
摘自:https://zhuanlan.zhihu.com/p/5830338806
总的来说,DPO让模型输出变长主要可以分为以下几个原因:
- RM和模型评测的长度偏好。不管是Reward Model还是当前用与评测的模型(即便是GPT4)都会存在比较明显的长度偏好,即倾向于给更长的回答一个更高的分数。这一点已经有非常多工作给出过分析了。
- 训练数据本身长度分布不均衡。实战过程中往往就是用RM进行排序构造训练数据,RM的长度偏好就是会导致训练数据中容易出现chosen比rejected更长的情况。训练数据的长度差异(chosen比rejected长)就会导致训练后模型输出变长。
- 数据长度差异导致的reward被高估或低估。《Eliminating Biased Length Reliance of Direct Preference Optimization via Down-Sampled KL Divergence》中发现,DPO的算法本身也存在对response长度的依赖,chosen和rejected之间的长度差异可能会导致reward被高估/低估(overestimated or underestimated rewards)。即,当chosen过短时,reward会被低估,而当chosen过长时,reward会被高估。
- DPO算法本身的长度敏感性。《Length Desensitization in Direct Preference Optimization》中提到,response长度会影响到似然概率的大小,并且进一步影响到训练优化方向:当chosen更长时,DPO会往chosen的方向进行优化(增大chosen概率),从而使输出变长;而rejected更长时,DPO会往远离rejected的方向优化(降低rejected概率),但却未必会让输出变短。
如何解决:
- RM的优化:前面讲的都是对DPO进行长度控制的工作,但对RM本身的长度偏好进行优化的工作没有看到太多,如果大家有看到相关的也可以在评论区提供一下。如果将RM本身的长度偏好问题解决的话,那就可以极大程度上解决训练数据的长度分布均衡问题了。
- 数据的优化:有些工作会在数据构造时对长度进行综合考虑,如对RM打分进行长度归一后再排序、采样多个答案进行排序时根据均值方差限制chosen的长度等,通过这些方式可以减少长度差距过大的情况。如果数据本身的长度分布均衡了,也能一定程度上减缓这种问题。
- 训练算法上的优化:如果从LD-DPO的分析上看,即便数据分布比较均衡,只要存在长度差异,DPO本身的长度敏感性就是会导致模型输出变长,因此可能还是需要一些算法层面的优化,比如在DPO阶段加入SFTloss就是一种简单有效的方法,在很多公开的大模型技术报告中也都有用到该方法。另外R-DPO、SamPO和LD-DPO的长度控制效果都算是比较好的方法。
DPO面临的一个问题(准确来讲是一种现象)就是会让大模型的输出变长,且多轮DPO的话会让模型输出越来越长。本篇文章我们将结合搜集到的一些相关工作,探讨一下业界对该现象的一些分析,探究这一现象产生的根本原因,以及如何有效地解决。
首先我们需要思考一个问题,模型输出变长到底是不是一件坏事?一般来说,输出变长可能会使内容更加详细,信息量更丰富,回复质量更高,用户体验更好。但如果过度长,输出了很多冗余信息,回复质量没有明显改善,反而带来了推理成本的增加,回复变得啰嗦,用户体验反而变差了。
因此,无论是从用户体验的角度还是多轮DPO能否run下去的角度,做好长度控制都是有必要的。
相关工作
先简要介绍一些相关工作,然后后面详细总结。
1.《Disentangling Length from Quality in Direct Preference Optimization》(简称R-DPO)
在这之前的一些RL的工作也有分析过长度爆炸问题,但该文章可能是第一个提出DPO的长度爆炸问题的。
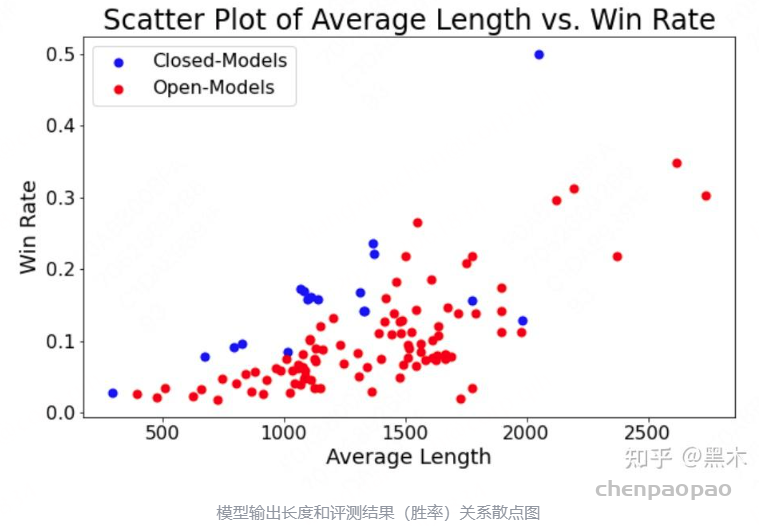
文章中发现,无论是RL训练中使用的Reward Model还是用来评测模型效果的打分模型(如GPT-4)都表现出明显的长度偏好,即会给更长的答案一个更高的分数(如下图)。且在一些公开的DPO训练数据集中,chosen的长度往往会比rejected更长,而这可能就是DPO后的模型输出长度明显比SFT模型更长的原因。
为了解决这个问题,该文章提出了一种长度正则化的策略,即在计算loss的时候添加一个长度正则项,从而避免模型对长度的过度拟合,公式如下:
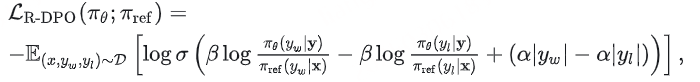
其中 |yw| 表示chosen的长度, |yl| 表示rejected的长度,从公式中可以看出,当chosen与rejected的长度差距越大,正则项的值越大,从而实现对长度的“惩罚”效果。
从文章中的实验结果可以看出,该方法确实可以在尽可能减少性能损失的前提下有效解决长度增长问题。(有时还是会损失一定的性能。)

2.《SimPO: Simple Preference Optimization with a Reference-Free Reward》(简称SimPO)
陈丹琦团队的工作,直接去掉了reference model,用长度归一的方式实现长度控制。其loss如下:
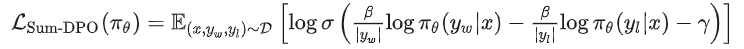
文章中提到了很多输出长度相关的内容,但核心贡献并不是做长度控制,而是用一种更简单高效的方法实现偏好训练。从公式上看,和原始DPOloss相比主要有两处不同,一个是分母从reference model的logp替换成了长度,另外就是增加了一个 γ ,类似一个offset的作用。不过其中对chosen和rejected的reward做长度归一的部分,直觉上看起来应该是能起到一定的长度控制效果的。
不过从论文中的实验结果看,该方法的效果还是比较好的(当时声称训出最强8B大模型),但与标准DPO相比似乎并没有实现长度控制的效果。
3.《Eliminating Biased Length Reliance of Direct Preference Optimization via Down-Sampled KL Divergence》(简称SamPO)
这篇论文对DPO后长度变长的问题进行了一定的分析,提出的一个核心观点是:DPO的算法本身也存在对response长度的依赖,chosen和rejected之间的长度差异可能会导致reward被高估/低估(overestimated or underestimated rewards)。即,当chosen过短时,reward会被低估,而当chosen过长时,reward会被高估。
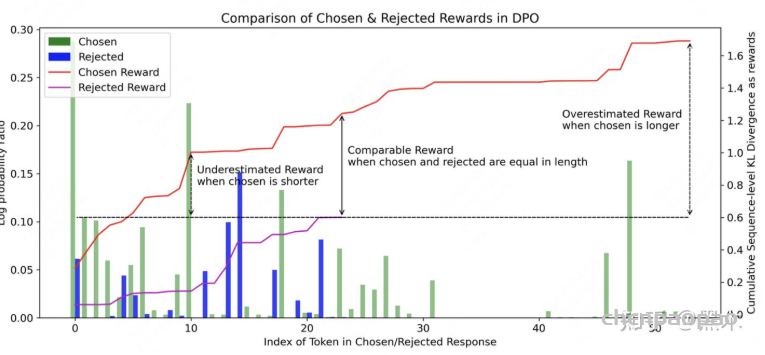
这篇工作中提出的一种方式就是在token级别下采样的概率特征,以计算正则化的KL散度,从而减少因pair长度不同而导致的奖励偏差。其loss的计算如下:
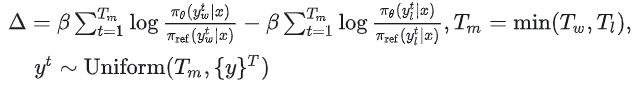
从公式可以看出,该方法的核心就是在计算reward的时候不再是全部token的条件概率的累乘(取log后就是累加),而是随机采样公共数量的token进行累乘。这样即便chosen和rejected长度不同,参与reward计算的token数是一样的。也就是说,在SamPO训练过程中,魔都看到的chosen和rejected相当于是完全等长的。
从文章中的实验结果看,该方法确实能有效控制模型输出长度的增长,甚至在多轮DPO依然能有效控制长度。但是在性能上看依然做不到碾压标准DPO的效果。
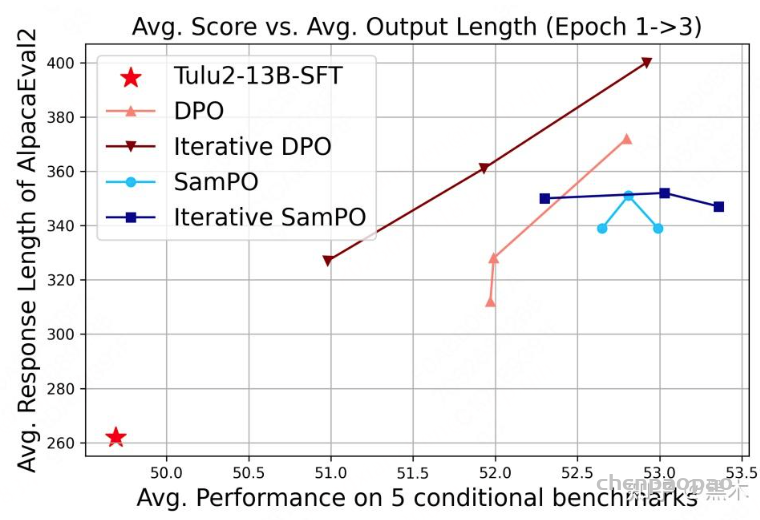
但该方法有两个风险便是:
- 本身DPO就存在一定的波动,随机下采样可能会导致训练的稳定性不强;
- 随机采样必然会导致一些信息缺失,如果采样时舍弃掉了一些非常重要的token可能会影响到训练效果。
4.《Length Desensitization in Direct Preference Optimization》(简称LD-DPO)
该论文可能是第一个从理论层面分析DPO后模型输出变长的原因的,其核心分析主要包括两方面:
- DPO的梯度优化方向和chosen/rejected的似然概率成反比。
- Response长度对似然概率的影响极大,因此长度会直接影响reward的计算,并影响到DPO的优化方向。
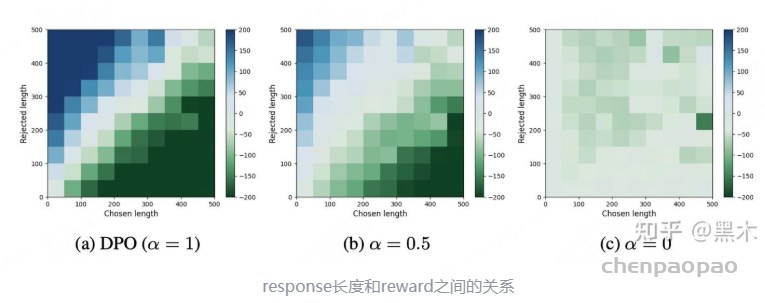
上图是一个对训练数据的统计热力图,图中,横坐标为chosen的长度,纵坐标为rejected的长度,颜色深度表示 logπθ(yl|x)−logπθ(yw|x) 值的大小。第一张图(a)是标准DPO,可以看出长度差距越大时,颜色越深,也就说明长度差距可能会导致reward计算产生bias,且长度差距越大这种bias越大。而这种bias会进一步影响到DPO的优化方向,使其往输出更长的方向进行优化。
该文章提出的解决方案是在计算似然概率时对长度进行解耦,将更长的答案拆成“公共长度部分”和“额外部分”,并进一步将后者拆分为真实偏好和冗余偏好,并对其中的冗余部分进行降权操作,通过一系列推导后将 πθ(y|x) 转化为如下的形式(可近似理解为完整似然概率部分与公共长度部分似然概率的加权和):
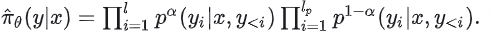
从公式上看,这种方式可以让长度更长的那个response(不管是chosen还是rejected)实现一定的缩放(),减少长度带来的似然概率的断崖式下滑,使其与另一个短response(不受影响)之间更具可比性,同时又不会像SamPO那样完全舍弃掉额外部分的信息。
从论文中的实验结果看,这种方法能够实现比较好的长度控制,且模型性能还能有一定提升,并且可以通过调整参数 α 可以实现不同程度的控制效果。另外文章还提出一个比较有意思的发现,就是过度冗余的回答可能反而会损害模型的推理能力,他们通过这种方法控制长度后,模型的推理能力也有明显提升。
其他工作
除此之外,还有一些工作直接在数据上做文章,通过控制chosen和rejected的长度差距来实现长度控制,如《Following Length Constraints in Instructions》(简称LIFT-DPO)。以及在一些开源模型的技术报告中我们也能看到一些相关的长度控制方法,如在利用RM打分排序时就综合考虑长度问题等,这些数据工作就不再详细展开了。
如何实现有效的长度控制?
- RM的优化:前面讲的都是对DPO进行长度控制的工作,但对RM本身的长度偏好进行优化的工作没有看到太多,如果大家有看到相关的也可以在评论区提供一下。如果将RM本身的长度偏好问题解决的话,那就可以极大程度上解决训练数据的长度分布均衡问题了。
- 数据的优化:有些工作会在数据构造时对长度进行综合考虑,如对RM打分进行长度归一后再排序、采样多个答案进行排序时根据均值方差限制chosen的长度等,通过这些方式可以减少长度差距过大的情况。如果数据本身的长度分布均衡了,也能一定程度上减缓这种问题。
- 训练算法上的优化:如果从LD-DPO的分析上看,即便数据分布比较均衡,只要存在长度差异,DPO本身的长度敏感性就是会导致模型输出变长,因此可能还是需要一些算法层面的优化,比如在DPO阶段加入SFTloss就是一种简单有效的方法,在很多公开的大模型技术报告中也都有用到该方法。另外R-DPO、SamPO和LD-DPO的长度控制效果都算是比较好的方法。
最后结合我自己的一些尝试来直接对比一下上面的四种方法:
- R-DPO是通过加正则项的方式实现长度控制,说是正则项,但其实只是一个常数,其原理相当于是对每条数据加上一个权重(文章中也提到了这点),即当chosen和rejected长度差距大时降低该数据的权重。也就是说,该方法其实是让模型减少对长度差距大的数据的学习权重。这种方法确实可以实现一定的长度控制效果,但必然会减少一些数据的利用率,这可能也是训练效果会有一定损失的原因。我自己尝试了一下该方案,实验下来确实可以做到长度控制效果,但大部分情况下性能都会比标准DPO差一些。
- SimPO是用长度归一来替换Reference Model的KL约束,理论上和长度控制其实没有太大关系,更多的是简化训练和提升性能。实验结果确实也体现了并不会比标准DPO更短。(该方法热度很高,但网络上褒贬不一,很多人表示无法复现结果。)根据我自己实验经验来看,跑出好的结果需要仔细调参,论文推荐的超参不一定适合所有情况。
- SamPO是直接用下采样的方式,强行将模型视角下的长答案变得和短答案一样长,该方法给人的直观感受就是长度控制效果肯定很好,但是很可能会有性能损失。但我自己实验下来,长度控制效果和R-DPO差不多,但是性能也比较不稳定,更换随机种子就会导致性能产生波动。我也尝试过将随机下采样改为top-k采样,即保留概率最大的top-k个token,但效果并不会比随机更好(这么直觉的方法可能论文作者也尝试过了)。
- LD-DPO的方法是只对答案过长的部分做了解耦和降权处理,通过降低过长部分的权重来实现整个条件概率的缩放,看起来是四种方法中实现最优雅的一种,既降低了长度差异带来的reward bias问题,又不会丢弃信息,相当于是用极小的代价实现了概率缩放目的。从论文中贴出的结果看,确实也是性能最强的一个,长度控制效果也是最好的。但论文代码没有开源,所以没有实验验证。但从公式上看复现难度应该不是很大,有能力的可以尝试复现一下看看效果。