
VITA-Audio: Fast Interleaved Cross-Modal Token Generation for Efficient Large Speech-Language Model
项目训练和推理代码以及模型权重完全开源,VITA-Audio 支持中英双语,且训练过程中仅使用开源数据,却在同等参数量级中稳居性能第一梯队。
如何高效生成Audio Token?
在端到端语音模型中,生成音频往往要经历以下流程:首先,语音 Token 随着语言模型(LLM)前向传播被逐步自回归地生成;随后,多个已生成的语音 Token 会被收集并送入解码器,最终合成为可播放的音频。由于每一步都依赖上一步的输出,这种多次循环推理的方式在生成首个音频片段前会消耗大量时间,且随着模型规模的扩大,延迟问题愈发严重。
VITA-Audio 团队对模型最后一层解码器的 Hidden States 进行了可视化分析。结果表明,语音模型在预测某个音频 Token 时,对应的文本 Token Hidden States 所承载的注意力权重显著高于其他位置。
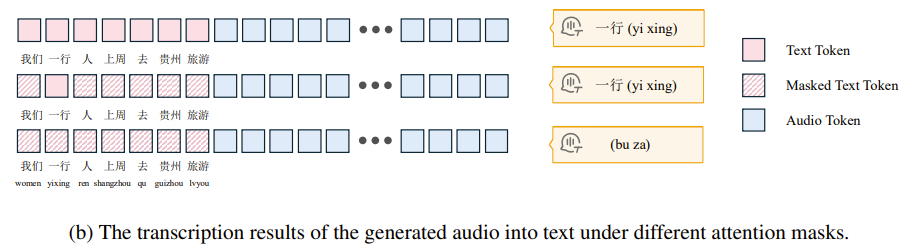
更进一步的实验发现:
- 当屏蔽所有文本位置的 Hidden States 时,模型无法生成正常的音频;
- 但如果仅保留与当前音频 Token 对应的那一位置的文本 Hidden States,模型依然能够输出准确、连贯的语音,且这些 Hidden States 已隐含了足够的上下文信息(例如,区分多音字“行”读作“xíng”还是“háng”)。
这一发现表明,语音生成并不需要对整个文本—音频序列的全局语义空间进行复杂建模;相反,只需利用对应位置的文本 Hidden States,通过相对简单的映射模块即可完成高质量的音频 Token 预测。
基于此,VITA-Audio 提出了一种轻量级的多重跨模态标记预测(Multiple Cross-modal Token Prediction,MCTP)模块。该模块直接在单次前向传播中预测多个音频 Token,大幅减少自回归循环次数,不仅加速了整体推理流程,更显著降低了流式场景下首个音频片段的生成延迟。
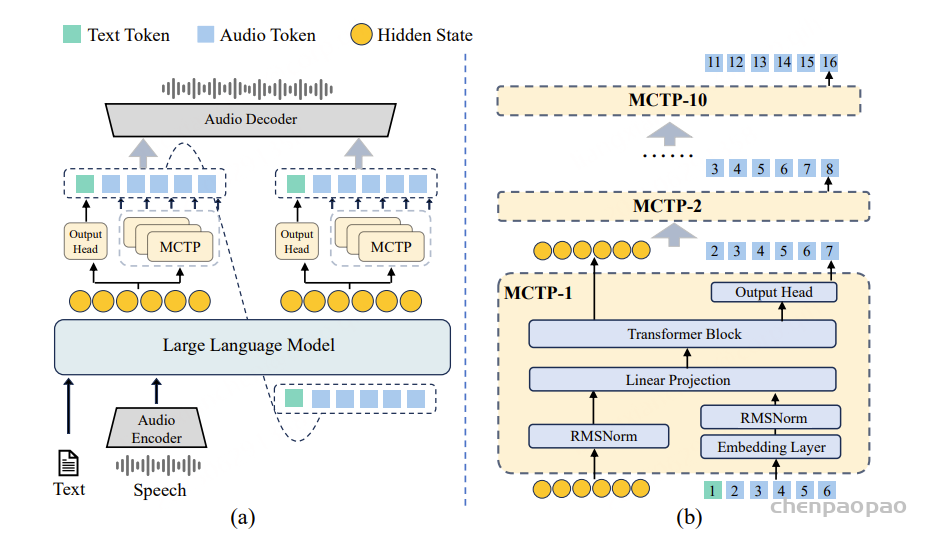
VITA-Audio 的核心组件包括音频编码器、音频解码器、LLM[Qwen2.5-7B]、十个轻量级 MCTP 模块。CosyVoice as the audio encoder and decoder。其推理流程如下:
- 1. 文本与音频特征分别经编码后输入 LLM,LLM 在单次前向传播中生成文本 Token 或音频 Token。
- 2. 将 LLM 最后一层的隐藏态和输出先输入第一个 MCTP 模块,其输出再依次传递给后续的 9 个 MCTP 模块;每个模块各自预测一个音频 Token,累计得到 10 个 Token,并由音频解码器合成为音频片段。
- 3. 在下一次前向传播中,LLM 生成的 Token 会与 MCTP 模块生成的音频 Token 一并作为 LLM 输入,进行下一次前向传播。
由于每个 MCTP 子模块的参数量远小于 LLM,单次预测耗时仅需约 2.4 ms(约为 LLM 推理时间的 11%),显著降低了首个音频片段的生成延迟,并大幅提升整体推理速度。
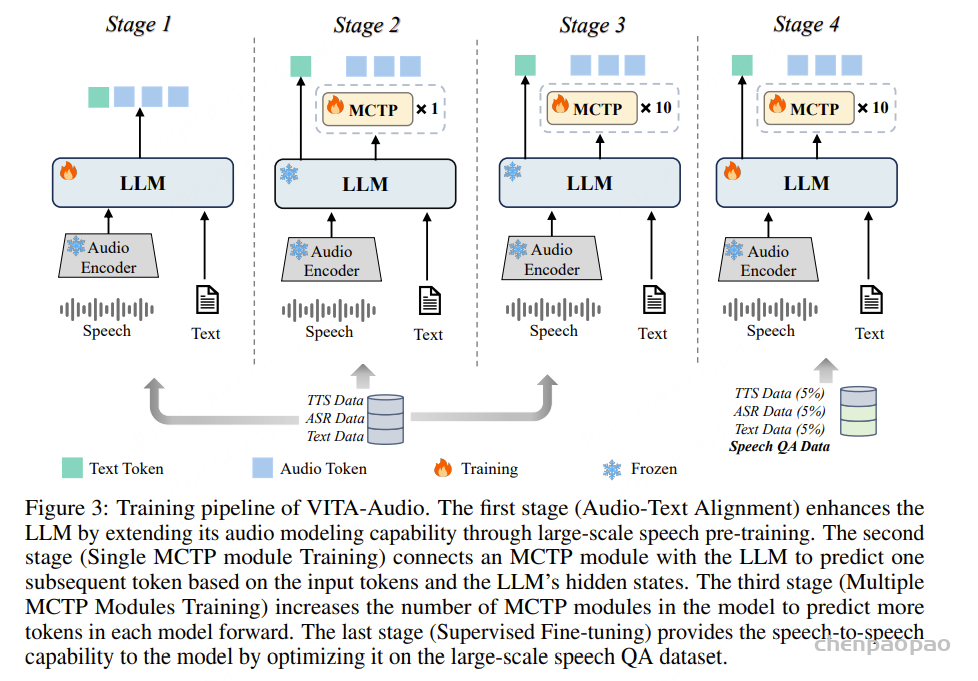
为了解决同时从头训练10个 MCTP 模块带来的不稳定性,VITA-Audio 采用了如下四阶段渐进式训练策略:
- 1. 第一阶段-音频–文本对齐:利用大规模语音预训练任务,将音频建模能力融入 LLM,使其 Hidden states 同时承载文本和音频信息。
- 2. 第二阶段-单 MCTP 模块训练:训练初始 MCTP 模块,使其能够基于 LLM 的输出 Token 和 Hidden States 预测下一个标记。
- 3. 第三阶段-多 MCTP 模块训练:将首个 MCTP 模块的能力扩展到多个 MCTP 模块,每个模块根据前一个 MCTP 模块的输出标记和 Hidden States 预测其对应位置的标记。
- 4. 第四阶段-监督微调:以语音问答数据集为主进行监督微调,同时穿插 TTS、ASR 及纯文本数据,确保模型在各类任务上的泛化能力与训练收敛的平衡。

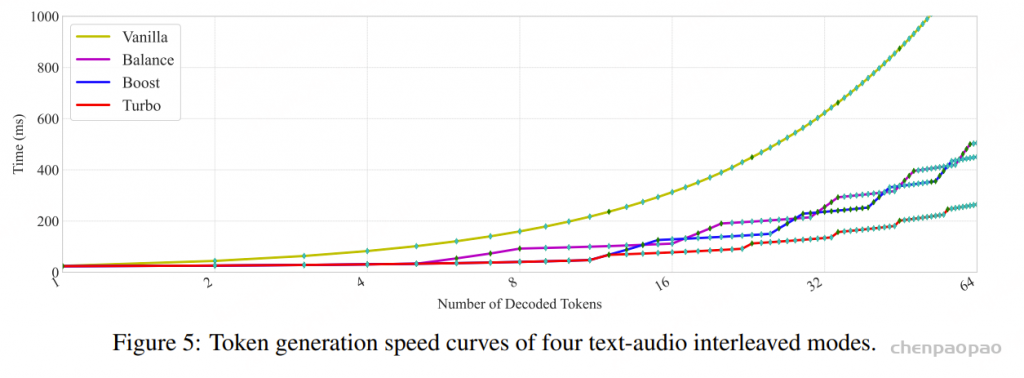
VITA-Audio 提供四种推理范式,以满足不同应用场景对速度与质量的平衡需求:
- VITA-Audio-Turbo:最高效的方式,每次前向传播 LLM 生成一个标记【音频或者文本token】,MCTP 模块生成 10 个标记【音频或者文本token】,但因 MCTP 模块也参与文本预测,性能会略有下降,常用于 ASR 和 TTS 任务中。
- VITA-Audio-Boost:LLM 专注生成文本 Token,MCTP 模块生成 Audio Token,并且第一次前向中就使用全部的 MCTP 模块,可以在第一次前向中就生成可以用于解码的 Audio Token Chunk。
- VITA-Audio-Balance:在前两次前向中仅激活部分 MCTP 模块,保以维持文本与音频 Token 的合理配比(1:2),随后逐步激活部模块,通过动态调节文本/音频 Token 输出比例,实现生成速度与质量的最优平衡。
- VITA-Audio-Vanilla:完全依赖 LLM 自回归生成所有 Token,不调用 MCTP 加速模块,推理速度最慢,但可获得最高的音频细节与一致性。



本文介绍了 VITA-Audio,这是一个轻量级框架,其核心在于引入独立高效的多重跨模态令牌预测(MCTP)模块,能够直接从文本 Token 与 LLM Hidden States 中生成音频响应,无需依赖 LLM 的全局语义建模,仅通过简单映射即可完成文本隐藏态到音频令牌的转换。
实验表明,VITA-Audio 在仅仅使用开源数据的情况下,在 ASR、TTS 和 SQA 任务的多个基准测试中均跻身同参数量级开源模型的第一梯队;同时,其推理速度与响应延迟也取得了显著突破。由此,VITA-Audio 为实时语音到语音生成树立了全新的范式。