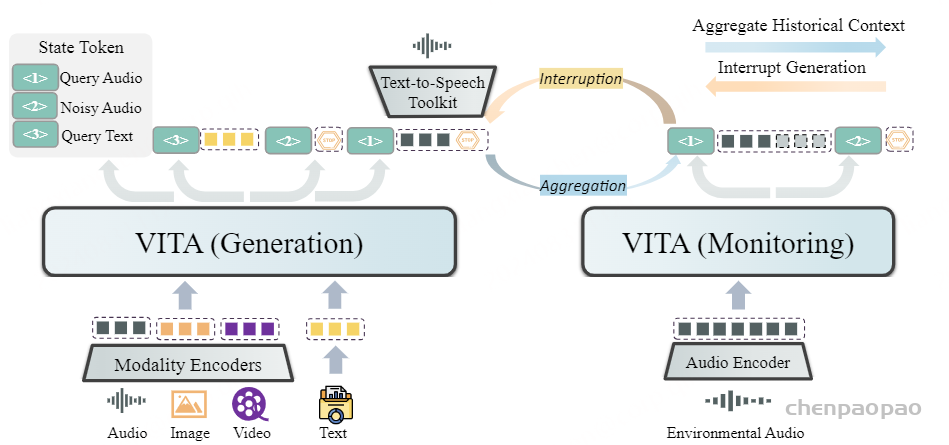
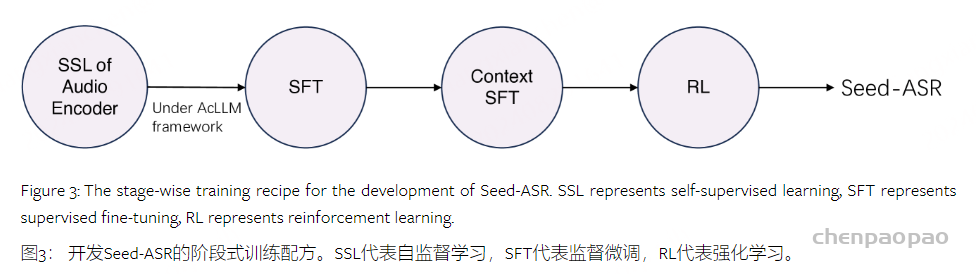
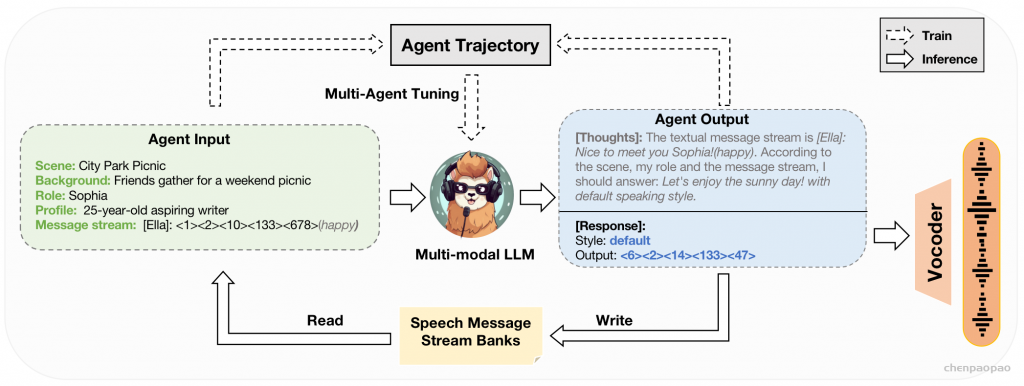
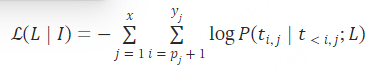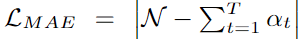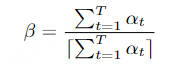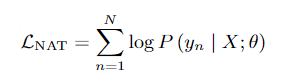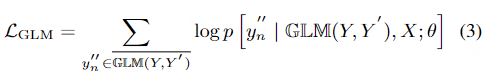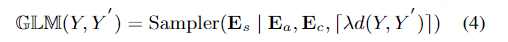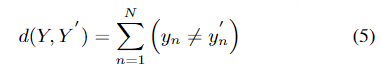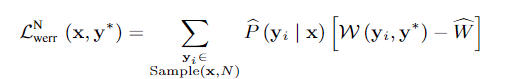为实现这一目标,我们提出了双工部署框架。如上图所示,两个 VITA 模型同时部署。在典型条件下,生成模型负责回答用户查询。同时,监控模型在生成过程中检测环境声音。它忽略非查询用户声音(即噪声音频),但在检测到查询音频时会停止生成模型的进度。监控模型随后整合历史上下文,并对最新的用户查询做出回应。这时,生成模型和监控模型的身份会发生转变。
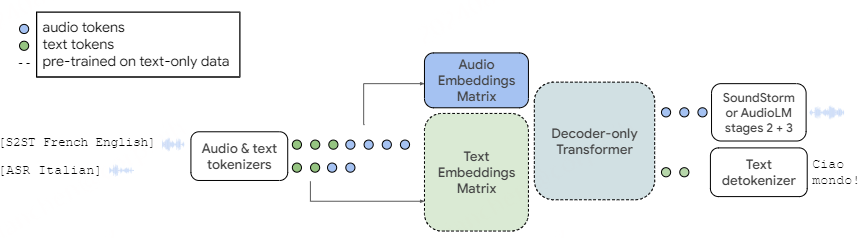
在Transformer解码器中,输入预处理后模型的第一层是标记嵌入矩阵 𝐄 ,它将整数值标记映射到密集嵌入;给定 t 标记的词汇表和大小为 m 的嵌入, 𝐄 是 t×m 矩阵,其第 i 行给出第 i 标记的嵌入。 另一个嵌入矩阵 𝐄′ 出现在最后的softmax层中,用于计算每个位置上所有标记的logit;它是一个 m×t 矩阵,与模型的 m 维输出相乘,以获得logit的 t 维向量,每个标记一个。 在PaLM架构中,这些矩阵具有共享变量,因此一个是另一个的转置,即 𝐄′=𝐄⊺ 。
解码器架构的其余部分对建模的令牌数量完全无关。 因此,我们只需要做一个小的修改,将纯文本模型转换为同时对文本和音频进行建模的模型:我们将嵌入矩阵 𝐄 的大小扩展为大小 (t+a)×m ,其中 a 是音频令牌的数量( 𝐄′=𝐄⊺ 的大小相应地改变)。
为了利用预训练的文本模型,我们通过向嵌入矩阵 𝐄 添加 a 新行来更改现有的模型检查点。实现细节是前 t 令牌(从零到 t )对应于SentencePiece文本令牌,而接下来的 a 令牌(从 t 到 t+a )表示音频令牌。 虽然我们可以重用预训练模型的文本嵌入,但新的音频嵌入是新初始化的,必须经过训练。我们发现有必要训练所有模型参数,而不是保持以前的权重固定。我们使用混合语音和文本任务进行训练。
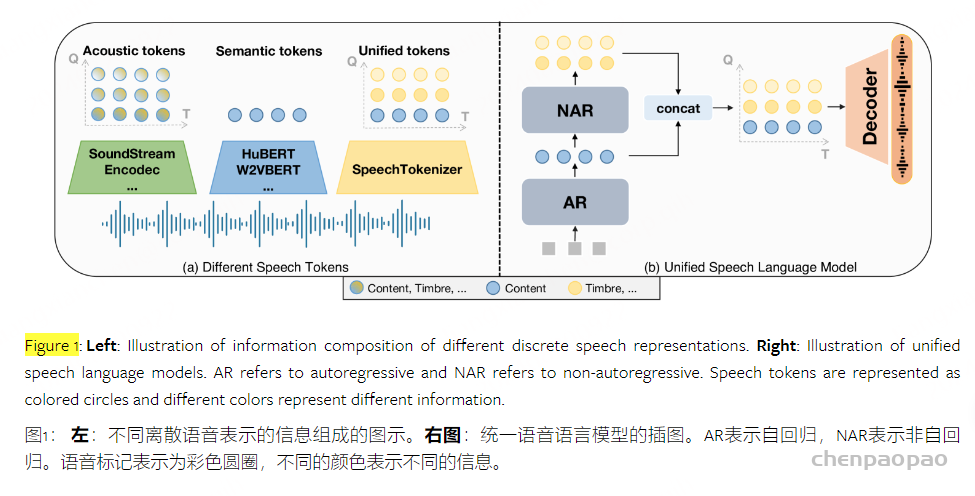
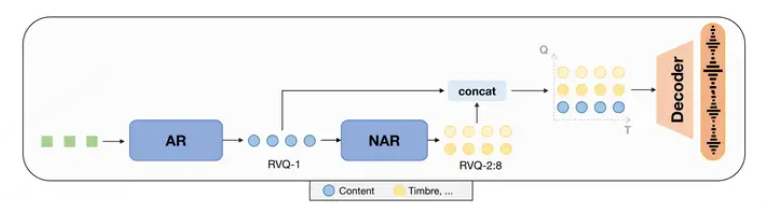
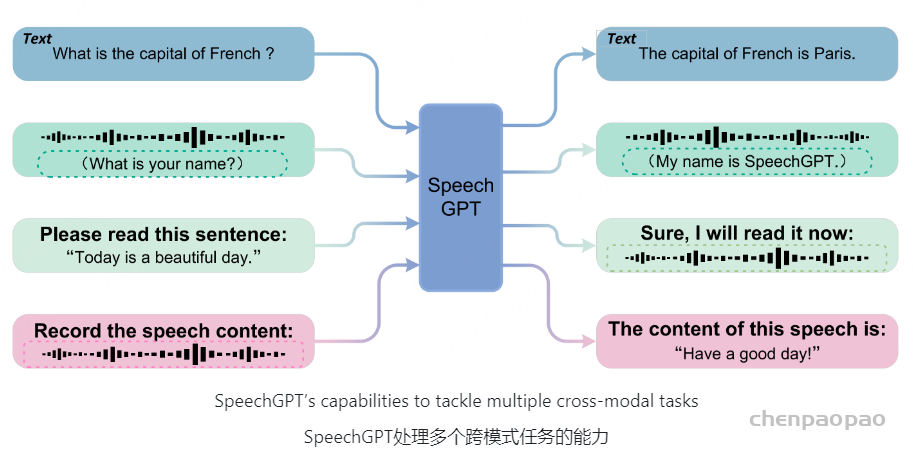
Semantic language models: 基于semantic token的自回归模型,常外接一个unit-vocoder来恢复语音,比如SpeechGPT。这类模型虽然可以完成一些语音内容相关的任务,但是它们产生的音质比较一般,并且无法完成一些副语言学相关的任务,比如音色转换等。
Acoustic language models: 基于acoustic token的speech LM,比如VALL-E。这类模型产生的语音音质比较好,并且可以较好地完成一些比如zero-shot TTS的任务,但是会存在内容不准确的问题。
Hierarchical speech language models: 这类模型由Semantic language models和Acoustic language models 级联而成,既可以产生比较精确的内容,也可以产生较好的音质,比如AudioPaLM。但是这类模型,建模阶段太多,较为复杂,需要两种tokenizer的参与;而且在semantic token和acoustic token之间其实存在有很大的信息冗余,会带来一些不必要的建模难度。
[
{
"prefix": "You are an AI assistant whose name is SpeechGPT.\n- SpeechGPT is a intrinsic cross-modal conversational language model that is developed by Fudan University. SpeechGPT can understand and communicate fluently with human through speech or text chosen by the user.\n- It can perceive cross-modal inputs and generate cross-modal outputs.\n",
"plain_text": "[Human]: Try to speak out this sentence, please. This is input: The alchemist rode in front, with the falcon on his shoulder.<eoh> [SpeechGPT]: <sosp><661><588><604><157><596><499><596><106><596><189><63><189><665><991><162><202><393><946><327><905><907><597><660><351><557><794><788><59><754><12><977><877><333><873><835><67><940><118><686><613><169><72><644><553><535><935><101><741><384><173><894><787><380><787><196><555><721><944><250><56><812><222><915><143><390><479><330><435><647><246><650><816><325><506><686><208><613><417><755><193><411><452><111><735><6><735><63><665><644><991><535><271><333><196><918><29><202><393><946><734><390><479><330><776><167><761><907><597><660><351><557><794><75><788><15><366><896><627><168><654><659><177><183><609><710><187><493><361><470><821><59><56><198><912><742><840><431><531><76><668><576><803><791><380><660><325><801><549><366><377><164><309><584><605><193><71><39><eosp><eoa> "
},
]
[
{
"prefix": "You are an AI assistant whose name is SpeechGPT.\n- SpeechGPT is a intrinsic cross-modal conversational language model that is developed by Fudan University. SpeechGPT can understand and communicate fluently with human through speech or text chosen by the user.\n- It can perceive cross-modal inputs and generate cross-modal outputs.\n",
"plain_text": "[Human]: <sosp><661><987><511><732><951><997><111><982><189><63><665><991><535><101><741><173><945><944><503><641><124><565><734><870><290><978><833><238><761><907><430><901><185><403><557><244><583><788><663><969><896><627><143><515><663><969><660><691><251><412><260><41><740><677><253><380><382><268><506><876><417><755><16><819><80><651><80><651><80><987><588><eosp><eoh>. [SpeechGPT]: What is a bad term for poop?; [ta] A bad term for poop is excrement. It is usually used as a polite way to refer to fecal waste.; [ua] <sosp><497><63><264><644><710><823><565><577><154><331><384><173><945><29><244><326><583><728><576><663><969><896><627><143><38><515><663><24><382><251><676><412><260><41><740><677><253><382><268><876><233><878><609><389><771><865><641><124><878><609><423><384><879><487><219><522><589><337><126><119><663><748><12><671><877><377><385><902><819><619><842><419><997><829><111><666><42><277><63><665><644><389><771><685><437><641><124><258><436><139><340><11><59><518><56><948><86><258><436><139><340><347><376><940><118><944><878><173><641><124><362><734><179><961><931><878><609><423><384><879><219><522><866><337><243><935><101><741><822><89><194><630><86><555><105><79><868><220><156><824><998><870><390><422><330><776><663><969><523><105><79><799><220><357><390><479><422><330><776><485><165><86><501><119><716><205><521><787><935><101><741><89><194><664><835><67><940><118><613><417><755><902><415><772><497><eosp><eoa>."
},
]
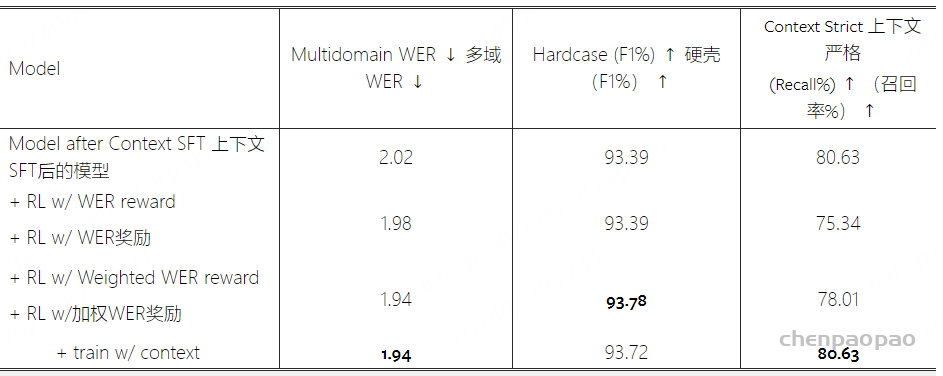
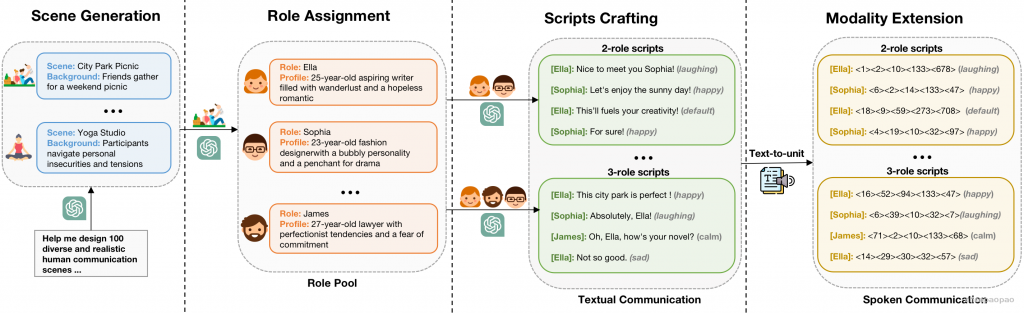
step3 数据构造Instruction Formatting :对于离散单元序列 U 及其相关联的转录 T ,我们基于概率 p 来确定它将被用于构造ASR任务还是TTS任务。随后,我们从step2相应的任务描述中随机选择一个描述 D 。表示为 (D,U,T) 。在此之后,使用模板[Human]:{D}。输入:{U}<eoh>。[SpeechGPT]:{T}<eos>。. 为了支持多轮对话,组装的指令以多轮对话的形式连接,遵守模型的最大输入长度。
LLM:采用Meta AI LLaMA(Touvron 等人,2023)模型作为我们的大型语言模型。LLaMA包括嵌入层、多个Transformer块和LM头层。LLaMA中的参数总数范围从7 B到65 B。从1.0万亿个令牌的广泛训练数据集中,LLaMA在各种NLP基准测试中与更大的175 B GPT-3相比表现出了竞争力。
Unit Vocoder:训练了一个多说话人 unit HiFi-GAN来解码语音信号, 离散表示。 HiFi-GAN架构由生成器 𝐆 和多个鉴别器 𝐃 组成。该生成器使用查找表(LUT)来嵌入离散表示,并且嵌入序列由一系列由转置卷积和具有扩张层的残差块组成的块进行上采样。 扬声器嵌入被连接到上采样序列中的每个帧。 该滤波器具有多周期鉴别器(MPD)和多尺度鉴别器(MSD)。
ASR:
You are asked to come up with a set of 100 diverse task instructions about automatic speech
recognition, which is about recognizing speech.
Here are the requirements:
1. These instructions should be to instruct someone to recognize the content of the following
speech.
2. Try not to repeat the verb for each instruction to maximize diversity.
3. The language used for instruction also should be diverse. For example, you should
combine questions with imperative instructions.
4. The type of instructions should be diverse.
5. The instructions should be in English.
6. The instructions should be 1 to 2 sentences long. Either an imperative sentence or a
question is permitted.
List of 100 tasks:
TTS:
You are asked to come up with a set of 100 diverse task instructions about text to speech,
which is about recognizing speech .
Here are the requirements:
1. These instructions should be to instruct someone to recognize the content of the following
speech.
2. Try not to repeat the verb for each instruction to maximize diversity.
3. The language used for instruction also should be diverse. For example, you should
combine questions with imperative instructions.
4. The type of instructions should be diverse.
5. The instructions should be in English.
6. The instructions should be 1 to 2 sentences long. Either an imperative sentence or a
question is permitted.
List of 100 tasks:
附录B:Examples of Task Description【gpt生成的一些例子】
ASR:
Begin by converting the spoken words into written text.
Can you transcribe the speech into a written format?
Focus on translating the audible content into text.
Transcribe the speech by carefully listening to it.
Would you kindly write down the content of the speech?
Analyze the speech and create a written transcription.
Engage with the speech to produce a text-based version.
Can you document the speech in written form?
Transform the spoken words into text accurately.
How about putting the speech’s content into writing?
TTS:
Can you please read this sentence out loud?
Recite the following words as if you were speaking normally.
Project your voice to clearly articulate this statement.
Would you mind speaking these words as naturally as possible?
Whisper the given sentence softly.
Enunciate each word in this sentence with precision. How would you express this sentence in
a conversational tone?
Could you please relay the message below verbally?
Emphasize the key points while reading the sentence.
Sing the text provided in a melodic voice.
附录C: Chain-of-Modality Instructions Templates
Speech Instruction-Speech Response:
[Human]: This is a speech instruction: {SpeechI}. And your response should be speech.
You can do it step by step. You can first transcribe the instruction and get the text Instruction.
Then you can think about the instruction and get the text response. Last, you should speak the
response aloud <eoh>. [SpeechGPT]: [tq] {TextI}; [ta] {TextR}; [ua] {SpeechR}<eoa>.
Speech Instruction-Text Response:
[Human]: This is a speech instruction: {SpeechI}. And your response should be text. You
can do it step by step. You can first transcribe the instruction and get the text instruction.
Then you can think about the instruction and get the text response. <eoh>. [SpeechGPT]:
[tq] {TextI}; [ta] {TextR}<eoa>.
Text Instruction-Speech Response:
[Human]: This is a text instruction: {TextI}. And your response should be speech. You can
do it step by step. You can think about the instruction and get the text response. Then you
should speak the response aloud <eoh>. [SpeechGPT]: [ta] {TextR}; [ua] {SpeechR}<eoa>.
Text Instruction-Text Response:
[Human]: This is a text instruction: {TextI}. And your response should be text. You can
think about the instruction and get the text response. [SpeechGPT]: [ta] {TextR}<eoa>.
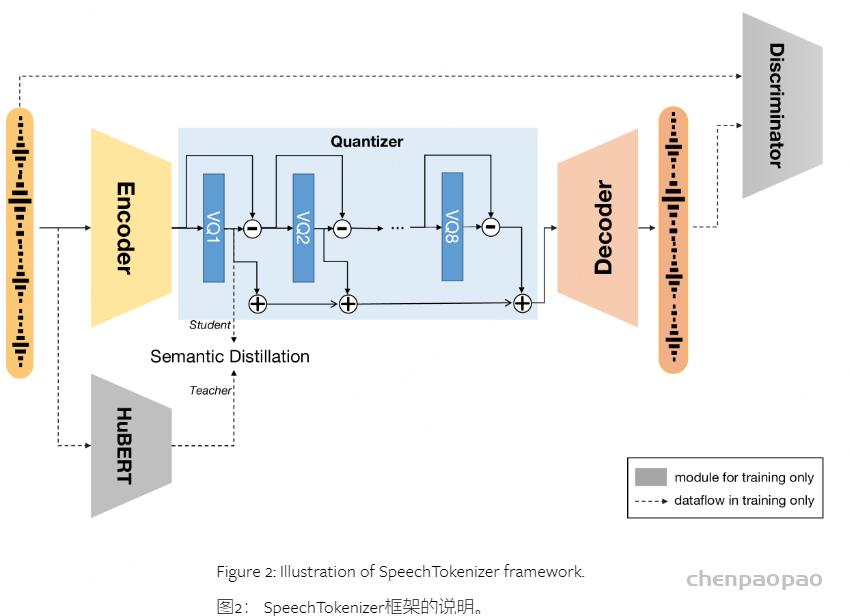
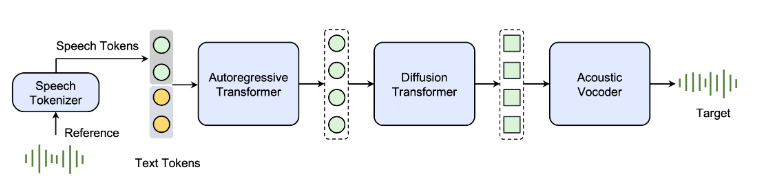
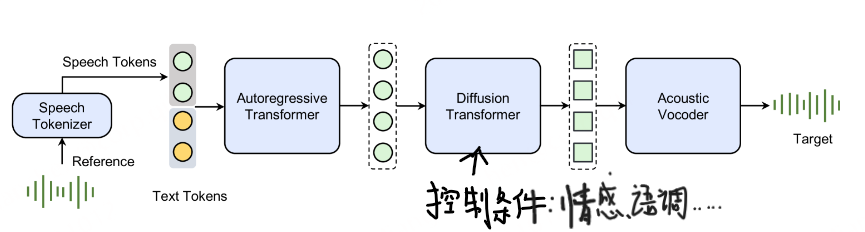
首先,语音标记器将语音信号转换为一系列语音标记,然后使用类似于 BASE TTS所描述的方法对标记语言模型进行训练。我们研究了连续和离散语音标记器,发现标记器的设计对整个系统的性能至关重要。语言模型是在成对的文本序列和语音标记上训练的。在推理过程中,模型自回归地生成语音标记。请注意,在本技术报告中,我们专注于语音生成任务,因此文本序列的损失是被掩蔽的。这些生成的标记随后由扩散模型处理,以增强声学细节。然后输出通过声学声码器处理,以预测最终的波形。
具体流程如下: 首先语音tokenizer将语音信号转换为语音token序列,在该语音token序列上训练token语言模型,我们研究了连续和离散语音token器,发现 tokenizer 的设计对整个系统的性能至关重要。语言模型在文本和语音token的配对序列上训练。在推理过程中,它自回归地生成语音token。这些生成的令牌,然后用扩散模型进行处理,以增强声学细节。输出被传递到声学声码器以预测最终波形。 声学声码器使用类似于Kumar等人【High-Fidelity Audio Compression with Improved RVQGAN】,并单独进行训练。
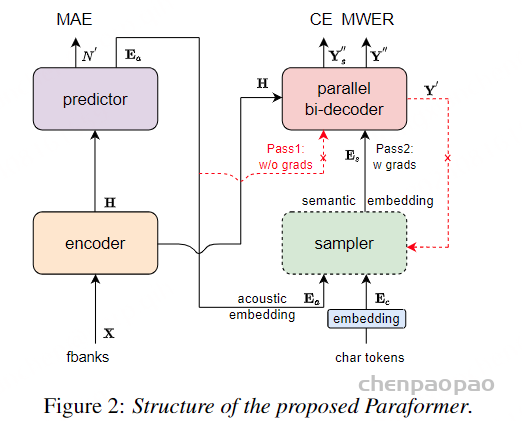
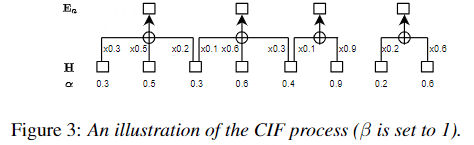
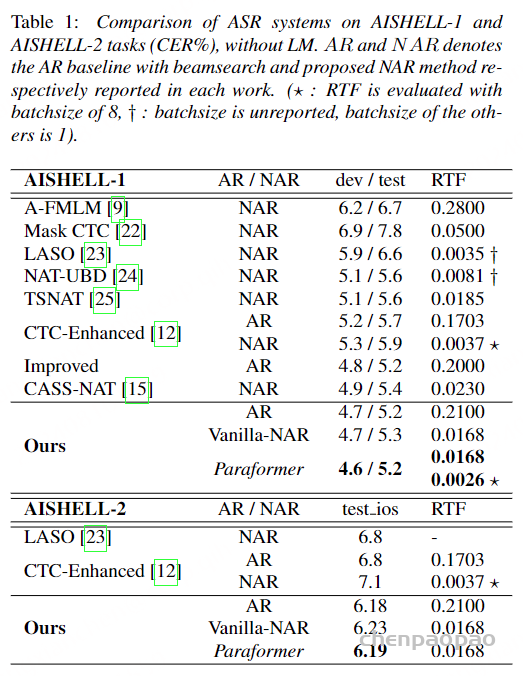
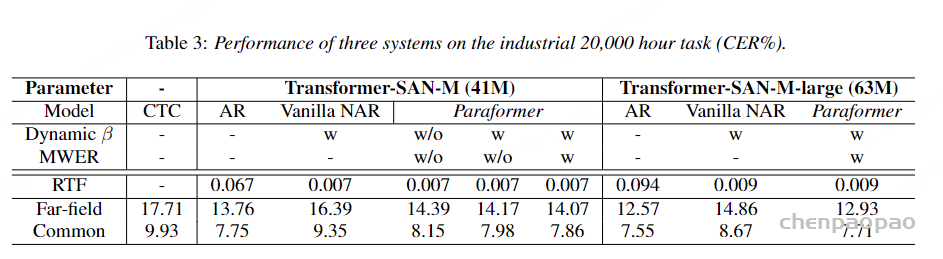
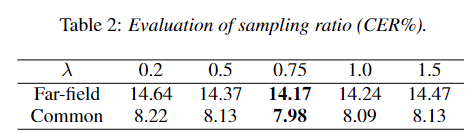
文章提出了一个又快又准的并行transformer模型,可以克服上面提到的两个挑战。首先,不像前面的基于CTC的工作,作者提出了使用基于CIF【continuous integrate-and-fire】的predictor网络评估目标长度并产生隐变量。对于第二个挑战,作者设计了基于GLM【glancing language mode】的sampler模块增强非自回归解码器对输出上下文的建模能力。这个工作受到了机器翻译工作的启发。作者另外设计了一个包含负例的策略,利用MWER损失指导模型学习提升模型性能。
直接训练完全并行生成来学习目标语句中词之间的依赖关系对模型并不友好。一种更为简单有效的依赖关系学习方式是根据部分输入词预测其余目标词。但是这种学习方式需要部分目标词作为输入,不符合非自回归模型并行生成的要求。作者观察到随着模型自身更好地学习到词之间的依赖关系,模型对于依赖关系的学习可以逐渐摆脱使用目标语句部分词作为输入的需求。基于以上观察,Glancing Transformer(GLAT)利用了一种 glancing language model 的方法,通过渐进学习的方式进行词之间依赖关系的建模。在渐进学习的过程中,模型会先学习并行输出一些较为简单的语句片段,然后逐渐学习整句话的单步并行生成。
[18] L. Dong and B. Xu, “CIF: Continuous integrate-and-fire for end-to-end speech recognition,” in ICASSP 2020-2020 IEEE Interna-tional Conference on Acoustics, Speech and Signal Processing(ICASSP). IEEE, 2020, pp. 6079–6083. [19] L. Qian, H. Zhou, Y. Bao, M. Wang, L. Qiu, W. Zhang, Y. Yu,and L. Li, “Glancing transformer for non-autoregressive neural machine translation,” arXiv preprint arXiv:2008.07905, 2020. [20] R. Prabhavalkar, T. N. Sainath, Y. Wu, P. Nguyen, Z. Chen, C.-C. Chiu, and A. Kannan, “Minimum word error rate training for attention-based sequence-to-sequence models,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 4839–4843
GGUF是一种量化方法,是LLM库的C++复制品,支持多种LLM,如LLaMA系列和Falcon等。它允许用户在 CPU 上运行 LLM,同时将其部分层次转移到 GPU 上以加速运行。尽管使用 CPU 通常比使用 GPU 进行推理要慢,但对于在 CPU 或 Apple 设备上运行模型的人来说,这是一种非常好的格式。特别是我们看到出现了更小、更强大的模型,如 Mistral 7B,GGUF 格式可能会成为一种常见的格式它提供了从2到8位精度的不同级别的量化。我们可以获取原始的LLaMA模型,将其转换为GGUF格式,最后将GGUF格式量化为较低的精度。