
论文:https://arxiv.org/abs/2210.02747
博客:https://lilianweng.github.io/posts/2018-10-13-flow-models/
最近, Flux.ai的 Flux 系列模型因各种原因而受到科技界和非科技界的广泛关注,模型速度快、易于使用(这要归功于扩散器(diffusers))并且易于调整(再次感谢扩散器)。但是,Flux 出色的图像文本对齐和高质量生成背后的原因是一种超越标准扩散过程的新方法,称为“流匹配(Flow matching)”。
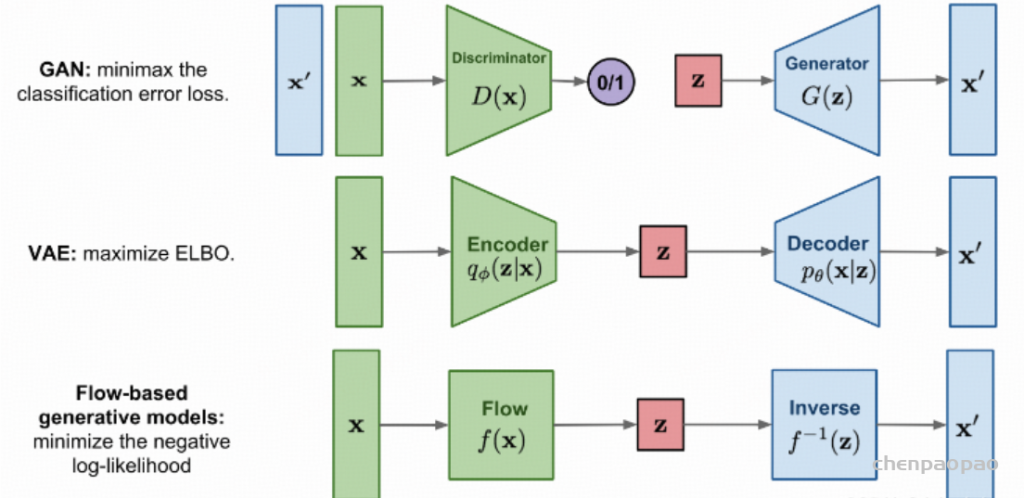
每个生成模型(generative model)理想情况下都是密度估计(density estimaor);因此模拟概率密度,最终是 JPD,具有两个预期特征,即采样和压缩,压缩基本上是将数据推送到信息空间,这似乎是较低维的,而采样是从任何特征分布(z)开始生成 P(x|z) 的能力,可以是正态分布(如 VAE 的情况),因此,在非常高的层次上,我们试图找到将 z 映射到 x 以及将 x 映射到 z(采样和压缩)的映射/函数。
什么是 Flow Matching?
Flow Matching 是一种用于训练生成模型的方法,它基于对流(flow)的概念。在生成模型中,“flow”通常指的是通过可逆的变换(reversible transformation)逐步将复杂的分布映射为简单的分布(如高斯分布),从而使生成模型能够更容易地对复杂数据进行建模。Flow Matching 的目标是通过最小化模型生成的流与真实数据分布的流之间的差异,来学习一个能够生成高质量样本的模型。
在 Flow Matching 中,通过对训练过程中每一步的匹配进行建模,模型逐渐学习如何从简单的噪声分布中生成复杂的目标数据。这种方法可以用于解决传统生成模型中一些难以处理的问题,如模式崩溃(mode collapse)等。
假设两个 Normalizing Flows,一个表示为 z(潜在或可处理分布),另一个表示为 X(数据分布),因为我们想要找到一个可以将 z 映射到 x 的函数,我们会得到 X 和 Z 密度之间的关系,这必然指出假设 X 和 Z 是共轭分布(变换前后同一家族 z 的分布),X 和 Z 的变化应该是相对的,因此,X 的变化是 Z 的某个函数,反之亦然。但是,按某个量缩放。这个量由雅可比矩阵给出的 z 和 x 之间每个维度的变化表示,在非常简单的尺度上,它基本上是 Z 和 X 之间变量的变化。但是,它不是那么简单,因为 X 和 Z 实际上并不共轭,因此,我们只剩下迭代采样和近似方法,比如最佳传输或吉布斯采样(用于 RBM)。鉴于这些限制,大多数方法都绕道去模拟分布并近似非精确映射,而像 Normalizing flow 这样的方法则做出简化假设,使计算和公式易于处理,形式为 p(x)dx = p(z)dz,可以将其重新表述为两个项,第一个是 MLE 项,第二个是雅可比行列式。
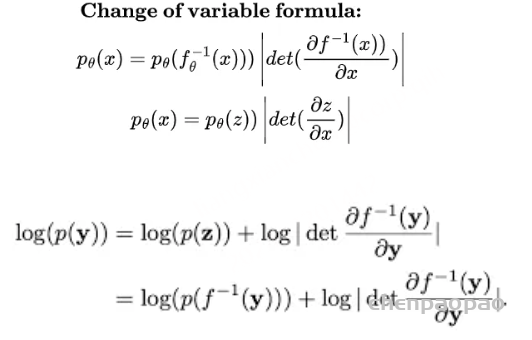
(标准化是因为变量的变化总是给出一个标准化的密度函数,流动是因为它迭代地模拟从源到目标的轨迹/流动)
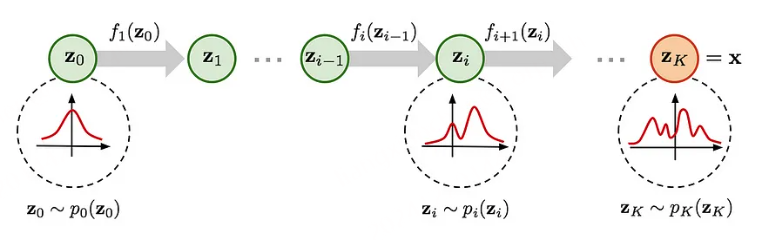
问题从这里开始,这样的函数存在需要两个条件,
1. p(x,z) 的 MLE 公式必须是双射的。
2. 雅可比矩阵的行列式是可有效计算的。

要解决这个问题,我们需要假设 z 和 X 之间的状态依赖性,使得它是双射的并且行列式可以有效计算,有三种主要方法
1. 耦合块:基本上你将 z 分成两块,只有最后 k 值预测 X 的最后 k 值(通过基于均值/方差的采样),X 的其他部分基本上是 z 的直接复制,这有何帮助?由于这种方法,雅可比矩阵变成了对角矩阵,左上角(<k)部分是恒等矩阵,右下角(>=k)变成元素乘积,右上角变成 0,因为 z(<k)和 x(>=k)之间没有依赖关系,因此,雅可比行列式的计算是有效的。
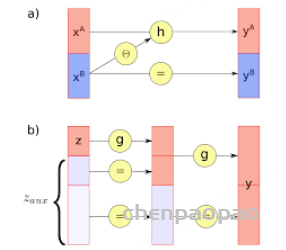
2. AR 流或自回归流是下一个合乎逻辑的扩展,与其制作大 k 块,为什么不将每个状态/特征视为马尔可夫链的一部分,从而消除额外的依赖关系,这会导致雅可比矩阵的下三角矩阵,这也很容易计算。但是,这种方法保留了更多的特征,并且不易受到我们在耦合层中为保留特征而进行的置换操作的影响。
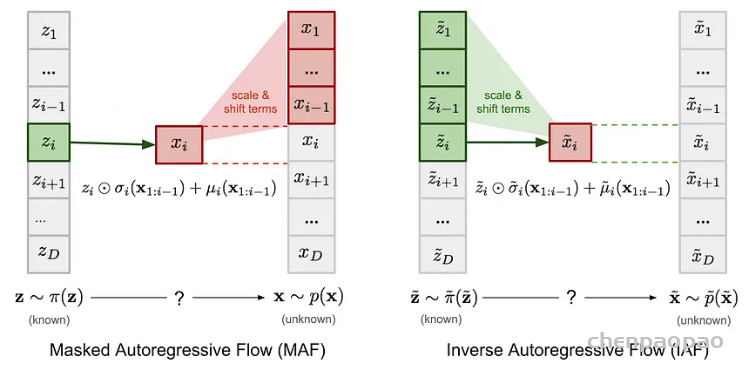
3. 最后,残差流,我们保留整个特征空间,而不牺牲计算。这个想法很简单,但却有非常复杂的数学支持。公式是残差形式 x = z + f(z),但这不是双射,因为 f 是一个神经网络。有趣的是,多亏了 Banach 和他的收缩映射,在理想情况下,存在一个唯一的 z*,它总是映射到相同的 x(稳定状态 z),因此,它也变成了双射,形式为 x = z* + f(z*),其中 f 是一个收缩映射(函数受 Lipschitz 小于 1 的限制,因此,z 的变化受 X 的变化的限制),该形式还为我们提供了一种在给定先前 z(k) 的情况下表示 z(k+1) 的方法,这有助于迭代近似 X,而不是单次框架。我们可以通过相同的公式从 z(0) 转到 z(t),也可以恢复回来,听起来很熟悉,这大致就是扩散。那么行列式呢,迭代变换导致雅可比矩阵迹的无穷项之和,这对于满秩雅可比矩阵来说是可怕的,但可以通过类似的矩阵公式使用哈钦森方法进行迹估计来简单地计算。

到目前为止,我们讨论的所有内容都对样本和轨迹状态(z=>x)做出了离散假设,为什么不使其连续或基本上成为连续的残差流呢?
残差形式 x(k+1) = x(k) + af(x(k)) 可以写成一个微分,其中 k 趋向于无穷大,这看起来很熟悉吗?是的,这现在是一个神经 ODE,但是,我们正在尝试对概率密度在 t 时的状态进行建模,该状态保持不变。密度的状态变化通过连续性或传输方程建模。具体而言,从密度函数的一部分移动到另一部分的质量可以看作是原始质量与当前/移动后质量之间的发散。这种发散是整个轨迹上的连续函数,必须进行积分,因此必须通过数值 ODE 求解,这使得它不可扩展。
这就像状态的比较,为什么不比较路径呢?
这引出了 Flux 背后的方法,即流匹配。想法是这样的……我们从一个非常简单的分布开始,并将其移向预期的分布,但是,由于我们不知道预期的分布,我们通过迭代扰动来调节它,并估计已知的附加噪声,最终模拟底层分布,这个过程简称为条件流匹配,理论上已经证明,在理想条件下,条件目标和无条件目标是完全相同的,因此,通过优化 CFM【条件流匹配】,我们倾向于优化流匹配背后的主要目标。
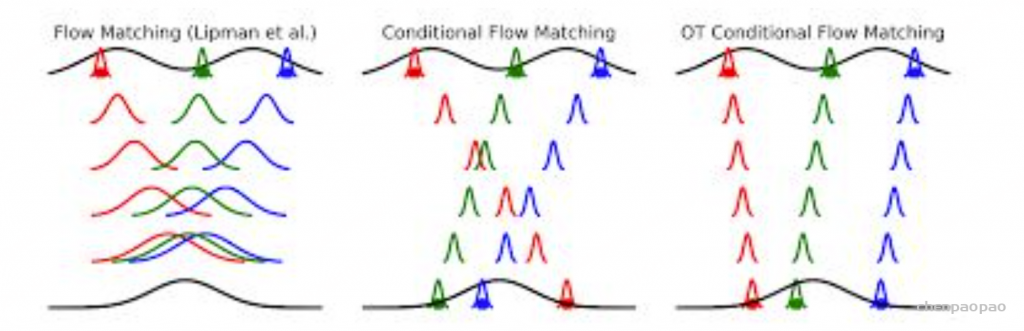
这正是扩散过程,但是,主要区别在于边界条件或初始和最终状态的定义,扩散过程假设纯噪声为 z(t),数据为 z(0),但是,这是在 t 趋向于无穷大时的假设。但是,这在经验上是不可行的,相反,我们会在足够的时间戳内执行此操作,因此,我们保持在更浅的流形中并且速度也更慢(稍后由 LCM 处理),这就像在低分辨率地图中寻找方式/方向,而在流匹配中,纯噪声和数据空间被建模为 lerp(线性插值),形式为 x(t) = t*x(t-1) + (1-t)*x(0),因此,在 t=0 时我们是纯数据样本,而在 t=t 时我们是纯噪声,这为模型提供了更精细的状态/流形,因此,更具代表性的高分辨率地图,也称为条件流匹配(通过噪声分布进行条件调节)。
Flow Matching 在语音生成中的应用
在语音生成任务中,Flow Matching 可以用于建模从语音特征(如梅尔频谱图、F0等)到波形的生成过程。由于语音信号是高度复杂且具有非线性的时序数据,Flow Matching 可以有效地捕捉语音数据中的复杂分布,并生成高质量的语音样本。
步骤概述:
- 输入特征提取:首先,将语音数据转换为特征表示,如梅尔频谱图或其它声学特征。
- Flow Model 构建:建立一个基于流的生成模型,通过一系列可逆变换将简单的分布(如标准高斯分布)映射到语音数据的分布。
- Flow Matching 训练:通过 Flow Matching 技术,最小化模型生成的语音分布与真实语音数据分布之间的差异,逐步学习生成高质量语音信号的能力。
- 语音生成:训练完成后,使用模型生成语音信号,从输入特征映射到语音波形。
优点
- 高质量生成:由于 Flow Matching 能够精确地建模复杂的分布,生成的语音往往更自然、更接近真实语音。
- 稳定性:相比一些其他生成方法(如 GANs),Flow Matching 更加稳定,避免了模式崩溃等问题。
- 可逆性:Flow 模型的可逆性使得对生成过程的控制更加灵活和精确。
应用场景
Flow Matching for Speech Generation 在文本到语音(TTS)系统、语音转换(Voice Conversion)、语音增强(Speech Enhancement)等领域有着广泛的应用前景。
通过 Flow Matching,语音生成模型可以更有效地处理复杂的语音信号,提供更高质量的输出。这种方法正逐步成为语音生成技术发展的重要方向之一。
https://blog.csdn.net/weixin_44966641/article/details/139842872
条件流匹配(Conditional Flow Matching, CFM)
条件流匹配是一种生成模型方法,旨在将条件信息(如标签、特征等)和生成的数据分布匹配起来。它通过条件信息来指导生成过程,使得生成模型能够生成与给定条件一致的数据。
最优传输条件流匹配模型(OT-CFM)
OT-CFM 结合了最优传输和条件流匹配的优势,通过最优传输理论提供的距离度量(如 Wasserstein 距离),以指导生成模型在复杂条件下匹配目标分布。具体来说,OT-CFM 的工作方式如下:
- 建模目标:OT-CFM 的目标是学习一个生成模型,使得在给定条件下,生成的数据分布与目标分布之间的最优传输距离最小化。这样可以保证生成的数据不仅真实,而且满足条件要求。
- 流匹配:模型通过条件流匹配技术,确保生成过程受条件信息的控制,逐步调整生成过程,使其更贴近目标分布。
- 优化过程:通过最优传输的距离度量(如 Wasserstein 距离)来优化生成模型,使得模型生成的数据分布与目标数据分布之间的传输成本最小化。