- 模型代码:https://github.com/boson-ai/higgs-audio
- 语音理解生成模型 Higgs-Audio:https://www.boson.ai/blog/higgs-audio
- Higgs Audio Tokenizer
- HiggsAudio-V2 模型架构
- https://www.boson.ai/blog/higgs-audio
- 模型微调:https://github.com/JimmyMa99/train-higgs-audio/tree/main
- 解读:量子位
Higgs Audio V2模型,不仅能处理文本,还能同时理解并生成语音。除了一些常规语音任务外,这个模型还具备一些较为罕见的能力,比如生成多种语言的自然多说话人对话、旁白过程中的自动韵律调整、使用克隆声音进行旋律哼唱以及同时生成语音和背景音乐。
整个过程堪称“大力出奇迹”,直接将1000万小时的语音数据整合到LLM的文本训练,

Higgs Audio v2 采用上图架构图中所示的“generation variant”。其强劲的性能源于三项关键技术创新:
- 开发了一套自动化注释流程,该流程充分利用了多个 ASR 模型、声音事件分类模型以及我们内部的音频理解模型。借助该流程,我们清理并注释了 1000 万小时的音频数据,并将其命名为 AudioVerse 。该内部理解模型在 Higgs Audio v1 Understanding 的基础上进行了微调,并采用了架构图中所示的“理解变体”。
- 从零开始训练了一个统一的音频分词器,它可以同时捕捉语义和声学特征。
- 提出了 DualFFN 架构,它增强了 LLM 以最小计算开销建模声学 token 的能力。
Higgs Audio V2 在音频 AI 能力上实现了重大飞跃:
- 多说话人对话自然流畅:多说话人对话往往难以处理,尤其是在角色无法匹配彼此的情绪和语气时。而借助 Higgs Audio V2,这种对话轻松自然,仿佛现场交流,充满生命力。
- 支持长音频生成:生成长音频时需要保持声音的一致性,同时兼顾真实感、吸引力和生动性。Higgs Audio 提供条件控制与提示机制,使长音频表现出色。
- 高保真音质:为了在高品质扬声器和耳机上实现逼真音效,V2 将音频处理管线从 16kHz 升级至 24kHz,带来更佳音质。
- 高效推理,资源友好:无论是个人项目还是商用部署,推理效率都很重要。我们最小的模型可以在 Jetson Orin Nano 上运行;最新的 3B Audio Generation V2 模型则至少需要 RTX 4090 才能高效推理。
- 生成真实、有情感的语音表现领先:在 EmergentTTS-Eval 基准测试中,其胜率超过 75%,超越 ChatGPT 4o。
- 开源:模型开源。
- 训练数据超千万小时:为实现更高音质与更逼真的语音效果,模型在超过1000万小时的音频上训练,并依托精细的处理与标注流程自动生成训练数据。
模型原理:
传统的语音和文本模型之间相互独立,李沐老师就想,欸,能不能将两者结合起来,直接让LLM用语音进行沟通。那么首先就要知道文本语言模型的本质是用给定的一段指令去生成预测结果,就是将任务先拆解为系统指令(system)、用户输入(user)、模型回复(assistant)三个部分。system告诉模型,需要做什么事情,例如回答该问题、写一段文字或者其他,user就是告知事情的详细内容,例如问题具体是什么、文字要什么风格。
所以如果要让模型支持语音,就需要为模型增加一个系统命令,在user里输入要转录为语音的文字,让模型从system里输出对应语音数据。这样语音任务就能转换成相同的处理格式,直接打通语音和文本之间的映射,通过追加更多的数据和算力,直接scaling law“大力出奇迹”。
音频分词器:
这就引出了新的问题,语音信号本质是连续的,要如何才能在离散的文本token中表示呢?
现有的方法是将一秒的语音信号裁切成多段(如100毫秒一段),为每一段匹配最相似的预定义模板(如45个模板),然后将其表示为长度为10的编号序列,也就是一个个token。
但这样做,虽然可以将一小时的音频从60兆压缩到0.16兆,但质量相当糟糕,所以需要优先保留语音的语义信息,而声学信号只保留少量部分,后续再通过其他手段还原。
于是他们训练了一个统一的离散化音频分词器,以每秒25帧 [40ms/帧] 的速度运行,同时保持甚至提高音频质量,以捕获语义和声学特征。
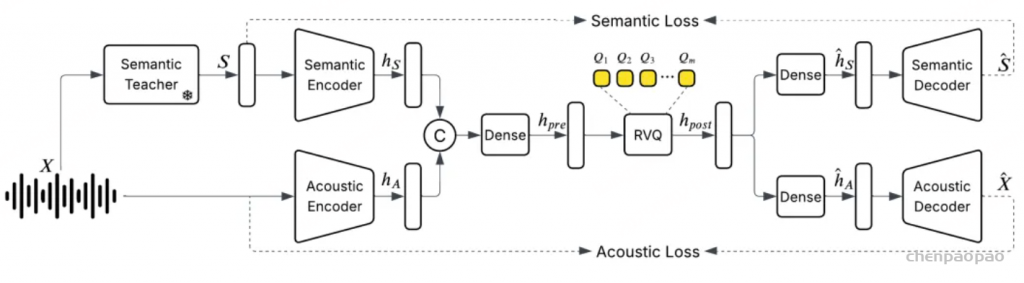
新的离散化音频分词器运行速度仅为每秒25帧,同时在音质上保持甚至优于码率翻倍的分词器。该模型是首个在 24 kHz 数据上训练的统一系统,覆盖语音、音乐与声音事件。同时,该模型采用简单的非扩散式编码器/解码器,实现快速批量推理。
解析模块:
- 语义教师模型 (Semantic Teacher): 生成语义表示 S,用于指导语义编码器提取语义信息;
- 语义编码器 (Semantic Encoder): 接收语义表示 S,提取语义特征 hS ;
- 声学编码器 (Acoustic Encoder): 直接从输入音频 X 中提取声学特征 hA ;
- 特征组合 (Concatenation): 将语义特征 hS 和声学特征 hA 进行特征组合,形成联合特征表示;
- Dense 层: 对联合特征进行非线性变换,生成预量化特征 hpre ;
- 残差向量量化 (RVQ): 对预量化特征进行hpre 量化,生成量化后的特征 hpost,并产生多个量化码本 Q1,Q2,…,Qm ;
- Dense 层: 对量化后的特征进行非线性变换hpost,生成用于解码的特征表示;
解码过程:
- 语义解码器 (Semantic Decoder): 使用处理后的量化特征重建语义表示 S^ ;
- 声学解码器 (Acoustic Decoder): 使用处理后的量化特征重建音频信号 X^ ;
具体流程:
- 特征提取: 原始音频 X 输入后,通过语义教师模型生成语义表示 S,然后通过语义编码器和声学编码器分别提取语义特征和声学特征;
- 特征组合与量化: 提取的语义和声学特征进行组合,经过非线性变换后进行残差向量量化,得到量化后的特征表示;
- 解码与重建: 量化后的特征分别输入语义解码器和声学解码器,重建语义表示 S^ 和音频信号 X^ ;
- 损失计算与优化: 通过计算语义损失和声学损失,优化模型的参数,使重建的语义和音频尽可能接近原始输入;
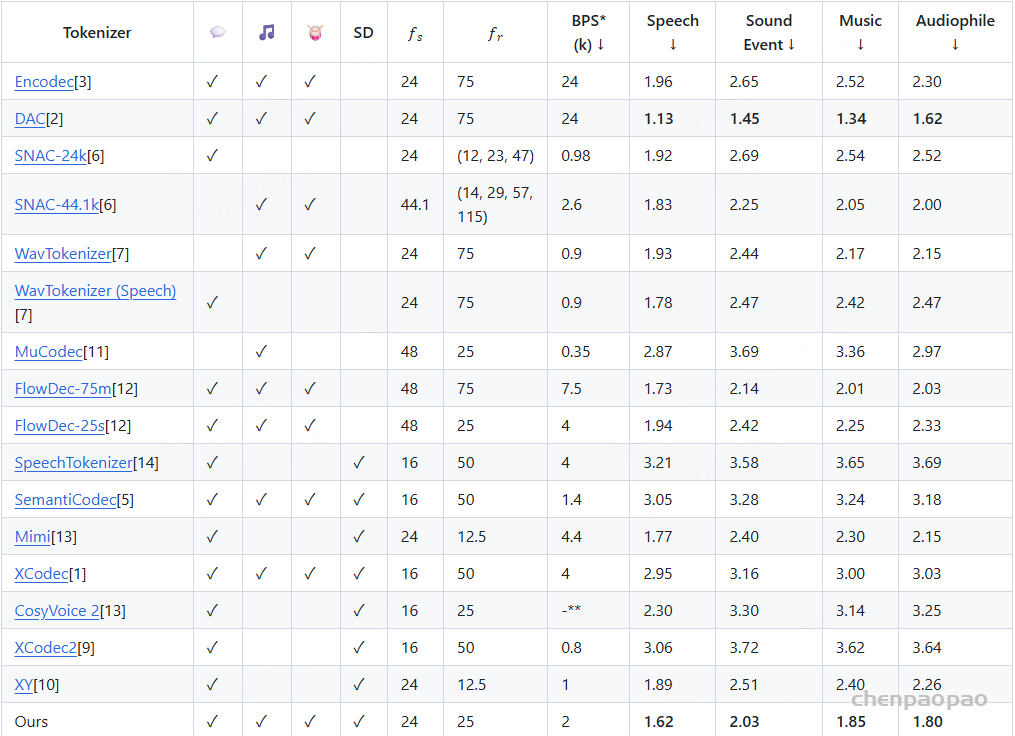
音频分词器性能:
整体架构
HiggsAudio-V2 模型基于大型语言模型(LLM),并集成了音频适配器(Audio Adapter)和音频解码器(Audio Decoder),用于处理音频输入和输出。
模型基于 Llama-3.2-3B 构建。为了增强模型处理音频 token 的能力,引入了“DualFFN”架构作为音频 adapter。DualFFN 充当音频专家,以最小的计算开销提升 LLM 的性能。通过引入 DualFFN,我们的实现保留了原始 LLM 91% 的训练速度。
组件组成
- Text Branch(浅蓝色):处理文本输入。
- Understanding Variant(浅蓝色):用于理解文本和音频输入。
- Generation Variant(黄色):用于生成文本和音频输出。
- Audio Adapter – Dual FFN(虚线框):专门设计用于处理音频令牌的模块,包含两个前馈网络(FFN)和多头自注意力(MHA)模块。
文本输入
- 文本输入通过 Text Tokenizer 转换为文本令牌(Text Token)。
- 文本令牌通过 Text Branch 进行处理。
音频输入
- 音频输入通过 Audio Tokenizer 转换为音频令牌(Audio Token)。
- 音频令牌通过 Understanding Variant 进行处理。
- 音频输入还通过 Semantic Encoder 提取语义信息。
文本和音频融合
- 文本和音频令牌在 LLM 中进行融合处理。
- Understanding Variant 和 Generation Variant 分别负责理解和生成任务。
音频适配器(Dual FFN)
- Audio Adapter 包含两个并行的前馈网络(FFN),分别处理文本和音频特征。
- 每个 FFN 之后都有一个归一化层(Norm)。
- 处理后的特征通过多头自注意力(MHA)模块进行进一步处理。
- 最终,处理后的文本和音频特征在音频适配器中融合。
为了提升模型处理音频令牌的能力,HiggsAudio-V2 引入了 “DualFFN” 架构作为音频适配器。DualFFN 作为音频专家模块,可以显著提升模型在音频任务上的性能,同时保持较低的计算开销。具体来说,DualFFN 在音频令牌处理过程中提供了额外的处理能力,使模型能够更有效地理解和生成音频数据。
延迟模式(Delay Pattern)
由于音频令牌化过程中涉及多个代码本,HiggsAudio-V2 采用了延迟模式(delay pattern)来实现跨代码本的并行代码生成。该模式通过在不同代码本之间引入偏移量,使得模型能够在保持音频质量的同时支持流式处理。延迟模式允许模型在生成音频时,同时处理多个代码本中的令牌,从而提高了生成效率。
然后要让模型很好地理解和生成声音,就需要利用模型的文本空间,将语音的语义尽量地映射回文本,当中需要大量的数据支持。
由于版权问题,沐导没有使用B站或YouTube这类公开视频网站数据,而是购买或从允许抓取的网站获取。这样得到的数据质量参差不齐,需要删除其中的90%才能满足1000万小时的训练数据需求。
其次,将语音对话表示为相应的system(场景描述、声学特征、人物特征等)、user(对话文本)、assistant(对应音频输出)的形式。由于OpenAI和谷歌一向禁止使用他们的模型输出再训练,且训练成本过高,为了实现这种标注,他们利用相同的模型架构额外训练出一个语音模型AudioVerse。
该模型接收用户语音输入,分析并输出场景、人物、情绪、内容等信息,再将输出反过来作为生成模型的system提示和user输入,实现模型的共同进步。
举个例子就是,如果想要教一个徒弟同时会拳脚功夫,但师傅一次又教不了,那就同时教两个徒弟,一个学打拳,一个学踢腿,然后让他们俩天天互相打,打着打着两个就都会拳脚功夫了。
最终,这个多模态模型就完成了,不仅可以完成简单的文本转语音,还能实现更复杂的任务,比如让它写一首歌并唱出来,再加上配乐。
还能根据语音分析场景、人物(性别、年龄、情绪状态)、环境音(室内外),并进行复杂的理解和推理。
在实时语音聊天上,还可实现低延迟、理解情绪并表达情绪的自然语音交互,而不仅仅是机械的问答。
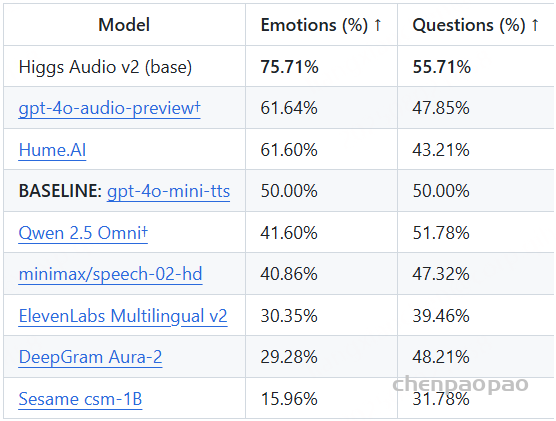
在EmergentTTS-Eval基准上,相较于其他模型,性能可以说是遥遥领先,尤其是在“情绪”和“问题”类别中,相比GPT-4o-mini-tts高出了75.7%和55.7%的胜率。
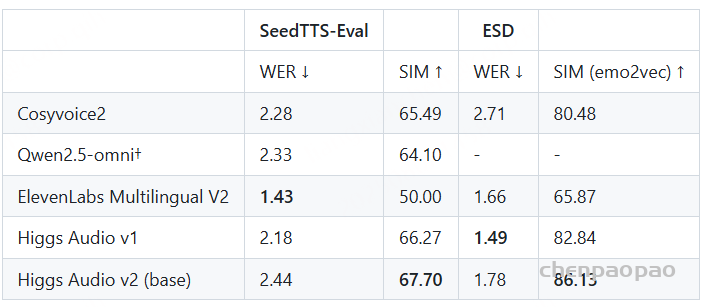
此外,它在Seed-TTS Eval和情感语音数据集 (ESD) 等传统TTS基准测试中也取得了最佳性能。
Evaluation:
Seed-TTS Eval & ESD
我们使用参考文本、参考音频和目标文本对 Higgs Audio v2 进行零样本语音合成(TTS)测试。评估采用 Seed-TTS Eval 和 ESD 中的标准评估指标。【SIM 指标一般是指 Speaker Similarity】
EmergentTTS-Eval (“Emotions” and “Questions”):根据 EmergentTTS-Eval 论文,我们报告了在使用 “alloy” 音色时,相较于 “gpt-4o-mini-tts” 的胜率。评判模型为 Gemini 2.5 Pro。
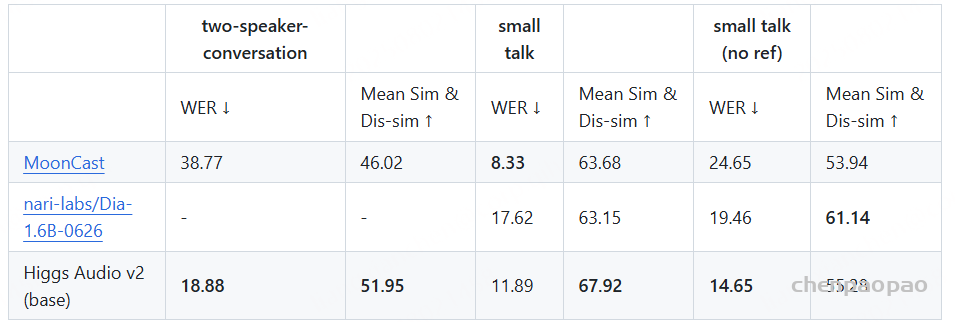
多说话人评估:我们还设计了一个多说话人评估基准,用于评估 Higgs Audio v2 在多说话人对话生成方面的能力。该基准集包含三个子集:
- two-speaker-conversation:包含1000条双人合成对话。我们固定两段参考音频,用以评估模型在双人语音克隆方面的能力,对话轮数在4到10轮之间,角色随机选择。
- small talk(无参考音频):包含250条合成对话,生成方式与上类似,但特点是发言简短、轮数较少(4–6轮)。本集合未提供参考音频,旨在评估模型自动为角色分配合适声音的能力。
- small talk(有参考音频):同样包含250条合成对话,发言更短。该集合在上下文中包含参考音频片段,类似于 two-speaker-conversation,用于评估基于参考音频的表现。
我们在这三个子集上报告了词错误率(WER)和说话人内相似度与说话人间差异度的几何平均值。除 Higgs Audio v2 外,我们还评估了 MoonCast 和 nari-labs/Dia-1.6B-0626 这两个当前最受欢迎、支持多说话人对话生成的开源模型。结果总结在下表中。由于 nari-labs/Dia-1.6B-0626 对话语长度及输出音频的严格限制,我们未能在 “two-speaker-conversation” 子集上运行该模型。