
最近在做ASR语音识别任务,基于阿里FunASR框架,特此记录下跟语言模型(LM)相关知识。
语言模型解码
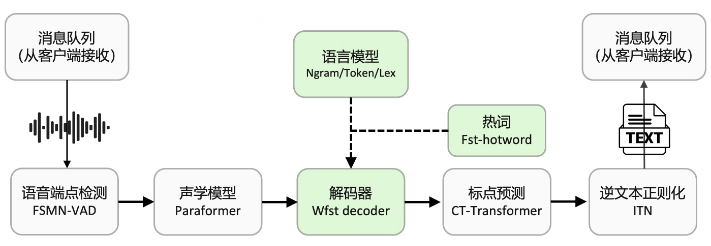
传统基于CD-phone声学建模ASR系统解码器普遍采用HCLG构建解码网络,当前方案中paraformer声学模型直接对音素或字符建模,为此我们采用TLG(Token、Lexicon、Grammar)结构构建统一解码网络,直接将音素/字符序列[ paraformer声学模型 ]、发音词典、语言模型编译形成T、L、G三个wfst子网络,再通过composition、determinization、minimization等一系列操作生成统一解码网络。
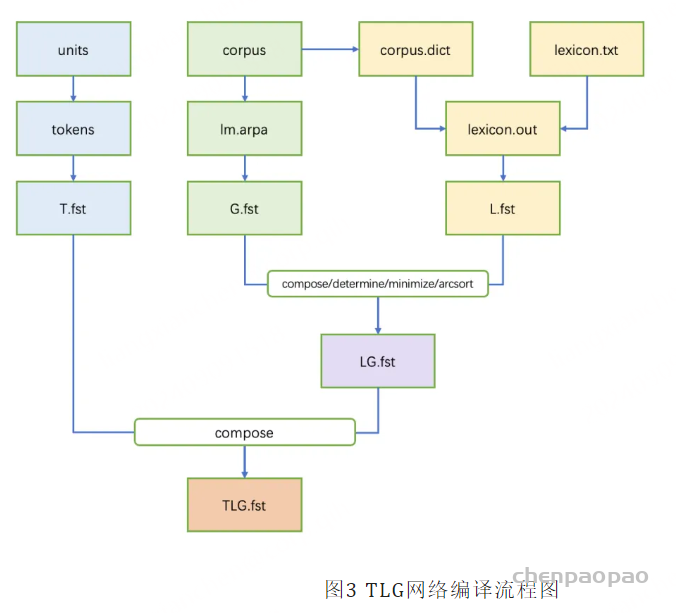
我们借鉴EESEN方案,基于openfst/kaldi构建TLG解码网络编译pipeline,支持从原始语料和发音词典到最终解码资源的全流程编译,便于用户自行定制适合自身的解码资源。如下是TLG网络编译流程图。
为什么需要语言模型?
为什么有些句子比其他句子更 流畅(fluent),或者说 更自然(natural)?
我们为什么关心这个问题呢?
因为在很多应用中,我们很关心语言的流畅性与自然性。
例如,在语音识别中,你听到一句话,并且想将它转换成文本,所以你需要区分这段语音可能对应的不同文本,并从中选择更加流畅和自然的版本。比如下面两个句子的发音很接近:recognise speech > wreck a nice beach,从流畅和自然的角度考虑,显然,左边的句子更有可能代表了讲话者的本意。而语言模型可以帮你做到这一点,它会告诉你 “recognise speech” 是人们更倾向表达的意思。
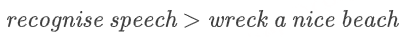
- 那么,我们如何衡量这种 “优度(goodness)”(或者说流畅度、自然度)呢?
我们用 概率 来衡量它,而语言模型提供了一种很自然的方式来估计句子的概率。 - 在此基础上,一旦你构建了一个语言模型,你还可以用它来 生成(generation) 语言。
语言模型可以用于哪些任务呢?
- 主要用于:
- 语音识别(Speech recognition)
- 拼写纠错(Spelling correction)
- 查询补全(Query completion)
- 光学字符识别(Optical character recognition)
- 其他生成任务:
- 机器翻译(Machine translation)
- 概括(Summarisation)
- 对话系统(Dialogue systems)
N-gram 语言模型
N-Gram是基于一个假设:第n个词出现与前n-1个词相关,而与其他任何词不相关(这也是隐马尔可夫当中的假设)。整个句子出现的概率就等于各个词出现的概率乘积。各个词的概率可以通过语料中统计计算得到。通常N-Gram取自文本或语料库。
概率:从联合概率到条件概率
我们的目标是得到一个由 m 个单词组成的任意序列(即一个包含 m 个单词的句子)的概率:
P(w1,w2,…,wm)
第一步是利用链式法则(chain rule)将联合概率转换成条件概率的连乘形式:
P(w1,w2,…,wm)=P(w1)P(w2∣w1)P(w3∣w1,w2)⋯P(wm∣w1,…,wm−1)
马尔可夫假设(The Markov Assumption)
目前,这仍然是一个比较棘手的问题,因为随着上下文的不断增加,我们构建的模型中将包含越来越多的参数。所以这里,我们采用一种称为 “马尔可夫假设” 的简化假设:某个单词出现的概率不再依赖于全部上下文,而是取决于离它最近的 n 个单词。因此,我们得到: P(wi∣w1,…,wi−1)≈P(wi∣wi−n+1,…,wi−1)
对于某个很小的 n:
- 当 n=1 时,一个 unigram 模型:P(w1,w2,…,wm)=∏i=1mP(wi)在 unigram 模型中,我们假设一个句子出现的概率等于其中每个单词单独出现的概率的乘积,这意味着每个单词出现的概率之间相互独立,即我们并不关心每个单词的上下文。
- 当 n=2 时,一个 bigram 模型:P(w1,w2,…,wm)=∏i=1mP(wi∣wi−1)在 bigram 模型中,我们假设句子中每个单词出现的概率都和它前一个单词出现的概率有关。
- 当 n=3 时,一个 trigram 模型:P(w1,w2,…,wm)=∏i=1mP(wi∣wi−2,wi−1)在 trigram 模型中,我们假设句子中每个单词出现的概率都和它前两个单词出现的概率有关。
最大似然估计
我们如何计算这些概率?
非常简单,我们只需要一个大的用于训练的语料库(corpus),然后我们就可以根据语料库中各个单词的计数(counts),利用最大似然估计来估计该单词出现的概率:
- 对于 unigram 模型:
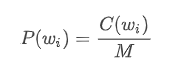
其中,C 是一个计数函数,C(wi) 表示单词 wi 在语料库中出现的次数,M 表示语料库中所有单词 tokens 的数量。
- 对于 bigram 模型:

其中,C(wi−1,wi) 表示单词 wi−1 和单词 wi 前后相邻一起出现的次数。
- 对于 n-gram 模型:
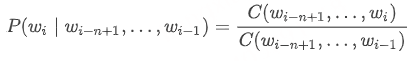
同理,我们计算 n-gram 出现的次数,除以 (n-1)-gram(即上下文)出现的次数。
序列的开头和结尾表示
在我们进入例子之前,我们需要用一些特殊的记号表示一个序列的开始和结束:
- <s> 表示句子的开始
- </s> 表示句子的结束
Trigram 例子
现在,让我们来看一个玩具例子,假设我们有一个只包含两个句子的语料库。
语料库:
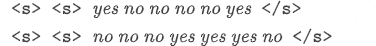
可以看到,每个句子开头有两个起始标记,因为我们采用的是 trigram 模型。
我们希望知道下面的句子在一个 trigram 模型下的概率是多少?
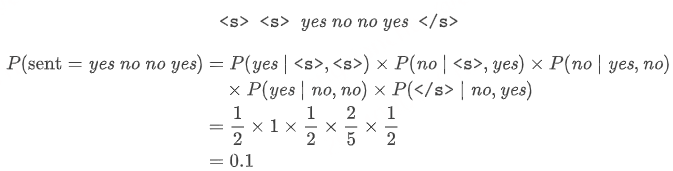
说明:
- 首先,我们对要计算的句子的概率按照 trigram 模型拆分成条件概率的连乘形式。
- 然后,对于等式右边的每一个条件概率项,按照 trigram 模型中的条件概率计算公式,分别统计 “当前单词连同它的上下文” 以及 “单独的上下文部分” 在语料库中出现的次数,并将两者相除,得到该项的计算结果。
例如,对于上面等式右边第一个条件概率项,我们考虑句子中第一个单词 “yes” 及其相邻的 bigram 上下文 “<s><s>”:
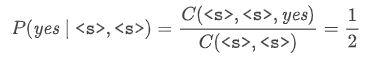
可以看到,子序列 “<s><s>yes” 在语料库中只出现过 1 次;而子序列 “<s><s>” 在语料库中一共出现了 2 次,所以第一个条件概率项的结果为 12。其余各条件概率项的计算方式同理,另外请注意,在计算第四个条件概率项时,bigram 上下文 “nono” 在语料库中一共出现了 5 次。
N-gram 语言模型的一些问题
-
语言通常具有长距离效应 —— 需要设置较大的 n 值
有些词对应的上下文可能出现在句子中距离该词很远的地方,这意味着如果我们采用固定长度的上下文(例如:trigram 模型) ,我们可能无法捕捉到足够的上下文相关信息。例如:The lecture/s that took place last week was/were on processing.在上面的句子中,假如我们要决定系动词 be 是应该用第三人称单数形式 was 还是复数形式 were,我们需要回头看句子开头的主语是 lecture 还是 lectures。可以看到,它们之间的距离比较远,如果我们采用 bigram 或者 trigram 模型,我们无法得到相关的上下文信息来告诉我们当前位置应该用 was 还是 were。这是所有有限上下文语言模型(finite context language models)的一个通病。 -
计算出的结果的概率通常会非常小
你会发现,一连串条件概率项连乘得到的结果往往会非常小,对于这个问题,我们可以采用取对数计算 log 概率来避免数值下溢(numerical underflow)。 -
对于不存在于语料库中的词,无法计算其出现概率
如果我们要计算概率的句子中包含了一些没有在语料库中出现过的单词(例如:人名),我们应该怎么办?
一种比较简单的技巧是,我们可以用某种特殊符号(例如:<UNK>)来表示这些所谓的 OOV 单词(out-of-vocabulary,即不在词汇表中的单词),并且将语料库中一些非常低频的单词都替换为这种表示未知单词的特殊 token。 -
出现在新的上下文(context)中的单词
默认情况下,任何我们之前没有在语料库中见过的 n-gram 的计数都为 0,这将导致计算出的 整个句子的概率为 0。这个问题和前面的 OOV 单词的问题类似,我们的语料库中可能已经包含了这些单词,但是并没有包含该单词在新句子中对应的特定的 n-gram(即上下文信息)。这意味着该单词在新的句子中对应 n-gram 对于语言模型来说是全新的,而且因为 n-gram 的组合存在如此多的可能性,以至于语料库很难将所有的可能性都覆盖到。例如:假设我们构建了一个 five-gram 语言模型,我们的语料库中一共有 20000 个词汇,那么一共存在多少种可能的 five -gram 组合?答案是:200005。这是一个非常非常大的数字,以至于无论我们的训练语料库有多大,都不可能捕捉到所有的可能性组合。这是一个相当常见的问题,并且很重要。如果我们回顾一下链式法则,可以看到所有的条件概率都连乘在一起,所以只要其中某一项在计算子序列时 n-gram 的计数为 0,那么最终 计算出的整个句子的概率就会为 0。为此,我们需要对语言模型进行 平滑处理(smoothing)。
平滑处理
- 基本思想:给之前没有见过的事件赋予概率。
- 必须附加一个约束条件:P(everything)=1
- 有很多不同种类的平滑处理方法:
- 拉普拉斯平滑(Laplacian smoothing,又称 Add-one smoothing,即 “加一” 平滑)
- “加 k” 平滑(Add-k smoothing)
- Jelinek-Mercer 插值(又称 线性插值平滑)
- 卡茨回退法(Katz backoff)
- 绝对折扣(Absolute discounting)
- Kneser-Ney
- ……
拉普拉斯平滑(“加一” 平滑)
简单思想:假装我们看到的每一个 n-gram 都比它们实际出现的次数多 1 次。
- 这意味着即使是那些我们在语料库中没有见过的 n-gram,我们也将它们出现的次数记为 1 次。所以对于一个新句子中的任何东西都至少有 1 次计数。
- 对于 unigram 模型(V= 词汇表):
在之前的模型中,我们只是简单的计算单词 wi 在语料库中出现的次数 C(wi) ,然后除以语料库中所有单词 tokens 的数量 M。
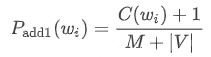
现在,对于分子而言,我们总是在它此前的基础上加上 1。然后,为了保证它仍然是一个合法的概率分布,即单词 wi 遍历词汇表中所有可能情况的的概率之和 ∑i=1|V|P(wi)=1,我们需要在此前分母 M 的基础上加上词汇表的长度 |V|(即语料库中所有单词 types 的总数)。
- 对于 bigram 模型:
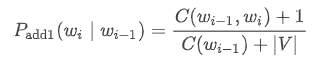
同样地,我们在之前分子的基础上加 1,在分母的基础上加 |V|。
所以现在,我们解决了之前新句子中的未知单词或者 n-gram 的计数为 0 从而导致最终计算出的概率为 0 的问题。
“加 k” 平滑
-
“加一” 往往太多了
但是很多时候,加 1 会显得太多了,我们并不想每次都加 1,因为这会导致原本的罕见事件可能变得有点过于频繁了。并且我们丢弃了所观测的 n-gram 的太多有效计数。 -
用 “加 k” 来代替 “加一”
这种方式也被称为 Lidstone 平滑(Lidstone Smoothing)。 - 对于 trigram 模型,公式如下:
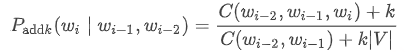
可以看到,和 “加一” 平滑类似,只是我们将分子中的加 1 变成了加 k,并且为了满足单词 wi 遍历词汇表中所有可能情况的概率之和为 1,我们在分母中的 |V| 前面乘了一个系数 k。
-
必须选择一个 k
事实上,如何选择一个合适的 k 值对于模型影响非常大。k 在这里实际上是一个超参数,我们需要尝试对其进行调整以便找到一个使模型表现比较好的 k 值。
Absolute Discounting 平滑
另外一种更好的方法是采用 绝对折扣平滑(Absolute Discounting):
- 从每个 观测到的 n-gram 计数中 “借” 一个 固定的概率质量(a fixed probability mass) d。
- 然后将其 重新分配(redistributes) 到 未知的 n-grams 上。
Backoff 平滑
基本上,我们会按照不断改进的顺序来介绍各种平滑处理方式的变体,由此,我们可以看到对于这些平滑方式的评估。现在,我们继续介绍另一种更好的平滑方式:Backoff 平滑。
- 在之前的 Absolute Discounting 平滑中,我们从观测到的每个 n-gram 计数中 “借来” 一个固定的概率质量,并将它们重新 平均 分配给所有的未知 n-grams。
- Katz Backoff:概率质量的重新分配是基于一个 低阶(lower order) 模型(例如:unigram 模型)
例如,假设我们现在有一个 bigram 模型,当我们将概率质量重新分配到未知的 bi-grams 时,我们将基于上下文单词的 unigram 概率进行重新分配。因为比例很简单,如果我们看到上下文出现次数越多,我们就给它更高的权重。
对于一个 bigram 模型,它的 Katz Backoff 平滑的概率公式 如下:

我们为什么将这种方式称为 Backoff(回退) 呢?
因为我们在碰到未知的 n-grams 的时候会将原来的模型回退到一个更低阶的 (n-1)-gram 模型:对于一个 bigram 模型,我们在计算未知 bi-grams 的概率时将回退到 unigram 模型;而对于一个 trigram 模型,我们在计算未知 tri-grams 的时候将回退到 bigram 模型。所以,我们总是只回退一步。
Kneser-Ney 平滑
现在,我们将介绍一种比 Katz Backoff 更好的平滑处理方式:Kneser-Ney 平滑
- 概率质量分配基于当前单词 w 出现在 不同上下文 中的次数。
对于概率质量重新分配的问题,相比 Katz Backoff 中只是简单地基于低阶模型,Kneser-Ney 平滑采用的方法是基于当前单词 w 在多少个 不同的上下文 中出现过,或者说是基于该单词的 多功能性(versatility)。
回忆前面 “glasses” 和 “Francisco” 的例子,其中 ,“Francisco” 是一个非常特殊的词,它的 versatility 非常低,因为它很可能只在上下文单词 “San” 后面出现过。因此,对于其他绝大多数的上下文单词,它们后面都不太可能出现 “Francisco” 这个词。而相比之下,“glasses” 这个词具有较高的 versatility,它可能在很多不同的上下文单词之后都出现过。 - 这种度量被称为 多功能性(versatility) 或者 延续概率(continuation probability)

可以看到,对于观测到的 n-grams,Kneser-Ney 概率和 Katz Backoff 概率两者是相同的。而对于那些未知的 n-grams,Kneser-Ney 概率中从观测 n-grams 中 “借来” 的概率质量 α(wi−1) 与之前一样保持不变,而之前关于低阶模型 P(wi) 的部分则由我们所说的延续概率 Pcont(wi) 来替代。
在延续概率 Pcont(wi) 的计算公式中:分子部分计算的是一共有多少个 唯一 的上下文单词 wi−1 和当前单词 wi 共同出现过(co-occurrence);而分母部分就是将所有可能的单词 wi 对应的不同共现上下文单词数量(即分子部分)进行一个累加。
Interpolation
我们将介绍最后一种也是最好的一种平滑处理方式:插值(Interpolation)
-
将不同阶数的 n-gram 模型结合起来 的更好的平滑方式。
我们在前面提到过的 Katz Backoff 平滑:对于一个 trigram 模型,如果我们遇到了一些未知的 tri-grams,我们将回退到一个低阶模型。
但是一种更好的做法是:将不同阶数的 n-gram 模型结合起来。 -
逐步缩短的上下文的概率加权求和
例如,对于一个 trigram 模型,我们计算未知 tri-grams 的平滑概率时会贯穿 trigram、bigram 和 unigram 三种阶数的模型。 - 一个 trigram 模型下的 Interpolation 平滑概率:

我们可以按照下面的步骤计算单词 wm 在上下文单词 “wm−2” 和 “wm−1” 之后出现的 Interpolation 平滑概率:
- 首先计算 trigram 概率 P3∗,并将其乘以一个系数 λ3;
- 然后计算 bigram 概率 P2∗,并将其乘以一个系数 λ2;
- 然后计算 unigram 概率 P1∗,并将其乘以一个系数 λ1;
- 最后,将三者相加得到最终结果。
并且,为了保证所得到的仍然是一个合法的概率分布,我们需要满足所有 λ 之和为 1。此外,这些 λ 的值甚至并不需要我们手动设置,而是由模型通过一些留存数据学习到的,因为我们想知道对于这些不同阶数的模型,什么样的 Interpolation 方式是最高效的。
Interpolated Kneser-Ney 平滑
基于 Interpolation,我们得到了 Kneser-Ney 的最后一种版本:Interpolated Kneser-Ney 平滑。
Interpolation 替代 back-off:
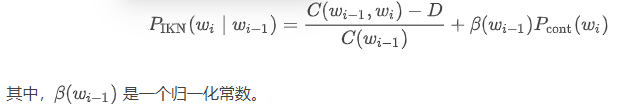
这里,我们所做的唯一改变就是:将之前观测 n-grams 和未知 n-grams 两种情况加在一起,取代了之前的 back-off 操作。所以,相比之前二选一的情况,现在我们都合并在一个公式里。
另外,相比之前的固定概率质量 α(wi−1),这里我们替换为归一化常数 β(wi−1),以确保上下文 wi−1 对应的所有可能的 wi 的概率 PIKN(wi∣wi−1) 之和为 1。
这就是我们到目前为止介绍过的最有效的平滑方式,在实际应用中有很多 n-gram 语言模型都是基于 Interpolated Kneser-Ney 平滑实现的。
实践应用
- 在实践中,我们通常采用 Kneser-Ney 语言模型并将 5-grams 作为最高阶数。
- 对于每个 n-gram 阶数都有不同的 discount 值。
- 当我们试图学习如何在它们之间进行 Interpolation 时,我们将从数据中学习。
生成语言
在最后一部分中,我们将介绍如何利用语言模型来 生成语言(Generating Language)。
我们这里讨论的是利用语言模型生成语言的一种通用的方法,并不仅仅局限于 n-gram 语言模型。
但是我们还是会以 n-gram 语言模型作为例子:
- 给定一个初始单词,从语言模型定义的概率分布中抽取一个词作为下一个出现的单词。
- 在我们的 n-gram 语言模型中包含 (n−1) 个起始 tokens,用于提供生成第一个单词所需的上下文。
- 永远不会生成起始标记 <s>,它只作为初始单词的生成条件
- 生成 </s> 来结束一个序列
例子:Bigram 语言模型
- Sentence =<s>
- P(?∣<s>)=“a”
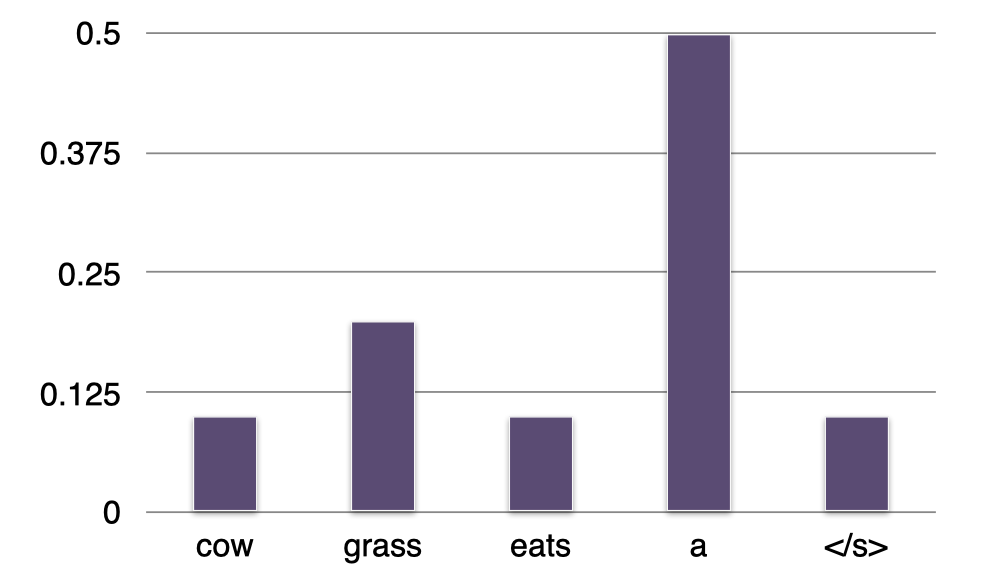
这里是一个很简单的例子,我们有一个 bigram 语言模型。现在有一个空句子,即只包含一个起始标记 <s>。我们试图预测在给定一个起始标记 <s> 的条件下,下一个最有可能出现的单词是什么。所以,我们会利用 bigram 语言模型来逐个检查词汇表中每个单词 w 的条件概率 P(w∣<s>),并选择其中概率最大的那个单词作为我们的预测结果。这里,我们可以看到单词 “a” 出现在一个句子开头的概率最大,我们将它添加到句子中。
- Sentence =<s> a
- P(?∣a)=“cow”
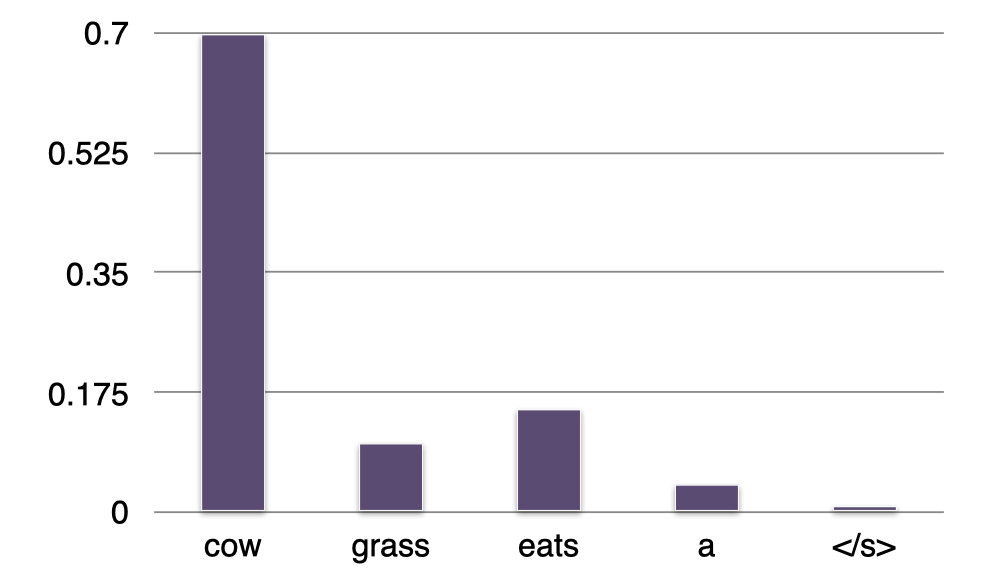
现在我们的句子有了第一个单词 “a”,我们想知道下一个最有可能出现的单词是什么。还是和之前一样,我们逐一检查词汇表中各个词在给定上下文单词 “a” 的情况下,哪个词对应的条件概率最大。可以看到,这里单词 “cow” 出现在单词 “a” 之后的概率最大,所以我们将它添加到句子中。
- Sentence =<s> a cow
- P(?∣cow)=“eats”
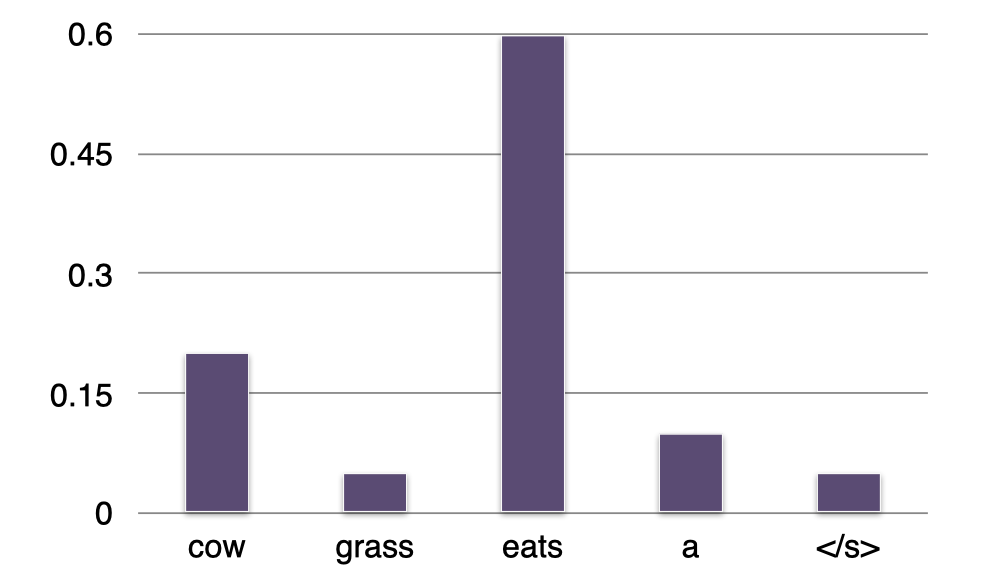
重复上面的步骤,我们得到了下一个最有可能的单词 “eats” 并将它添加到句子中。
- Sentence =<s> a cow eats
- P(?∣eats)=“grass”
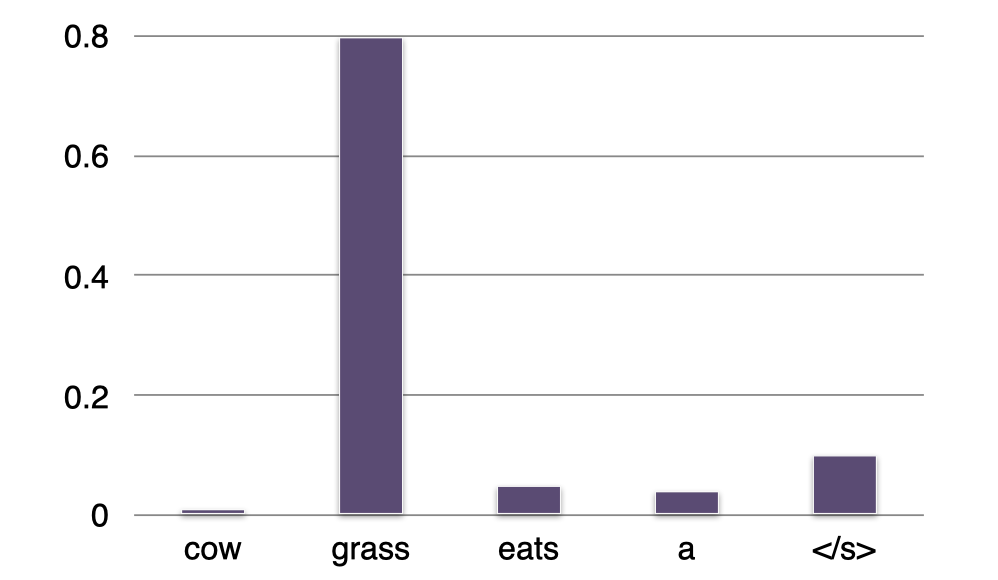
继续,我们得到单词 “grass” 并将它添加到句子中。
- Sentence =<s> a cow eats grass
- P(?∣grass)=“</s>”
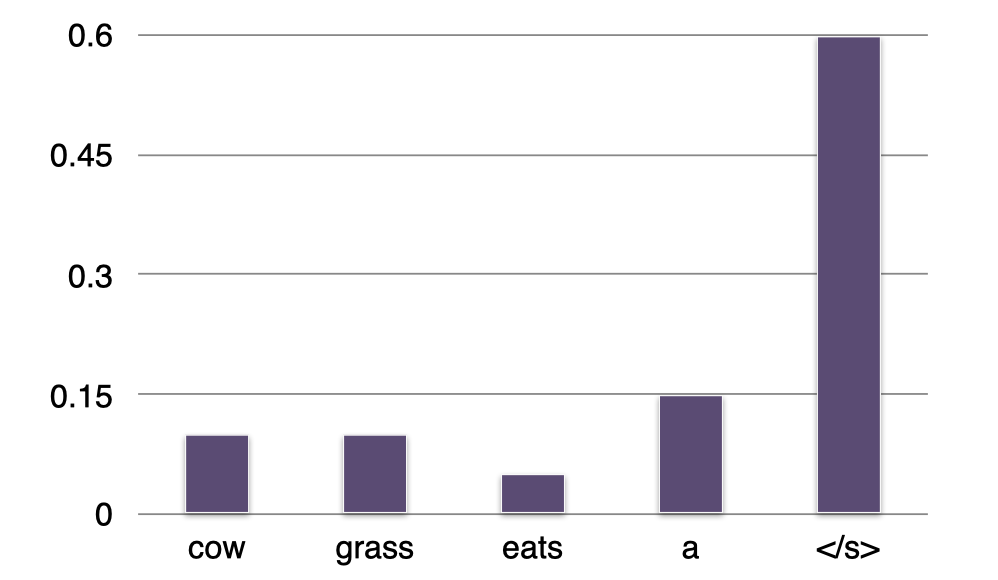
最终,我们预测单词 “grass” 后面最有可能出现的是结束标记 “</s>”,我们将它添加到句子中。
- Sentence =<s> a cow eats grass </s>
- 完成
现在我们得到了一个由这个 bigram 语言模型生成的句子:a cow eats grass
如何选择下一个单词
-
Argmax:在每一轮中选择与上下文共现概率最高的那个单词。
-
贪婪搜索(Greedy search )
这其实是一种贪婪搜索策略,因为即使在每一步中我们都选择概率最高的那个单词,也无法保证最终生成的句子具有最优的概率。
-
贪婪搜索(Greedy search )
-
Beam search decoding
一种更好的方法是 Beam search decoding,它在机器翻译中应用非常广泛。- 在每轮中,我们跟踪概率最高的前 N 个单词
- 我们总是检查这几个候选单词给出的完整句子的概率
- 这种方法可以生成具有 近似最优(near-optimal) 概率的句子
-
从分布中随机抽样
另一种方法是从语言模型给出的概率分布中随机抽样,例如:temperature sampling
评估语言模型
如何评估一个语言模型的质量?
评估
语言模型的评估通常有两种范式:
-
外部的(Extrinsic)
这种评估范式常见于下游应用中,我们根据其反馈来评估语言模型的表现。比如对于机器翻译中的某些任务,我们可以比较不同语言模型在完成该任务上的表现。- 例如:拼写纠错、机器翻译
-
内部的(Intrinsic)
在这种评估范式下,我们不依赖任何下游应用,而是观察我们的语言模型在保留测试集上的 Perplexity。- 在保留测试集(held-out test set)上的 Perplexity
- Perplexity(困惑) 衡量的是我们对于模型在测试数据上给出的预测的置信度。置信度越高,对应的 Perplexity 就越低,代表我们的模型越好。
Perplexity
- 整个测试集的逆概率(Inverse probability)
- 通过单词 tokens(包括结束标记 </s>)的数量实现归一化(Normalization)
- 假设我们保留的测试集语料库是一个由 m 个单词 w1,w2,…,wm 组成的序列,我们用 PP 表示 Perplexity。从下面的公式可以看到,它是通过对整个测试集的概率 P(w1,w2,…,wm) 取倒数,然后再开 m 次方得到的:
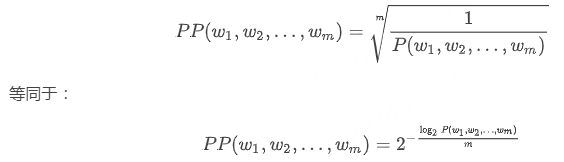
- 如果我们遇到未知单词(OOV),我们通常是直接忽略掉,因为我们没有办法表示它们。
-
Perplexity 越低,模型表现越好。
假如我们模型的 Perplexity 只有 1,那么这是最好的情况。因为当我们的测试集语料库上的概率 P(w1,w2,…,wm)=1 时,PP(w1,w2,…,wm)=1。而对于一个非常差的语言模型,可能在测试集上的概率 P(w1,w2,…,wm)=0,此时模型的 Perplexity 将趋近 ∞。所以,最理想的情况是 Perplexity 等于 1,当然,我们永远不可能达到这个值。
总结
- N-gram 模型在捕捉语言的可预测性方面是一种简单且高效的方法。
模型的构建很容易:我们只需要一个大的语料库,并且对单词和上下文进行计数即可。 - 信息可以通过无监督的方式推导得出,可以扩展到大型语料库。
- 由于稀疏性的存在,需要进行平滑处理才能保证有效性。
我们需要一些工程上的技巧处理稀疏性问题,例如:smoothing、back-off、interpolation 等。
虽然 n-gram 模型非常简单,但是它在实践中的效果非常好。所以,在构建语言模型时,我们通常会选择将 n-gram 模型作为 baseline,尽管目前有很多模型都采用了深度学习。
思考
思考: Interpolation、Interpolated Kneser-Ney 和 Kneser-Ney 之间有什么区别?我们应当如何判断应该采用哪种方法?
首先,我们应该明确一点:Interpolated(插值)、Smoothing(平滑)和 Backoff(回退)都是用来解决数据稀疏问题(sparsity)的方法。我们在这节课中讨论的前 3 种平滑方法(拉普拉斯、“加 k” 和 Lidstone)都是在 和原先的 N-gram 模型相同的阶数 内重新分配概率,将概率质量从常见情况向罕见情况进行偏移。
Interpolation 和 Backoff 都是通过 结合不同阶数的 N-gram 模型 来解决这个问题。对于 Backoff 而言,如果高阶 higher-gram 的计数为 0,那么它将完全落回低阶 lower-gram;而 Interpolation 则是通过将我们所有的 N-gram 模型加权求和来将它们结合起来。
现在,当我们采用低阶模型时又会带来一个新的问题。例如,对于单词 “Old” 和 “Zealand”,很可能它们的 bi-gram “Old Zealand” 计数为 0,所以我们需要依赖 unigram 模型提供的概率。想象一下,如果单词 “Zealand” 具有一个非常高的 unigram 概率,那么对于这两个词的 bi-gram,我们还是可以得到一个相对较高的共现概率,而这不是我们希望看到的。
Kneser-Ney Smoothing 中引入了所谓 延续计数(continuation count) 的概念。因为在大多数情况下,单词 “Zealand” 只出现在上下文单词 “New” 的后面,所以对于单词 “Zealand” 出现在上下文单词 “Old” 后面这种情况(即 bi-gram “Old Zealand”)的延续计数会非常低。到这里,我们通过 在不同上下文中的频率计数 解决了上述例子中的问题。
回到原问题中提到的哪种方法更好,我们可以在 Backoff 或者 Interpolation 二者中选择一种来使用 Kneser-Ney Smoothing。通常来说,Interpolation 可能更合适,因为这种方式更灵活(因为我们考虑了所有阶数的 N-gram 模型)。