语音语言模型的统一语音标记器
https://github.com/ZhangXInFD/SpeechTokenizer
SpeechTokenizer: Unified Speech Tokenizer for Speech Language Models
SpeechTokenizer是一个统一的语音语言模型的语音分词器,它采用了编码器-解码器架构与残差矢量量化(RVQ)。统一语义和声学标记,SpeechTokenizer在不同的RVQ层上分层地解开语音信息的不同方面。具体地,RVQ的第一量化器输出的代码索引可以被认为是语义令牌,并且其余量化器的输出主要包含音色信息,其用作对由第一量化器丢失的信息的补充。
目前的Speech Langauge Model(speech LM)大多依赖于语音的离散表示。具体来说,这些模型首先将连续的语音信号转换成离散的tokens,进而像处理文本一样以自回归的方式进行训练,再通过一个解码器将离散tokens恢复为语音。
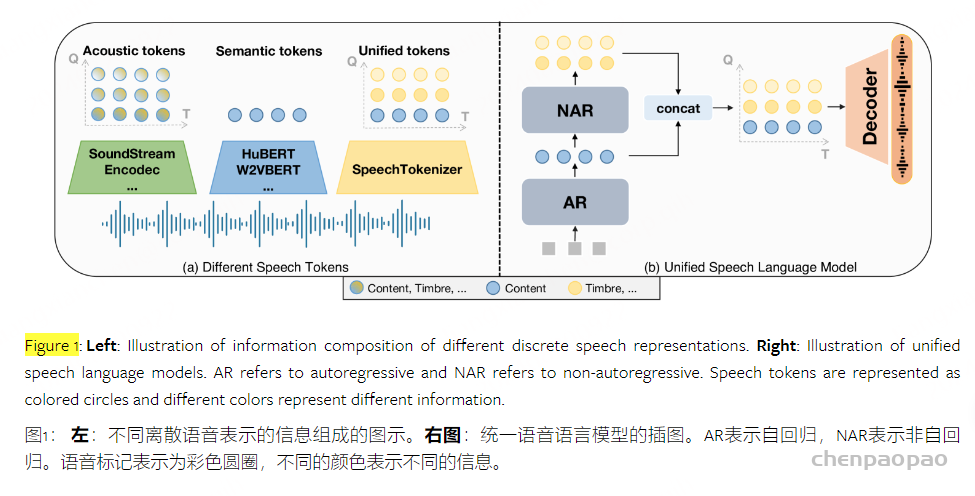
比较常用的语音离散表示大致可分为两种:语义semantic token和 声学acoustic token。token如其名,通常认为semantic token建模语音中较为global的内容信息,它们来自于以mask langauge modeling为training objective的自监督预训练模型,比较常见的有HuBERT, W2VBERT等;acoustic token建模语音中的局部声学细节,通常来自于以reconstruction为training objective的neural audio codec,比较常见的有SoundStream, EnCodec。
基于这两种token,目前已有的speech LM建模范式大致可分为三类:
- Semantic language models: 基于semantic token的自回归模型,常外接一个unit-vocoder来恢复语音,比如SpeechGPT。这类模型虽然可以完成一些语音内容相关的任务,但是它们产生的音质比较一般,并且无法完成一些副语言学相关的任务,比如音色转换等。
- Acoustic language models: 基于acoustic token的speech LM,比如VALL-E。这类模型产生的语音音质比较好,并且可以较好地完成一些比如zero-shot TTS的任务,但是会存在内容不准确的问题。
- Hierarchical speech language models: 这类模型由Semantic language models和Acoustic language models 级联而成,既可以产生比较精确的内容,也可以产生较好的音质,比如AudioPaLM。但是这类模型,建模阶段太多,较为复杂,需要两种tokenizer的参与;而且在semantic token和acoustic token之间其实存在有很大的信息冗余,会带来一些不必要的建模难度。
因此,如果想要打造好的speech LM,需要有一个理想的speech tokens,它应该具有以下两个特征:
- 和文本的对齐程度比较高
- 保留了语音中各个方面的信息
但是现有的speech tokens都不是专门为构建speech LM而设计的,并不清楚它们和speech LM的适配性。因此我们建立了SLMTokBench来评估不同类型speech token在构建speech LM方面的适用性。它从文本对齐程度和信息保留程度两个方面来量化分析speech tokens,具体评测方法可以看我们论文。通过SLMTokBench,我们发现semantic tokens和文本的对齐程度比较高,但是损失了语音中很大一部分说话人信息。acoustic tokens保留了语音中的各个方面信息,但是和文本的对齐程度不够高。因此,他们都不适合于构建speechLM。
方法
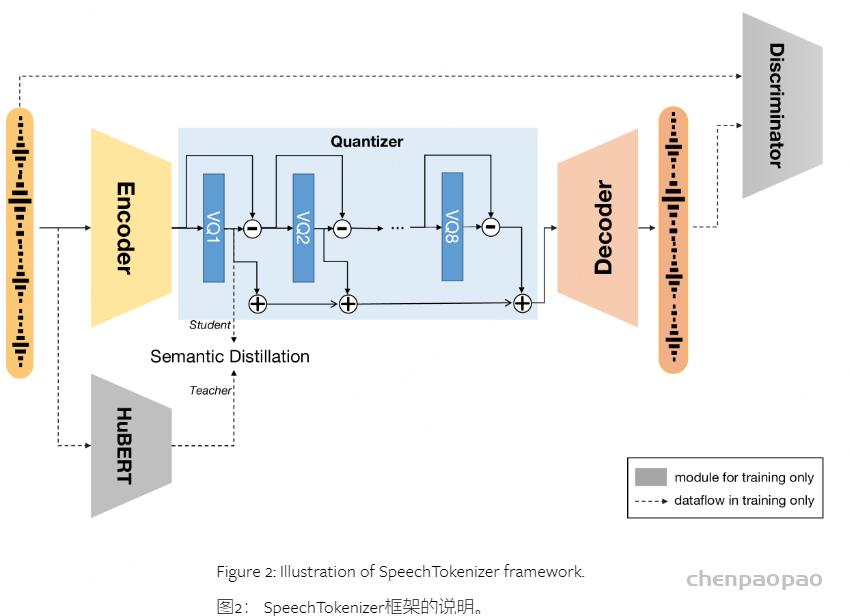
虽然说SoundStream和Encodec这样的基于RVQ-VAE的压缩建模方法包含了语音的声学特征,但其中也不可避免地带入了语义特征。二者提取的实际上更像是一种语义特征和声学特征的混合体。基于此,SpeechTokenizer在二者的基础上,引入了语义引导信息来解耦语义特征和声学特征。语义特征和声学特征的解耦对于最终的语音合成有着相当的重要性。SpeechTokenizer的具体做法是:使用HuBERT的特征对RVQ1的特征做语义蒸馏,其余部分保留声学信息。
基于此,我们想统一semantic token和acoustic token,我们提出了SpeechTokenizer,它基于EnCodec架构,在不同的RVQ层上对语音信息进行解耦和分层建模,从而让第一层token建模语音中的内容信息,剩下几层token补充除内容信息之外的其他信息,如下图。这是首个专为speech LM设计的语音离散化工具。
具体实现方法为在EnCodec的整体框架上,使用HuBERT representation对RVQ-1的quantized output进行semantic guidance,从而达到第一层token建模语音中的内容信息的效果,并且残差结构会使得剩下的几层来补充内容信息之外的其他信息。使用EnCodec的基于卷积的编码器-解码器网络,该网络使用选定的步幅因子执行时间缩减。值得注意的是,我们已经用两层BiLSTM代替了最初在EnCodec编码器中的卷积块之后的两层LSTM,以增强语义建模能力。我们对附录B中的模型结构进行了消融研究。我们使用残差向量量化(RVQ)来量化编码器的输出,RVQ是一种可以在初始量化步骤之后使用不同码本来量化残差的方法。有关模型结构的更多详细信息,请参见附录D。 在训练期间,语义教师提供语义表示以指导残差量化过程。
并且基于SpeechTokenizer,我们可以统一上面讲的三种speech LM建模范式,从而构建unified speech language model(USLM),模型结构如下图。
在SpeechTokenizer上构建一个统一的语音语言模型。它由自回归模型和非自回归模型组成,可以对语音信息进行分层建模。自回归(AR)模型通过对来自第一RVQ量化器的令牌进行建模来捕获内容信息。非自回归(NAR)模型通过从以第一层令牌为条件的后续量化器生成令牌来补充AR模型的语言信息。我们在零拍TTS任务上验证了统一语音语言模型的有效性。
回归(AR)模型通过对来自第一RVQ量化器的令牌进行建模来捕获内容信息。非自回归(NAR)模型通过从以第一层令牌为条件的后续量化器生成令牌来补充AR模型的语言信息。
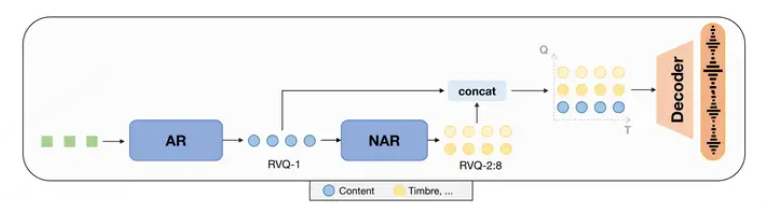
NAR模型可以是条件流匹配[speech-Gen]、扩散模型 【Seed-TTS】等
在推理过程中,我们将文本输入转换为音素序列,将语音提示转换为语音标记。它们连接在一起形成AR和NAR模型的提示。在此基础上,AR模型生成第一级令牌,而NAR模型迭代地生成后续级别的令牌。由AR和NAR模型生成的令牌然后被连接以构造语音令牌矩阵。最后,我们使用SpeechTokenizer解码器来生成以完整令牌矩阵为条件的波形。
Speech Language Model Token Benchmark:
文本对齐评估:

下游模型采取语音令牌作为输入。具体来说,对于每个离散表示,我们首先建立一个嵌入矩阵,该矩阵可以随机初始化,也可以从离散化过程中获得的k均值质心矩阵或矢量量化码本中导出。我们使用嵌入矩阵来嵌入离散表示并获得连续表示,然后将其输入下游模型。我们在LibriSpeech train-clean-100子集上训练下游模型,并使用dev-clean子集来估计互信息。我们还计算了测试集上的单词错误率(WER)。
信息保存评估:
为了评估离散语音表示中语音信息的保留,我们将语音令牌转换回语音,并通过内容和音质的自动度量来评估重新合成的语音。我们训练一个单元-HiFIGAN(Polyak 等人,2021)在LibriSpeech数据集上将HuBERT单位转换为波形。值得注意的是,为了避免额外信息的干扰,我们在训练期间不提供任何说话人信息。对于Encodec令牌,我们使用Encodec解码器直接产生波形。通过使用Whisper en-medium模型转录重新合成的语音来计算WER来评估内容保存(拉德福 等人,2023年)。通过利用WavLM-TDNN(Chen 等人,2022)来计算合成语音和地面实况语音之间的说话人相似度。 我们从LibriSpeech测试集中随机抽取300个语音样本进行评估。
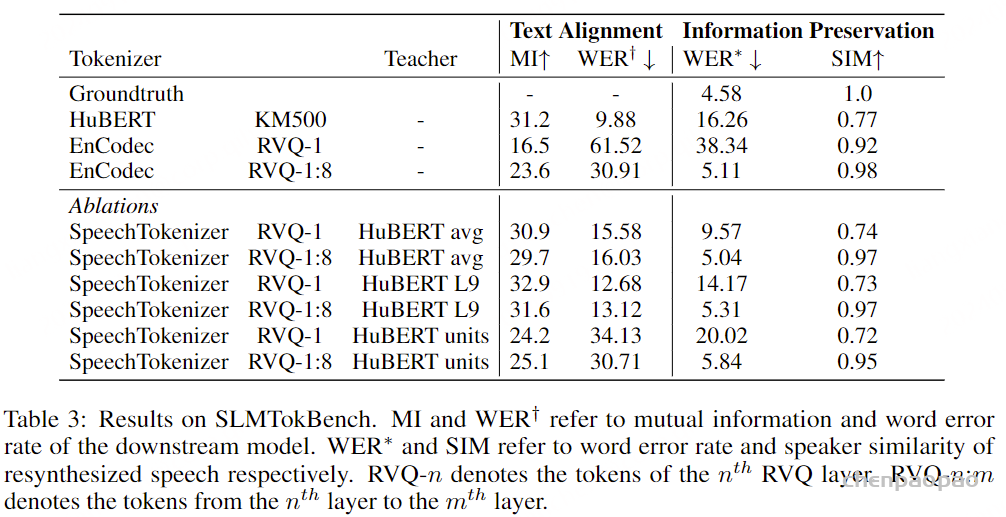
比较语义 & 声学令牌
我们使用HuBERT L9单元来表示语义令牌,使用EnCodec代码来表示声学令牌语义标记实现了与文本的高互信息,但其重新合成的语音具有低说话人相似性。声学标记实现低WER和高说话人相似度的再合成语音,但与文本的互信息低。
SpeechTokenizer
模型结构
我们的模型基于 RVQ-GAN 框架,遵循与 SoundStream和 EnCodec相同的模式。如图 2 所示,模型使用了 EnCodec 中基于卷积的编码器-解码器网络,通过选择的步长因子进行时间下采样。值得注意的是,我们将 EnCodec 编码器中卷积模块后原本使用的两层 LSTM 替换为两层 BiLSTM,以增强语义建模能力。我们在附录 B 中进行了模型结构的消融研究。我们使用残差矢量量化(RVQ)对编码器输出进行量化,这种方法可以在初始量化步骤后使用不同的码书对残差进行量化。模型结构的进一步细节可参见附录 D。在训练期间,一个语义教师为残差量化过程提供语义表示指导。
语义提炼
为了实现跨不同RVQ层的不同信息的分层建模,我们采用语义指导的第一个量化器,使其能够捕获内容信息。利用残差结构使得后续量化器能够补充剩余的非语言信息。
我们采用HuBERT(Hsu 等人,2021)作为我们在这项研究中的语义老师,因为HuBERT被证明包含大量的内容信息(Mohamed 等人,2022年)。我们介绍了两种类型的蒸馏:连续表示蒸馏和伪标签预测。
对于连续表示蒸馏,我们采用第9层HuBERT表示或所有HuBERT层的平均表示作为语义教师。训练目标是最大化RVQ第一层和语义教师表示的输出之间的所有时间步长在维度级别上的余弦相似性。形式上,连续蒸馏损失定义为:
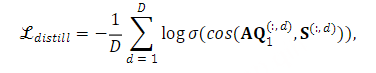
其中 𝐐1 和 𝐒 分别表示RVQ第一层和语义教师表示的量化输出。 𝐀 表示投影矩阵, D 是语义教师表征的维度。上标 (:,d) 表示包括来自维度 d 处的所有时间步的值的向量。 cos(⋅) 表示余弦相似性, σ(⋅) 表示S形激活。这种连续蒸馏损失函数偏离了常用的方法,该方法基于学生和教师模型在同一时间步输出的表示来计算损失。附录C对这两种方法进行了比较分析。
对于伪标签预测,我们采用HuBERT单元作为目标标签。培训目标如下:
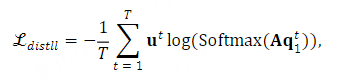
其中 𝐪1t 和 𝐮t 分别表示第一VQ层和HuBERT单元在时间步t的量化输出。 T 表示时间步长的数量, 𝐀 是投影矩阵。
Training Objective
我们的训练方法包括重建任务和语义蒸馏任务。在重建任务中,我们采用了GAN目标,优化了重建项,判别损失项和RVQ承诺损失的组合。在语义蒸馏任务中,训练目标涉及语义蒸馏损失项。在下文中, 𝐱 表示语音信号,并且 𝐱^ 表示通过网络重构的信号.
重建损失重建损失包括时域和频域损失。鉴别损失我们使用与HiFi-CodecYang等人(2023)相同的鉴别器,其中包括三个鉴别器:基于多尺度STFT(MS-STFT)的鉴别器;多周期鉴别器(MPD)和多尺度鉴别器(MSD)。鉴别器的更多详细信息可参见附录D。对抗性损失用于提高感知质量,并且它被定义为在多个鉴别器上和在时间上平均的在多个鉴别器的logits上的铰链损失。RVQ Commitment Loss 我们在预量化值和其量化值之间添加承诺损失 ℒw ,而不为量化值计算梯度。RVQ承诺损失被定义为: ℒw=∑i=1Nq∥𝐳i−𝐳qi∥22. ,其中 𝐳i 和 𝐳qi 分别表示对应码本中的当前残差和最近条目。
通常,生成器被训练以优化以下损失:
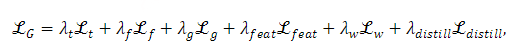
RVQ token中信息解耦的效果如何?
我们做了one-shot voice conversion的实验。具体做法为把source speech的RVQ-1 token和reference speech的RVQ-2:8 token拼在一起送到decoder中得到converted speech。我们发现这种简单拼接RVQ token的做法也可以有不错的音色转换的效果,说明信息解耦是比较成功的。可以到我们的demo page上听效果。
SpeechTokenizer能否直接应用到unseen langauge上?
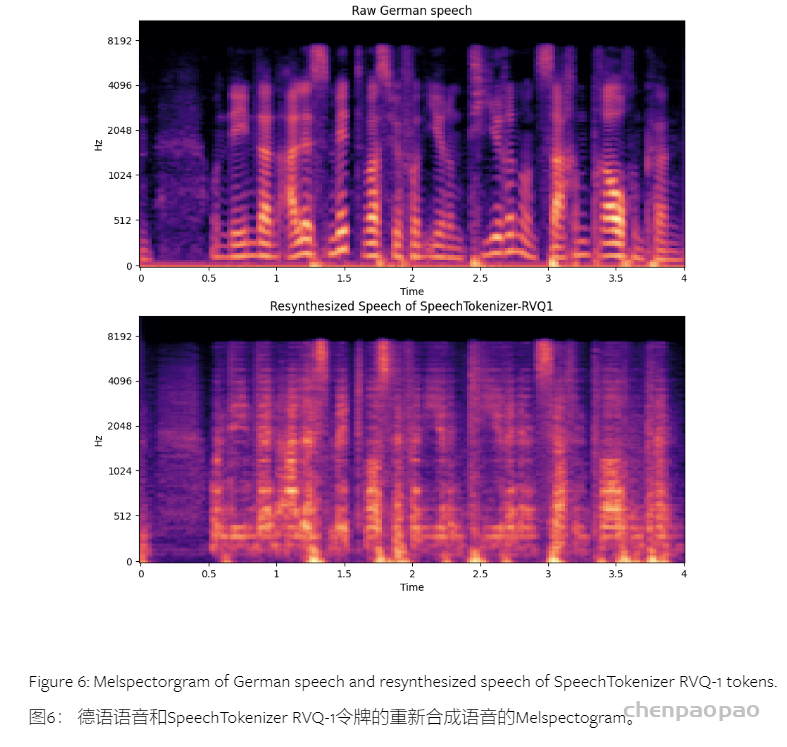
SpeechTokenizer在训练过程中只见过英语,我们直接用它直接来tokenize 德语和中文speech。发现RVQ-1送到decoder得到的speech比较机械,没有音色和韵律,说明也有比较好的解耦效果,大家可以去project page听demo。从下面频谱图也可以看出RVQ-1得到的语音丢掉了一些如共振峰等特征。