉为中心的VQA问题,涉及2D的空间位置关系和物体计数、3D的深度次序和相对距离。
最后,让我们共同期待我国的AGI基础模型不断取得新的突破,引领世界潮流!
