
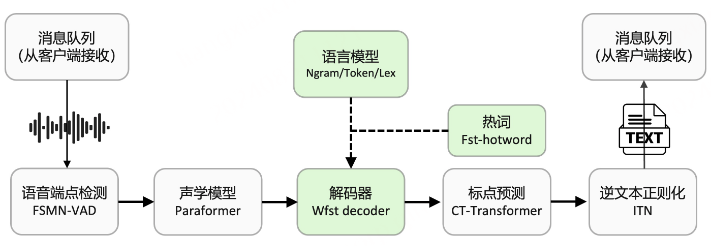
最近在做ASR语音识别任务,基于阿里FunASR框架,特此记录下跟热词模型相关知识。
wfst热词增强
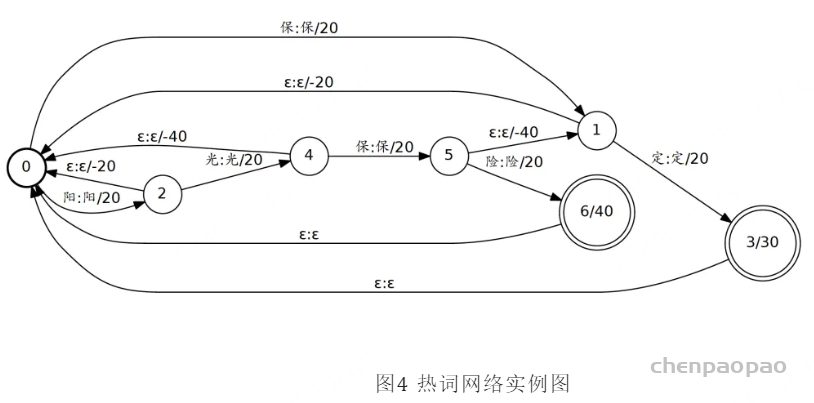
热词构图,我们采用AC自动机结构进行热词网络构图,解决热词前缀重叠场景下难以有效激励的问题。例如热词列表包含“阳光保险”与“保定”两个热词,实际语音内容为“阳光保定”,在匹配到“定”时匹配失败则会根据AC自动机回退机制回退至“保定”热词路径,确保仍可继续匹配的最大子串路径可正常激励。
如下是热词网络实例图。
热词发现与匹配,我们采用对主解码网络弧上ilabel音素/字符序列信息进行热词发现及匹配,而非在网络搜索出词时再对整词匹配,该方式优势是能够更早实现对尚未出词热词路径激励,避免热词路径被过早误裁减,其次也可避免由于热词分词结构不一致而导致匹配失败。
热词激励方式,我们采用过程渐进激励和整词激励相结合的方式,而非热词首字或尾字激励。采用仅首字激励方式可能存在部分case在热词后续字的解码过程中路径仍被裁剪掉的情况,而仅在尾字出词时施加激励则可能激励过晚。
过程渐进激励(incremental bias)对过程中每匹配成功一步即进行等量激励,如在后续扩展过程匹配失败则通过回退弧跳转进行激励减除。
整词激励(word bias)支持用户针对不同的热词做差异化的激励分配置,在热词整词出词时进一步施加对应的补偿或惩罚,进而提高热词综合效果。
使用 WFST Beam Search 时,我们有两种方式实现热词增强:
- 作用在 TLG 的 ilabel:相当于先应用热词增强,再对热词增强的结果使用语言模型
- 作用在 TLG 的 olabel:相当于先应用语言模型,再对语言模型的输出使用热词增强
热词增强 1.0 作用在 TLG 的 olabel 上:
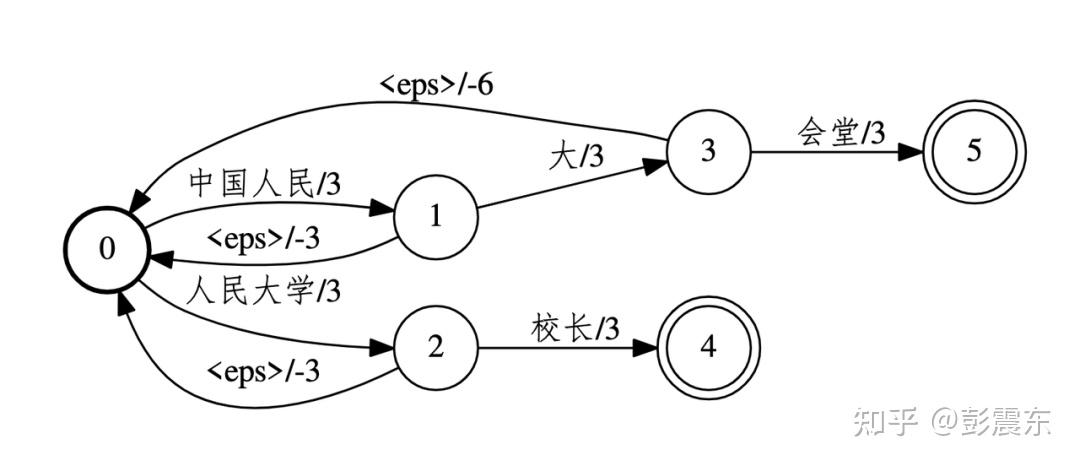
语言模型的输出是词,导致只能在词的级别上回退。由于在分词的时候,使用的是最长匹配策略,可能会产生下述热词图,令“中国人民大学校长”无法正常回退。
这次我们将热词增强作用在 ilabel 上,可以解决上述问题。但是带来的新问题是:增强出来的热词,有可能被语言模型剪枝掉。
FST热词是一种基于 有限状态转换器(Finite State Transducer)的关键词识别技术,它具有较高的准确率和实时性,适用于对大量文本进行快速匹配的场景。 但是,FST热词需要提前构建好词典和规则库,且不支持多语种和变体。
FST目前在语音识别和自然语言搜索、处理等方向被广泛应用。例如,在自然语言处理中,经常会遇到一些针对某些内容法则做出修改的操作,比如:如果c的后面紧接x的话,则把c变为b,FST则是基于这些规则上的数学操作,来把若干个规则整合成一个单程的大型规则,以有效提高基于规则的系统(rule-based system)的效率。其功能类似于字典的功能,但其查找是O(1)的,仅仅等于所查找的key长度。目前Lucene4.0在查找Term时就用到了该算法来确定此Term在字典中的位置。FST 可以表示成FST<Key, Value>的形式,我们可以用O(length(key))的复杂度,找到key所对应的值。除此之外,FST 还支持用Value来查找key以及查找Value最优的key等功能。在查找最优的Value时,会用到求最短路径的Dijikstra算法,但建图过程与此无关。
FST是一种用于映射输入符号序列到输出符号序列的有向图结构。它由一组状态组成,状态之间通过带有权重的转换(transitions)相连。每个转换关联输入符号、输出符号和权重(或代价),用于表示从一个状态转移到另一个状态时的条件。
FST与热词的结合:
- 提高权重或优先级:FST可以通过增加热词的优先级或降低其识别权重,使得在解码过程中,热词的路径更容易被选择。
- 热词优先通路:可以通过引入热词的专有路径(transition paths),使得这些词比其他普通词汇更容易通过FST的状态转换。
- 增强精度:通过调整FST中热词的权重或映射路径,系统在遇到热词时会优先选择包含热词的路径,从而提高识别或转换的准确率。
实现方法:
- 构建基础FST: 首先,需要基于词典或语言模型构建一个基础FST。这个FST将输入符号(如字母、音素或单词)映射到输出符号。在语音识别中,FST通常将输入的音素序列映射为单词。
- 加入热词权重:
- 修改权重:对热词的转换路径赋予更低的权重,降低其状态转换代价,使得解码器(decoder)在搜索时更倾向于选择这些路径。例如,使用一个加权的FST,可以将普通词的转换权重设为较大值,而将热词的权重设为较小值。
- 插入额外路径:将热词的路径单独插入到FST中,创建直接通路,以便系统在解码过程中直接选择这些热词而不需要复杂的转移。
- 组合语言模型和热词FST: 在实际应用中,通常会将热词FST与其他语言模型(如N-gram或神经网络语言模型)结合起来。例如:
- 使用热词FST作为一个小型的子图插入到更大规模的语言模型FST中。
- 热词FST可以作为一个前端过滤器,预处理输入序列以优先选择热词的路径。
- 动态插入热词: 热词列表可能会根据应用场景动态变化。例如,在语音助手中,用户可能会要求系统识别特定的品牌名称。在这种情况下,FST需要支持动态更新,即在运行时动态插入或删除热词路径。这可以通过以下几种方式实现:
- On-the-fly 插入:根据实时需求,将新的热词添加到现有FST结构中,可能使用备用状态机或其他支持增量更新的FST实现。
- 重构FST:当热词发生较大变化时,重新构建FST,以反映新的热词权重。