
Github:https://github.com/shuaijiang/Ke-Omni-R 【开源训练和推理代码】
贡献:用于将GRPO/思考过程 加入到语音大模型的强化训练过程中。
- [1] Xie, Zhifei, et al. “Audio-Reasoner: Improving Reasoning Capability in Large Audio Language Models.” arXiv preprint arXiv:2503.02318.
- [2] Ma, Ziyang, et al. “Audio-CoT: Exploring Chain-of-Thought Reasoning in Large Audio Language Model.” arXiv preprint arXiv:2501.07246.
- [3] Li, Gang, et al. “Reinforcement Learning Outperforms Supervised Fine-Tuning: A Case Study on Audio Question Answering.” arXiv preprint arXiv:2503.11197
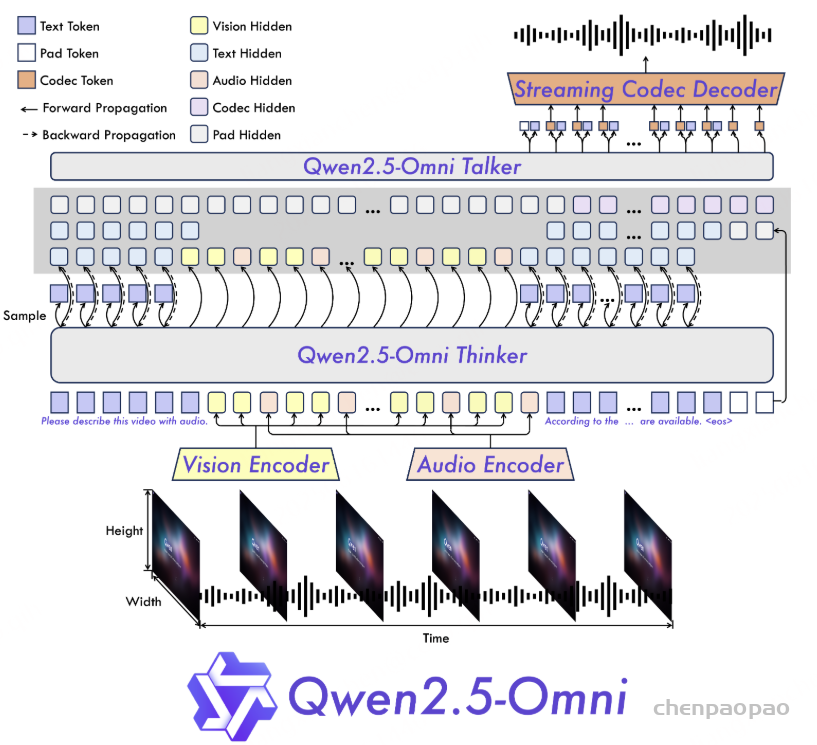
- [4] Xu, Jin, et al. “Qwen2.5-Omni Technical Report.” arXiv preprint arXiv:2503.20215
Ke-Omni-R 是基于 Qwen2.5-Omni 构建的高级音频推理模型。构建音频推理模型,通过强化学习引入深度思考过程,提升复杂任务的理解和推理能力。仅使用 10,000 个训练后样本,Ke-Omni-R 就在 MMAU Test-mini 和 Test 基准测试中取得了最佳性能。其开发过程中的关键洞察包括:
- GRPO 算法 :GRPO 算法显著增强了已经很强大的基础模型(Qwen2.5-Omni-7B)的性能,即使在看不见的语音领域也表现出卓越的泛化能力。
- 思考过程 :融入简洁的思考过程(少于 50 个字)对于提高推理能力起着至关重要的作用。
- KL 散度 :通过利用 KL 散度,在 GRPO 训练期间观察到轻微的改进。
- 领域比例 vs. 数据量 :领域多样性比数据量更重要。我们仅使用了 10,000 个样本,其中 5,000 个从 AVQA 中随机选取,另外 5,000 个从 MusicBench 中选取。
Performance: Accuracies (%)↑ on MMAU Test-mini and Test benchmark
| Model | Method | Sound (Test-mini) | Sound (Test) | Music (Test-mini) | Music (Test) | Speech (Test-mini) | Speech (Test) | Average (Test-mini) | Average (Test) |
|---|---|---|---|---|---|---|---|---|---|
| – | Human* | 86.31 | – | 78.22 | – | 82.17 | – | 82.23 | – |
| Gemini Pro 2.0 Flash | Direct Inference* | 56.46 | 61.73 | 58.68 | 56.53 | 51.65 | 61.53 | 55.60 | 59.93 |
| Audio Flamingo 2 | Direct Inference* | 61.56 | 65.10 | 73.95 | 72.90 | 30.93 | 40.26 | 55.48 | 59.42 |
| GPT4o + Strong Cap. | Direct Inference* | 57.35 | 55.83 | 49.70 | 51.73 | 64.86 | 68.66 | 57.30 | 58.74 |
| Llama-3-8B-Instruct + Strong Cap. | Direct Inference* | 50.75 | 49.10 | 48.93 | 48.93 | 55.25 | 62.70 | 52.10 | 53.57 |
| Qwen2-Audio-7B-Instruct | Direct Inference* | 54.95 | 45.90 | 50.98 | 53.26 | 42.04 | 45.90 | 49.20 | 52.50 |
| SALAMONN | Direct Inference* | 41.00 | 40.30 | 34.80 | 33.76 | 25.50 | 24.24 | 33.70 | 32.77 |
| Audio-Reasoner(Qwen2-Audio-7B-Instruct) | [1] | 60.06 | – | 64.30 | – | 60.70 | – | 61.71 | – |
| Audio-Cot(Qwen2-Audio-7B-Instruct) | [2] | 61.86 | – | 56.29 | – | 55.26 | – | 57.80 | – |
| R1-AQA(Qwen2-Audio-7B-Instruct) | [3] | 68.77 | 69.76 | 64.37 | 61.40 | 63.66 | 62.70 | 65.60 | 64.36 |
| Qwen2.5-Omni-7B | [4] | 67.87 | – | 69.16 | – | 59.76 | – | 65.60 | – |
| Qwen2.5-Omni-3B | [4] | 70.27 | – | 60.48 | – | 59.16 | – | 63.30 | – |
| Ke-Omni-R-3B(Qwen2.5-Omni-3B) | GRPO w/ think (ours) | 72.37 | 71.87 | 65.57 | 59.60 | 64.26 | 64.17 | 67.40 | 65.17 |
| Ke-Omni-R(Qwen2.5-Omni-7B) | GRPO w/o think (ours) | 69.67 | 70.57 | 67.66 | 64.00 | 66.37 | 67.17 | 67.90 | 67.24 |
| Ke-Omni-R(Qwen2.5-Omni-7B) | GRPO w/ think (ours) | 69.37 | 71.90 | 69.46 | 67.13 | 67.87 | 67.10 | 68.90 | 68.71 |
Performance: CER/WER (%)↓ on ASR benchmark
| Model | Method | WenetSpeech test-net | WenetSpeech test-meeting | LibriSpeech test-clean | LibriSpeech test-other |
|---|---|---|---|---|---|
| Qwen2.5-Omni-3B | [4] | 6.3 | 8.1 | 2.2 | 4.5 |
| Qwen2.5-Omni-7B | [4] | 5.9 | 7.7 | 1.8 | 3.4 |
| Ke-Omni-3B | ours | 11.7 | 16.1 | 1.8 | 3.8 |
| Ke-Omni-7B | ours | 7.5 | 9.8 | 1.6 | 3.1 |