
https://huggingface.co/nvidia/parakeet-tdt-1.1b
parakeet-tdt-1.1b 是一个自动语音识别 (ASR) 模型,可将语音转录为小写英文字母。该模型由 NVIDIA NeMo 和 Suno.ai 团队联合开发。它是 FastConformer [1] TDT [2](约 11 亿个参数)模型的 XXL 版本。
英伟达在发布了一款开源语音识别模型:Parakeet TDT 0.6B V2,其以 600M 参数登顶 Hugging Face Open ASR 榜单。
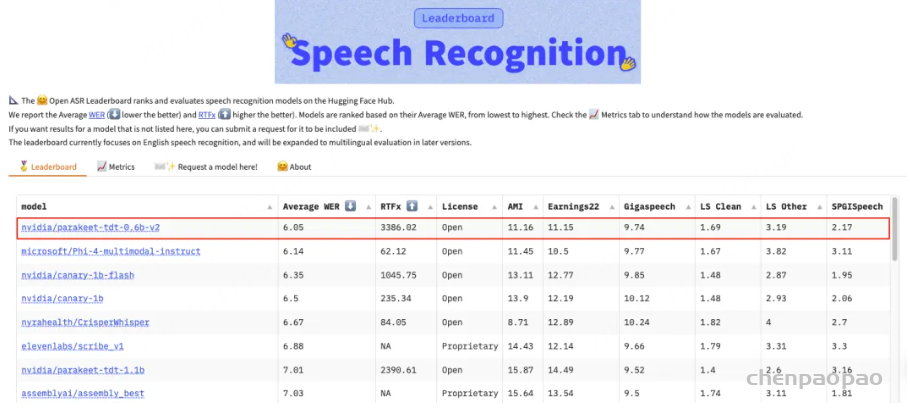
平均词错误率(WER)仅 6.05%,超越所有主流闭源模型。它能在 1 秒内转录 60 分钟高质量音频。
基于 FastConformer 架构和 TDT 解码器,仅用 600M 参数实现超低 WER 和极快推理速度。该模型基于 NVIDIA NeMo 和 Suno 团队收集和准备的 64K 小时英语语音进行训练。
该模型采用 FastConformer-TDT 架构。
FastConformer 是对传统 Conformer 模型的优化版本,采用了 8 倍深度可分离卷积下采样(8x depthwise-separable convolutional downsampling),以提高计算效率。
TDT(Token-and-Duration Transducer) 是对传统 Transducer 的一种泛化方式,它将 “音素(token)”与“持续时间(duration)”的预测过程解耦。与传统 Transducer 在推理阶段产生大量空白(blank)输出不同,TDT 模型可以通过持续时间预测跳过大多数 blank(例如本模型 parakeet-tdt-1.1b 最多可跳过 4 帧),从而大幅提升推理速度。关于 TDT 的详细内容,请参见文章:Efficient Sequence Transduction by Jointly Predicting Tokens and Durations。
The training dataset consists of private subset with 40K hours of English speech plus 24K hours from the following public datasets:
- Librispeech 960 hours of English speech
- Fisher Corpus
- Switchboard-1 Dataset
- WSJ-0 and WSJ-1
- National Speech Corpus (Part 1, Part 6)
- VCTK
- VoxPopuli (EN)
- Europarl-ASR (EN)
- Multilingual Librispeech (MLS EN) – 2,000 hour subset
- Mozilla Common Voice (v7.0)
- People’s Speech – 12,000 hour subset
自动语音识别(ASR)模型的性能通常通过词错误率(Word Error Rate, WER)来衡量。由于该数据集在多个领域上进行了训练,并且包含了更大规模的语料库,因此在通用音频转写任务中通常表现更好。
下表总结了本集合中各可用模型在使用Transducer 解码器下的性能表现。所有 ASR 模型的性能均以贪婪解码(greedy decoding)方式计算的 词错误率(WER%) 进行报告。
| 模型 | Tokenizer | Vocabulary Size | AMI | Earnings-22 | Giga Speech | LS test-clean | SPGI Speech | TEDLIUM-v3 | Vox Populi | Common Voice |
|---|---|---|---|---|---|---|---|---|---|---|
| 指标 | SentencePiece Unigram | 1024 | 15.90 | 14.65 | 9.55 | 1.39 | 2.62 | 3.42 | 3.56 | 5.48 |
核心优势
- • 极致转录效率:60 分钟音频仅需 1 秒内完成转录(A100 推理)
- • OpenASR 榜首表现:超越 Whisper、Conformer、Wav2Vec 等主流闭源模型
- • 极小参数量:仅 0.6B(轻量级,适合边缘设备)
- • 高精度:平均 WER 6.05%(Hugging Face Open ASR 榜单),优于 Whisper-large-v3
- • 高鲁棒性:多语速、多口音、多录音环境下表现稳定(英文)
应用场景推荐
- • 实时会议转写
- • 手机/设备端语音助手
- • 视频字幕生成
- • 大模型音频输入预处理器
- • 教育/课程转录系统
技术构建说明
- • 架构:TDT(Time-Depth Transformer),专注于时间维度建模
- • 数据:英伟达自建 + 公共语音数据集大规模训练
- • 推理引擎优化:支持 TensorRT / ONNX Runtime 等高性能部署方案