
AudioPaLM,一个用于语音理解和生成的大型语言模型。AudioPaLM融合了基于文本和基于语音的语言模型,将PaLM-2和AudioLM集成到一个统一的多模式架构中,该架构可以处理和生成文本和语音,可以实现包括语音识别和语音到语音翻译。AudioPaLM继承了AudioLM保留说话人身份和语调等非语言信息的能力,以及仅存在于PaLM-2等文本大型语言模型中的语言知识。我们证明,使用纯文本大型语言模型的权重初始化AudioPaLM可以改善语音处理,成功地利用预训练中使用的大量文本训练数据来帮助语音任务。 由此产生的模型显著优于现有的语音翻译任务系统,并且能够为许多语言执行零样本语音到文本的翻译,这些语言在训练中没有看到输入/目标语言组合。
https://google-research.github.io/seanet/audiopalm/examples/
https://arxiv.org/html/2306.12925
AudioPaLM的核心是一个联合词汇表,它可以用有限数量的离散tokrn来表示语音和文本,结合任务的基本标记描述,允许在涉及任意交织的语音和文本的混合任务上训练单个仅解码器模型。这包括语音识别、文本到语音合成和语音到语音翻译,将传统上由异构模型解决的任务统一到单个架构和训练运行中。此外,由于AudioPaLM的底层架构是大型Transformer模型,因此我们可以使用在文本上预训练的大型语言模型的权重来初始化其权重,这允许其受益于诸如PaLM的模型的语言和常识知识。
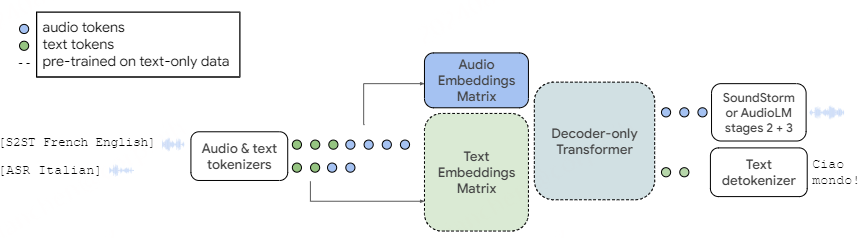
图1:AudioPaLM模型,以语音到语音翻译和自动语音识别为例。我们采用一个预训练的纯文本模型(虚线),并扩展其嵌入矩阵来建模一组新的音频令牌,这里的token基于w2v-BERT 或者USM-v提取的,但token中同时含有语义信息和说话人声学信息【 k-means聚类之前不对嵌入进行归一化 ,用于保留说话人信息】。模型架构在其他方面没有改变:文本和音频令牌的混合序列作为输入被送入,并且模型解码文本或音频令牌。音频令牌通过后面的AudioLM阶段或SoundStorm转换回原始音频。
我们使用一个只有解码器的Transformer来建模由文本和音频令牌组成的序列。就模型而言,文本和音频只是任意整数的序列,因为输入在馈送到模型之前被标记化,并且任何输出在返回给模型的用户之前都被去token化。通过在有限的词汇表中用离散的标记来表示语音,我们可以构建一个多模态词汇表,它是这个音频词汇表和一个用于表示文本的SentencePiece的结合。因此,原则上,我们的设置和通常的纯文本解码器设置之间几乎没有区别,除了在我们的设置中,一些令牌代表音频和一些文本,并且我们使用预训练的纯文本检查点初始化我们的多模态模型。
方法
音频嵌入和令牌化
将原始波形转换为令牌。这涉及从现有的语音表示模型中提取嵌入,然后将这些嵌入离散化为有限的音频令牌集合。从w2v-BERT模型中提取嵌入,通过K-means进行离散化。在这项工作中,我们实验了以下方法来获得一组离散的音频令牌:
1、我们使用了一个w2v-BERT模型,该模型已经在多语言数据上进行了训练,其次,我们在执行k-means聚类之前不对嵌入进行归一化。虽然Borsos等人发现标准化在不降低性能的情况下删除了说话者身份信息,但我们发现在多语言环境中,标准化确实会导致性能下降【保留了说话人的声学信息,所以这里的token可以认为是声学token+语义token】。该方法以25 Hz的速率产生令牌,令牌词汇表的大小为1024。
2、USM-v1:我们使用更高性能的通用语音模型(USM)编码器执行相同的过程,以替换w2v-BERT编码器。我们使用这个多语言语音编码器的最大2B参数变体,并从中间层提取嵌入。与w2v-BERT类似,该方法以25 Hz的速率生成令牌,令牌词汇表的大小为1024。
修改纯文本解码器以适应文本和音频
在Transformer解码器中,输入预处理后模型的第一层是标记嵌入矩阵 𝐄 ,它将整数值标记映射到密集嵌入;给定 t 标记的词汇表和大小为 m 的嵌入, 𝐄 是 t×m 矩阵,其第 i 行给出第 i 标记的嵌入。 另一个嵌入矩阵 𝐄′ 出现在最后的softmax层中,用于计算每个位置上所有标记的logit;它是一个 m×t 矩阵,与模型的 m 维输出相乘,以获得logit的 t 维向量,每个标记一个。 在PaLM架构中,这些矩阵具有共享变量,因此一个是另一个的转置,即 𝐄′=𝐄⊺ 。
解码器架构的其余部分对建模的令牌数量完全无关。 因此,我们只需要做一个小的修改,将纯文本模型转换为同时对文本和音频进行建模的模型:我们将嵌入矩阵 𝐄 的大小扩展为大小 (t+a)×m ,其中 a 是音频令牌的数量( 𝐄′=𝐄⊺ 的大小相应地改变)。
为了利用预训练的文本模型,我们通过向嵌入矩阵 𝐄 添加 a 新行来更改现有的模型检查点。实现细节是前 t 令牌(从零到 t )对应于SentencePiece文本令牌,而接下来的 a 令牌(从 t 到 t+a )表示音频令牌。 虽然我们可以重用预训练模型的文本嵌入,但新的音频嵌入是新初始化的,必须经过训练。我们发现有必要训练所有模型参数,而不是保持以前的权重固定。我们使用混合语音和文本任务进行训练。
3、将音频令牌解码为原始音频
为了从音频令牌合成音频波形,我们实验了两种不同的方法:i)自回归解码,遵循AudioLM的设置非自回归解码,ii) 使用最近提出的SoundStorm模型。在这两种情况下,音频令牌首先用于生成声音流令牌,然后用卷积解码器将其转换为音频波形。
AudioLM中的声学生成分两个阶段进行:先将音频token声音流令牌,然后再在合成语音:“阶段2”是仅解码器的Transformer模型,其将AudioPaLM产生的音频令牌和语音调节作为输入,并生成SoundStream令牌,其可用于以所需语音实现语音,但比特率非常低。“阶段3”重建SoundStream的残差矢量量化器的更高级别,这增加了比特率并提高了音频质量。
SoundStorm提出了一种替代的非自回归解码方案,该方案应用了一种迭代方法,该方法在所有令牌上并行进行。SoundStorm产生的音频质量与AudioLM相同,但在语音和声学条件方面具有更高的一致性,同时速度快了两个数量级。
通过提供原始输入语音的一部分作为语音调节,该模型能够在将其语音翻译为不同语言时保留原始说话者的语。
实验
由于 AudioPaLM 是基于 Transformer 模型的大语言模型,它可以使用基础的文本预训练模型来初始化权重,从而受益于 PaLM 或 PaLM 2 等模型的语言和常识知识。由于统一的多模态架构,AudioPaLM 能够使用直接映射或组合任务的方式来解决语音识别、语音合成和语音翻译等问题。单一任务包括自动语音识别(ASR)、自动语音翻译(AST)、语音到语音翻译(S2ST)、文本到语音(TTS)和文本到文本机器翻译(MT)等。为了指定模型在给定输入上执行的任务,可以在输入前加上标签,指定任务和输入语言的英文名称,输出语言也可以选择加上。例如,[ASR French]表示执行法语的自动语音识别任务,[TTS English]表示执行英语的文本到语音任务,[S2ST English French]表示执行从英语到法语的语音到语音翻译任务,而组合任务的标签[ASR AST S2ST English French]表示依次进行从英语到法语的自动语音识别、自动语音翻译、语音到语音翻译。微调使用的数据集包含音频、音频的转录、音频的翻译、音频的翻译文本等。一个数据集可以用于多个任务,将同一数据集中的多个任务结合起来可以提高性能。
AudioPaLM 在语音翻译基准测试中展示了最先进的结果,并在语音识别任务上表现出竞争性能。利用 AudioLM 的语音提示,该模型还可以对未见过的讲话者进行 S2ST,超越现有方法,以客观和主观评估的方式衡量语音质量和声音保持。另外,该模型展示了零样本迁移的能力,可以使用训练中未曾出现过的语音输入/目标语言组合进行 AST。