
- https://github.com/google/sentencepiece
- https://github.com/openai/tiktoken
- https://github.com/rsennrich/subword-nmt/tree/master 【paraformer使用】
SentencePiece 简介
https://github.com/google/sentencepiece
SentencePiece 是一种无监督的文本 tokenizer 和 detokenizer,主要用于基于神经网络的文本生成系统,其中,词汇量在神经网络模型训练之前就已经预先确定了。 SentencePiece 实现了subword单元(例如,字节对编码 (BPE))和 unigram 语言模型),并可以直接从原始句子训练字词模型(subword model)。 这使得我们可以制作一个不依赖于特定语言的预处理和后处理的纯粹的端到端系统。
SentencePiece 在大模型领域主要用于文本的 分词 和 编码。
分词 是将文本分割成一个个独立的词语或符号。传统的中文分词方法,例如 BMM 分词、HMM 分词,都是基于规则的,需要人工制定分词规则。而 SentencePiece 则是基于 无监督学习 的,它可以自动学习文本的语义和结构,并根据学习结果进行分词。
编码 是将分词后的词语或符号转换为数字形式,以便计算机能够处理。SentencePiece 使用了一种称为 字节对编码 的方法,它可以将每个词语或符号编码成一个或多个字节。字节对编码的优点是能够有效地利用空间,并且可以将词语或符号之间的关系编码到编码中。
SentencePiece 在大模型领域具有以下优势:
- 分词效果好,能够准确地识别词语和符号的边界。
- 编码效率高,能够节省空间。
- 能够将词语或符号之间的关系编码到编码中,有利于模型学习。
因此,SentencePiece 已经被广泛应用于各大模型,例如 Google 的 BERT、GPT-3,以及阿里巴巴的 M6 等。
简单来说,SentencePiece 就是大模型领域的一个 分词和编码工具。它可以帮助大模型更好地理解和处理文本。
自监督训练原理
SentencePiece 的自监督训练模型原理是通过 无监督学习 的方式,学习文本的语义和结构,并根据学习结果进行分词和编码。
具体来说,SentencePiece 的训练过程可以分为以下几个步骤:
- 数据准备:首先需要准备一个文本语料库,语料库中的文本可以是任何类型,例如新闻文章、书籍、代码等。
- 模型训练:使用无监督学习算法训练 SentencePiece 模型,模型的输入是文本语料库,输出是分词后的文本。
- 模型评估:使用评估指标评估模型的性能,例如分词准确率、召回率等。
SentencePiece 使用的无监督学习算法是一种称为 Masked Language Modeling (MLM) 的算法。MLM 的基本思想是:将文本中的部分词语或符号进行遮蔽,然后让模型预测被遮蔽的词语或符号。通过这种方式,模型可以学习文本的语义和结构。
在 SentencePiece 中,MLM 的具体实现如下:
- 随机选择文本中的部分词语或符号进行遮蔽。
- 将被遮蔽的词语或符号替换为一个特殊符号,例如
[MASK]。 - 将处理后的文本输入模型,让模型预测被遮蔽的词语或符号。
通过这种方式,模型可以学习到被遮蔽词语或符号与周围词语或符号之间的关系,从而提高分词和编码的准确性。
SentencePiece 的自监督训练模型具有以下优势:
- 不需要人工制定分词规则,能够自动学习文本的语义和结构。
- 分词效果好,能够准确地识别词语和符号的边界。
- 编码效率高,能够节省空间。
SentencePiece 的自监督训练模型已经被广泛应用于各大模型,例如 Google 的 BERT、GPT-3,以及阿里巴巴的 M6 等。
SentencePiece中包含有四个部分:
- Normalizer: 规一化操作,类似Unicode把字符转为统一格式。
- Trainer: 从规一化后的语料中学习subword的切分模型。
- Encoder: 对应预处理时的tokenization操作,把句子转为对应的subword或id。
- Decoder: 对应后处理时的detokenization操作,把subword或id还原为原有句子
和 SentencePiece 类似的工具
- Jieba:Jieba 是一个中文分词工具,它使用了一种称为 最大似然法 的方法进行分词。Jieba 的分词效果较好,并且速度较快。
- Hmmseg:Hmmseg 是另一个中文分词工具,它使用了一种称为 隐马尔可夫模型 的方法进行分词。Hmmseg 的分词效果较好,并且可以支持多种语言。
- Stanford CoreNLP:Stanford CoreNLP 是一个自然语言处理工具包,它包含了分词、词性标注、句法分析等功能。Stanford CoreNLP 的分词效果较好,并且可以支持多种语言。
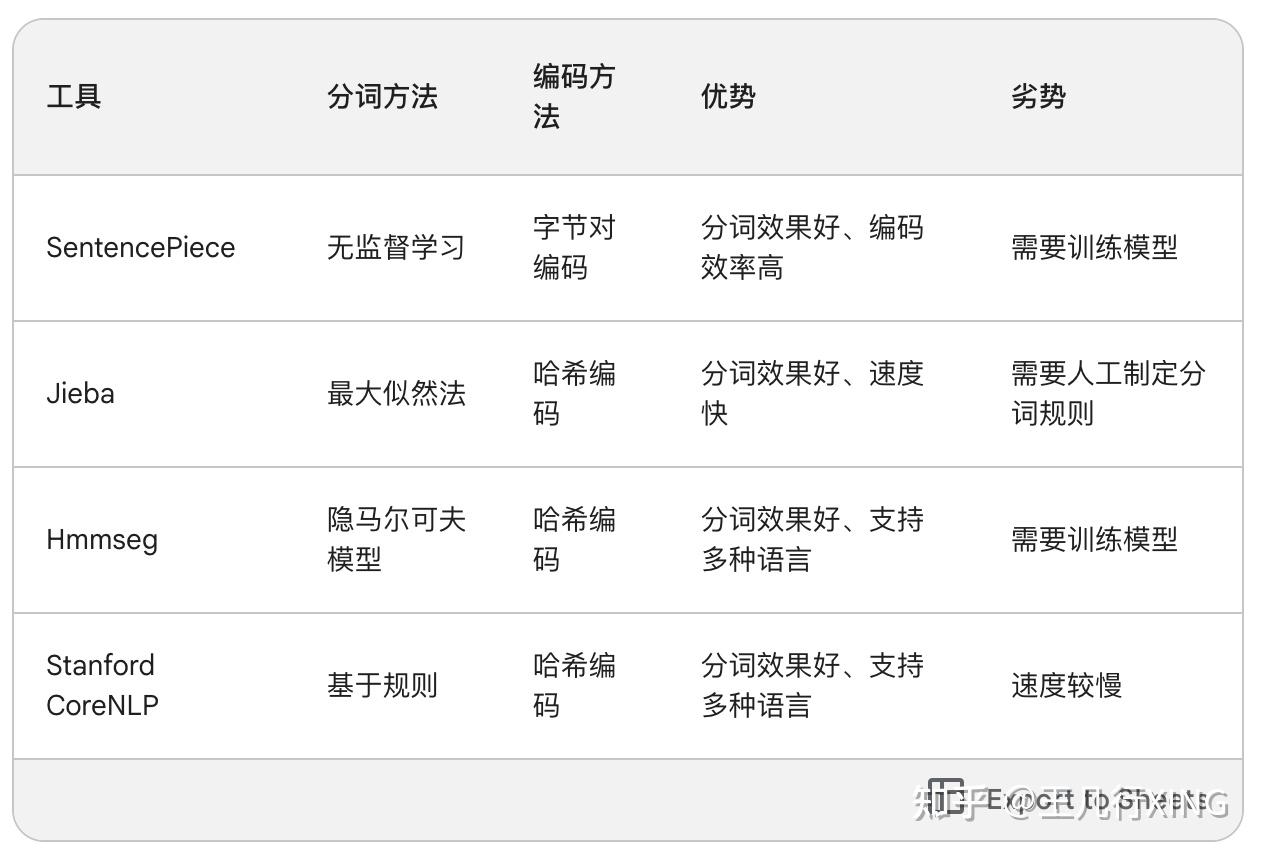
使用建议:
- 如果需要对中文文本进行分词,并且对分词效果要求较高,可以选择 SentencePiece、Jieba 或 Hmmseg。
- 如果需要对多种语言文本进行分词,可以选择 Stanford CoreNLP。
- 如果需要对文本进行分词和编码,并且对速度要求较高,可以选择 Jieba。
- 如果需要对文本进行分词和编码,并且对分词效果要求较高,可以选择 SentencePiece 或 Hmmseg。
TiToken 简介
Tiktoken 的功能与 SentencePiece 类似,都是用于文本的 分词 和 编码。
Tiktoken 是一个基于 BPE 算法的 快速分词器,它专门针对 GPT-4 和 ChatGPT 等大模型进行了优化。Tiktoken 的主要特点如下:
- 速度快:Tiktoken 的分词速度比 SentencePiece 快很多,可以满足大模型训练和推理的需求。
- 效果好:Tiktoken 的分词效果与 SentencePiece 相当,能够准确地识别词语和符号的边界。
- 易用性:Tiktoken 提供了简单的 API 接口,方便使用。
Tiktoken 与 SentencePiece 的主要区别 如下:
- 分词算法:Tiktoken 使用 BPE 算法进行分词,而 SentencePiece 使用的是无监督学习算法。
- 速度:Tiktoken 的分词速度比 SentencePiece 快很多。
- 模型:Tiktoken 专门针对 GPT-4 和 ChatGPT 等大模型进行了优化,而 SentencePiece 则是通用的。
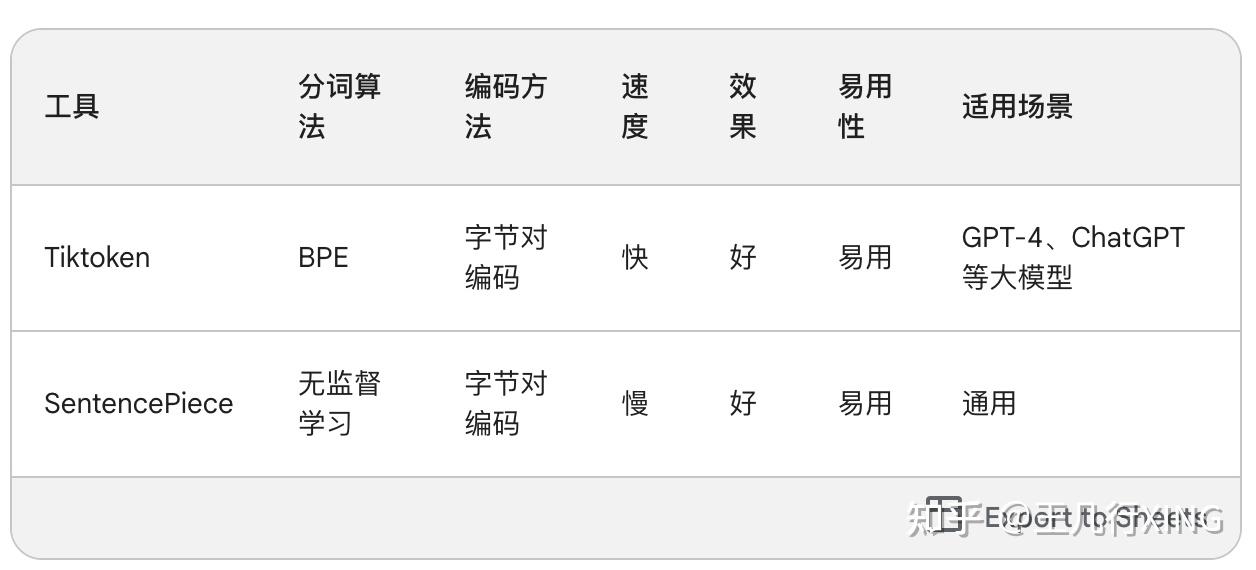
具体使用建议:
- 如果需要对文本进行快速分词,并且对分词效果要求较高,可以选择 Tiktoken。
- 如果需要对文本进行分词和编码,并且需要支持多种语言,可以选择 SentencePiece。
- 如果需要对 GPT-4 或 ChatGPT 等大模型进行训练或推理,可以选择 Tiktoken。