
InternVL家族:用开源组件缩小与商业多模态模型的差距——一个开创性的开源替代方案,旨在平替GPT-4o
https://github.com/OpenGVLab/InternVL/
[🆕 博客] [🚀 InternVL2 博客] [🗨️ 对话Demo] [🤗 HF Demo] [📖 文档] [🌐 API] [🚀 快速开始]
[📜 InternVL 1.0 论文] [📜 InternVL 1.5 报告] [📖 1.0 中文解读] [📖 1.5 中文解读] [📖 2.0 中文解读]
书生·万象多模态大模型。万象,代表对多模态大模型的愿景,即理解真实世界一切事物和景象,实现全模态全任务的通用智能。它涵盖图像,视频,文字,语音、三维点云等5种模态,首创渐进式对齐训练,实现了首个与大语言模型对齐的视觉基础模型,通过模型”从小到大”、数据”从粗到精”的渐进式的训练策略,以1/5成本完成了大模型的训练。它在有限资源下展现出卓越的性能表现,横扫国内外开源大模型,媲美国际顶尖商业模型,同时也是国内首个在MMMU(多学科问答)上突破60的模型。它在数学、图表分析、OCR等任务中表现优异,具备处理复杂多模态任务、真实世界感知方面的强大能力,是当之无愧的最强多模态开源大模型。
书生万象具有千亿规模参数,支持图像,视频,文字,语音、三维点云等模态。为了使模型能够支持丰富的输出格式,书生万象首次使用了向量链接技术,链接各领域专用解码器,打通梯度传输链路,实现通专融合,支持检测、分割、图像生成、视觉问答等百种细分任务,性能媲美各领域的专家模型。为了训练书生万象模型,我们从各类来源构建了最大图文交错数据集OmniCorpus,包含约160亿图像,3万亿文本词元,相比现有开源图文数据集 ,图像数量扩大了三倍,文本数量扩大了十倍。
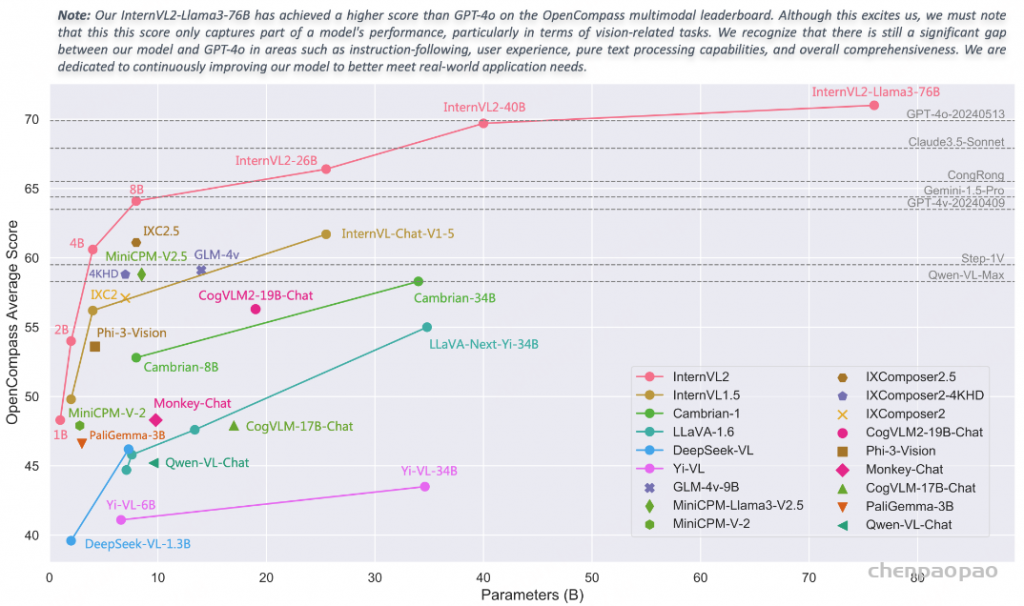
传统的预训练范式直接使用大模型+大数据进行一步到位训练,需要大量的算力资源。为了提高训练效率,研究团队首创了渐进式训练策略,先利用小模型在海量带噪数据上进行高效预训练,然后再使用大模型在较少高质量精选数据上进行高效对齐,模型”从小到大”,数据”从粗到精”,仅需20%的算力资源即可取得同等效果。 采用这种训练策略,我们实现了首个与大模型对齐的视觉基础模型,同时,我们的多模态大模型,展现出卓越的性能,在MathVista(数学)、AI2D(科学图表)、MMBench(通用视觉问答)、MM-NIAH(多模态长文档)等评测上可比肩GPT-4o、Gemini 1.5 Pro等闭源商用大模型。
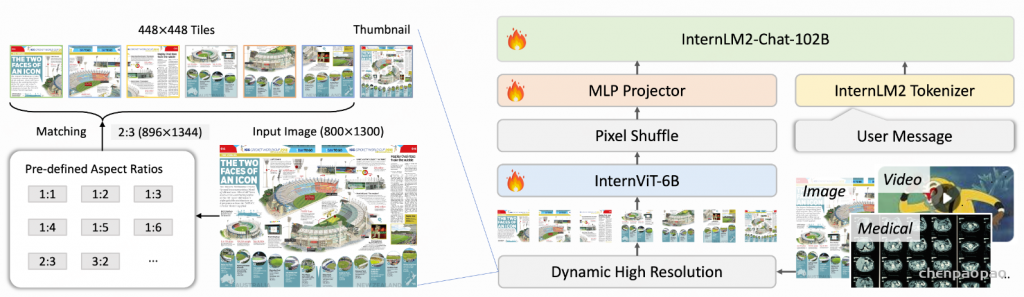
InternVL2系列基于以下设计构建:
1、渐进式与大型语言模型:我们引入了渐进式对齐训练策略,从而使第一个视觉基础模型与大型语言模型原生对齐。通过采用渐进式训练策略,即模型从小到大,而数据从粗到细,我们以相对较低的成本完成了大型模型的训练。这一方法在有限的资源下表现出了出色的性能。
2、多模式输入:通过一组参数,我们的模型支持多种输入模式,包括文本、图像、视频和医疗数据。
3、多任务输出:由我们最近的工作VisionLLMv 2提供支持,我们的模型支持各种输出格式,如图像,边界框和蒙版,展示了广泛的通用性。通过将MLLM与多个下游任务解码器连接,InternVL 2可以推广到数百个视觉语言任务,同时实现与专家模型相当的性能。

性能:
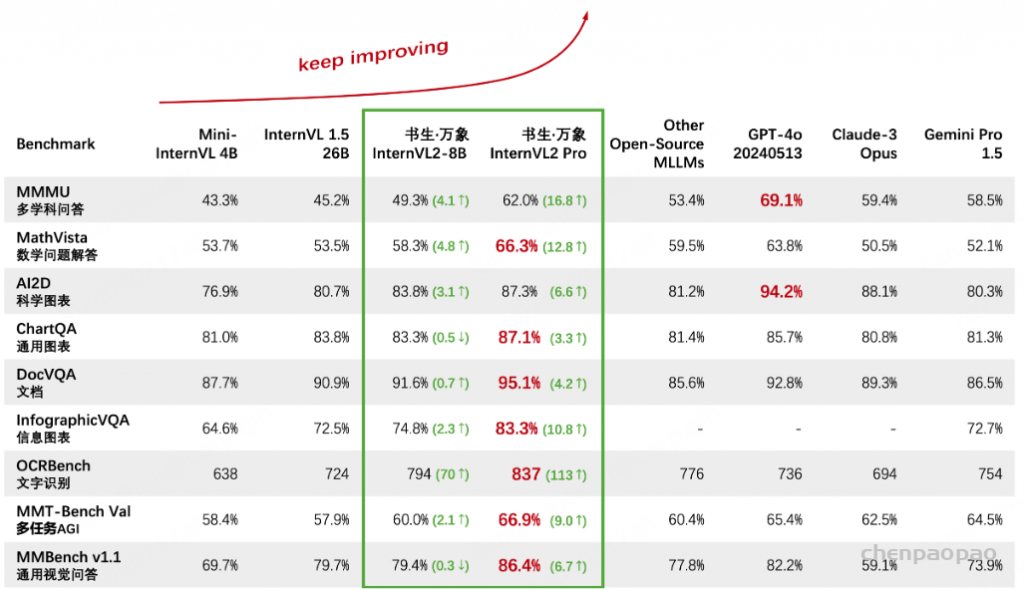
InternVL2在处理复杂的多模态数据方面表现出强大的能力,在数学、科学图表、通用图表、文档、信息图表和OCR等任务中表现出色。例如,在MathVista基准测试中,InternVL2的准确率达到66.3%,大大超过了其他闭源商业模型和开源模型。此外,InternVL2在广泛的基准测试中实现了最先进的性能,包括通用图表基准测试ChartQA,文档基准测试DocVQA,信息图表基准测试InfographicVQA和通用视觉问答基准测试MMBench。
| name | MMMU (val) | MathVista (testmini) | AI2D (test) | ChartQA (test) | DocVQA (test) | InfoVQA (test) | OCRBench | MMB-EN (test) | MMB-CN (test) | OpenCompass (avg score) |
|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4V* (20240409) | 63.1 / 61.7 | 58.1 | 89.4 | 78.1 | 87.2 | – | 678 | 81.0 | 80.2 | 63.5 |
| Gemini Pro 1.5* | 58.5 / 60.6 | 57.7 | 80.3 | 81.3 | 86.5 | 72.7 | 754 | 73.9 | 73.8 | 64.4 |
| Claude3.5-Sonnet* | 68.3 / 65.9 | 67.7 | 94.7 | 90.8 | 95.2 | – | 788 | 79.7 | 80.7 | 67.9 |
| GPT-4o* (20240513) | 69.1 / 69.2 | 63.8 | 94.2 | 85.7 | 92.8 | – | 736 | 83.4 | 82.1 | 69.9 |
| Cambrian-1 | 49.7 / 50.4 | 53.2 | 79.7 | 75.6 | 75.5 | – | 600 | 81.4 | – | 58.3 |
| LLaVA-NeXT Qwen1.5 | 50.1 | 49.0 | 80.4 | 79.7 | 85.7 | – | – | 80.5 | – | – |
| InternVL2-Pro | 58.9 / 62.0 | 66.3 | 87.3 / 96.0 | 87.1 | 95.1 | 83.3 | 837 | 87.8 | 87.2 | 71.8 |
| name | MMMU (val) | MathVista (testmini) | AI2D (test) | ChartQA (test) | DocVQA (test) | InfoVQA (test) | OCRBench | MMB-EN (test) | MMB-CN (test) | OpenCompass (avg score) |
|---|---|---|---|---|---|---|---|---|---|---|
| InternVL2-1B | 35.4 / 36.7 | 37.7 | 64.1 | 72.9 | 81.7 | 50.9 | 754 | 65.4 | 60.7 | 48.3 |
| InternVL2-2B | 34.3 / 36.3 | 46.3 | 74.1 | 76.2 | 86.9 | 58.9 | 784 | 73.2 | 70.9 | 54.0 |
| InternVL2-4B | 47.0 / 48.3 | 58.6 | 78.9 | 81.5 | 89.2 | 67.0 | 788 | 78.6 | 73.9 | 60.6 |
| InternVL2-8B | 49.3 / 51.2 | 58.3 | 83.8 | 83.3 | 91.6 | 74.8 | 794 | 81.7 | 81.2 | 64.1 |
| InternVL2-26B | 48.3 / 50.7 | 59.4 | 84.5 | 84.9 | 92.9 | 75.9 | 825 | 83.4 | 82.0 | 66.4 |
| InternVL2-40B | 53.9 / 55.2 | 63.7 | 87.1 | 86.2 | 93.9 | 78.7 | 837 | 86.8 | 86.5 | 69.7 |
| InternVL2-Llama3-76B | 55.2 / 58.2 | 65.5 | 87.6 | 88.4 | 94.1 | 82.0 | 839 | 86.5 | 86.3 | 71.0 |
| InternVL2-Pro | 58.9 / 62.0 | 66.3 | 87.3 / 96.0 | 87.1 | 95.1 | 83.3 | 837 | 87.8 | 87.2 | 71.8 |
实例:

