
LLaMA-Omni是基于Llama-3.1-8B-Instruct构建的低延迟、高质量的端到端语音交互模型,旨在实现GPT-4o级别的语音功能。
HF链接–https://huggingface.co/ICTNLP/Llama-3.1-8B-Omni
论文链接–https://arxiv.org/pdf/2409.06666
代码链接–https://github.com/ictnlp/LLaMA-Omni
总的来说,LLaMa-Omni的训练方法第一阶段类似Qwen2Audio模型,都是用whisper large作为音频编码器,“输入文本-语音特征-文本”的输入,输出文本,用于训练LLM和 Speech Adaptor 。第二阶段,为了将文本输出转成语音输出,固定LLM和 Speech Adaptor, 用 LLM输出的隐藏状态作为输入,生成与语音响应对应的HUBERT离散单元序列,然后使用该序列合成语音。缺点:hubert token合成的语音生硬、缺乏声学信息,后续可以替换为WavTokenizer 或者 RVQ【encodec、soundsream】的方法合成带声学特征的语音。因为输出的是离散的hubert token,可以一边输出,一边流式合成语音。第一阶段本质上是让LLM拥有“耳朵”,第二阶段是让LLM能够”说话“。但一二阶段分离训练会不会导致第一阶段LLM学习到的都是一些语义知识,声学信息都损失掉了,这样的话即使在第二阶段替换不同的token方法也很难从LLM的输出中学习到声学信息。另外,在数据集的制作上,使用LJSpeech数据集训练了一个TTS,缺乏丰富的情感控制,后续可以考虑使用Seed-TTS /cosyvoice/SeedTTS 等情感可控的等语音合成方法来合成响应的音频。 对于LLM主干网络的选择,可以考虑使用Qwen2Qudio这样的经过音频预训练过的LLM模型和语音编码器作为主干,只需要对音频解码器进行第二步的解码器微调训练。
“自从OpenAI推出了GPT-4o之后,它开启了语音交互大模型的大门。国内相继也有很多大公司和创业公司开始模仿它,计划推出自己的语音交互大模型。ChatGPT等大语言模型通常只支持基于文本的交互,而GPT4o的出现使得通过语音与LLM交互成为可能,按照极低的延迟响应用户的指令,并显著提升了用户体验。然而,开源社区在构建基于LLM的语音交互模型方面仍然缺乏探索。当前,实现与LLM的语音交互的最简单方法是通过基于自动语音识别(ASR)和文本到语音(TTS)模型的三段式级联系统,其中ASR模型将用户的语音指令转录为文本,TTS模型将LLM的响应合成为语音。然而,由于级联系统顺序输出转录文本、文本响应和语音响应,因此整个系统往往具有更高的延迟。
为了解决这个问题,作者提出了LLaMA-Omni,这是一种新的模型架构,旨在与LLM进行低延迟和高质量的语音交互。LLaMA-Omni集成了预训练语音编码器、语音适配器、LLM和流式语音解码器。它消除了对语音转录的需要,并且可以直接从语音指令中以极低的延迟同时生成文本和语音响应。LLaMA-Omni在内容和风格上都能提供更好的响应,响应延迟低至226ms。此外,整个LLaMA-Omni模型仅需要在4个GPU上训练3天左右。
💪 基于Llama-3.1-8B-Instruct构建,确保高质量的响应。
🚀 低延迟语音交互,延迟低至226 ms。
🎧 同时生成文本和语音响应。
♻️ 仅️使用4个GPU,在不到3天的时间内完成训练。
语音交互大语言模型发展历程
SpeechGPT算法简介
2023年,Dong Zhang, Shimin Li等人提出“SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities”算法。本文提出了SpeechGPT,这是一种具有内在跨模态会话能力的大型语言模型,能够感知和生成多模型内容。通过离散语音表示,作者首先构建了SpeechInstruct,这是一个大规模的跨模态语音指令数据集。此外,作者采用了一种三阶段训练策略,包括模态适应预训练、跨模态教学微调和模态教学链微调。大量的实验结果表明:SpeechGPT具有令人印象深刻的能力,可以遵循多模态人类指令,并突出了用一个模型处理多种模态的潜力。
SALMONN算法简介
2024年,Changli Tang, Wenyi Yu等人提出“SALMONN: Towards generic hearing abilities for large language models”算法。SALMONN是一个支持语音、音频事件和音乐输入的大型语言模型(LLM),由清华大学电子工程系和字节跳动共同开发。SALMONN可以感知和理解各种音频输入,从而获得多语言语音识别和翻译以及音频语音协同推理等新兴功能,而不是仅语音输入或仅音频事件输入。这可以被视为赋予了LLM“耳朵”和认知听觉能力,这使SALMONN朝着有听觉功能的通用人工智能迈出了一步。
Qwen2-audio算法简介
2024年7月,Yunfei Chu, Jin Xu等人提出“Qwen2-audio technical report”算法。作为一个大规模音频语言模型,Qwen2-Audio能够接受各种音频信号输入,并根据语音指令执行音频分析或直接响应文本。作者介绍了两种不同的音频交互模式:语音聊天 voice chat 和音频分析 audio analysis。语音聊天:用户可以自由地与 Qwen2-Audio 进行语音互动,而无需文本输入;音频分析:用户可以在互动过程中提供音频和文本指令对音频进行分析;作者已经开源了 Qwen2-Audio 系列的两个模型:Qwen2-Audio-7B和Qwen2-Audio-7B-Instruct。
LLaMA-Omni背景简介
以ChatGPT为代表的大型语言模型(LLM)已经成为强大的通用任务求解器,它们能够通过对话交互帮助人们解决日常生活中的问题。然而,大多数LLM目前只支持基于文本的交互,这限制了它们在文本输入和输出不理想的情况下的应用场景。最近,GPT4o的出现使得通过语音与LLM交互成为可能,按照极低的延迟响应用户的指令,并显著提升了用户体验。然而,开源社区在构建基于LLM的语音交互模型方面仍然缺乏探索。因此,如何利用LLM实现低延迟和高质量的语音交互模型是一个亟待解决的重大挑战。 当前,实现与LLM的语音交互的最简单方法是通过基于自动语音识别(ASR)和文本到语音(TTS)模型的三段式级联系统,其中ASR模型将用户的语音指令转录为文本,TTS模型将LLM的响应合成为语音。然而,由于级联系统顺序输出转录文本、文本响应和语音响应,因此整个系统往往具有更高的延迟。
相比之下,学者们相继已经提出了一些多模态语音语言模型,这些模型将语音离散化为标记,并扩展LLM的词汇表从而支持语音输入和输出。这种语音语言模型理论上可以直接从语音指令生成语音响应,而无需产生中间文本,从而实现极低的响应延迟。然而,在实践中,由于涉及复杂的映射,直接根据语音生成语音可能具有挑战性,因此通常会生成中间文本来实现更高的生成质量,然而这会牺牲一些响应延迟。
LLaMA-Omni算法简介
LLaMA-Omni由语音编码器、语音适配器、LLM和流式语音解码器组成。LLM用户的语音指令由语音编码器编码,然后由语音适配器编码,然后输入到LLM中。LLM直接从语音指令解码文本响应,而不首先将语音转录成文本。语音解码器是非自回归(NAR)流式传输Transformer,其将LLM的输出隐藏状态LLM作为输入并使用连接主义时间分类(CTC)来预测对应于语音响应的离散单元的序列。 在推理过程中,当LLM自回归生成文本响应时,语音解码器同时生成相应的离散单元。为了更好地适应语音交互场景的特点,我们通过重写现有的文本指令数据并进行语音合成来构建一个名为InstructS 2S-200 K的数据集。
大量的实验结果表明,与之前的语音语言模型相比,LLaMA-Omni在内容和风格上都能提供更好的响应,响应延迟低至226ms。此外,整个LLaMA-Omni模型仅需要在4个GPU上训练3天左右,为未来高效开发语音语言模型铺平了道路。

LLaMA-Omni组成和算法流程
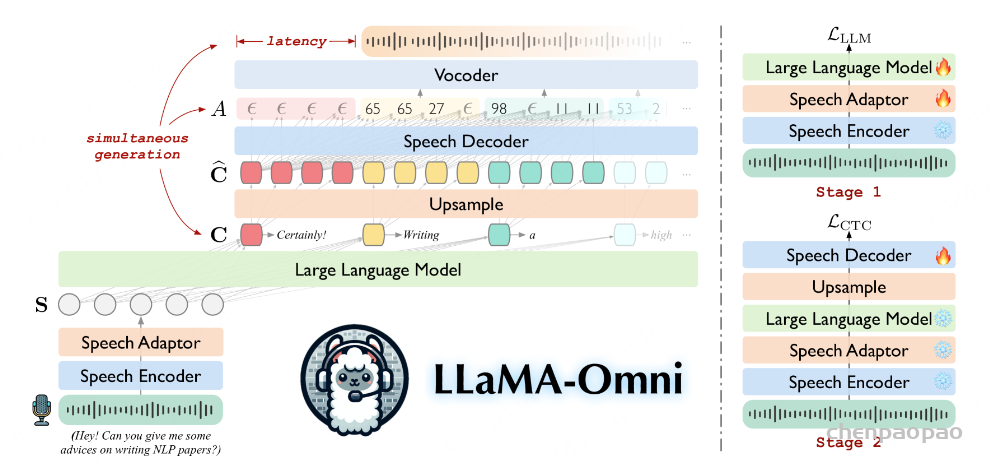
如上图所示,左图展示了LLaMA-Omni的模型的整体架构。它由一个语音编码器、语音适配器、LLM和语音解码器组成。详细的步骤如下所述:
- 首先,将用户的提问语音输入到一个Speech Encoder模块中执行语音编码操作,作者使用Whisper-large-v3的编码器作为语音编码器E;
- 然后,将其结果送入一个Speech Adaptor模块中。为了使LLM能够理解输入语音,作者引入了一个可训练的语音适配器,它能够将语音连续特征表示映射到LLM的嵌入空间中;
- 接着,将语言适配器的结果送入一个大语言模型中。作者使用Llama-3.1-8B-Instruct3,这是目前最先进的开源LLM。它具有很强的推理能力,与人类的偏好非常一致。
- 最后,将大语言模型的结果经过上采样之后送入一个Speech Decoder模块中。为了在生成文本响应的同时生成语音响应,作者在LLM之后添加了一个流式语音解码器D。它由几个与LLaMA具有相同架构的标准Transformer层组成,每个层都包含一个因果自我注意模块和一个前馈网络。
右图展示了LLaMA- Omni的两阶段训练策略示意图。在第一阶段中,作者训练模型直接从语音指令中生成文本响应。具体而言,语音编码器被冻结,语音适配器和LLM使用方程中的目标Lllm进行训练。在此阶段,语音解码器不参与训练。在第二阶段,训练模型从而生成语音响应。在此阶段,语音编码器、语音适配器和LLM都被冻结,只有语音解码器使用目标Lctc进行训练。
Speech Encoder
使用Whisper-large-v3的编码器作为语音编码器 ℰ 。Whisper是一种基于大量音频数据训练的通用语音识别模型,其编码器能够从语音中提取有意义的表示。具体地,对于用户的语音指令 XS ,编码语音表示由 𝐇=ℰ(XS) 给出,其中 𝐇=[𝐡1,…,𝐡N] 是长度为 N 的语音表示序列。我们在整个训练过程中保持语音编码器的参数冻结。
Speech Adaptor
为了使LLM能够理解输入语音,我们结合了一个可训练的语音适配器 𝒜 ,它将语音表示映射到LLM的嵌入空间中。我们的语音适配器首先对语音表示 𝐇 进行下采样以减小序列长度。具体地,每 k 个连续帧沿特征维度被沿着连接:
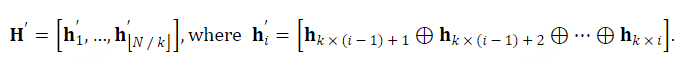
接下来, 𝐇′ 通过线性层之间具有ReLU激活的2层感知器,产生最终的语音表示 𝐒,非离散的特征 。上述过程可以形式化如下:
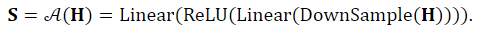
Large Language Model
我们使用Llama-3.1-8B-Instruct 作为LLM ℳ ,这是目前最先进的开源LLM。它具有强大的推理能力,并且与人类的偏好保持一致。提示模板 𝒫(⋅) 如图3所示。将语音表示序列 𝐒 填充到对应于<speech>的位置,然后将整个序列 𝒫(𝐒) 输入到LLM中。LLM最后,LLM自回归直接基于语音指令生成文本响应 YT=[y1T,…,yMT] ,并使用交叉熵损失进行训练:
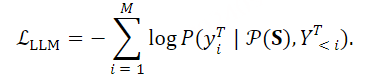
Speech Decoder
对于语音响应 YS ,我们首先遵循Zhang等人将语音离散化为离散单元。具体来说,我们使用预训练的HuBERT模型来提取语音的连续表示,然后使用K均值模型将这些表示转换为离散聚类索引。随后,将连续的相同索引合并成单个单元,从而产生最终的离散单元序列 YU=[y1U,…,yLU],yiU∈{0,1,…,K−1},∀1≤i≤L ,其中 K 是簇的数目,并且 L 是离散单元序列的长度。离散单元可以用附加的基于单元的声码器 𝒱 转换成波形
为了与文本响应同时生成语音响应,我们在LLM之后添加了流式语音解码器 𝒟 。LLM它由几个标准的Transformer组成具有与LLaMA相同架构的层,每个包含因果自我注意模块和前馈网络。与Ma等人(2024 a); Zhang等人(2024 b)2024 a)类似,语音解码器以非自回归方式运行,将LLM输出的隐藏状态作为输入,生成与语音响应对应的离散单元序列。LLM具体地,对应于文本响应的输出隐藏状态被表示为 𝐂=[𝐜1,…,𝐜M] ,其中


LLaMA-Omni算法实现细节
提示词模版

上图展示了提示模板P。语音表示序列S被填充到与<speech>对应的位置,然后整个序列P(S)被输入到LLM中。最后,LLM直接基于语音指令自回归生成文本响应结果,整个过程使用交叉熵损失进行训练。
Training
如图2所示,作者采用两阶段训练策略为LLaMA-Omni。在第一阶段,作者训练模型直接从语音指令生成文本响应。具体而言,语音编码器被冻结,而语音 Adapter 和LLM使用公式(3)中的目标进行训练。在这一阶段,语音解码器不参与训练。在第二阶段,作者训练模型生成语音响应。在此阶段,语音编码器、语音 Adapter 和LLM都被冻结,只有语音解码器使用公式(5)中的目标进行训练。
Inference
在推理过程中,LLM 自动回归地生成文本响应。同时,由于作者的语音解码器使用因果注意力,一旦 LLM 生成一个文本响应前缀 ,对应的 upsampled 隐藏状态 可以被输入到语音解码器中,生成一个部分对齐 ,从而得到与生成的文本前缀对应的离散单元。
为了进一步实现语音波形的 Stream 合成,当生成的单元数量达到预定义的块大小 时,作者将这个单元段输入到 vocoder 中,合成一个语音段,然后立即播放给用户。因此,用户可以在等待完整文本响应生成完成之前开始听语音响应,确保低响应延迟,该延迟不受文本响应长度的影响。
此外,由于语音解码器使用非自回归建模,每个文本令元 对应的对齐 都在块内并行生成。因此,同时生成文本和语音的解码速度与仅生成文本的速度之间没有显著差异。
在推理过程中,LLM根据语音指令自回归生成文本响应。同时,由于其语音解码器使用因果注意力机制,一旦LLM生成文本响应前缀,相应的上采样隐藏状态就可以被馈送到语音解码器中生成部分对齐结果,这反过来又产生了与生成的文本前缀对应的离散单元。
为了进一步实现语音波形的流式合成,当生成的单元数量达到预定义的块大小时,作者将该单元段输入到声码器中以合成语音段,然后立即向用户播放。因此,用户可以开始收听语音响应,而无需等待生成完整的文本响应,从而确保不受文本响应长度影响的低响应延迟。
INSTRUCTS2S-200K数据集构建细节
为了训练LLaMA-Omni,作者需要利用由<语音指令、文本响应、语音响应>组成的三元组数据。然而,大多数公开的指令数据都是文本形式的。因此,作者通过以下步骤来基于现有的文本指令数据构建语音指令数据集。
步骤1–指令重写。由于语音输入与文本输入具有不同的特征,作者根据以下规则重写文本指令:1)在指令中添加适当的填充词(如“hey”、“so”、“uh”、 “um”等),来模拟自然语音模式。2) 将指令中的非文本符号(如数字)转换为相应的口语形式,从而确保TTS的正确合成。3) 修改说明,使其相对简短,不要过于冗长。作者利用Llama-3-70BInstruct4模型根据这些规则重写指令。
步骤2–响应生成。在语音交互中,来自文本指令的现有响应不适合直接用作语音指令响应。这是因为,在基于文本的交互中,模型倾向于使用复杂的句子生成冗长的响应,并可能包含有序列表或括号等非语言元素。然而,在语音交互中,简洁而信息丰富的回答通常是首选。因此,作者使用Llama-3-70B-Instruct模型根据以下规则生成语音指令的响应:1)响应不应包含TTS模型无法合成的内容,如括号、有序列表等。2)响应应非常简洁明了,避免冗长的解释。
步骤3–语音合成。在获得适合语音交互的指令和响应后,作者需要使用TTS模型将其进一步转换为语音。对于指令,为了使合成的语音听起来更自然,作者利用CosyVoice-300M-SFT模型为每条指令随机选择男声或女声。对于响应,作者使用在LJSpeech数据集上训练的VITS模型将响应合成为标准语音。
LLaMA-Omni算法性能评估
实验配置
训练数据集:
作者使用第3节中提到的InstructS2S-200K数据集(包含20万条语音指令数据)。为了提取对应目标语音的离散单元,作者使用了一个预训练的K-means分箱器9,它从HuBERT特征中学习了1000个簇。预训练的高保真GAN解码器用于将离散单元合成为波形。
对于评估数据,作者从Alpaca-Eval10中选择了两个子集:_helpful_base_和_vicuna_,因为它们的问题更适合语音交互场景。作者删除了与数学和代码相关的问题,总共得到199条指令。为了获得语音版本,作者使用CosyVoice-300M-SFT模型将指令合成为语音。作者将在以下章节中将其称为InstructS2S-Eval测试集。
模型配置:
作者使用Whisper-large-v3的编码器作为语音编码器,使用LLama-3.1-8B-Instruct作为LLM。语音 Adapter 对语音表示进行5倍下采样。语音解码器由2个与LLaMA相同的Transformer层组成,具有4096个隐藏维度、32个注意力头和11008个 FFN 维度,其中包含425M参数。上采样因子λ设置为25。对于输入语音编码器的最小单位块大小Ω,作者在主要实验中设置Ω=+∞,这意味着作者等待整个单位序列生成后再将其输入到语音合成器进行语音合成。在后续实验中,作者将分析如何调整Ω的值来控制响应延迟,以及延迟和语音质量之间的权衡。
训练全功能的LLaMA-Omni遵循两阶段的训练过程。在第一阶段,作者使用32个批量的语音 Adapter (speech adapter)和语言模型(LLM),训练3个周期,每次迭代32步。作者使用余弦学习率调度器,前3%的步骤用于 Warm up ,峰值学习率设置为2e-5。在第二阶段,作者使用相同的批量大小、步骤数和调度器训练语音解码器,但峰值学习率设置为2e-4。整个训练过程大约需要65小时,在4个NVIDIA L40 GPU上运行。
Evaluation
由于LLaMA-Omni可以根据语音指令同时生成文本和语音响应,作者评估模型在两个任务上的性能:语音到文本指令遵循(S2TIF)和语音到语音指令遵循(S2SIF)。作者使用贪心搜索以确保可重复的实验结果。从以下方面对模型进行评估:
为了评估模型遵循语音指令的能力,作者使用 GPT-4o对模型的响应进行评分。对于S2TIF任务,评分基于语音指令的转录文本和模型的文本回复。对于S2SIF任务,作者首先使用 Whisper-large-v3 模型将模型的语音回复转录为文本,然后像S2TIF任务一样以相同的方式进行评分。 GPT-4o 在两个方面给出评分:内容和风格。 内容评分评估模型回复是否充分解决了用户指令,而风格评分评估模型回复的风格是否适合语音交互场景。详细说明可以在附录A中找到。
语音文本对齐为了评估文本响应和语音响应之间的对齐情况,作者使用Whisper-large-v3模型将语音响应转录为文本,然后计算转录文本和文本响应之间的Word Error Rate(WER)和Character Error Rate(CER)。作者将这些指标分别称为ASR-WER和ASR-CER。
为了评估生成的语音的质量,作者使用了名为UTMOS11的Mean Opinion Score(MOS)预测模型,该模型能够预测语音的MOS分数以评估其自然度。作者将这个指标称为UTMOS分数。
响应延迟latency是语音交互模型的一个关键指标,它指的是从输入语音指令到语音响应开始之间的时间间隔,这对用户体验有显著影响。此外,当语音响应开始时,作者还计算出已经生成的文字数量,称为**#滞后词**。
Baseline Systems
作者将以下语音语言模型作为基准系统:
SpeechGPT 是一种支持语音输入和输出的语言模型。作者使用原论文中采用的连续模态 Prompt 进行解码,根据语音指令依次输出文本指令、文本响应和语音响应。
SALMONN (+TTS) 是一种能够接受语音和音频输入并作出文本响应的LLM,使其能够执行S2TIF任务。对于S2SIF任务,作者在SALMONN之后添加了一个VITS TTS模型,以分阶段方式生成语音响应。
Qwen2-Audio (+TTS) 是一种强大的通用音频理解模型,能够执行各种与音频相关的任务,包括S2TIF任务。作者还构建了一个Qwen2-Audio和VITS ConCat 的系统,以完成S2SIF任务。
主要结果

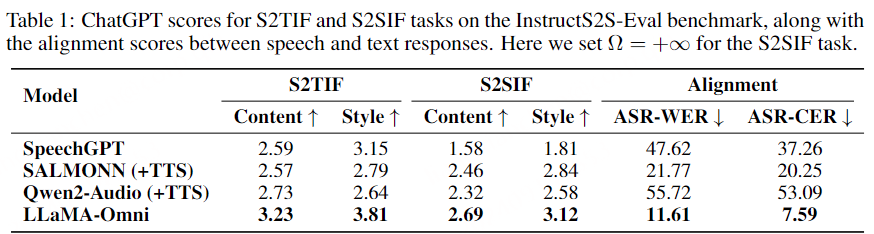
表1展示了在InstructS2S-Eval基准测试上的主要结果。首先,对于S2TIF任务,从内容角度来看,LLaMA-Omni相较于之前的模型有显著提高。这主要是由于LLaMA-Omni是基于最新的LLaMA-3.1-8B-Instruct模型开发的,利用其强大的文本指令遵循能力。从风格角度来看,SALMONN和Qwen2-Audio的得分较低,因为他们是语音转文本模型。他们的输出风格与语音交互场景不匹配,经常产生格式化内容并包含大量冗余解释。
相比之下,SpeechGPT作为语音转语音模型,实现了更高的风格分数。同样,作者的LLaMA-Omni也获得了最高的风格分数,表明在经过作者InstructS2S-200K数据集的训练后,输出风格已经与语音交互场景很好地对齐。对于S2SIF任务,LLaMA-Omni在内容和风格得分上都优于之前的模型。这进一步证实了LLaMA-Omni能够在简洁高效的方式下,有效地处理用户的指令。
此外,在语音与文本响应的对齐方面,LLaMA-Omni实现了最低的ASR-WER和ASR-CER分数。相比之下,SpeechGPT在将语音与文本响应对齐方面表现不佳,这可能是由于其顺序生成文本和语音的缘故。
级联系统的语音-文本对齐,如SALMONN+TTS和Qwen2-Audio+TTS,也是次优的,主要原因是生成的文本响应可能包含无法合成为语音的字符。这个问题在Qwen2-Audio中尤为明显,它偶尔会输出中文字符,导致语音响应中出现错误。相比之下,LLaMA-Omni实现了最低的ASR-WER和ASR-CER分数,表明生成的语音与文本响应之间的对齐程度更高,进一步验证了同时生成文本和语音响应的优势。
Case Study

上图展示了该模型与多个不同模型(Qwen2-Audio、SALMOON、Speech GPT)针对输入指令(“我该如何把礼物包装整齐?”)的输出结果。通过观察与分析,我们可以发现:Qwen2 Audio的响应相当长,包括换行符和括号等无法合成语音的元素。SALMONN的回应也有点长。SpeechGPT的响应风格更适合语音交互场景,但其响应中包含的信息量较少。相比之下,LLaMA Omni给出的响应更详细、更有用,同时保持了简洁的风格,在语音交互场景中优于之前的模型。
语音质量和响应延迟之间的权衡
LLaMA-Omni 可以同时生成文本响应和与语音响应对应的离散单元。如第2.6节所述,为了进一步实现流形波生成,当生成的离散单元数量达到一定块大小Ω时,该块单元被输入到语音合成器中进行合成和播放。通过调整Ω的值,作者可以控制系统的延迟,其中较小的Ω对应较低的系统延迟。当Ω=+∞时,意味着在合成语音之前等待所有单元生成。同时,Ω的值也影响生成的语音质量。较小的Ω意味着将语音分割成更多段进行合成,这可能导致段与段之间的断续,可能降低语音的整体连贯性。
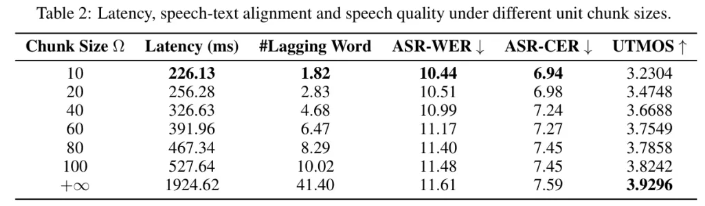
为了更好地理解Ω的影响,作者研究了系统的延迟、语音与文本响应的对齐以及不同Ω设置下生成的语音质量。如表2所示,当Ω设置为10时,系统的响应延迟低至226毫秒,甚至低于GPT-4o的平均音频延迟320毫秒。此时,语音响应在开始时平均滞后1.82个词。当Ω设置为无穷大时,延迟增加到约2秒。对于ASR-WER和ASR-CER指标,作者惊讶地发现,随着块大小的增加,错误率也增加。作者认为可能有两个原因。
- 一方面, vocoder可能比长序列更可靠地处理短单元序列,因为它通常训练在较短序列上。
- 另一方面,作者使用的ASR模型Whisper-large-v3具有很强的鲁棒性。即使语音与较小Ω的较小连续性,对ASR识别精度影响很小。
因此,作者进一步使用UTMOS指标评估生成的语音自然度。它显示,随着Ω的增加,语音的自然度提高,因为语音的不连续性减少。总之,作者可以根据不同的场景调整Ω的值,以实现响应延迟和语音质量之间的权衡。
Decoding Time
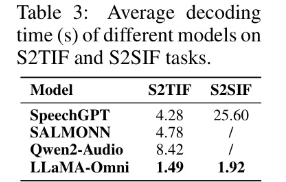
表3列出了不同模型在S2TIF和S2SIF任务上的平均解码时间。对于S2TIF任务,SpeechGPT需要先输出文本指令,然后输出文本回复,而SALMONN和Qwen2-Audio倾向于产生冗长的回复。
相比之下,LLaMA-Omni能直接提供简洁的答案,导致解码时间显著降低,每条指令的平均解码时间仅为1.49秒。对于S2SIF任务,SpeechGPT逐条输出文本和语音回复,导致解码时间比仅生成文本回复时大约延长6倍。相比之下,LLaMA-Omni同时输出文本和语音回复,并采用非自动回归架构生成离散单元。因此,总生成时间仅增加1.28倍,证明了LLaMA-Omni在解码速度上的优势。
客观指标性能评估
上表展示了该算法与多个SOTA算法在InstructS2S评估基准上的评估结果。首先,对于S2TIF任务,从内容的角度来看,LLaMA Omni与之前的模型相比有了显著改进。这主要是因为LLaMA Omni是基于最新的LLaMA-3.1-8BInstruct模型开发的,利用了其强大的文本指令跟踪功能。
从风格角度来看,SALMONN和Qwen2 Audio的得分较低,因为它们是语音转文本模型。它们的输出风格与语音交互场景不一致,通常会产生格式化的内容,并包含大量冗余的解释。相比之下,SpeechGPT作为一种语音对语音模型,其风格得分更高。同样,LLaMA Omni获得了最高的风格得分,这表明在该算法InstructS2S-200K数据集上训练后,输出风格与语音交互场景非常一致。 对于S2SIF任务,LLaMA Omni在内容和风格得分方面也优于之前的模型。这进一步证实了LLaMA Omni能够以简洁高效的方式通过语音有效地处理用户的指令。