
快手科技、天津大学、中科院自动化所与清华大学联合发布了SecoustiCodec,一种跨模态对齐的流式单码本语音Codec。支持语义信息、副语言信息、声学信息的独立编码与重构。可以应用于语音合成、语音对话模型等生成式语音任务。
- 论文题目:SecoustiCodec: Cross-Modal Aligned Streaming Single-Codecbook Speech Codec
- 论文题目:跨模态对齐的流式单码本语音Codec
- DemoPage链接:https://qiangchunyu.github.io/SecoustiCodec_Page/
- GitHub链接:https://github.com/QiangChunyu/SecoustiCodec
- HuggingFace链接:https://huggingface.co/qiangchunyu/SecoustiCodec
背景动机
随着大型语言模型(Large Language Models,LLMs)在生成式人工智能领域的快速发展,基于语音的应用如文本到语音合成(TTS)、自动语音识别(ASR)以及语音对话系统等日益受到关注。语音编解码器作为连接原始语音信号与语言模型的重要桥梁,其作用类似于自然语言处理中的文本分词器,能够将连续的语音波形转化为离散的编码 token,便于与LLM等模型进行有效融合和交互。
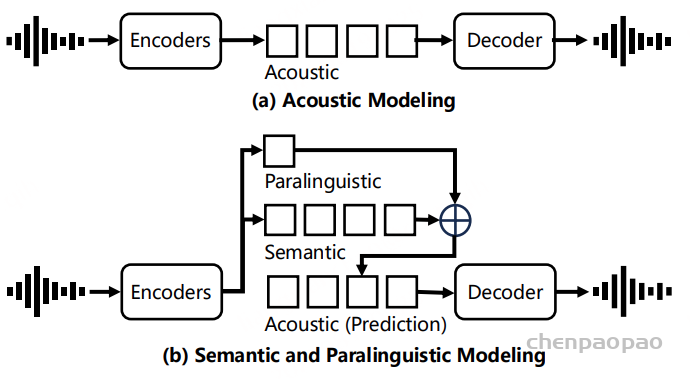
然而,当前主流的神经语音编解码器通常采用残差向量量化(RVQ)方法,通过将语音的语义信息与残差信息直接相加的方式重构语音。这种设计限制了语义编码的解耦能力及重构效果,不利于语义和声学信息的有效分离和高质量恢复。采用单一码本进行编码,这在低比特率条件下限制了编码的表达能力,难以兼顾语音的高保真度和压缩效率。同时,大多数现有模型采用非因果网络结构,导致处理延迟较高,难以满足实时语音翻译、在线会议和交互式对话系统等延迟敏感场景的需求。
针对上述瓶颈,我们提出了SecoustiCodec,一种全新设计的神经语音编解码器框架。SecoustiCodec通过独立建模声学信息、语义信息以及副语言信息,实现了低码率、高保真度的实时流式语音编码与解码。该方法不仅提升了语义编码的可分离性和重构质量,还有效降低了延迟,显著增强了模型在实际实时应用中的适用性。
语义 + 副语言 ≈ 声学
Contributions:
- 为了确保语义完整性和重建保真度,引入了副语言编码来弥合语义编码和声学编码之间的信息鸿沟。
- 基于 VAE+FSQ 的纯语义高效量化方法,提高码本利用率以及缓解token的长尾分布。
- 提出了一种基于对比学习的语义解缠方法,该方法在联合多模态帧级空间中对齐文本和语音。
- 设计了一种声学约束的多阶段优化策略,通过逐步引入模块并调整不同损失成分的影响来确保模型的有效收敛。此外,采用因果架构来支持流式编码和解码。
方法
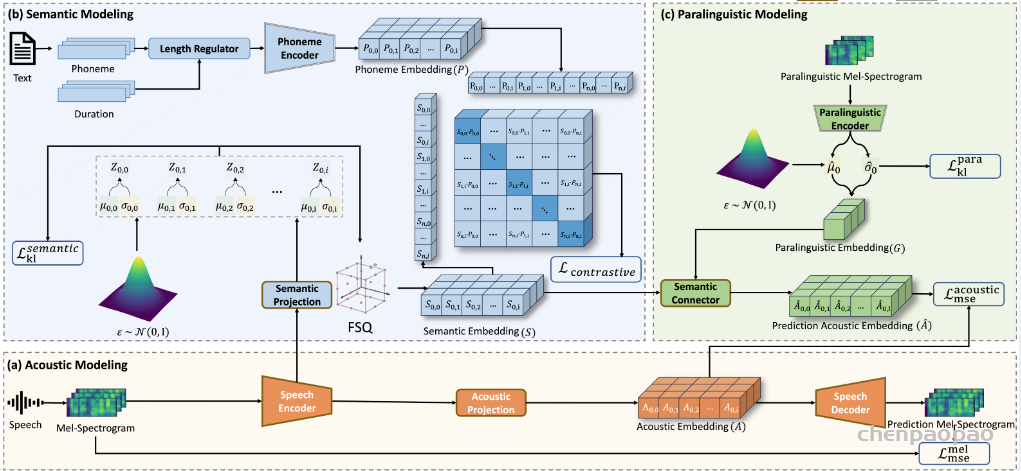
SecoustiCodec的整体架构包括三个主要的建模过程:声学建模(Acoustic Modeling)、语义建模(Semantic Modeling)和副语言建模(Paralinguistic Modeling)。这三个过程相互协作,共同实现语音信号的编码和解码。具体来说:
- 声学建模:负责将输入的语音信号编码为连续的声学表示,并通过解码器重建语音信号。
- 语义建模:通过对比学习和高效的量化方法,提取纯净的语义信息,并将其编码为离散的语义表示。
- 副语言建模:提取语音中的副语言信息(如音色、情感等),并将其编码为全局级的副语言表示。
这三个表示之间的关系可以用公式S + G ≈ A 来描述,其中 S 是离散语义编码,G 是全局级副语言编码,A 是连续声学表示。通过这种方式,SecoustiCodec能够在单码本空间中实现语义和副语言信息的分离。
1.声学建模
声学建模部分包括语音编码器、声学投影和语音解码器。语音编码器将输入的语音信号Sin编码为连续的声学表示 A,然后通过声学投影模块进一步处理。语音解码器则负责将声学表示 A 重建为语音信号。
2. 语义建模
语义建模部分包括语义投影、变分自编码器(VAE)、有限标量量化(FSQ)和对比学习模块。其目标是从语音信号中提取纯净的语义信息,并将其编码为离散的语义表示 S。首先通过语义投影,将语音编码器的输出进一步映射到一个低维的语义空间。随后采用VAE + FSQ,通过VAE生成语义表示的均值 μ 和方差 σ,然后通过FSQ将这些连续的语义表示量化为离散的语义编码 S。这种方法不仅保留了语义信息,还进一步去除了副语言信息,同时提高了码本利用率。最后通过对比学习模块,将语音编码器生成的语义表示 S 和文本编码器生成的音素表示 P 对齐到一个联合帧级对齐的多模态空间中。通过最大化正样本对(S和对应的P)之间的相似度,同时最小化负样本对(S和不对应的P)之间的相似度,模型能够学习到纯净的语义表示。
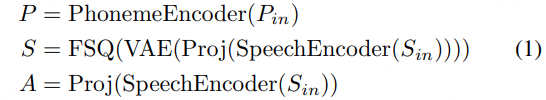
其中 P 是音频表征,S 是语义表征,A是声学表征。
3. 副语言建模
副语言建模部分包括副语言编码器和语义连接器。其目标是从语音信号中提取副语言信息,并将其编码为全局级的副语言表示G。首先通过副语言编码器才从语音信号中提取副语言信息,如音色、情感等。随后经过语义连接器,将语义表示 S 和副语言表示 G 结合起来,预测声学表示 A^。通过这种方式,模型能够在解码阶段利用副语言信息来重建语音信号。
副语言语音 Gin 作为副语言编码器的输入:
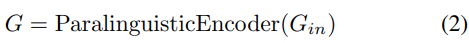
G 表示副语言嵌入,其中 G 是固定长度的全局向量
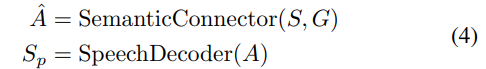
4. 声学约束的多阶段优化策略
SecoustiCodec设计了一种声学约束的多阶段优化策略,逐步引入模块和调整损失函数的影响,确保模型的有效收敛。具体来说:
第一阶段(声学建模)Algorithm(Lines 3-4):仅训练语音编码器、声学投影和语音解码器,专注于学习声学表示A。
第二阶段(语义和副语言建模)Algorithm(Lines 5-13):冻结第一阶段的模块,训练语义投影、副语言编码器、语义连接器等模块,逐步引入对比学习损失和KL散度损失,优化语义和副语言表示。

实验结果
1.结构对比
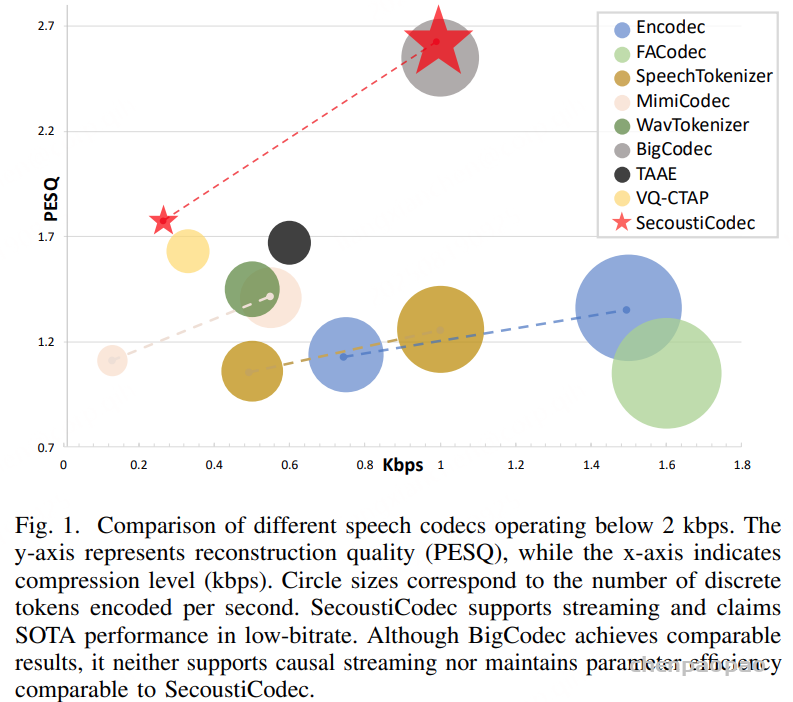
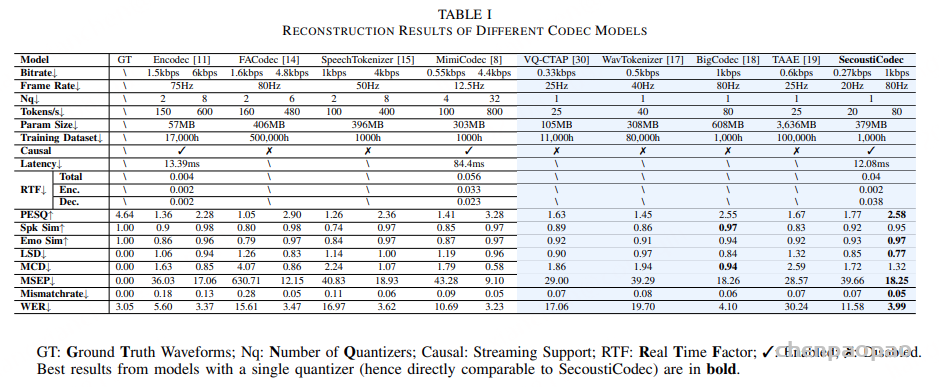
SecoustiCodec在0.27kbps的比特率下实现了20Hz的帧率和20tokens/s的编码速率,仅次于MimiCodec。SecoustiCodec采用VAE+FSQ量化方法,同时支持单码本语义编码和连续值声学编码。SecoustiCodec使用1000小时的训练数据,与SpeechTokenizer、MimiCodec和BigCodec相当,但远少于FACodec的500000小时和TAAE的100000小时。此外,SecoustiCodec采用因果结构以支持流式编码和解码。
2. 语音重建性能
SecoustiCodec在0.27kbps和1kbps的比特率下实现了业界领先的重建质量。具体来说,SecoustiCodec(0.27kbps)在PESQ(感知语音质量评估)指标上达到了1.77,而SecoustiCodec(1kbps)的PESQ值更是高达2.58。这些结果不仅优于其他单码本模型,甚至在某些情况下超过了使用多个码本的模型。此外,SecoustiCodec在情感相似度(EmoSim)、说话人相似度(SpkSim)、对数谱距离(LSD)、基频误差(MSEP)、误配率(Mismatchrate)和词错误率(WER)等多个指标上也表现出色,证明了其在语义解耦和重建能力方面的优势。
3. 流式处理能力
SecoustiCodec的因果架构设计使其在流式处理方面表现出色。实验结果表明,SecoustiCodec的初始延迟为12.08ms,低于Encodec和MimiCodec等其他支持流式处理的模型。虽然Encodec在实时因子(RTF)方面表现更好,区别主要体现在解码阶段,SecoustiCodec在去掉声码器处理时间后的解码RTF仅为0.001,显著低于Encodec。
4. 消融实验

在不同量化方法的性能对比结果显示,VAE+FSQ量化方法在各项关键指标上均展现出优于VQ-VAE、SimVQ和FSQ等其他量化方法的表现。这一结果表明,VAE+FSQ在保留语义信息、去除副语言信息以及提高码本利用率方面具有显著优势。
对于因果结构的实验结果表明,具备因果结构的模型版本在多个指标上相较于不具备因果结构的版本有更佳表现,尤其是在实时性和低延迟场景中,这凸显了因果结构对于流式处理支持的重要作用。
在音高特征方面,实验结果表明,加入音高特征的模型在MSEP和WER等指标上的表现不如未加入音高特征的模型,这表明音高特征可能会对语义信息的提取产生干扰。
对于多阶段训练策略的实验结果表明,采用该策略的模型在所有指标上均优于未采用的版本,这表明多阶段训练策略对于模型的收敛和性能提升具有关键性影响。
声学嵌入维度的实验结果表明,较高的声学嵌入维度(256维)能够显著提升模型在多个评价指标上的表现。基于此,我们最终选择将256维作为SecoustiCodec的声学编码维度。
SecoustiCodec在单说话人场景下也表现出色,经过针对单一目标说话人进行微调后,模型在所有关键指标上均取得了高分。

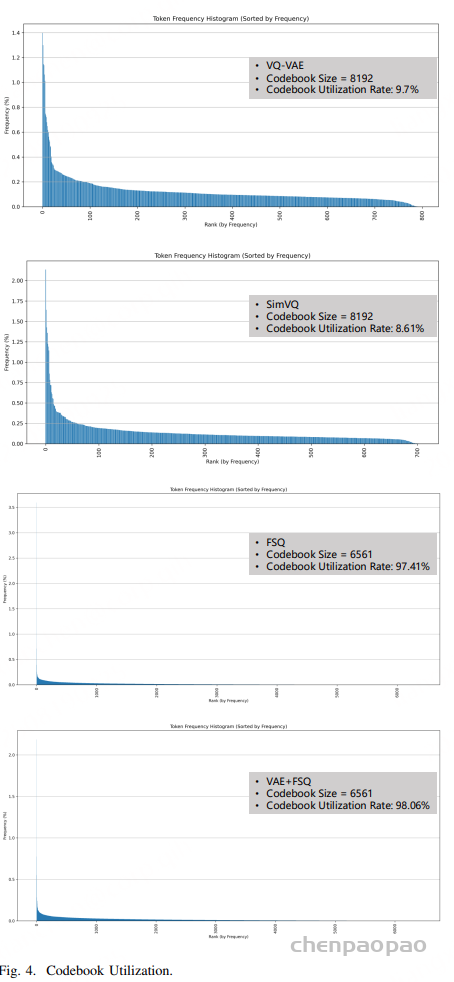
SecoustiCodec的VAE + FSQ量化方法在码本利用率方面表现出色,达到了98.06%。这一结果显著高于其他量化方法,如VQ-VAE(9.7%)和SimVQ(8.61%)。高码本利用率意味着模型能够更有效地利用有限的码本资源,减少长尾分布问题,从而提高语言模型训练的效率和效果。
总结与未来展望
SecoustiCodec通过独立建模声学、语义和副语言信息,结合基于VAE + FSQ的高效量化方法、对比学习驱动的语义解耦技术和声学约束的多阶段优化策略,成功地在低比特率下实现了高保真、实时流式语音编解码。其在多个关键指标上的卓越表现证明了其在语音编解码领域的先进性和实用性。未来,我们计划探索无监督解耦方法,以减少对标注文本数据的依赖,并验证模型在其他语言上的适应性,以进一步提升其有效性和通用性。