
突破音频语言表征的瓶颈! 1s音频仅需40个Token,就能够高质量重建音频
论文:Wavtokenizer: An Efficient Acoustic Discrete Codec Tokenizer For Audio Language Modeling
论文地址:https://arxiv.org/pdf/2408.16532
Github地址:https://github.com/jishengpeng/WavTokenizer
HuggingFace地址:https://huggingface.co/novateur/WavTokenizer
浙江大学,联合阿里通义语音实验室和Meta研究员发表了一篇题为“Wavtokenizer: An Efficient Acoustic Discrete Codec Tokenizer For Audio Language Modeling”的论文。该论文研究了如何将多码本(RVQ)语音声学编解码器模型简化为单码本(VQ)结构,它不仅在压缩率和重构质量上超越了现有的最先进Codec模型,在UTMOS主观感知质量等指标上实现了SOTA的性能,还在语义信息建模上取得了重要进展,极致的序列压缩将有效提升下游语音大语言模型/多模态大语言模型的建模能力。
背景动机:解决音频语言建模的瓶颈,迈向更高效的音频处理
在大规模语言模型快速发展的背景下,音频处理领域依赖于离散化声学编解码器模型将音频信号转换为离散token,使其能被语言模型处理。然而,当前的技术在以下几个方面存在显著的局限性:
- 压缩与重构质量的权衡:大多数现有模型(如DAC、Encodec)通过多量化器层的设计来提升音频重构质量,但这也增加了计算复杂性和资源消耗。例如,DAC模型在9个量化器层的条件下,每秒需要900个token来重构一秒音频。如此高的压缩比率和计算成本,使得下游应用和模型部署变得复杂且代价高昂。
- 缺乏语义信息的丰富表达:当前的声学编码模型大多专注于音频的重构,而未能有效捕捉和保留语音和音频中的语义信息,这是重建任务和下游生成任务本身的训练gap。一些研究通过添加独立的语义模块来增强语义内容,但这通常需要多阶段的模型架构,增加了训练复杂度,并导致难以统一建模语音、音乐和其他音频数据。
- 单量化器模型的探索潜力:多量化器模型的复杂性推动了研究者对单量化器模型的探索,但在极端压缩条件下保持高质量重构仍是一个挑战。单量化器模型的优势在于更简单的架构和更低的计算成本,但如何优化矢量量化(VQ)空间以增强表示能力,并设计出避免重构伪影的解码器结构,依然是未解决的问题。
基于这些挑战,我们提出了 WavTokenizer。通过创新设计扩展VQ空间、优化解码器架构、扩展上下文建模窗口和引入多尺度判别器,我们的模型实现了极致的压缩效果,同时显著提升了音频重构质量和语义信息表达能力。这一工作不仅为音频语言建模提供了新方向,也在音频生成和理解的未来应用中展现出巨大潜力。
它与SOTA声学编解码器相比,在音频领域具有以下几个优点:
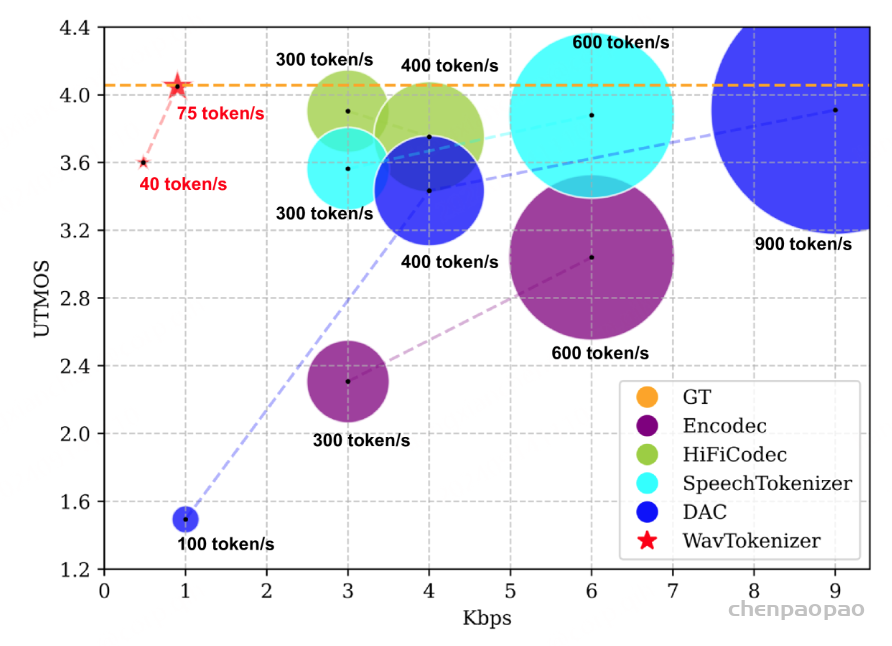
1)极限压缩。通过压缩量化器的层次和离散编解码器的时间维度,24kHz采样率的一秒音频仅需要具有40或75个令牌的单个量化器。
2)提高主观质量。尽管减少了令牌的数量,但WavTokenizer仍能以出色的UTMOS得分实现最先进的重建质量,并固有地包含更丰富的语义信息。
实现细节:WavTokenizer的核心技术设计
为了突破当前音频语言建模中存在的压缩和重构质量瓶颈,我们设计了一个新的离散声学编解码器模型——WavTokenizer。它在音频压缩、重构质量和语义信息表达能力上实现了前所未有的平衡。
我们的模型建立在VQ-GANs框架上,遵循与SoundStream和EnCodec相同的模式。具体来说,WavTokenizer通过三个模块传递原始音频 X ,编码器模块、量化模块、解码器模块。
1) 采用音频输入并生成潜在特征表示 Z 的全卷积编码器网络;
2) 用于生成离散表示 Zq 的单个量化器来离散化特征Z。
3) 一种改进的解码器,用于从压缩的潜在表示 Zq 中重构音频信号 X~ 。
该模型是端到端训练的,优化了在时间和频率域上应用的重建损失,以及在不同分辨率下操作的鉴别器形式的感知损失。
考虑到WavTokenizer被设计为大型音频语言模型的离散令牌表示,重点应该放在编解码器的主观重建质量(音频保真度)和语义内容信息上。在图1中,我们可视化了比特率和UTMOS度量之间的关系。我们可以观察到WavTokenizer仅用75个令牌就实现了最先进的重建质量。此外,它还探索了极端的压缩比特率,在0.48 kbps时达到了3.6的UTMOS分数。
编码器设计
跟Encodec设计类似,编码器模型由具有C个通道的1D卷积组成,并且核大小为7,随后是B个卷积块。每个卷积块由单个残差单元组成,该残差单元之后是由步长S的两倍的核大小的步长卷积组成的下采样层。残差单元包含两个核大小为3的卷积和一个跳跃连接.每当发生下采样时,通道数量加倍。卷积块之后是用于序列建模的两层LSTM和具有7个核大小和D个输出通道的最终1D卷积层。
扩展矢量量化(VQ)空间,提高码本利用率
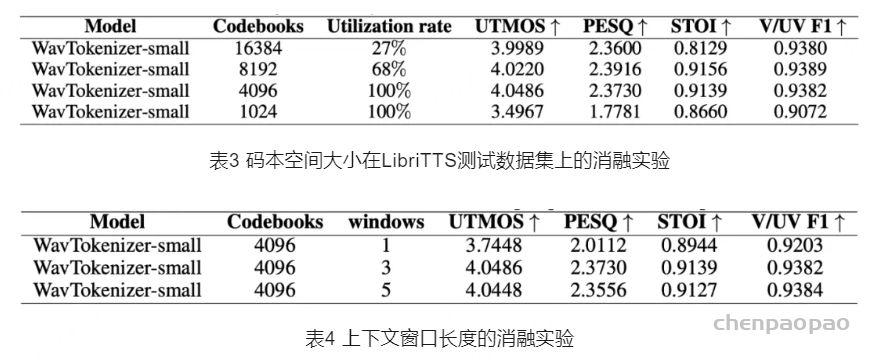
在传统的声学编解码器模型中,矢量量化(VQ)空间的大小通常是固定的,这限制了模型对音频信号的表达能力。我们通过将VQ空间从 1024 扩展到4096,显著提升了模型对高维音频数据的压缩和表达能力。为了确保扩展后的VQ空间得到充分利用,WavTokenizer 采用了基于K-means聚类初始化和随机唤醒策略的优化方法。这种设计能够在保证较低码率的同时,维持高质量的音频重构效果,并且能够有效减少信息损失。
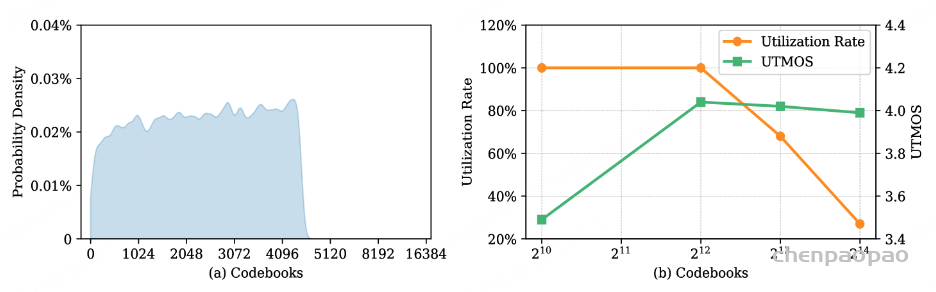
最初,在不改变任何结构的情况下,我们试图在训练期间仅依赖于单个量化器来进行重构,但发现结果不是最佳的。考虑到自然语言中巨大的词汇空间,我们假设将语音作为一种独特的语言来处理可能会产生更好的结果。因此,我们首先将码本空间从 210 扩展到 214 。我们对LibriTTS进行了585小时的训练,并在LibriTTS测试-清理数据集上可视化了码本的概率分布,如图2(a)所示。 我们观察到语音词汇空间集中在 212 的左侧,表明利用更大的 212 语音词汇空间的潜力。当前的编解码器码本 210 可能没有充分利用语音空间的潜力。
此外,扩展量化码本空间可能导致较低的利用率,
我们使用K均值聚类来初始化码本向量。我们将聚类中心的数量调整为200,以与较大的码本空间对齐。在训练期间,使用衰减为0.99的指数移动平均值来更新每个输入的所选代码,并且用从当前批次中随机采样的输入向量来替换对于若干批次未分配的代码。这种强制激活策略有助于确保大码本空间的有效利用。 如图2(B)所示,我们分析了码本利用率与重构结果的关系,确认了 212 是合适的,与图2(a)的结论一致,适当扩展相应的码本空间可以减少将分层RVQ结构压缩到单个量化器所带来的信息损失。语音可以在串行化量化器结构下有效地重构,其中 212 的码本空间实现利用率和重构质量之间的有利平衡。这表明了将语音与广泛的自然语言词汇对齐的潜力,通过标记器将其作为一种独特的语言进行强有力的映射。
改进的解码器架构:逆傅里叶变换、注意力机制与扩展的上下文窗口结合
传统的编解码器模型通常使用镜像卷积上采样的方法,但这容易产生混叠伪影,影响音频重构质量。为了解决这一问题,WavTokenizer 在解码器设计中基于Vocos模型,采用了基于逆傅里叶变换(iFFT)的方法。iFFT 能在所有深度上保持一致的特征分辨率,有效减少重构伪影,同时更精确地恢复音频信号。在解码器部分中,使用短时傅立叶变换(STFT)来表示目标音频信号 X~
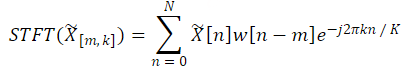
此外,WavTokenizer 在解码器中引入了注意力模块,并设计了扩展的上下文窗口来增强语义信息的建模能力。研究表明,使用更大的上下文窗口(例如 3 秒)有助于捕捉更多的语义信息,提升模型对长音频序列的重构质量。这种方法能够更好地处理音频中的静音段,提高了重构结果的连贯性和自然度。通过将注意力网络与逆傅里叶变换结合,WavTokenizer 在极低码率下实现了高质量的音频重构。
将WavTokenizer的上下文建模窗口扩展到3秒,注意力模块将进一步改善训练过程中的编解码器重建。这可能是因为一秒钟的剪辑,包括沉默,可能包含不足的语义信息。增加上下文建模窗口大小有助于编解码器模型更好地捕获上下文。我们通过详细的消融研究验证了这些发现。在我们的实验中,我们还发现在WavTokenizer中引入注意力模块只对解码器有益。
多尺度判别器与复数STFT判别器的设计
为了进一步优化生成音频的质量,WavTokenizer 引入了多尺度判别器(MSD)和复数短时傅里叶变换(STFT)判别器。这些判别器能够在不同时间尺度和频谱范围内对生成的音频进行评估。模型使用了对抗性损失(adversarial loss)和特征匹配损失(feature matching loss)进行联合优化。与现有模型相比,这种创新设计能够更好地保留音频的细节信息和语义内容,提高了音频重构的主观质量。
端到端优化策略,实现高效压缩
WavTokenizer 采用了端到端的优化策略,同时考虑时间域和频率域的重构损失。与现有的多量化器层模型相比,WavTokenizer能够在单量化器条件下实现更高效的音频压缩。在 24kHz 采样率下,每秒音频仅需 40 或 75 个离散token,这大大减少了模型的带宽需求,同时保持了高水平的音频重构质量。
这些技术创新使得WavTokenizer能够在单量化器结构下实现音频的极致压缩和高质量重构,同时提供丰富的语义信息表达能力。我们相信,这一模型将为音频语言建模的未来应用提供新的可能性。
实验验证:WavTokenizer的卓越性能
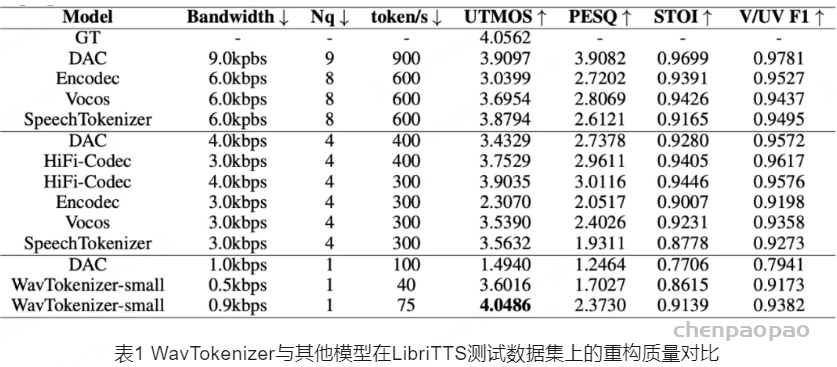
为了验证 WavTokenizer 在音频语言建模中的实际效果,我们在多个数据集上进行了广泛的实验,涵盖了语音重构、语义信息评估和消融研究。结果显示,WavTokenizer 在多个指标上均优于现有的最先进模型,展现了其卓越的压缩效率、重构质量和语义表达能力。在LibriTTS测试集上的语音重构实验中,WavTokenizer-small在0.9 kbps的压缩率下,仅使用一个量化器和75个token,就实现了4.05的UTMOS得分,显著超越了使用9个量化器和900个token的DAC模型的3.91分。这一结果表明,WavTokenizer在极低码率下依然能够保持卓越的音频重构质量,接近人类听觉感知水平。相比于需要多个量化器的复杂模型,WavTokenizer在使用单一量化器、40个token的条件下,也展现出高效的压缩率和优异的重构效果,大大降低了计算成本。同时,在PESQ等感知语音质量指标上,WavTokenizer表现与多量化器模型相当甚至更优,进一步验证了其在单量化器设置下对音频质量的强大保持能力。
在语义信息评估方面,我们使用ARCH基准评估了WavTokenizer在不同音频任务中的表现。结果显示,WavTokenizer在情感语音、歌曲(RAVDESS)和口语理解(SLURP)等多领域任务中,表现优于使用更多量化器的Encodec和DAC,展现出卓越的语义捕捉能力。这一结果说明,WavTokenizer不仅能够在极限压缩条件下保持高质量的重构,还能在语义信息表达方面提供强大支持,为下游任务带来更高的应用价值。
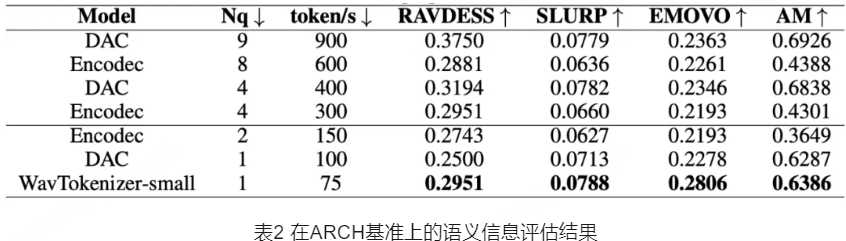
为了深入研究WavTokenizer中各个模块的贡献,我们还进行了消融实验,验证了VQ空间扩展、上下文窗口长度的作用。实验结果表明,扩展VQ空间能够显著提高音频重构质量,从而验证了VQ空间优化对模型性能的关键作用;增加上下文窗口长度也有助于更好地捕捉语义信息,尤其是在处理长音频序列时表现突出。
通过这些实验,WavTokenizer 展现出在极限压缩率和长序列生成任务中的强大适应性和稳定性,证明了其在音频压缩、重构质量和语义表达能力方面的全面优势。这些结果不仅为音频语言建模提供了新的可能性,也为未来多模态大模型的音频处理与生成提供了一个更高效、更有潜力的解决方案。
进一步探索
由于训练成本较大,我们将在十月之前补充WavTokenizer-medium,WavTokenizer-large版本的实验结果,以及在audio和music领域codec重建性和语义丰富性的实验。同时将进一步探索WavTokenizer模型在下游生成任务例如text-to-speech和GPT-4o范式任务上的性能,并且补充更多的消融实验结果。
总 结
在本文中,我们提出了一个新的离散声学编解码器模型——WavTokenizer,旨在解决音频语言建模中压缩效率和重构质量之间的权衡问题。与现有的多量化器模型相比,WavTokenizer通过一系列技术创新,包括扩展矢量量化(VQ)空间、改进的解码器架构(结合逆傅里叶变换和注意力机制)、扩展的上下文建模窗口、多尺度判别器和复数STFT判别器的设计,实现了在单量化器架构下的高效音频压缩和高质量音频重构。实验结果表明,WavTokenizer在LibriTTS、RAVDESS、SLURP等多个数据集上的重构质量和语义信息表达方面,均优于当前最先进的模型。
通过对模型架构的改进和优化,WavTokenizer在保持高效压缩的同时,成功减少了模型的计算复杂性和带宽需求,在24kHz采样率下每秒音频仅需40或75个离散token。这一工作不仅验证了单量化器模型的可行性,还为音频生成和语义建模的未来发展提供了新的视角和方向。未来,我们计划进一步扩展模型的应用场景,探索WavTokenizer在更多下游任务和多模态数据处理中的潜力。