开源:https://github.com/0nutation/SpeechGPT SpeechGPT (2023/05) - Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities SpeechGPT(2023/05)-为大型语言模型提供内在的跨模态会话能力 SpeechGPT-Gen (2024/01) - Scaling Chain-of-Information Speech Generation SpeechGPT-Gen(2024/01)-缩放信息链语音生成 SpeechAgents: Human-Communication Simulation with Multi-Modal Multi-Agent Systems SpeechAgents:多模态多智能体系统的人机交互仿真 SpeechAlign: Aligning Speech Generation to Human Preferences SpeechAlign: 使语音生成与人类偏好保持一致 paper: https://arxiv.org/abs/2401.03945 [SpeechAgents] https://arxiv.org/abs/2305.11000 [SpeechGPT] https://arxiv.org/abs/2401.13527 [SpeechGPT-Gen/SpeechGPT2] https://arxiv.org/abs/2404.05600 [SpeechAlign]
这算是复旦大学邱锡鹏组在这个领域一个成系列的工作,我们一个一个来看。SpeechGPT是一种基于深度学习的语言模型,它能够理解和生成自然语言。SpeechGPT是一种新型的大型语言模型,它不仅能够理解语音和文本,还能够在这两者之间自如转换。简单来说,它能够感知和表达情感,并根据上下文和人类指令提供多种风格的语音响应。无论是说唱、戏剧、机器人、搞笑还是低语,SpeechGPT都能够根据需要生成相应风格的语音。
SpeechGPT
SpeechGPT做的是兼具语音理解能力和语音生成能力的多模态模型。在模型的训练上,SpeechGPT大幅度向LLM看齐,使用了三段式的训练方法:第一阶段先做模态适应的预训练,其实就是拿ASR的语音数据来做预训练;第二阶段和第三阶段都是指令微调,不过根据指令模态的不同,细分为了跨模态的指令微调和模态链指令微调。指令微调的数据集都是来自ASR数据集。描述任务需求的指令由GPT-4生成。
在我看来,这个工作还是相当偏学术化的作品,文中有不少点都有值得商榷的地方:第一,语音的离散化仅仅用了HuBERT,模型只能看到语音的语义特征,这对模型合成语音的音质和表现力有非常大的影响,demo的语音也验证了我的判断;第二,指令微调数据集的构造上有问题。他们用的是ASR数据集,其实更好的选择应该是TTS数据集,可惜高质量的TTS数据集实在是太少了。ASR数据集中的文本和语音可能并不是严格对齐的,GPT-4产生的meta-prompt和语音本身的特征也有可能是对不上的,比如prompt要求大声朗读,但语音本身可能是特定低沉的。meta-prompt本身就无法做到足够复杂丰富,不能描述到语音的一些细粒度信息。
这一部分,最好要有像诸如SALMONN这样的多模态语音理解模型的介入,像DALLE3一样丰富指令的多样性。至于语音方面,可以考虑引入zero-shot的语音合成模型或者变声模型来做合成数据。第三,文中的训练方法也没有与人类偏好做对齐。
这项技术的核心在于将连续的语音信号离散化,使其能够与文本模态统一,从而让模型具备感知和生成语音的能力。

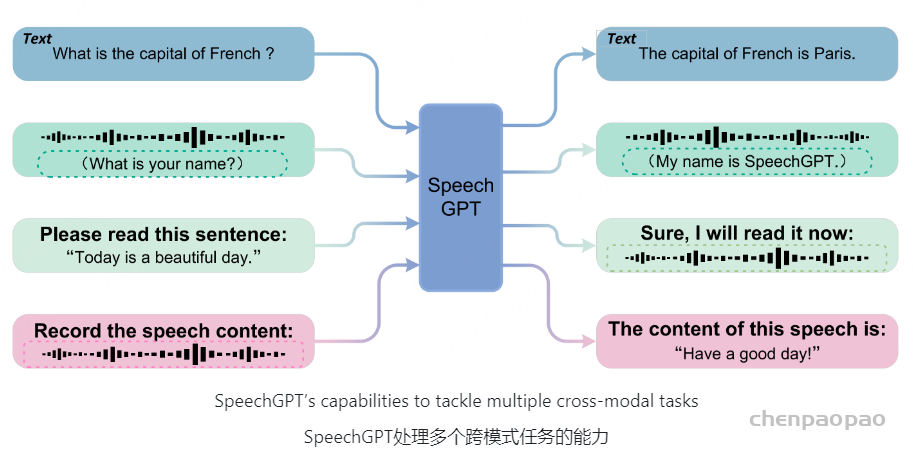
SpeechGPT是一种大型语言模型,具有内在的跨模态会话能力,能够按照人类指令感知和生成多模型内容。本文首先利用离散语音表示构造了一个大规模的跨模态语音指令集SpeechInstruct。此外,我们采用了一个三阶段的训练策略,包括模态适应预训练,跨模态指令微调,和链的模态指令微调。实验结果表明,SpeechGPT具有良好的多模态人机交互能力,并能在一个模型中处理多种模态。
模型训练过程:
第一阶段,使用LLaMA-7 B初始化,并在LibriLight语音单元上进一步预训练。第二阶段,使用上一步预训练的模型进行初始化,并在SpeechInstruct跨模态指令集上进一步微调。这是一个强大的基础模型,可以对齐语音和文本。第三阶段,在SpeechInstruct模态链指令集上进一步进行lora-finetuning。
数据集格式:
SpeechInstruct-cross-modal:跨模态指令集,mHuBERT从大规模英语ASR数据集中标记了大约900万个单元文本数据对。数据格式:
[
{
"prefix": "You are an AI assistant whose name is SpeechGPT.\n- SpeechGPT is a intrinsic cross-modal conversational language model that is developed by Fudan University. SpeechGPT can understand and communicate fluently with human through speech or text chosen by the user.\n- It can perceive cross-modal inputs and generate cross-modal outputs.\n",
"plain_text": "[Human]: Try to speak out this sentence, please. This is input: The alchemist rode in front, with the falcon on his shoulder.<eoh> [SpeechGPT]: <sosp><661><588><604><157><596><499><596><106><596><189><63><189><665><991><162><202><393><946><327><905><907><597><660><351><557><794><788><59><754><12><977><877><333><873><835><67><940><118><686><613><169><72><644><553><535><935><101><741><384><173><894><787><380><787><196><555><721><944><250><56><812><222><915><143><390><479><330><435><647><246><650><816><325><506><686><208><613><417><755><193><411><452><111><735><6><735><63><665><644><991><535><271><333><196><918><29><202><393><946><734><390><479><330><776><167><761><907><597><660><351><557><794><75><788><15><366><896><627><168><654><659><177><183><609><710><187><493><361><470><821><59><56><198><912><742><840><431><531><76><668><576><803><791><380><660><325><801><549><366><377><164><309><584><605><193><71><39><eosp><eoa> "
},
]SpeechInstruction-chain-of-modality:四种输入输出格式的思想链样式指令,即Speech Instruction-Speech Response、Speech Instruction-Text Response、Text Instruction-Speech Response和Text Instruction-Text Response。
[
{
"prefix": "You are an AI assistant whose name is SpeechGPT.\n- SpeechGPT is a intrinsic cross-modal conversational language model that is developed by Fudan University. SpeechGPT can understand and communicate fluently with human through speech or text chosen by the user.\n- It can perceive cross-modal inputs and generate cross-modal outputs.\n",
"plain_text": "[Human]: <sosp><661><987><511><732><951><997><111><982><189><63><665><991><535><101><741><173><945><944><503><641><124><565><734><870><290><978><833><238><761><907><430><901><185><403><557><244><583><788><663><969><896><627><143><515><663><969><660><691><251><412><260><41><740><677><253><380><382><268><506><876><417><755><16><819><80><651><80><651><80><987><588><eosp><eoh>. [SpeechGPT]: What is a bad term for poop?; [ta] A bad term for poop is excrement. It is usually used as a polite way to refer to fecal waste.; [ua] <sosp><497><63><264><644><710><823><565><577><154><331><384><173><945><29><244><326><583><728><576><663><969><896><627><143><38><515><663><24><382><251><676><412><260><41><740><677><253><382><268><876><233><878><609><389><771><865><641><124><878><609><423><384><879><487><219><522><589><337><126><119><663><748><12><671><877><377><385><902><819><619><842><419><997><829><111><666><42><277><63><665><644><389><771><685><437><641><124><258><436><139><340><11><59><518><56><948><86><258><436><139><340><347><376><940><118><944><878><173><641><124><362><734><179><961><931><878><609><423><384><879><219><522><866><337><243><935><101><741><822><89><194><630><86><555><105><79><868><220><156><824><998><870><390><422><330><776><663><969><523><105><79><799><220><357><390><479><422><330><776><485><165><86><501><119><716><205><521><787><935><101><741><89><194><664><835><67><940><118><613><417><755><902><415><772><497><eosp><eoa>."
},
]Introduction
在本文中,我们提出了SpeechGPT,一个大型的语言模型,具有内在的跨模态会话能力,能够感知和生成多模型内容。我们使用自监督训练的语音模型进行语音离散化,以统一语音和文本之间的模态。然后,离散的语音token扩展到LLM的词汇表中,从而赋予模型固有的感知和生成语音的能力。
为了使模型具有处理多模态指令的能力,我们构建了第一个语音-文本跨模态指令遵循数据集SpeechInstruct。具体地,我们将语音离散化为离散单元(Hsu 等人,2021),并基于现有的ASR数据集构建跨模态单元文本对。同时,我们使用GPT-4为不同的任务构建了数百条指令,以模拟实际的用户指令,如附录B所示。此外,为了进一步增强模型的跨模态能力,我们设计了模态链指令数据,即,该模型接收语音命令,以文本形式思考该过程,然后以语音形式输出响应。
为了更好地进行跨模态迁移和有效的训练,SpeechGPT经历了三个阶段的训练过程:模态适应预训练,跨模态指令微调和模态链指令微调。第一阶段使语音理解与离散语音单元连续任务的SpeechGPT。第二阶段采用SpeechInstruct来提高模型的跨模态能力。第三阶段利用参数有效的LoRA(Hu 等人,2021年)进行微调,以进一步调整模式。
SpeechInstruct Construction:
SpeechInstruct,一个语音文本跨模态解释跟随数据集。该数据集由两部分组成,第一部分称为跨模态指令[Cross-modal Instruction],第二部分称为模态链指令[Chain-of-Modality Instruction]。
Cross-modal Instruction数据集构造:
step1 数据收集: 收集了几个大规模的英语ASR数据集来构建跨模态教学,包括Gigaspeech(Chen et al.,2021)、Common Voice(Ardila 等人,2020)和LibriSpeech(Panayotov 等人,2015年)。我们采用mHuBERT作为语音分词器,以将语音数据离散化为离散单元,并去除相邻帧的重复单元以获得缩减的单元。最终,我们获得了900万个单元文本数据对。
step2 任务描述生成:我们生成与语音-文本数据对兼容的ASR和TTS任务描述。与自我指导方法不同(Wang 等人,2022),我们通过零zero-shot 方法生成描述。具体来说,我们直接将附录A中所示的提示输入OpenAI GPT-4以生成任务描述。我们的生成方法为每个任务生成100条指令,附录B中显示了一些示例。
step3 数据构造Instruction Formatting :对于离散单元序列 U 及其相关联的转录 T ,我们基于概率 p 来确定它将被用于构造ASR任务还是TTS任务。随后,我们从step2相应的任务描述中随机选择一个描述 D 。表示为 (D,U,T) 。在此之后,使用模板[Human]:{D}。输入:{U}<eoh>。[SpeechGPT]:{T}<eos>。. 为了支持多轮对话,组装的指令以多轮对话的形式连接,遵守模型的最大输入长度。
Chain-of-Modality Instruction数据集构造:
语音指令生成: 由于缺乏语音输入和语音输出的指令数据,我们训练了一个文本到单元【text-to-unit】生成器来将文本指令数据转换为语音指令数据。具体地,文本到单元生成器采用Transformer编码器-解码器架构。我们在跨模态教学中对LibriSpeech unit-text pairs进行了训练。 我们从moss-002-sft-data数据集中选择了37,969个响应长度小于35个单词的样本,通过文本到单元生成器将它们的指令和响应转换为单元序列。结果,我们获得了由语音指令、文本指令、文本响应和语音响应组成的37,969个四元组,表示为 (SpeechI,TextI,TextR,SpeechR) 。
使用上述四元组,我们可以为四种输入输出格式构建思维链风格的指令,即语音指令-语音响应,语音指令-文本响应,文本指令-语音响应和文本指令-文本响应。其相应模板可参见附录C。
Model Structure:
模型由三个主要组件组成:离散单元提取器,大语言模型和单元声码器。在这种架构下,LLM可以感知多模态输入并生成多模态输出。
离散单元提取器 离散单元提取器利用隐藏单元BERT(HuBERT)模型(Hsu 等人,2021)以将连续语音信号变换成离散单元的序列。HuBERT是一种自监督模型,它通过基于应用于模型中间表示的k均值聚类来预测掩蔽音频片段的离散标签来学习。它具有1-D卷积层和Transformer编码器的组合,将语音编码为连续的中间表示,k-means模型进一步将这些表示转换为聚类索引序列。随后,去除相邻的重复索引,得到表示为 U=(u1,u2,…,uT) 、 ui∈0,1,…,K−1 、 ∀1≤i≤T 的离散单元序列,其中 K 表示簇的总数。
LLM:采用Meta AI LLaMA(Touvron 等人,2023)模型作为我们的大型语言模型。LLaMA包括嵌入层、多个Transformer块和LM头层。LLaMA中的参数总数范围从7 B到65 B。从1.0万亿个令牌的广泛训练数据集中,LLaMA在各种NLP基准测试中与更大的175 B GPT-3相比表现出了竞争力。
Unit Vocoder:训练了一个多说话人 unit HiFi-GAN来解码语音信号, 离散表示。 HiFi-GAN架构由生成器 𝐆 和多个鉴别器 𝐃 组成。该生成器使用查找表(LUT)来嵌入离散表示,并且嵌入序列由一系列由转置卷积和具有扩张层的残差块组成的块进行上采样。 扬声器嵌入被连接到上采样序列中的每个帧。 该滤波器具有多周期鉴别器(MPD)和多尺度鉴别器(MSD)。
Training:
为了将语音离散表示纳入LLM,我们首先扩展词汇表和相应的嵌入矩阵。我们将培训过程分为三个阶段。第一阶段是对未配对语音数据进行模态自适应预训练。第二阶段是跨模态教学微调。第三阶段是模态链教学微调。
扩大词汇 给定大小为 |V| 的原始LLM词汇表 V ,为了将语音离散表示集成到LLM中,我们用大小为 |V′|=K 的单元标记 V′ 的附加集合来扩展词汇表。扩展词汇表 V′′ 是原始词汇表 V 和新词 V′ 的联合:V′′=V∪V′
我们将原始词嵌入矩阵表示为 E∈ℝ|V|×d ,其中 d 是词嵌入的维数。为了适应扩展的词汇表,我们需要创建一个随机初始化的单词嵌入矩阵 E′∈ℝ|V′′|×d 。 我们通过将 E 的值复制到 E′ 的前 |V| 行来保留原始的单词嵌入:E′[0:|V|,:]=E
Stage 1: Modality-Adaptation Pre-training
为了使LLM能够处理离散单元模态,我们利用未标记的语音语料库在下一个令牌预测任务中训练LLM。这种方法与LLM的文本预训练目标一致。 给定由语音 U1,U2,…,Um 和表示为 L1 的LLM组成的未标记语音语料库 C ,负对数似然损失可以公式化为:

其中, m 是数据集 C 中的语音的数量, nj 是语音 Uj 中的离散单元标记的数量,并且 ui,j 表示第j个语音中的第i个单元标记
Stage 2: Cross-modal Instruction Fine-Tuning
跨模态教学微调 在这个阶段,我们利用配对数据对齐语音和文本模态。我们将SpeechInstruct中的跨模态指令与moss-002-sft数据集混合以导出混合数据集 I ,其由样本 T1,T2,…,Tx 组成。我们在 I 上对从第一阶段获得的模型 L 进行微调。
由 t1,t2,…,tnj 组成的每个样本 Tj 通过连接前缀和文本来形成。训练目标是最小化负对数似然,损失计算只考虑文本部分,忽略前缀,可以格式化为:
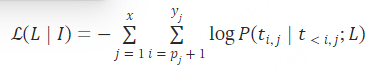
其中 x 是语料库 I 中的样本数, yj 是样本 Tj 中的标记总数, pj 是 Tj 的前缀部分中的标记数,并且 ti,j 表示 Tj 中的第i个单词

Stage 3: Chain-of-Modality Instruction Fine-Tuning
在获得阶段2中的模型之后,我们利用参数有效的低秩自适应(LoRA)(Hu 等人,2021年),以微调它的链的模态教学SpeechInstruct。我们将LoRA权重(适配器)添加到注意力机制中,并训练新添加的LoRA参数。我们采用与阶段2相同的损失函数。
附录A:Prompts to Generate Task Description
ASR:
You are asked to come up with a set of 100 diverse task instructions about automatic speech
recognition, which is about recognizing speech.
Here are the requirements:
1. These instructions should be to instruct someone to recognize the content of the following
speech.
2. Try not to repeat the verb for each instruction to maximize diversity.
3. The language used for instruction also should be diverse. For example, you should
combine questions with imperative instructions.
4. The type of instructions should be diverse.
5. The instructions should be in English.
6. The instructions should be 1 to 2 sentences long. Either an imperative sentence or a
question is permitted.
List of 100 tasks:
TTS:
You are asked to come up with a set of 100 diverse task instructions about text to speech,
which is about recognizing speech .
Here are the requirements:
1. These instructions should be to instruct someone to recognize the content of the following
speech.
2. Try not to repeat the verb for each instruction to maximize diversity.
3. The language used for instruction also should be diverse. For example, you should
combine questions with imperative instructions.
4. The type of instructions should be diverse.
5. The instructions should be in English.
6. The instructions should be 1 to 2 sentences long. Either an imperative sentence or a
question is permitted.
List of 100 tasks:
附录B:Examples of Task Description【gpt生成的一些例子】
ASR:
Begin by converting the spoken words into written text.
Can you transcribe the speech into a written format?
Focus on translating the audible content into text.
Transcribe the speech by carefully listening to it.
Would you kindly write down the content of the speech?
Analyze the speech and create a written transcription.
Engage with the speech to produce a text-based version.
Can you document the speech in written form?
Transform the spoken words into text accurately.
How about putting the speech’s content into writing?
TTS:
Can you please read this sentence out loud?
Recite the following words as if you were speaking normally.
Project your voice to clearly articulate this statement.
Would you mind speaking these words as naturally as possible?
Whisper the given sentence softly.
Enunciate each word in this sentence with precision. How would you express this sentence in
a conversational tone?
Could you please relay the message below verbally?
Emphasize the key points while reading the sentence.
Sing the text provided in a melodic voice.
附录C: Chain-of-Modality Instructions Templates
Speech Instruction-Speech Response:
[Human]: This is a speech instruction: {SpeechI}. And your response should be speech.
You can do it step by step. You can first transcribe the instruction and get the text Instruction.
Then you can think about the instruction and get the text response. Last, you should speak the
response aloud <eoh>. [SpeechGPT]: [tq] {TextI}; [ta] {TextR}; [ua] {SpeechR}<eoa>.
Speech Instruction-Text Response:
[Human]: This is a speech instruction: {SpeechI}. And your response should be text. You
can do it step by step. You can first transcribe the instruction and get the text instruction.
Then you can think about the instruction and get the text response. <eoh>. [SpeechGPT]:
[tq] {TextI}; [ta] {TextR}<eoa>.
Text Instruction-Speech Response:
[Human]: This is a text instruction: {TextI}. And your response should be speech. You can
do it step by step. You can think about the instruction and get the text response. Then you
should speak the response aloud <eoh>. [SpeechGPT]: [ta] {TextR}; [ua] {SpeechR}<eoa>.
Text Instruction-Text Response:
[Human]: This is a text instruction: {TextI}. And your response should be text. You can
think about the instruction and get the text response. [SpeechGPT]: [ta] {TextR}<eoa>.SpeechAgents:多模态多智能体系统的人机交互仿真
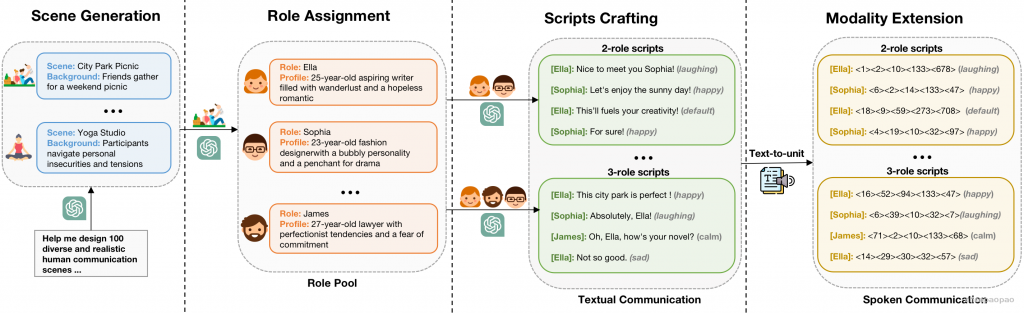
SpeechAgents是一个基于多模态LLM的多智能体系统,旨在模拟人类的交流。与现有的基于LLM的多Agent系统不同,SpeechAgents使用多模态LLM作为单个Agent的中央控制,并使用多模态信号作为Agent之间交换消息的媒介。 此外,我们提出了多代理调整,以提高LLM的多代理功能,而不影响一般的能力。为了加强和评估人类通信仿真的有效性,我们建立了人类通信仿真基准。实验结果表明,SpeechAgents可以模拟人类交流对话一致的内容,真实的节奏,丰富的情感和表现出良好的可扩展性,即使多达25个代理,这可以适用于任务,如戏剧创作和音频小说生成。
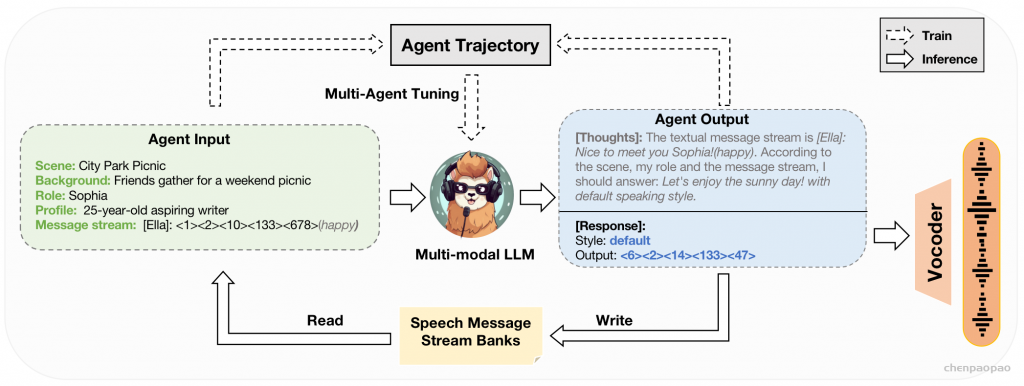
图3:SpeechAgents中单个代理的训练和推理过程的图示。实心箭头表示推理过程中的数据流。在一个代理的回合中,它接收包括场景、背景、角色、简档和来自语音消息流库的消息流的输入。智能体的输出包括其内部思想、生成的语音响应和相应的风格。然后将具有样式的响应写入语音消息流库。虚线箭头表示训练过程中的数据流。从人类通信模拟基准测试中的脚本解析的代理轨迹指令以图中代理输入和输出的串联的形式可视化地表示,并用于多模态LLM的多代理调整。
SpeechGPT-Gen[SpeechGPT2]: 缩放信息链语音生成
对于上面的第一个问题,作者在其后的SpeechGPT-Gen中做了解决。解决思路的核心点就是:让模型不仅看到语音的语义token,也要看到语音的声学token。具体做法是:SpeechGPT的HuBERT特征替换成了SpeechTokenizer中的语义特征,用SpeechGPT这一LLM来自回归地建模语义特征,有了语义特征之后,再使用Flow-Matching这样的扩散模型来建模声学特征。这里选用Flow-Matching扩散模型,可能是受了SD3和Voicebox/Audiobox的影响。为了增强两阶段建模的依赖关系,作者将语义特征的先验信息注入到第二阶段扩散模型的先验分布中。可以看到,这里语音的解码其实也是一种层次化渐进式解码。
SpeechGPT 2是一种端到端的语音对话语言模型,类似于GPT-4 o。它可以感知和表达情感,并根据上下文和人类指令提供各种风格的适当语音响应,如说唱,戏剧,机器人,搞笑和耳语。为了解决冗长语音序列的问题,SpeechGPT 2采用了超低比特率语音编解码器(750 bps),该编解码器对语义和声学信息进行建模。它使用多输入多输出语言模型(MIMO-LM)。目前,SpeechGPT 2仍然是一个基于回合的对话系统。我们正在开发实时SpeechGPT 2的全双工版本,并且已经取得了一些有希望的进展。
得益于有效的语音建模,当前的语音大语言模型(SLLM)在上下文语音生成和对未知说话人的有效泛化方面表现出了卓越的能力。然而,流行的信息建模过程是由某些冗余,导致语音生成效率低下。我们提出了信息链生成(CoIG),在大规模语音生成的语义和感知信息解耦的方法。在此基础上,我们开发了SpeechGPT-Gen,这是一个在语义和感知信息建模方面具有80亿参数的SLLM。它包括一个基于LLM的自回归模型用于语义信息建模和一个采用流匹配的非自回归模型用于感知信息建模 [感知信息建模主要关注的是与感官输入(如视觉、听觉等)直接相关的信息处理,非自回归模型通常用于感知信息建模中,因为这些模型可以并行处理数据,更加适合需要实时处理或低延迟的应用场景]。此外,我们引入了新的方法,注入语义信息的先验分布,以提高流匹配的效率。 大量的实验结果表明,SpeechGPT-Gen在zero-shot文本到语音,zero-shot语音转换和语音到语音对话方面表现出色,强调了CoIG在捕捉和建模语音的语义和感知维度方面的卓越能力。
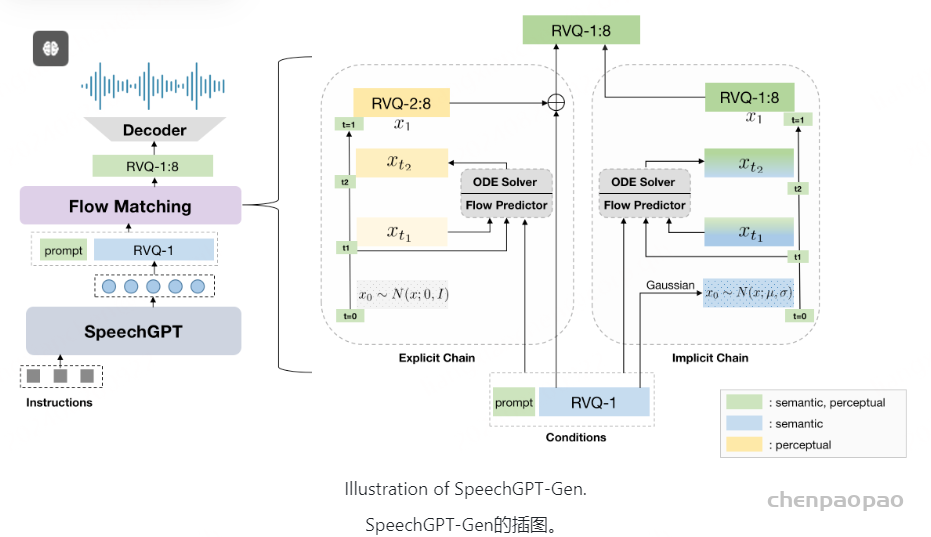
SpeechGPT-Gen基于信息链生成方法,依次进行语义建模和感知建模。SpeechTokenizer(Zhang 等人,2023 b)用于提取语义表示和感知表示。SpeechGPT-Gen由用于语义建模的基于LLM的自回归模型和用于感知建模的基于流匹配的非自回归模型组成。
Speech Tokenization:
SpeechTokenizer(Zhang 等人,2023 b)是基于残差矢量量化(RVQ)的语音标记化方法,并且跨不同RVQ层分层地解开语音信息的不同方面。具体地,第一RVQ量化器生成包含语义信息的令牌,而后续量化器补充剩余的感知信息。 SpeechTokenizer将单声道音频信号表示为 作为输入,其中 d 表示持续时间, fsr 表示采样率。 SpeechTokenizer的输出包括用于对应RVQ层的 Q=8 分层RVQ令牌 (q1,…,qQ) 和 Q 码本 (C1,…,CQ) 。 qi∈ℝT 表示长度为 T 的一维序列。 RVQ令牌 qi 可以由码本 Ci∈ℝK×H 嵌入,从而产生连续矢量序列 vi∈ℝT×H ,其中 vij=Ci(qij) 用于 i∈1,…,Q 、 j∈1,…,T 。 表示为 v1:8=∑i=1Qvi 的来自所有RVQ层的连续表示的总和包含语音内的所有信息。 我们利用来自第一RVQ层 q1 的标记作为包含语义信息的表示,并且利用从第二层到最后一层 v2:7=∑i=2Qvi 求和的连续向量作为包含感知信息的表示。
LLM用于语义建模:
SpeechGPT是一个大型的跨模态语言模型,可以执行跨模态指令跟随和语音到语音对话,表现出出色的语音语义建模能力。 利用HuBERT(Hsu 等人,2021)将语音离散化为单元,SpeechGPT执行模态适应预训练,跨模态指令微调和模态链指令微调。我们通过用SpeechTokenizer RVQ-1令牌 q1 替换HuBERT离散单元来使用SpeechGPT进行语音语义建模。 对于模型结构,我们采用LLaMA 2 – 7 B-Chat作为预训练的LLM。 对于训练数据,我们采用SpeechTokenizer RVQ-1令牌来表示语音,并遵循SpeechInstruct的过程和设置来构造训练数据集 D ,包括跨模态指令集和模态链指令集。我们使用Multilingual Librispeech 、Gigaspeech(Chen 等人,2021)、Commonvoice(Ardila 等人,2020)和Librispeech(Panayotov 等人,2015年)构建跨模态指令集。 对于训练,我们跳过模态适应预训练,并使用跨模态指令集 I 对LLaMA 2 – 7 B-Chat执行跨模态指令微调。 在模态链指令微调中,我们选择全参数微调而不是模态链指令集上的LoRA微调。 这两个培训阶段的培训目标可以格式为:

感知建模的流程匹配:
给定语音 s 、语义表示 v1 、感知表示 v2:8 和由SpeechTokenizer提取的完整信息表示 v1:8=v1+v2:8 ,感知建模是指在给定提示语音 a 和语义表示 v1 的情况下预测完整表示 v1:8 。 我们提出了两种感知建模的流匹配模式:显式链和隐式链。





SpeechAlign :使语音生成与人类偏好保持一致
SpeechAlign做的则是SLM与人类偏好的对齐,彻底地向LLM的训练方法看齐。该工作构建了对比gold token和合成token的encodec数据集,然后进行偏好优化来进行改进。使用的偏好优化方法包括RLHF和Chain of Hindsight。
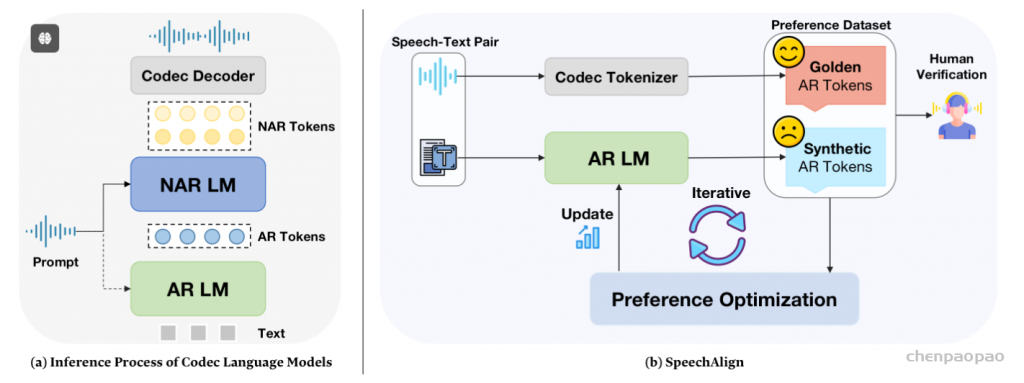
本文首先分析编解码器语言模型中的分布差距,强调它如何导致训练阶段和推理阶段之间的差异,从而对性能产生负面影响,从而解决这一差距。然后,我们探索利用从人类反馈中学到的知识来弥合分布差距。我们介绍了 SpeechAlign,这是一种迭代式自我改进策略,可将语音语言模型与人类偏好保持一致。SpeechAlign 涉及构建一个偏好编解码器数据集,将黄金编解码器令牌与合成令牌进行对比,然后进行首选项优化以改进编解码器语言模型。这个改进周期是迭代进行的,以稳步将弱模型转换为强模型。通过主观和客观评估,我们表明 SpeechAlign 可以弥合分布差距并促进语音语言模型的持续自我改进。此外,SpeechAlign 具有强大的泛化功能,适用于较小的模型。