论文:Voxtral https://arxiv.org/abs/2507.13264
- Webpage: https://mistral.ai/news/voxtral/
- Model weights:
- Evals: https://huggingface.co/collections/mistralai/speech-evals-6875e9b26c78be4a081050f4
法国 AI 巨头发布了他们首个开源语音模型系列——Voxtral,推出了 Voxtral Mini [4.7B]和 Voxtral Small[24.3B] 两款多模态音频聊天模型。
Voxtral 的两个模型不仅仅是转录工具,还具备以下功能:
- 长文本上下文处理:支持最长 32,000 个 token 的上下文长度,可处理最长 30 分钟的转录音频,或最长 40 分钟的语义理解任务。
- 内置问答与总结功能:无需串联 ASR(自动语音识别)和语言模型,即可直接就音频内容提问或生成结构化摘要。
- 原生多语言支持:自动语言识别,在全球主流语言(如英语、西班牙语、法语、葡萄牙语、印地语、德语、荷兰语、意大利语等)中表现优异,帮助团队使用单一系统服务全球用户。
- 语音直接调用函数功能:可根据用户语音中的意图,直接触发后端函数、工作流或 API 调用,无需中间解析步骤,使语音交互可直接转化为系统指令。
- 强大的文本处理能力:延续了其语言模型基础——Mistral Small 3.1 的文本理解能力。
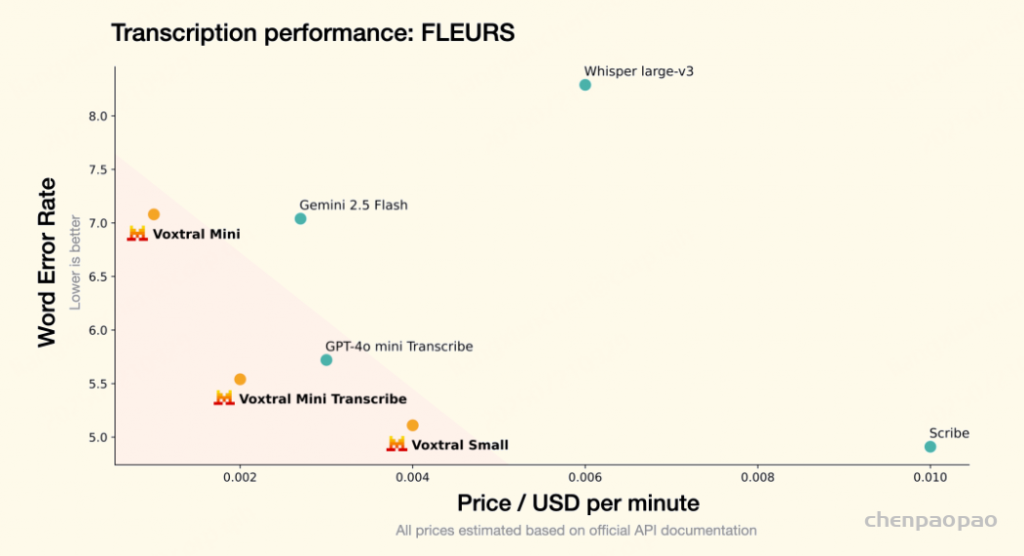
这些功能使 Voxtral 模型非常适合真实世界中的交互场景和下游任务,如摘要生成、问题回答、内容分析和洞察提取。在对成本敏感的应用场景中,Voxtral Mini Transcribe 的性能优于 OpenAI Whisper,价格却不到一半;在高端应用中,Voxtral Small 的表现媲美 ElevenLabs Scribe,同样价格不到一半。
Modeling
Voxtral 基于 Transformer 架构,由三个组件组成:用于处理语音输入的音频编码器、用于对音频嵌入进行下采样的适配器层,以及用于推理和生成文本输出的语言解码器。其整体架构如图 1 所示:

input:log-Mel spectrogram[128Mel-bins and 160 hop-length]
Audio Encoder:Whisper large-v3 50Hz
Adapter:MLP downsampling factors of 4x
LLM: Ministral 3B && Mistral Small 3.1 24B
Audio Encoder
音频编码器基于 Whisper large-v3。原始音频波形首先被转换为 log-Mel 频谱图,其参数为 128 个 Mel 频段(Mel-bins)和 160 的步长(hop-length)。在 Whisper 编码器内部,频谱图首先通过一个卷积层(convolutional stem),将时间分辨率下采样一半,然后输入一系列双向自注意力层(bidirectional self-attention layers)。最终得到的音频嵌入帧率为 50 Hz。
Mel-bins 指的是将频率轴按照 Mel 标度划分的“通道”数。Mel 标度是模拟人耳感知音高的非线性频率标度,低频分得更密,高频分得更疏。128 Mel-bins 就是将频率范围(通常是从 0 到某个最大频率,比如 8000Hz)映射成 128 个“频带”或“维度”,每一维代表一个 Mel 频段的能量。 hop-length 表示相邻两个短时傅里叶变换(STFT)窗口之间的间隔(帧移)。单位是 样本数(samples),不是时间。每 10 毫秒提取一帧频谱(帧移),这使得频谱图具有较高的时间分辨率。
Whisper 的感受野固定为 30 秒。为了处理超过该时长的音频序列,系统会先对整段音频计算 log-Mel 频谱图,但编码器会将其划分为每段 30 秒,分别独立处理。每个分段的绝对位置编码都会重置,并在同一个 batch 维度中组织这些分段。
在编码器的注意力层中,这种做法在功能上等同于 chunk-wise attention ,可有效降低长音频输入的计算开销,同时增强对不同长度输入的泛化能力。每个分段计算得到的嵌入(embedding)会在输出阶段拼接在一起,最终形成对整段音频的统一表示。
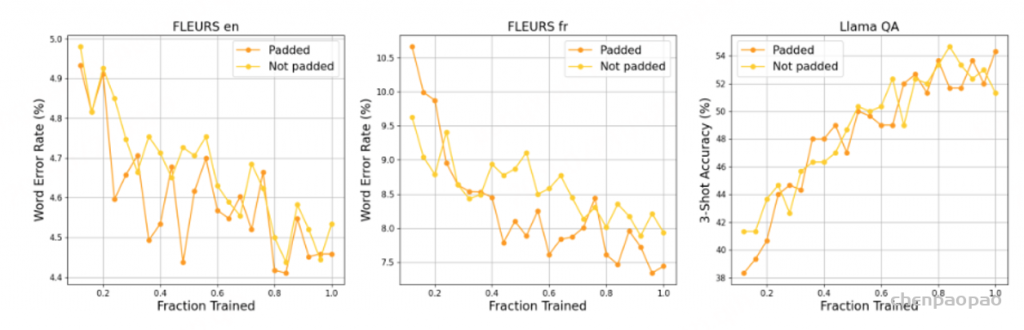
由于感受野固定,Whisper 也会将较短的音频填充到 30 秒。然而,实证结果显示,即使对编码器进行了适应性调整,性能仍有所下降。因此,我们仍保留将所有音频输入填充到下一个 30 秒整数倍的做法。
Whisper 将短音频填充至 30 秒。我们研究了在预训练过程中,在编码器权重已训练以适应新配置的前提下,这种填充约束是否必要。禁用填充几乎不会对 FLEURS 英语造成任何惩罚,但法语的 WER 会降低 0.5%。在两次运行的训练过程中,Llama QA 的 3 次准确率相当。为了在不影响语音理解的情况下获得最佳的语音识别分数,我们选择在音频编码器中保留填充。
Adapter Downsampling
基准音频编码器的运行帧率为 50 Hz。为了减少解码器的计算量和内存占用,我们插入了一个 MLP 适配器层,用于沿时间轴对音频嵌入进行下采样。我们分别以 50、25、12.5 和 6.25 Hz 的目标帧率进行实验,对应的下采样倍数分别为 1 倍、2 倍、4 倍和 8 倍。
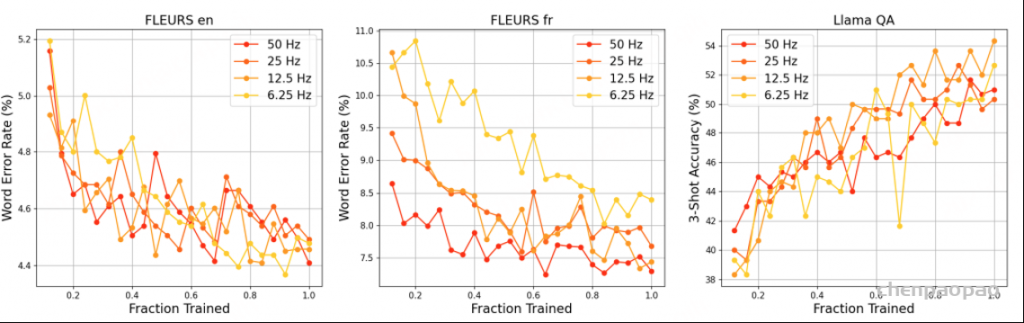
对于 25 Hz 和 12.5 Hz,ASR 基准测试中几乎没有下降。然而,对于 6.25 Hz,FLUERS 法语的损失超过 1%。在 Llama QA 上,12.5 Hz 超过了 50 Hz 的基准,得分高出 1.5%。我们假设,在 12.5 Hz 下,每个音频嵌入编码的信息量与语言解码器主干中的文本嵌入相似,从而带来卓越的理解性能。基于序列长度、ASR 和语音理解性能之间的权衡,我们选择 12.5 Hz 作为 Voxtral 的最佳帧率。
Language Decoder
Voxtral 的两个版本:Mini 和 Small。Voxtral Mini 构建于 Ministral 3B 之上,这是一个专注于边缘计算的模型,在较小的内存占用下提供极具竞争力的性能。Voxtral Small 则利用了 Mistral Small 3.1 24B 主干模型 ,在一系列知识和推理任务中表现出色。

Methodology
Pretraining:introduce speech to the language decoder
Voxtral 的预训练阶段旨在将语音引入语言解码器,与现有的文本模态互补。我们定义了两种将音频和文本结合到模型训练样本中的模式: 音频到文本重复和跨模态延续 。
音频转文本的重复模式定义为一个音频片段 An ,后跟相应的转录 Tn 。训练样本由单个音频-文本对 (An,Tn) 组成。此公式模拟语音识别,用于明确地训练模型进行语音转文本对齐。
另一方面,跨模态连续模式旨在通过模态不变的上下文建模,隐式地对齐语音和文本模态。具体来说,对于每个音频片段 An ,对应的文本是序列 Tn+1 中的前一个文本片段。此外,训练样本由多个连续片段的音频和文本交织而成: (A1,T2,A3,T4,…,AN−1,TN) 。这种结构类似于问答或对话等任务,其中模型必须保持跨模态的话语连续性。
由于我们使用两种不同的数据模式,因此给定音频片段的后续文本片段具有歧义性;重复和延续都是有效的。为了消除歧义,我们引入了两个特殊标记来指定预期输出: <repeat> 表示重复, <next> 表示延续。这些标记用于在训练期间指示模式,并在推理期间作为提示的一部分来控制模型行为。
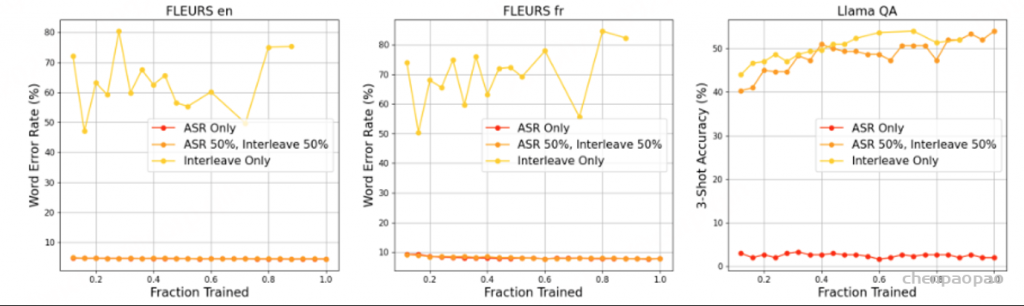
Balancing the two tasks with equal ratios achieves ASR and Llama QA performance comparable。
我们在预训练过程中利用了两种数据模式:音频到文本的重复和跨模态延续。图 9 演示了改变这两种模式的比例如何影响 ASR 和语音理解。为了更好地理解跨模态延续模式对 ASR 的潜在能力,我们在 FLEURS ASR 任务的 3-Shot 版本上对其进行了评估,该版本与训练期间呈现的多轮模式更加一致。
仅包含音频转文本重复模式可获得出色的 ASR 性能,但 Llama QA 的性能几乎为零。相反,仅使用跨模态延续模式进行训练可获得出色的 Llama QA 性能,但 ASR 的字错误率 (WER) 接近 60%。以相同的比率平衡这两个任务,可实现与使用单一模式的运行相当的 ASR 和 Llama QA 性能。因此,我们在预训练期间以相同的概率对每个模式进行采样。
为了保留文本能力,我们还在数据混合中包含了文本预训练数据。
Supervised Finetuning
在训练后阶段,我们的主要目标是保留或略微提升预训练期间建立的转录能力,同时扩展模型在一系列语音理解任务中的熟练程度。我们还开发了强大的指令遵循行为,无论用户输入是音频还是文本形式。
我们的语音理解数据分为两类:一类是以音频作为语境,助手响应文本查询的任务;另一类是助手直接响应音频输入的任务。这两类任务都高度依赖于合成数据。
Audio Context, Text Query:为了创建涉及音频上下文与文本查询配对任务的合成数据,我们利用长格式音频数据(最长约 40 分钟的片段)及其对应的转录本和语言识别元数据。转录本与定制的提示配对,并输入到 LLM (Mistral Large) 中,然后 LLM 生成与音频内容相关的问答对。提示明确指示 LLM 将问题和答案构建为听觉理解而非文本分析的结果,从而鼓励下游音频模型做出自然的响应。为了实现数据的多样性和丰富性,我们采用了多种问题类型,包括简单的事实查询、“大海捞针”式的检索任务以及推理密集型问题。此外,为了最大限度地减少重复的问题风格,LLM 会为每个音频片段生成多个候选问答对,并从中抽取一对纳入训练后数据集。虽然我们通常确保问答对与原始音频和文字记录的语言相匹配,但我们偶尔会指示 Mistral Large 生成不同语言的问答对,以便对用户不会说的语言的音频进行 QA。
此外,我们还分配了另一部分长音频数据用于合成摘要和翻译数据。对于翻译任务,我们利用语言识别元数据来选择不同于原始音频语言的目标语言。为了避免过度拟合于狭窄范围的用户消息模式,我们从大量手动整理的合理用户请求中进行了采样。
Audio-Only Input:对于用户仅提供音频输入的场景,我们调整了现有的文本监督微调数据(包括函数调用数据集),通过使用文本转语音 (TTS) 模型将文本用户消息转换为合成音频。然而,仅仅依赖 TTS 生成的音频会导致对真实人类语音(尤其是带口音的声音)的泛化能力较差,最常见的表现是对话提示的转录错误而不是适当的延续。为了解决这一限制,我们从长篇 ASR 数据中提取了可以通过一般世界知识充分回答的问题,因此不需要额外的音频上下文。然后,我们分离包含这些问题的音频摘录,并使用 Mistral Large 生成相应的文本答案。此过程生成由真实人类语音问题与文本答案配对组成的数据集。
语音识别是一个独特的用例,其特点是任务明确,因此文本提示显得多余。为了解决这个问题,我们引入了专用的“转录模式”,并通过一个新的特殊标记发出信号。此模式明确指示模型执行转录任务,从而无需文本提示。
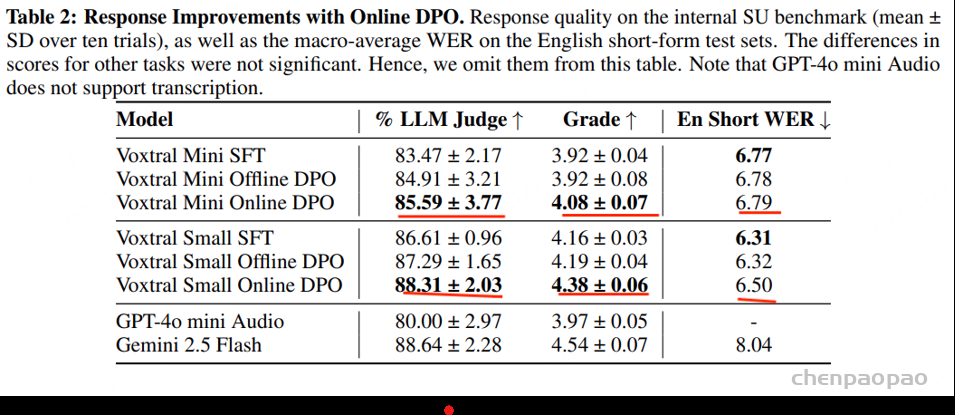
Preference Alignment
选择了 直接偏好优化 (DPO) 和 在线 (DPO) 。对于在线DPO,从当前策略中采样两个温度为 T=0.5 的候选响应。为了对响应进行排名,我们获取整个对话,用其转录替换音频,并利用基于文本的奖励模型。虽然奖励模型只能访问音频转录 – 而不是原始音频本身 – 但它能够从这些信息中捕捉语义、风格和事实一致性,这些属性会迁移到生成的文本响应。
虽然 DPO 和在线 DPO 都有助于提高响应质量,但在线版本更有效。
Voxtral Mini 在线 DPO 变体能够提供更清晰的接地气、更少的幻觉,并且通常能提供更有帮助的响应。
对于 Voxtral Small,我们发现其语音理解基准测试的响应质量得分显著提升,但在英语短句基准测试中却略有下降。
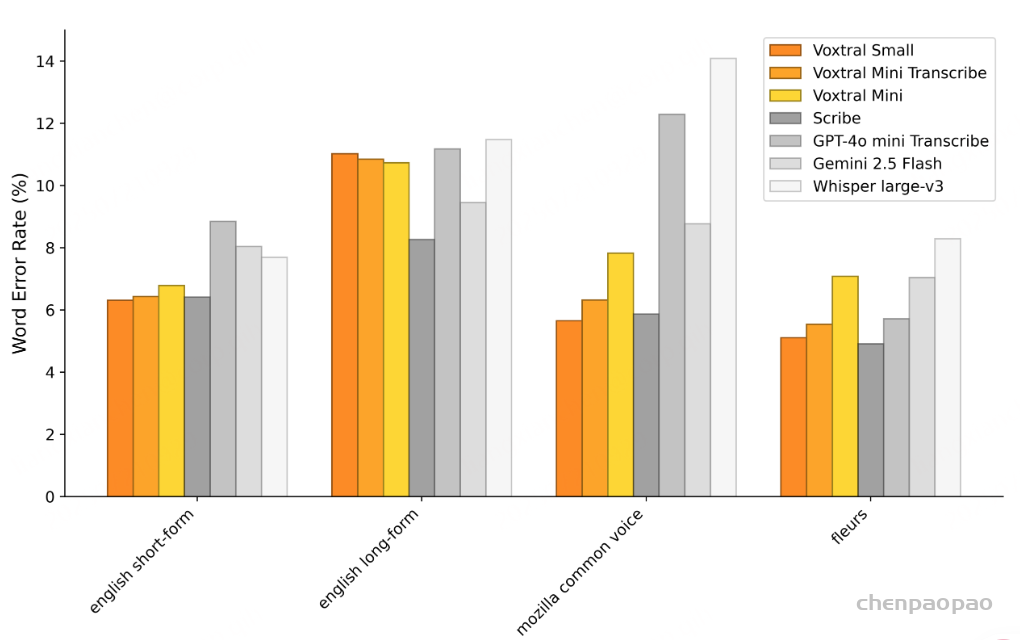
Results
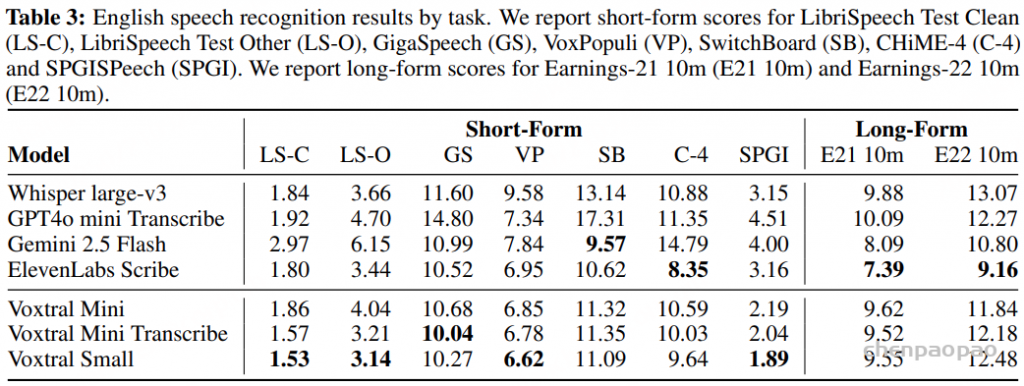
语音识别:各任务的平均 WER 结果。Voxtral Small 在英语短格式和 MCV 上的表现优于所有开源和闭源模型。Voxtral Mini Transcribe 在每项任务中均胜过 GPT-4o mini Transcribe 和 Gemini 2.5 Flash。
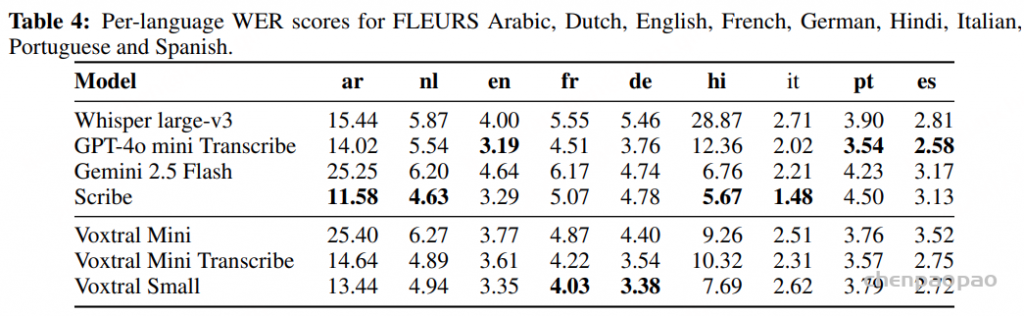
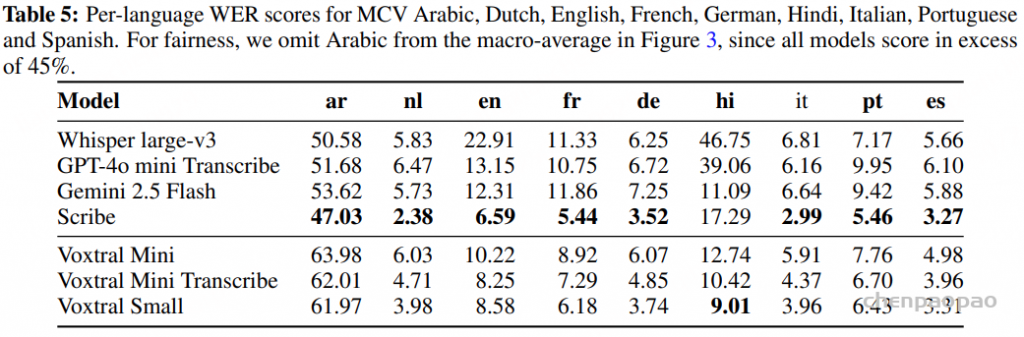
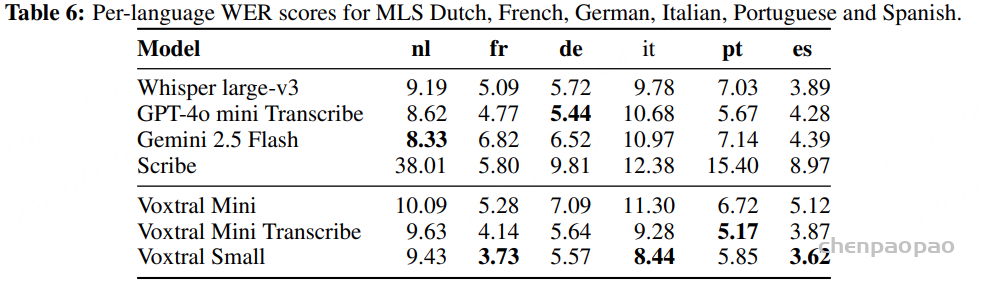
Tables 4, 5 and 6 show the per-language breakdown of WER scores for the FLEURS, Mozilla Common Voice and Multilingual LibriSpeech benchmarks, respectively.
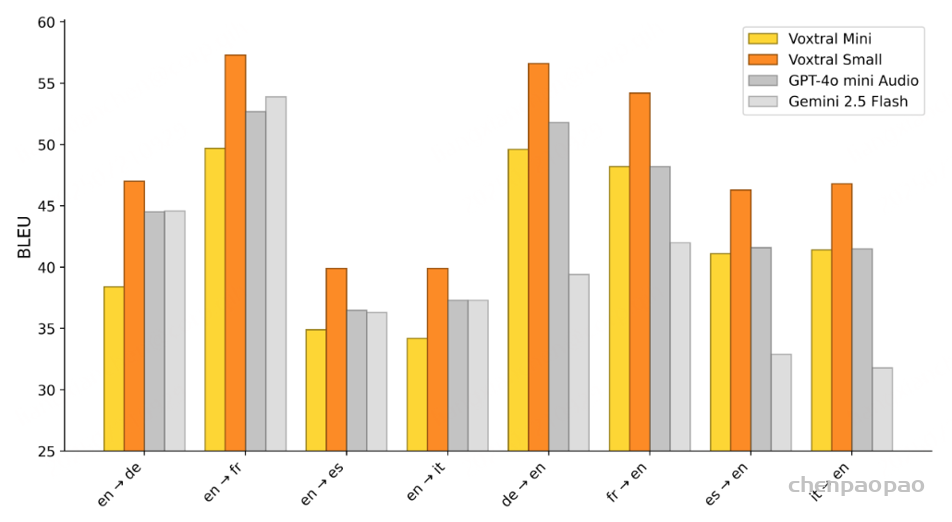
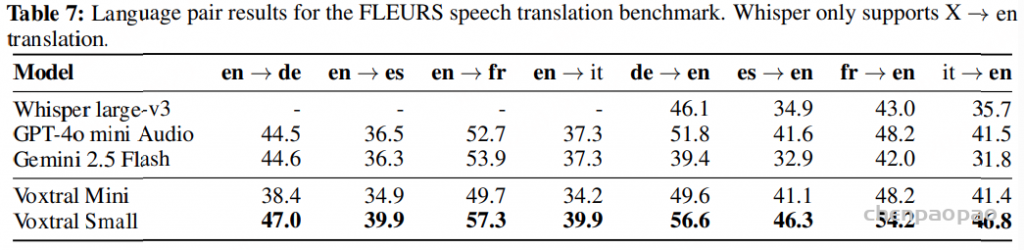
Speech Translation:在 FLEURS 语音翻译基准上对 Voxtral 进行了评估。图 4 展示了部分源/目标对的 BLEU 得分。Voxtral Small 在所有源/目标组合中都取得了最佳的翻译得分。
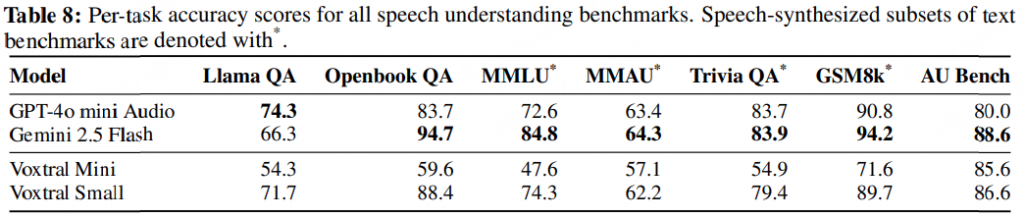
Speech Understanding:在三个语音理解基准和三个合成语音文本子集基准上的准确率。Voxtral Small 与闭源模型相比具有竞争力,在七个基准中的三个上超越了 GPT-4o mini Audio。
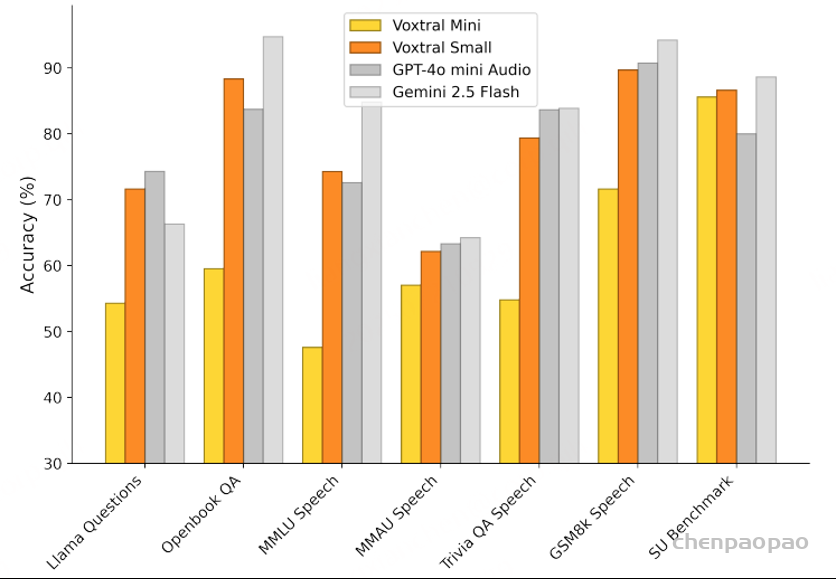
Speech Understanding Benchmark:

Text Benchmarks:
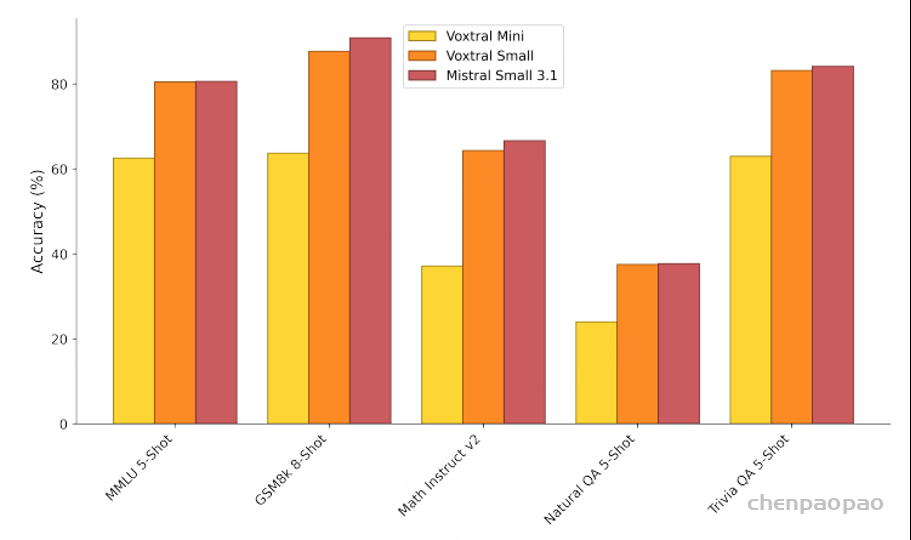
将 Voxtral Mini 和 Small 与纯文本 Mistral Small 3.1 模型的性能进行了比较。Voxtral Small 在文本基准测试中保持了良好的性能,使其成为文本和音频任务的理想替代品。