
- 论文标题:FireRedASR: Open-Source Industrial-Grade Mandarin Speech Recognition Models from Encoder-Decoder to LLM Integration
- 论文地址:http://arxiv.org/abs/2501.14350
- 项目地址:https://github.com/FireRedTeam/FireRedASR
小红书 FireRed 团队正式发布并开源了基于大模型的语音识别模型 ——FireRedASR,在语音识别领域带来新突破。在业界广泛采用的中文普通话公开测试集上,FireRedASR 凭借卓越的性能取得了新 SOTA!FireRedASR 在字错误率(CER)这一核心技术指标上,对比此前的 SOTA Seed-ASR,错误率相对降低 8.4%,充分体现了团队在语音识别技术领域的创新能力与技术突破。
FireredAsr,旨在满足各种应用程序中出色的性能和最佳效率的各种要求。 fireredasr包括两个变体:
FireRedASR-LLM:
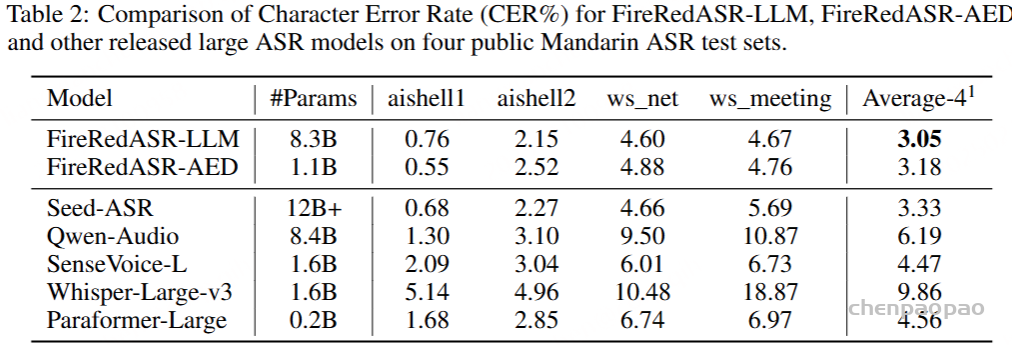
采用Encoder-Adapter-LLM,结合了文本预训练 LLM 的能力,为极致的 ASR 准确率而生,适用于对准确率要求极高的应用场景。在公共普通话基准上,fireredasr-LLM (8.3b参数)达到3.05%的平均字符错误率(CER),超过了3.33%的最新SOTA,相对CER(CERR)8.4%。它显示出优于工业级基线的卓越概括能力,在多源普通话ASR方案(例如视频,现场和智能助理)中,达到24%-40%的CERR。
FireRedASR-AED:
基于经典的 Attention-based Encoder-Decoder 架构,FireRedASR-AED 通过扩展参数至 1.1B,成功平衡了 ASR 语音识别的高准确率与推理效率。适用于资源受限的应用程序。
主要贡献:
- High-Accuracy Models with Efficiency: ASR识别准确率优于Seed-ASR[字节跳动],模型在保持效率的同时达到卓越精度的能力。
- Robust Real-World Performance: 在各种实用的场景中,包括简短的视频,直播,字幕生成,语音输入和智能助手,我们的模型表现出了出色的功能,与相比的相对减少(CERR)相比实现了24%-40%流行的开源基线和领先的商业解决方案。
- 多功能识别能力:支持方言/中文/英文/歌曲识别。而且在歌词识别中表现出色。
模型结构:
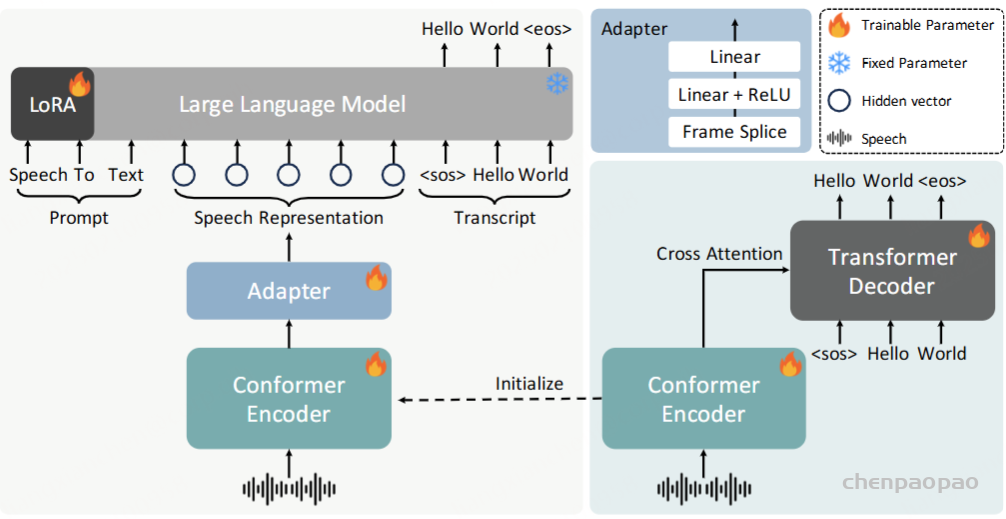
FireRedASR-AED是基于注意的编码器-解码器 ASR模型。训练数据:包括大约70,000小时的音频数据,主要是高质量的普通话语音。与Whisper中使用的弱标记数据集不同,我们的大多数数据都是由专业注释者手动转录的,从而确保了高转录精度和可靠性。该数据集还包含大约11,000小时的英语语音数据,以增强英语ASR功能。
Input Features: 输入25ms窗口的80-dimensional log Mel filterbank (Fbank),10ms frame shifts,然后是全局均值和方差归一化。
Encoder Structure:编码器由两个主要组件组成:一个下采样模块和Conformer blocks堆叠。
Decoder Structure:解码器遵循Transformer 体系结构。
Tokenization:BPE编码英文文本, 1,000 English BPE tokens, 6,827 Chinese characters, and 5 special tokens.
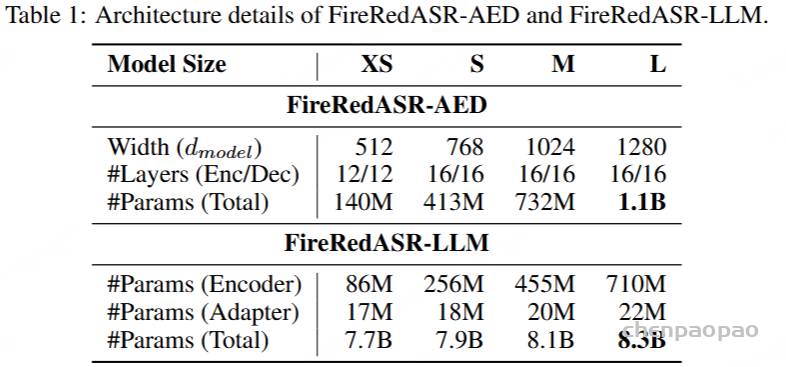
FireRedASR-LLM: Encoder-Adapter-LLM 架构。
Input Features and Encoder: 训练数据和处理、encoder跟FireredAsr-AED相同。
Adapter Structure:一个简单但有效的线性RELU线性网络组成,该网络投射了编码器的输出维度,以匹配输入LLM。在适配器的开头合并了一个额外的框架剪接操作。此操作进一步将时间分辨率从40ms降低到每个帧的80ms,从而降低了序列长度并提高了计算效率LLM。
LLM初始化和处理:LLM用QWEN2-7B-INSTRUCT的预训练的重量初始化。训练数据格式:(prompt, speech, transcript)
Training Strategy: 编码器和适配器是完全训练的,LLM采用lora微调,保证LLM的文本能力。此策略可确保编码器和适配器经过充分训练,以将语音特征映射到LLM的语义空间中,同时保留其预训练能力。训练目标基于交叉熵损失,损失仅在输入的转录部分上计算,忽略提示和语音嵌入。
Evaluation
缩放定律的观察:
LLMs 方面的最新研究表明,模型性能通常会随着模型尺寸的增加而提高,这称为缩放定律 。如表3所示,我们研究了具有不同模型大小的模型的缩放行为。对于 FireRedASR-AED,我们将模型大小逐步从 140M、413M、732M 扩展到 1.1B 参数。随着模型尺寸的增加,性能持续提高,从 XS 扩展到 S、从 S 扩展到 M 以及从 M 扩展到 L 配置时分别实现 6.1%、5.3% 和 5.6% 的 CERR。对于 FireRedASR-LLM,专注于扩展编码器,同时保持 LLM 主干不变。编码器大小从 86M 增加到 710M 参数,适配器参数的变化很小(17M 到 22M)。这表现出相似的扩展模式并带来一致的性能改进,从 XS(3.29%)到 L(3.05%)配置的总体 CERR 为 7.3%。这些结果证明了我们的扩展策略的有效性,并表明通过更大的模型容量可以进一步改进。

下图是 FireRedASR 和其他 ASR 大模型的对比,在业界常用的中文普通话公开测试集上,FireRedASR-LLM(8.3B 参数量)取得了最优 CER 3.05%、成为新 SOTA!FireRedASR-AED (1.1B 参数量)紧随其后取得 3.18%,两者均比 Seed-ASR(12+B 参数量)的 3.33% 低、并且参数量更小。FireRedASR 也比 Qwen-Audio、SenseVoice、Whisper、Paraformer 取得了更优的 CER。
FireRedASR 不仅在公开测试集上表现优异,在多种日常场景下,也展现了卓越的语音识别效果。
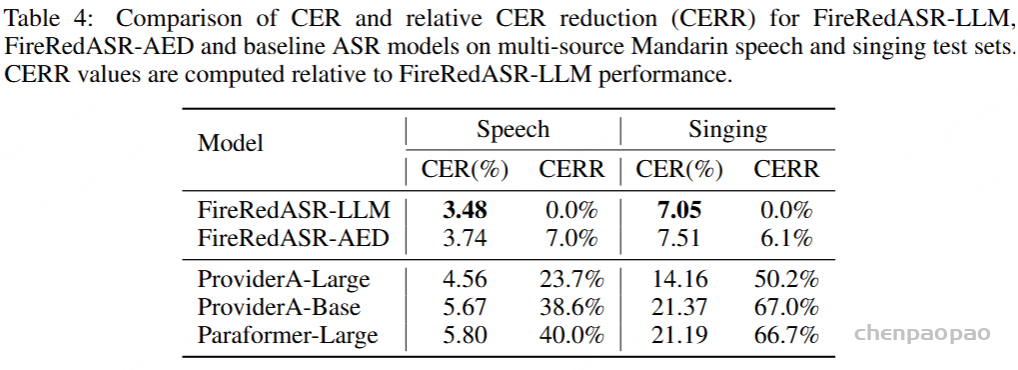
如下图所示,在由短视频、直播、语音输入和智能助手等多种来源组成的 Speech 测试集上,与业内领先的 ASR 服务提供商(ProviderA)和 Paraformer-Large 相比, FireRedASR-LLM 的 CER 相对降低 23.7%~40.0%,优势十分明显。
值得一提的是,在需要歌词识别能力的场景中,FireRedASR-LLM 也表现出极强的适配能力,CER 实现了 50.2%~66.7% 的相对降低,这一成果进一步拓宽了 FireRedASR 的应用范围,使其不仅能胜任传统语音识别需求,还能在创新性的多媒体场景中大放异彩。
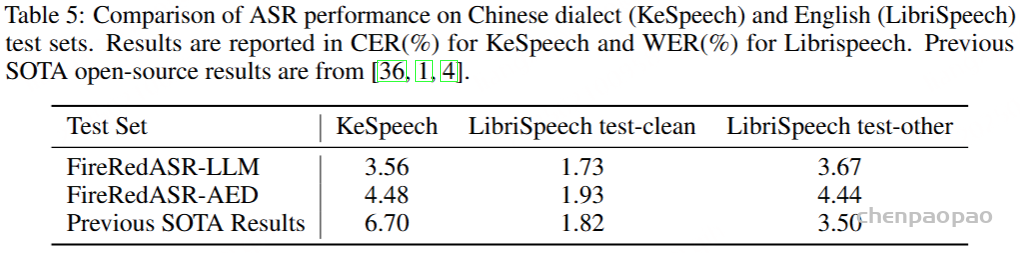
值得一提的是,FireRedASR 在中文方言和英语场景中同样表现不俗。在 KeSpeech(中文方言)和 LibriSpeech(英语)测试集上,FireRedASR 的 CER 显著优于此前的开源 SOTA 模型,使其在支持好普通话 ASR 的前提下,在中文方言和英语上也足够通用,进一步凸显了其鲁棒的语言适配能力。
Discussion:
FireredAsr模型优于竞争模型的原因:
高质量和多样化的训练数据:语料库主要由从现实世界情景中收集的专业转录音频组成,该音频比在受控环境中提供的传统阅读式录音相比,它提供的训练信号明显更高。该数据集包括声音条件,扬声器,重音和内容域的广泛差异,总计数万小时。这种多样性和规模使我们的模型能够学习强大的语音表征和语言模式。
实证研究表明,一千小时的高质量,人工标注的数据比一万小时的弱标记数据(例如,来自视频标题,OCR结果或其他ASR模型的输出)更好的结果,这解释了我们比Whisper的优势 。此外,在我们的语料库中包含唱歌数据为处理音乐内容时的基线模型的显着改进做出了贡献。
优化的训练策略:将FireredAsr-A的扩展为140m到1.1b参数时,我们将正则化和学习率确定为影响模型收敛的关键因素。我们制定了一种渐进式正则化训练策略:最初没有正则化技术以实现快速收敛,然后逐渐引入更强的正则化,因为出现了过度拟合的趋势。此外,较大的模型需要降低学习率,这对于调整此参数的最佳性能至关重要。
高效的ASR框架。
总结:提出了fireredasr-LLM和FireredAsr-AED,两种针对普通话优化的高性能ASR模型。通过全面的评估,我们证明了他们的体系结构,培训策略和高质量的数据集可以在保持计算效率的同时达到最先进的性能。
关于数据batch!=1时候短音频末尾重复出字的问题:
原因:组 batch时候要对音频特征进行pad到最大长度,特征补了0 padding
问题的关键可能是padded_feat,原来的方式是一个一个wav提特征得到feats,如果多个并且有时长相差较大的wav放入提特征得到padded_feats,就会出现某个wav的feat有很多个0 padding,就可能会导致重复出字。发现重复解码的case都是完整且正确地得到了结果,然后重复出字,确实是padding影响了实际问题。
训练的时候按照readme所说做一个时长的数据预处理,将时长相近的wav组成一个个batch来提feats,那么理论上会导致该问题的发生,因为模型会学习到不同的 feat长度对应不同的文本label长度,所以在推理时候补pad后模型认为输出也应该更长。
实际上如果训练时候不对相近的音频组batch,而是随机各种长度组batch进行训练,模型应该就不会出现重复问题,但训练效率会大大降低!!!
最好训练组batch时候可以不在音频特征后补pad,而是最终在 “音频+prompt+lebel” 之后在补 -100【ignore id】,就不会出现这个问题